
英伟达 H100 vs. 苹果 M2,大模型训练,哪款性价比更高?


M1 芯片 | Uitra | AMD | A100
M2 芯片 | ARM | A800 | H100
关键词:M2 芯片;Ultra;M1 芯片;UltraFusion;ULTRAMAN;RTX4090、A800;A100;H100;LLAMA、LM、AIGC、CHATGLM、LLVM、LLM、LLMs、GLM、NLP、ChatGPT、AGI、HPC、GPU、CPU、CPU+GPU、英伟达、Nvidia、英特尔、AMD、高性能计算、高性能服务器、蓝海大脑、多元异构算力、高性能计算、大模型训练、大型语言模型、通用人工智能、GPU 服务器、GPU 集群、大模型训练 GPU 集群、大语言模型
摘要:训练和微调大型语言模型对于硬件资源的要求非常高。目前,主流的大模型训练硬件通常采用英特尔的 CPU 和英伟达的 GPU。然而,最近苹果的 M2 Ultra 芯片和 AMD 的显卡进展给我们带来了一些新的希望。
苹果的 M2 Ultra 芯片是一项重要的技术创新,它为苹果设备提供了卓越的性能和能效。与此同时,基于 AMD 软硬件系统的大模型训练体系也在不断发展,为用户提供了更多选择。尽管英伟达没有推出与苹果相媲美的 200G 显卡,但他们在显卡领域的竞争仍然激烈。对比苹果芯片与英伟达、英特尔、AMD 的最新硬件和生态建设,我们可以看到不同厂商在性价比方面带来了全新的选择。
蓝海大脑为生成式 AI 应用提供了极具吸引力的算力平台,与英特尔紧密协作,为客户提供强大的大模型训练和推理能力,加速 AIGC 创新步伐、赋力生成式 AI 产业创新。
基于英特尔 CPU+英伟达 GPU 大模型训练基础架构
一、深度学习架构大模型的主要优势
当前主流大模型架构都是基于深度学习 transformer 的架构模型,使用 GPU 训练深度学习架构的大模型主要有以下优势:
1、高性能计算
深度学习中的大部分计算都是浮点计算,包括矩阵乘法和激活函数的计算。GPU 在浮点计算方面表现出色,具有高性能计算能力。
2、并行计算能力
GPU 具有高度并行的计算架构,能够同时执行多个计算任务。深度学习模型通常需要执行大量的矩阵乘法和向量运算,这些操作可以高度并行的方式进行,从而提高深度学习模型训练效率。
3、高内存带宽
GPU 提供高达几百 GB/s 的内存带宽,满足深度学习模型对数据大容量访问需求。这种高内存带宽能够加快数据传输速度,提高模型训练的效率。
二、当前大多数大模型采用英特尔的 CPU 加英伟达的 GPU 作为计算基础设施的原因
尽管 GPU 在训练大模型时发挥着重要作用,但单靠 GPU 远远不够。除 GPU 负责并行计算和深度学习模型训练外,CPU 在训练过程中也扮演着重要角色,其主要负责数据的预处理、后处理以及管理整个训练过程的任务。通过 GPU 和 CPU 之间的协同工作,可以实现高效的大规模模型训练。
1、强大的性能
英特尔最新 CPU 采用 Alder Lake 架构,具备出色的通用计算能力。而英伟达最新 GPU H100 拥有 3.35TB/s 的显存带宽、80GB 的显存大小和 900GB/s 的显卡间通信速度,对大数据吞吐和并行计算提供友好的支持。
2、广泛的支持和生态系统
基于英特尔 CPU 提供的 AVX2 指令集和基于英伟达 GPU 提供的 CUDA 并行计算平台和编程模型,构建优秀的底层加速库如 PyTorch 等上层应用。
