
现代 CPU 技术发展
介绍
这篇文章主要是介绍CPU技术的发展,包括最近几十年CPU性能提升和半导体工艺发展,当前技术发展方向。希望可以帮助软件开发者理解CPU指令集和组成运行原理、CPU性能提升的现状和瓶颈、CPU技术发展方向会如何影响软件开发/设计的框架和编程思想。
提示:因为是面向软件开发者,所以会忽略掉一些电路设计、制造工艺等底层的硬件知识。同时也不会特别深入的介绍每个知识点,只是提供一个概览。
CPU 指令集和运行原理
当前使用最广泛的指令集是x86、ARM、RISC-V,指令集对于CPU性能和软件开发有多大的影响,指令集的发展方向是什么。现代CPU内部微架构、流水线是如何设计的,为什么CPU的控制单元和缓存相比GPU复杂很多。
CPU 性能提升和未来方向
近些年CPU性能提升遇到了功耗墙的问题导致提升速度放缓,为什么以前的优化技术都遇到了瓶颈,同时当前有哪些新的技术方向用于提高CPU的性能。
CPU 技术方向对软件开发技术的影响
软件最终会在CPU上运行,更好的利用CPU提供的能力进行编程才能带来更好的性能。一部分CPU优化技术是内部微架构调整对软件开发者是透明的,例如时钟频率和IPC的提升。但是另一些优化技术需要软件开发者进行优化,例如多核心、SIMD、DSA等。这些需要软件开发者改造的技术会如何影响编程语言和系统框架的设计,从而影响软件开发者的编程方式。
CPU 结构和原理
计算机结构
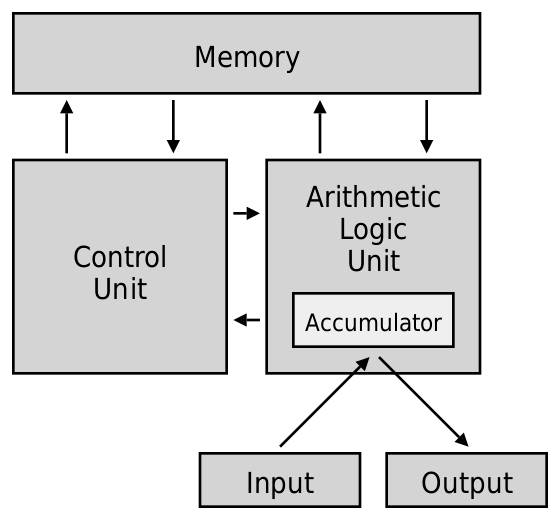
1945 年冯诺依曼提出了一种计算机实现的结构设计,现代的计算机和CPU基本上依然是基于冯诺依曼结构的思想进行实现。冯诺依曼结构定义了计算机的5个组成部分,分别是内存、控制单元、运算单元、输入、输出:
提示:还有一种不同的架构是
哈佛架构,它是一种程序指令和数据分开的计算机结构。现在L1缓存中就是使用哈佛架构的思想将指令和数据缓存分开存储。
CPU 结构
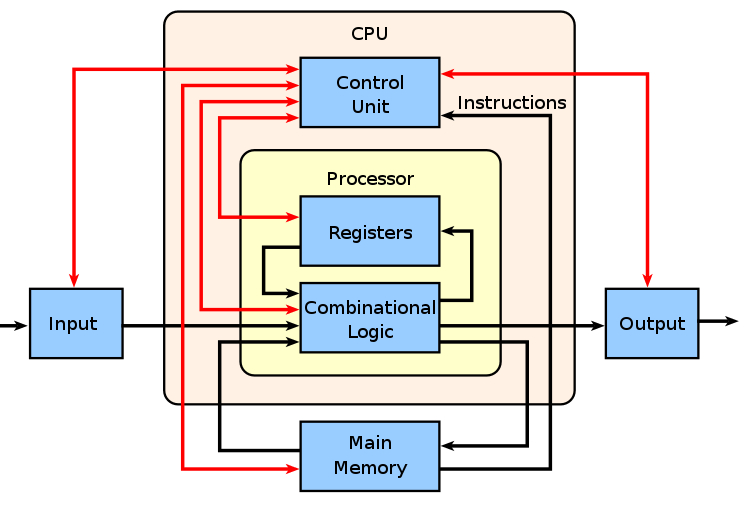
现代CPU虽然使用冯诺依曼架构思想进行设计,但是经过几十年技术的发展非常复杂。因为内存不属于CPU内部结构,现代CPU主要分为4个组成部分,分别是高速缓存、控制单元、运算单元、寄存器。这里先简单介绍一下各个组成部分的功能,后面流水线实现的部分会更详细的介绍。
高速缓存
高速缓存将内存中更频繁使用的程序指令和数据保存在高速缓存中,避免每次都从内存读取降低数据读写延迟。
多级缓存- 现代CPU通常有2-3级缓存,离 CPU 更近的缓存速度更快但是容量更低。
控制单元
控制单元是CPU中最复杂的部分,负责调度和协调其他部分进行运行。调度流水线执行、异常处理等。
流水线调度- 分支预测、高速缓存读写、指令读取、指令解码、指令调度执行、乱序执行、指令发射、更新寄存器
异常处理- 处理 CPU 运行时的各种异常
运算单元
运算单元包含大量的运算器执行计算任务,包括逻辑运算、分支、内存读写单元。
ALU- 算数逻辑单元负责整数加减乘除和位运算
FPU- 浮点单元负责浮点数运算
Branch- 分支单元用于分支判断,当 CPU 支持分支预测时还需要更新分支预测缓存和分支预测错误回滚执行
SIMD- 向量单元负责向量运算
内存读写- 内存单元负责内存读写,从缓存中读取数据或将数据写回缓存
寄存器
寄存器用于保持运行时的临时数据和CPU自身的一些状态值。
通用寄存器- 用于存储临时数据,局部变量/函数参数/返回值等数据
PC- 程序计数器存储下一条指令的地址
IP- 指令指针用于存储当前执行的指令地址
SP- 堆栈指针用于存储栈的地址
指令集架构
ISA(指令集架构)是一种处理器基本功能和指令集架构规范。它定义了CPU硬件可以执行的所有操作指令,指令的编解码格式、指令类型、寄存器、内存寻址、异常处理、权限级别等内容。编译器和CPU选择一种指令集规范作为标准进行实现,这样可以保证任意符合指令集规范编译的代码都可以相同指令集规范的 CPU 上正常运行。ISA主要有指令集、寄存器、内存模型、异常中断处理等规范定义。
指令集架构规范组成
指令集- 支持的操作指令、指令的编解码格式、指令长度
寄存器- 支持的寄存器类型、寄存器数量
内存模型- 支持的内存访问方式、内存寻址方式、内存一致性规则
异常/中断处理- 定义了处理器如何处理异常和终端事件
指令集
指令集定义了处理器可以执行的所有操作指令和指令的编解码格式。目前常见的指令集主要分为两种类型,复杂指令集和精简指令集。复杂指令集CISC主要是以x86为代表,精简指令集RISC主要是以ARM/RISC-V为代表。