3、良好的兼容性和互操作性
在硬件和软件设计上考虑彼此配合使用的需求,能够有效地协同工作。这种兼容性和互操作性使得英特尔的 CPU 和英伟达的 GPU 成为流行的组合选择,在大规模模型训练中得到广泛应用。
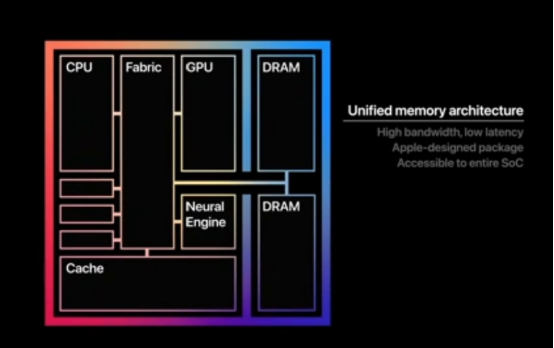
苹果的 M2 Ultra 统一内存架构
在 WWDC2023 开发者大会上苹果推出 M2 Ultra 芯片,以及搭载该芯片的新款 Mac Studio 和 Mac Pro。这款芯片采用了第二代 5nm 制程工艺技术,是苹果迄今为止最大且最强大的芯片。
去年 3 月,苹果展示了一种将两块 M1 芯片“粘”在一起的设计,发布集成 1140 亿颗晶体管、20 核 CPU、最高 64 核 GPU、32 核神经网络引擎、2.5TB/s 数据传输速率、800GB/s 内存带宽、128GB 统一内存的“至尊版”芯片 M1 Ultra。延续 M1 Ultra 的设计思路,M2 Ultra 芯片通过采用突破性的 UltraFusion 架构,将两块 M2 Max 芯片拼接到一起,拥有 1340 亿个晶体管,比上一代 M1 Ultra 多出 200 亿个。

UltraFusion 是苹果在定制封装技术方面的领先技术,其使用硅中介层(interposer)将芯片与超过 10000 个信号连接起来,从而提供超过 2.5TB/s 的低延迟处理器间带宽。基于这一技术,M2 Ultra 芯片在内存方面比 M1 Ultra 高出了 50%,达到 192GB 的统一内存,并且拥有比 M2 Max 芯片高两倍的 800GB/s 内存带宽。以往由于内存不足,即使是最强大的独立 GPU 也无法处理大型模型。然而,苹果通过将超大内存带宽集成到单个 SoC 中,实现单台设备可以运行庞大的机器学习工作负载,如大型 Transformer 模型等。

AMD 的大模型训练生态
除苹果的 M2 Ultra 在大模型训练方面取得了显著进展之外,AMD 的生态系统也在加速追赶。
据 7 月 3 日消息,NVIDIA 以其显著的优势在显卡领域获得了公认的地位,无论是在游戏还是计算方面都有着显著的优势,而在 AI 领域更是几乎垄断。然而,有好消息传来,AMD 已经开始发力,其 MI250 显卡性能已经达到了 NVIDIA A100 显卡的 80%。 AMD 在 AI 领域的落后主要是因为其软件生态无法跟上硬件发展的步伐。尽管 AMD 的显卡硬件规格很高,但其运算环境与 NVIDIA 的 CUDA 相比仍然存在巨大的差距。最近,AMD 升级了 MI250 显卡,使其更好地支持 PyTorch 框架。
MosaicML 的研究结果显示,MI250 显卡在优化后的性能提升显著,大语言模型训练速度已达到 A100 显卡的 80%。AMD 指出,他们并未为 MosaicML 进行这项研究提供资助,但表示将继续与初创公司合作,以优化软件支持。 但需要注意的是,NVIDIA A100 显卡是在 2020 年 3 月发布的,已经是上一代产品,而 NVIDIA 目前最新的 AI 加速卡是 H100,其 AI 性能有数倍至数十倍的提升。AMD 的 MI250 显卡也不是最新产品,其在 2021 年底发布,采用 CDNA2 架构,6nm 工艺,拥有 208 个计算单元和 13312 个流处理器核心,各项性能指标比 MI250X 下降约 5.5%,其他规格均未变动。