x86
x86指令集架构最早使用在Intel在1978年推出8086处理器,指令集专利由Intel和AMD拥有。目前主要是在PC/笔记本和服务器市场使用,x86的优势在于软件生态/兼容性和高性能,劣势在高能耗和开放性:

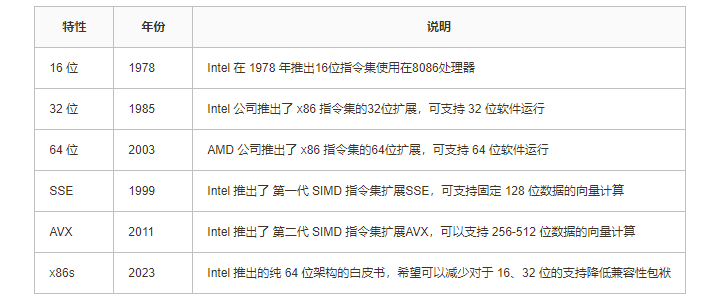
x86 指令集发展
x86包含多个扩展指令集,指令长度至少8位可变长度。以下是x86指令集的一些重要版本更新:
ARM
ARM指令集架构是英国 ARM 公司开发的一种RISC指令集架构,指令集专利由ARM公司拥有。ARM诞生于1980年代,当时的处理器都是基于CISC设计复杂度高、功耗大,ARM公司希望使用精简的指令集实现低功耗和高性能,可以应用在嵌入式设备和移动设备中。
因为ARM有非常好的能效优势,目前主要是使用在追求功耗比的嵌入式和移动设备。ARM设备几乎占据所有的手机和Pad市场。在笔记本市场因为苹果切换到ARM,同时高通和INVIDIA开始布局ARM桌面端芯片未来也会推动ARM份额的提升,目前已经占据了15%+的笔记本市场份额。近年ARM性能和芯片设计水平逐渐提高,ARM在服务器市场的份额逐渐提升。
不过ARM也有和x86同样的问题就是开放性,导致ARM受到了RISC-V的挑战。ARM指令集专利属于ARM公司,同时ARM公司对使用指令集会有一些限制。

ARM 指令集发展
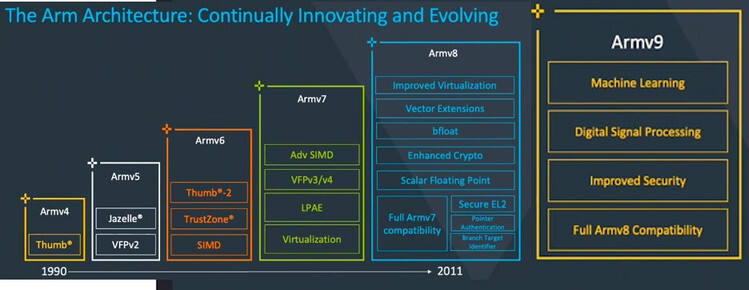
ARM包含多个扩展指令集,指令长度为固定32位。以下是ARM的一些重要版本更新:

RISC-V
RISC-V架构是2010年由加州大学伯克利分校发起的开源RISC指令集架构标准。RISC-V有以下几个优势:
精简设计- 设计非常简单,相比x86和ARM指令集设计更加精简,降低了复杂度和指令数量。
模块化设计- 采用模块化设计思想。提供精简的基础指令集实现基础能力,其它包括浮点、SIMD、原子操作、位运算等指令都是通过扩展指令集提供。芯片设计厂商可以基于自身需求将各种指令集扩展模块进行组合应用到不同的场景。
开源-x86/ARM都需要授权才能使用,RISC-V完全开源可以免费使用不用担心版权和专利费的问题。
RISC-V的优势在于更先进的设计和开源,劣势在软件生态和芯片厂商的设计能力还需要进步:
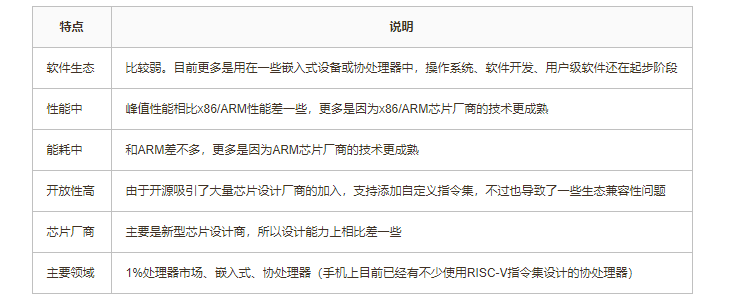
RISC-V 指令集
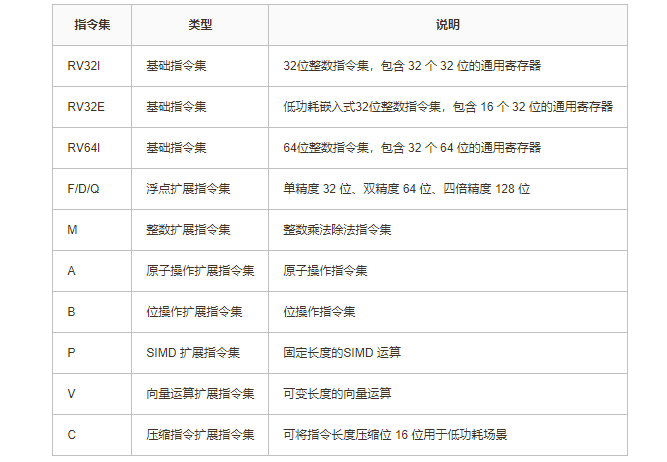
RISC-V有 3 个基础指令集和多个扩展指令集,指令长度为固定32位。以下是RISI-V常见的指令集:
RISC-V 寄存器

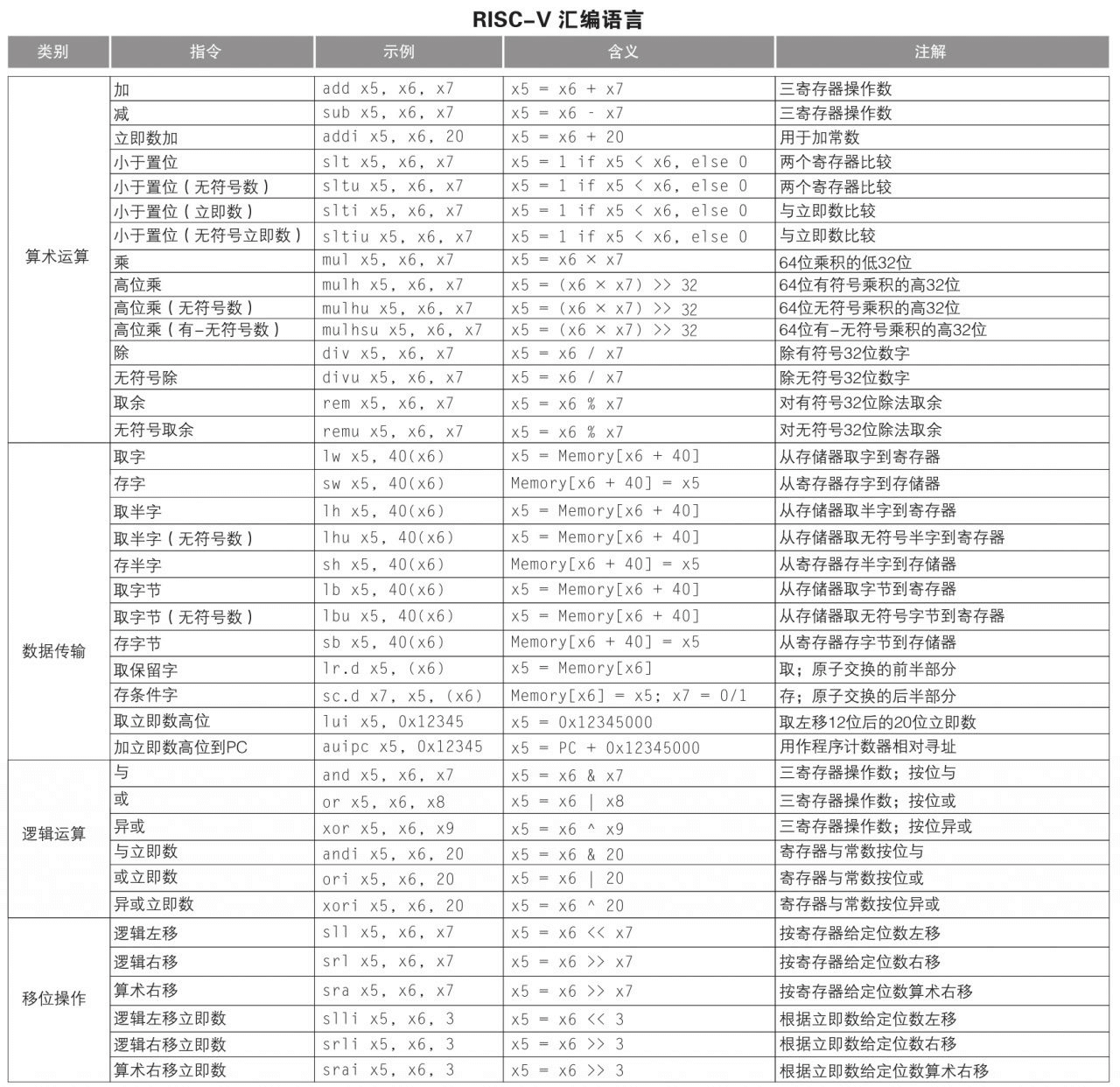
RISC-V 汇编语言

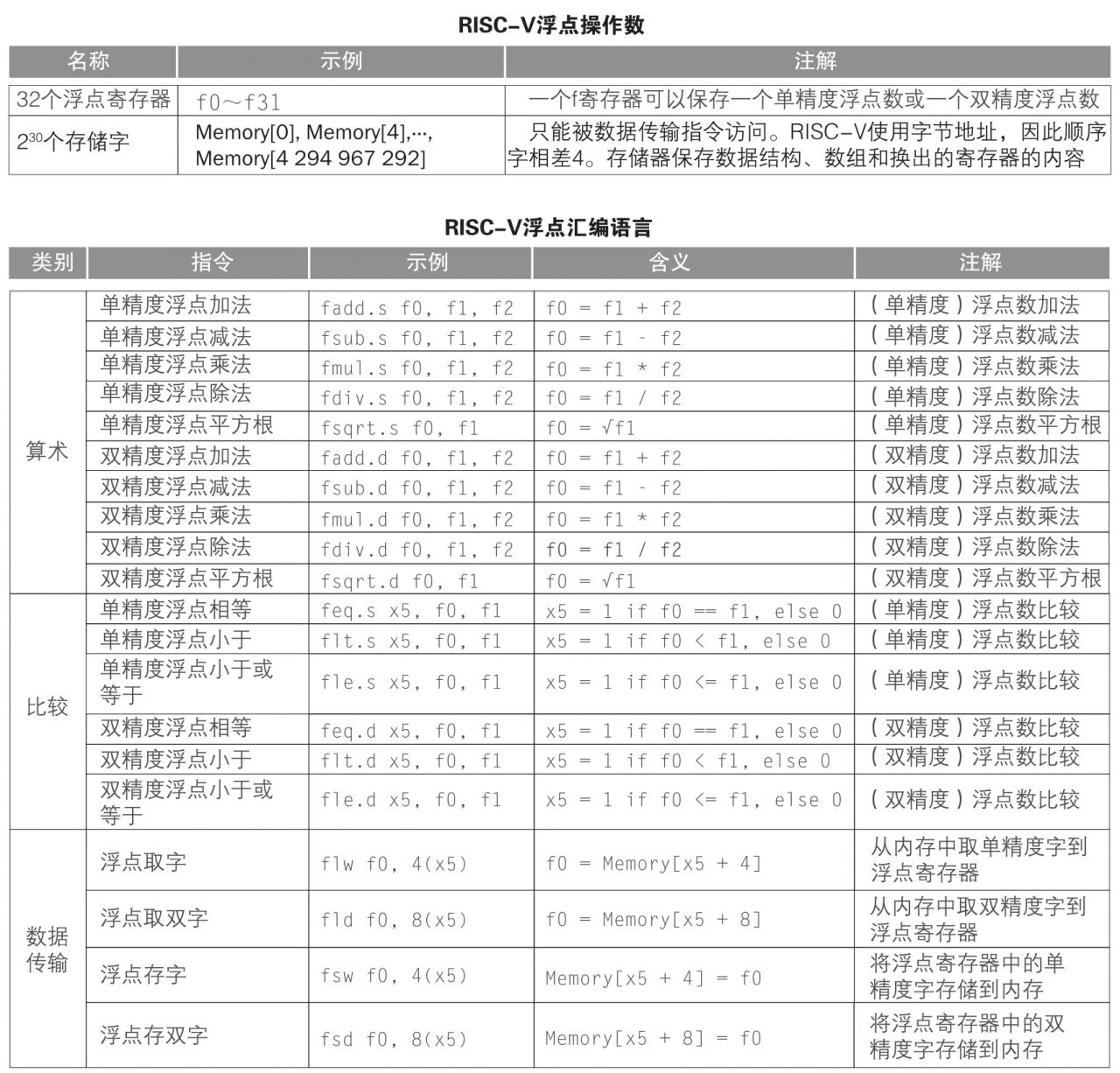
指令编码格式
指令集规范定义了指令的二进制格式。以ARM指令集为例,编译器在编译时按照指令集规范将每一个汇编指令编码成32位的二进制指令,CPU在运行时通过解码器按照指令集规范将二进制指令解码成特定的指令进行执行。
x86指令集更复杂,ARM和RISC-V更精简。x86使用可变长度指令,至少8位+,同时x86支持更多的内存寻址模式。ARM使用固定32位指令,至少少数几种内存寻址模式。
ARM 指令编码格式

指令集对比
复杂指令集和精简指令集
x86是复杂指令集,主要是因为x86指令数量多、复杂指令、内存寻址方式多、指令长度不同等原因,导致硬件设计实现更复杂。使用复杂指令集主要是行业早期技术限制和兼容性原因导致的:

以上这些原因导致早期使用CSIC将更多的复杂性转移到CPU处理,导致CPU设计复杂成本高。之后随着半导体技术的发展可以集成更多晶体管和内存以及编译器技术的发展可以更好的生成机器代码,1979年开始行业逐渐发现CISC有以下这些缺点:
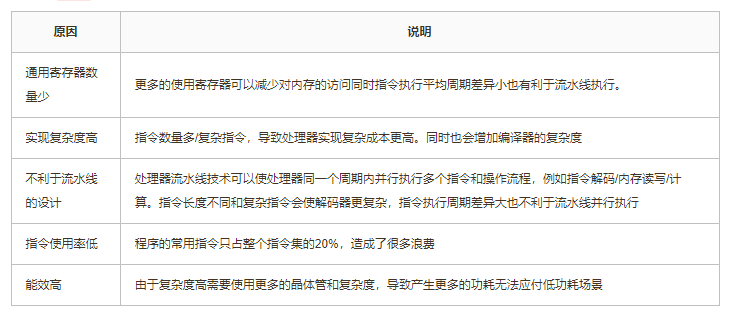
以上这些缺点推动了新的指令集都使用RISC设计更有利于提高处理器的性能和能效。但是Intel因为兼容性和软件生态的考虑选择继续使用x86。经过这些年处理器技术的发展,x86也做了非常多的技术改进提高性能,不过由于兼容性约束指令集很难缓慢的进行改进。
x86的一些技术改进:
降低指令复杂度- 持续减少对一些老旧指令的兼容减少指令数量