AMD 体系的特点如下:
一、LLM 训练非常稳定
使用 AMD MI250 和 NVIDIA A100 在 MPT-1B LLM 模型上进行训练时,从相同的检查点开始,损失曲线几乎完全相同。
二、性能与现有的 A100 系统相媲美
MosaicML 对 MPT 模型的 1B 到 13B 参数进行了性能分析发现 MI250 每个 GPU 的训练吞吐量在 80%的范围内与 A100-40GB 相当,并且与 A100-80GB 相比在 73%的范围内。随着 AMD 软件的改进,预计这一差距将会缩小。
三、基本无需代码修改
得益于 PyTorch 对 ROCm 的良好支持,基本上不需要修改现有代码。
英伟达显卡与苹果 M2 Ultra 相比性能如
一、英伟达显卡与 M2 Ultra 相比性能如何
在传统英特尔+英伟达独立显卡架构下,CPU 与 GPU 之间的通信通常通过 PCIe 进行。最强大的 H100 支持 PCIe Gen5,传输速度为 128GB/s,而 A100 和 4090 则支持 PCIe 4,传输速度为 64GB/s。
另一个重要的参数是 GPU 的显存带宽,即 GPU 芯片与显存之间的读写速度。显存带宽是影响训练速度的关键因素。例如,英伟达 4090 显卡的显存带宽为 1.15TB/s,而 A100 和 H100 的显存带宽分别为 1.99TB/s 和 3.35TB/s。
最后一个重要的参数是显存大小,它指的是显卡上的存储容量。目前,4090 是消费级显卡的顶级选择,显存大小为 24GB,而 A100 和 H100 单张显卡的显存大小均为 80GB。这个参数对于存储大规模模型和数据集时非常重要。
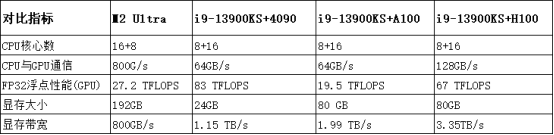
M2 Ultra 的芯片参数和 4090 以及 A100 的对比(CPU 采用英特尔最新的 i9-13900KS)
从这些参数来看,苹果的 M2 Ultra 相对于英伟达的 4090 来说性能稍低,与专业级显卡相比则较为逊色。然而,M2 Ultra 最重要的优势在于统一内存,即 CPU 读写的内存可以直接被显卡用作显存。因此,拥有 192GB 的显存几乎相当于 8 个 4090 或者 2.5 个 A100/H100 的显存。这意味着单个 M2 Ultra 芯片可以容纳非常大的模型。例如,当前开源的 LLaMA 65B 模型需要 120GB 的显存才能进行推理。这意味着苹果的 M2 Ultra 可以直接适用于 LLaMA 65B,而目前没有其他芯片能够单独承载如此庞大的模型,甚至包括最新的 H100。
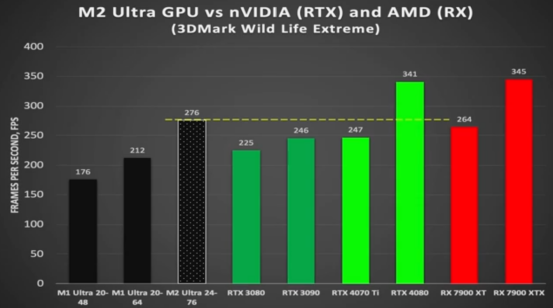
从上述参数对比来看,M2 Ultra 在其他指标接近 4090 的情况下,显存大小成为其最大的优势。尽管 M2 Ultra 并非专为大模型训练而设计,但其架构非常适合进行大模型训练。
在上层生态方面,进展也非常良好。2022 年 5 月 18 日,PyTorch 宣布支持苹果芯片,并开始适配 M1 Ultra,利用苹果提供的芯片加速库 MPS 进行加速 Ultra 上使用 PyTorch 进行训练。以文本生成图片为例,它能够一次性生成更多且更高精度的图片。
二、NVIDIA 为什么不推出一款 200GB 显存以上的 GPU?