内部使用精简指令集的设计- 由于半导体工艺的发展芯片可以集成更多晶体管提高性能。增加了通用寄存器的数量、内部将复杂指令解码为多条简单指令用于流水线执行。
更多技术支持- 提供了很多基于Intel平台的指令集扩展和开发框架,操作系统和软件开发者可以利用这些技术提高性能。
指令差异
以下面的汇编为例。RISC指令集必须将内存数据加载到寄存器以后才能计算,CISC指令集可以支持指令内存寻址。所以RISC会生成更多的指令数量。
CISC
RISC
指令集架构实现对比
因为ARM和RISC-V都是精简指令集设计上很接近,所以使用x86-64和ARM64来对比实现上的一些细节。

其他
CPU 遇到不支持的指令如何处理
指令集通常包含基础指令集和扩展指令集,基础指令集是使用最频繁的指令,扩展指令集是用于一些特定场景的指令集,例如64位和SIMD支持。通常CPU核心只会支持一部分扩展指令集,因为支持更多指令可能会增加额外的计算单元和寄存器,这会导致耗费更多的晶体管增加成本和功耗。同时一些使用频率低/成本高的扩展指令只用在部分追求高性能的场景。以下是两种情况:
不支持部分扩展指令集:Intel酷睿 12 系列开始不再支持AVX-512向量扩展,只有在更高级的至强处理器才支持。AVX-512需要多个512位寄存器,多个支持512位向量运算的计算单元。移除AVX-512指令扩展可以节省晶体管数量降低功耗或者将这些晶体管用于其他能力。
大小核差异化处理:高通骁龙 8gen2 处理器,大核只支持64位,小核支持32/64位。CPU继续支持 32 位应用运行,32 位应用可以继续在小核上运行。但是同时支持 32/64 位也会增加CPU的复杂度增加成本和功耗,所以在8gen3处理器中已经完全移除了对 32 位的支持。
当CPU遇到不支持的指令如何处理,通常CPU会采用几种处理方式:
抛出异常- 直接抛出异常停止执行。
模拟执行- 解码成更简单的指令进行模拟执行,但是可能会导致性能降低。
x86 和 ARM 的性能
当前总体来看能耗比ARM更优秀,高性能场景x86使用率更高。但是指令集对于CPU性能和功耗的影响会越来越小,制造工艺、使用场景、兼容性等因素也会导致x86和ARM平台的性能差异。