主要原因可以分为以下几点:
1、大语言模型火起来还没多久;
2、显存容量和算力是要匹配的,空有 192GB 显存,但是算力不足并无意义;
3、苹果大内存,适合在本地进行推理,有希望引爆在端侧部署 AI 的下一轮热潮。
从 2022 年 11 月 ChatGPT 火起来到现在,时间也不过才半年时间。从项目立项,到确定具体的规格,再到设计产品,并且进行各种测试,最终上市的全流程研发时间至少在一年以上。客观上讲,大语言模型形成全球范围的热潮,一定会带动对于显存容量的需求。英伟达未来显存容量的升级速度一定会提速。
过去之所以消费级显卡的显存容量升级较慢,根本原因是没有应用场景。8GB 的消费级显卡用来打游戏足矣,加速一些视频剪辑也绰绰有余。更高的显存容量,只能服务于少量科研人员,而且大多都去买了专业卡专门应用。现在有了大语言模型,可以在本地部署一个开源的模型。有了对于显存的明确需求,未来一定会快速提升显存容量的。
其次,苹果有 192GB 的统一内存可以用于大语言模型的“训练”。这个认知是完全错误的。AI 模型可以分为训练(train)、微调(fine-tune)和推理(inference)。简单来说,训练就是研发人员研发 AI 模型的过程,推理就是用户部署在设备上来用。从算力消耗上来说,是训练>微调>推理,训练要比推理的算力消耗高至少 3 个数量级以上。
训练也不纯粹看一个显存容量大小,而是和芯片的算力高度相关的。因为实际训练的过程当中,将海量的数据切块成不同的 batch size,然后送入显卡进行训练。显存大,意味着一次可以送进更大的数据块。但是芯片算力如果不足,单个数据块就需要更长的等待时间。
显存和算力,必须要相辅相成。在有限的产品成本内,两者应当是恰好在一个平衡点上。现阶段英伟达的 H100 能够广泛用于各大厂商的真实模型训练,而不是只存在于几个自媒体玩具级别的视频里面,说明 H100 能够满足厂商的使用需要。
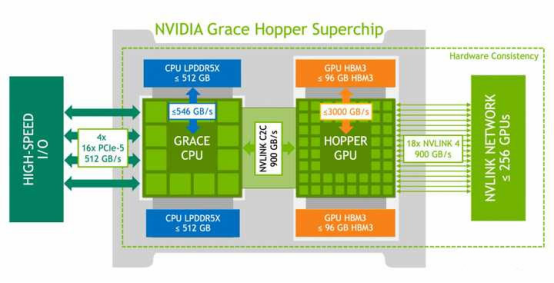
要按苹果的显存算法,一块 Grace Hopper 就超过了啊。一块 Grace Hopper 的统一内存高达 512GB,外加 Hopper 还有 96GB 的独立显存,早就超了。
使用 NVIDIA H100 训练 ChatGPT 大模型仅用 11 分钟
AI 技术的蓬勃发展使得 NVIDIA 的显卡成为市场上备受瞩目的热门产品。尤其是高端的 H100 加速卡,其售价超过 25 万元,然而市场供不应求。该加速卡的性能也非常惊人,最新的 AI 测试结果显示,基于 GPT-3 的大语言模型训练任务刷新了记录,完成时间仅为 11 分钟。
据了解,机器学习及人工智能领域的开放产业联盟 MLCommons 发布了最新的 MLPerf 基准评测。包括 8 个负载测试,其中就包含基于 GPT-3 开源模型的 LLM 大语言模型测试,这对于评估平台的 AI 性能提出了很高的要求。
参与测试的 NVIDIA 平台由 896 个 Intel 至强 8462Y+处理器和 3584 个 H100 加速卡组成,是所有参与平台中唯一能够完成所有测试的。并且,NVIDIA 平台刷新了记录。在关键的基于 GPT-3 的大语言模型训练任务中,H100 平台仅用了 10.94 分钟,与之相比,采用 96 个至强 8380 处理器和 96 个 Habana Gaudi2 AI 芯片构建的 Intel 平台完成同样测试所需的时间为 311.94 分钟。
H100 平台的性能几乎是 Intel 平台的 30 倍,当然,两套平台的规模存在很大差异。但即便只使用 768 个 H100 加速卡进行训练,所需时间仍然只有 45.6 分钟,远远超过采用 Intel 平台的 AI 芯片。