随着ARM逐渐开始在高性能电脑和处理器市场占据更多的份额,也在不断的提升CPU性能。x86逐渐减少兼容性包袱同时也更加关注能效比。可能未来我们可以更清晰的理解指令集架构导致的性能和能耗差异。
小结
现代指令集架构也在互相借鉴,指令集之间的差异越来越小。x86CPU 内部会将复杂指令解码成多个简单指令执行有利于超标量 CPU 指令级并行,ARM也添加更多的指令以支持更多场景,RISC-V的设计者认为ARMv8借鉴了很多RISC-V的设计。
二进制翻译技术的使用也越来越多。MacOS提供Rosetta 2软件支持x86程序在ARM芯片上运行,虽然将x86指令转换成ARM指令会导致一定的性能损耗和兼容性问题(部分指令不支持),但是可以帮助大部分x86程序在ARM平台上正常运行。同时Windows On ARM也支持x86程序在ARM芯片上仿真执行。
同时从指令集版本升级特性也能看出,近些年指令集的变更主要是在提高向量运算指令应对越来越多的AI和多媒体场景,其他指令改进很少。
处理器技术发展
处理器技术的发展主要是提高处理器的运行性能。对于如何提高处理器的性能,我们先用一个简单的公式来度量处理器的性能:
指令数- 程序执行需要的指令总数
CPI- 处理器平均每个时钟周期可以执行的指令数量(多核心也会增加 CPI)
时钟频率- 处理器一秒钟可以执行的周期次数
因为指令数量无法控制,所以只能通过提高CPI和时钟频率来提升处理器的性能。接下来我们来了解处理器通过哪些技术来提高CPI和时钟频率。
半导体工艺、时钟频率、能耗、晶体管数量
功耗、时钟频率、性能
当前提升处理器性能遇到的最大的挑战就是功耗墙。电流通过晶体管会带来热量,太高的功耗导致处理器温度过高无法运行,同时移动设备电池技术发展也非常缓慢。我们先来看看处理器动态功耗计算公式,即处理器晶体管开关切换过程中产生的能耗:
提示:这里只是一种简单的功耗工时,还需要考虑半导体制造工艺和漏电造成的影响。
从功耗公式可以看出功耗和晶体管数量、电容、电压、时钟频率成正比,增加晶体管数量和提高频率都会增加处理器的功耗。
早期半导体工艺发展通过不断降低晶体管的尺寸可以减少电容的大小、以及降低晶体管开关切换时间,芯片可以使用更低的电压运行,通常每次工艺提升可以使电压降低15%。处理器制造商可以不断在芯片上增加晶体管数量以及提高时钟频率,同时控制功耗的增长速度。