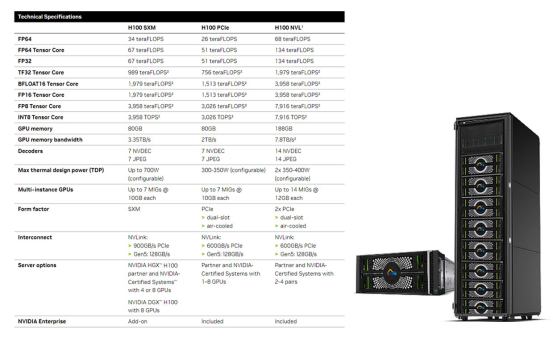
H100 加速卡采用 GH100 GPU 核心,定制版台积电 4nm 工艺制造,拥有 800 亿个晶体管。它集成了 18432 个 CUDA 核心、576 个张量核心和 60MB 的二级缓存,支持 6144-bit HBM 高带宽内存以及 PCIe 5.0 接口。

H100 计算卡提供 SXM 和 PCIe 5.0 两种样式。SXM 版本拥有 15872 个 CUDA 核心和 528 个 Tensor 核心,而 PCIe 5.0 版本则拥有 14952 个 CUDA 核心和 456 个 Tensor 核心。该卡的功耗最高可达 700W。
就性能而言,H100 加速卡在 FP64/FP32 计算方面能够达到每秒 60 万亿次的计算能力,而在 FP16 计算方面达到每秒 2000 万亿次的计算能力。此外,它还支持 TF32 计算,每秒可达到 1000 万亿次,是 A100 的三倍。而在 FP8 计算方面,H100 加速卡的性能可达每秒 4000 万亿次,是 A100 的六倍。
蓝海大脑大模型训练平台
蓝海大脑大模型训练平台提供强大的支持,包括基于开放加速模组高速互联的 AI 加速器。配置高速内存且支持全互联拓扑,满足大模型训练中张量并行的通信需求。支持高性能 I/O 扩展,同时可以扩展至万卡 AI 集群,满足大模型流水线和数据并行的通信需求。强大的液冷系统热插拔及智能电源管理技术,当 BMC 收到 PSU 故障或错误警告(如断电、电涌,过热),自动强制系统的 CPU 进入 ULFM(超低频模式,以实现最低功耗)。致力于通过“低碳节能”为客户提供环保绿色的高性能计算解决方案。主要应用于深度学习、学术教育、生物医药、地球勘探、气象海洋、超算中心、AI 及大数据等领域。

一、为什么需要大模型?
1、模型效果更优
大模型在各场景上的效果均优于普通模型
2、创造能力更强
大模型能够进行内容生成(AIGC),助力内容规模化生产
3、灵活定制场景
通过举例子的方式,定制大模型海量的应用场景
4、标注数据更少
通过学习少量行业数据,大模型就能够应对特定业务场景的需求
二、平台特点
1、异构计算资源调度
一种基于通用服务器和专用硬件的综合解决方案,用于调度和管理多种异构计算资源,包括 CPU、GPU 等。通过强大的虚拟化管理功能,能够轻松部署底层计算资源,并高效运行各种模型。同时充分发挥不同异构资源的硬件加速能力,以加快模型的运行速度和生成速度。
2、稳定可靠的数据存储
支持多存储类型协议,包括块、文件和对象存储服务。将存储资源池化实现模型和生成数据的自由流通,提高数据的利用率。同时采用多副本、多级故障域和故障自恢复等数据保护机制,确保模型和数据的安全稳定运行。
3、高性能分布式网络
提供算力资源的网络和存储,并通过分布式网络机制进行转发,透传物理网络性能,显著提高模型算力的效率和性能。
4、全方位安全保障
在模型托管方面,采用严格的权限管理机制,确保模型仓库的安全性。在数据存储方面,提供私有化部署和数据磁盘加密等措施,保证数据的安全可控性。同时,在模型分发和运行过程中,提供全面的账号认证和日志审计功能,全方位保障模型和数据的安全性。
三、常用配置
目前大模型训练多常用 H100、H800、A800、A100 等 GPU 显卡,其中 H100 配备第四代 Tensor Core 和 Transformer 引擎(FP8 精度),与上一代产品相比,可为多专家 (MoE) 模型提供高 9 倍的训练速度。通过结合可提供 900 GB/s GPU 间互连的第四代 NVlink、可跨节点加速每个 GPU 通信的 NVLINK Switch 系统、PCIe 5.0 以及 NVIDIA Magnum IO™ 软件,为小型企业到大规模统一 GPU 集群提供高效的可扩展性。
搭载 H100 的加速服务器可以提供相应的计算能力,并利用 NVLink 和 NVSwitch 每个 GPU 3 TB/s 的显存带宽和可扩展性,凭借高性能应对数据分析以及通过扩展支持庞大的数据集。通过结合使用 NVIDIA Quantum-2 InfiniBand、Magnum IO 软件、GPU 加速的 Spark 3.0 和 NVIDIA RAPIDS™,NVIDIA 数据中心平台能够以出色的性能和效率加速这些大型工作负载。
1、H100 工作站常用配置
CPU:英特尔至强 Platinum 8468 48C 96T 3.80GHz 105MB 350W *2
内存:动态随机存取存储器 64GB DDR5 4800 兆赫 *24
存储:固态硬盘 3.2TB U.2 PCIe 第 4 代 *4
GPU :Nvidia Vulcan PCIe H100 80GB *8
平台 :HD210 *1
散热 :CPU+GPU 液冷一体散热系统 *1
网络 :英伟达 IB 400Gb/s 单端口适配器 *8
电源:2000W(2+2)冗余高效电源 *1
2、A800 工作站常用配置
CPU:Intel 8358P 2.6G 11.2UFI 48M 32C 240W *2
内存:DDR4 3200 64G *32
数据盘:960G 2.5 SATA 6Gb R SSD *2
硬盘:3.84T 2.5-E4x4R SSD *2
网络:双口 10G 光纤网卡(含模块)*1
双口 25G SFP28 无模块光纤网卡(MCX512A-ADAT )*1
GPU:HV HGX A800 8-GPU 8OGB *1
电源:3500W 电源模块*4
其他:25G SFP28 多模光模块 *2
单端口 200G HDR HCA 卡(型号:MCX653105A-HDAT) *4
2GB SAS 12Gb 8 口 RAID 卡 *1
16A 电源线缆国标 1.8m *4
托轨 *1
主板预留 PCIE4.0x16 接口 *4
支持 2 个 M.2 *1
原厂质保 3 年 *1
3、A100 工作站常用配置
CPU:Intel Xeon Platinum 8358P_2.60 GHz_32C 64T_230W *2
RAM:64GB DDR4 RDIMM 服务器内存 *16
SSD1:480GB 2.5 英寸 SATA 固态硬盘 *1
SSD2:3.84TB 2.5 英寸 NVMe 固态硬盘 *2
GPU:NVIDIA TESLA A100 80G SXM *8
网卡 1:100G 双口网卡 IB 迈络思 *2
网卡 2:25G CX5 双口网卡 *1
4、H800 工作站常用配置
CPU:Intel Xeon Platinum 8468 Processor,48C64T,105M Cache 2.1GHz,350W *2
内存 :64GB 3200MHz RECC DDR4 DIMM *32
系统硬盘: intel D7-P5620 3.2T NVMe PCle4.0x4 3DTLCU.2 15mm 3DWPD *4
GPU: NVIDIA Tesla H800 -80GB HBM2 *8
GPU 网络: NVIDIA 900-9x766-003-SQO PCle 1-Port IB 400 OSFP Gen5 *8
存储网络 :双端口 200GbE IB *1
网卡 :25G 网络接口卡 双端口 *1

还未添加个人签名 2021-11-25 加入
深度学习GPU液冷服务器,大数据一体机,图数据库一体机









评论