半导体工艺发展带来的提升
增加晶体管数量- 在同样尺寸的芯片中集成更多数量的晶体管,这些增加的晶体管可以用于增加缓存大小、控制单元等模块提高处理器的性能。同时也推动了 SOC 芯片的发展,在芯片内集成多核心、GPU 等单元。
提高时钟频率- 提高时钟频率可以使处理器执行的更快
降低电压- 使用更低的电压进行运行,在同样的性能下可以降低能耗。同时更好的晶体管设计可以降低漏电。
技术定律
登纳德缩放定律:1974 年罗伯特·登纳德发现,由于晶体管尺寸变小,在固定的芯片面积上增加晶体管的数量不会增加功耗。
摩尔定律:1965 年戈登·摩尔预测,由于晶体管尺寸逐渐变小,同样面积的芯片上晶体管数量每隔一年翻一番,1975 年改为每隔两年翻一番。
功耗墙
从2004年开始登纳德缩放定律失效。缩短晶体管栅长本来能降低电压、提高晶体管开关频率,但在栅长缩短到65nm左右时,晶体管开关频率增加导致芯片功耗和温度急剧上升。同时,栅长缩短导致漏电流急剧增加,这些电能也会转化为热量。目前大概40%的功耗是由于漏电导致的,即使晶体管处于关闭状态也会增加漏电能耗。早期每一代新工艺至少可以让晶体管栅长缩小30%,虽然现在半导体制造商继续使用现有工艺节点乘以0.7作为下一代的节点名称,例如 10nm、7nm、5nm、3nm,然而栅长缩小尺寸已远远达不到这个要求,需要二十年左右才能使晶体管数量翻一番。同时每一代新技术节点的制造成本越来越高,每代制造成本相比前一代高几倍。
小结
由于功耗墙的限制,相同电压和电容条件下增加晶体管数量提高核心数量相比增加时钟频率带来的功耗影响更小。同时晶体管尺寸减少速度变缓,增加晶体管数量可能需要增加芯片的面积,但是增加芯片的面积会导致生产良率更低成本更高。处理器设计不再追求单核时钟周期快速提升,朝着多核心方向发展通过增加核心数提高指令吞吐量并行执行提高性能。
提示:以功耗公式来计算,
1GHz=10 亿。Intel 2006 年推出的Core 2 E6700处理器时钟频率2.66 GHz、2个核心、2.9亿个晶体管。所以增加 1 个核心带来的功耗提高比增加时钟频率1GHz低。
CPU 能效曲线
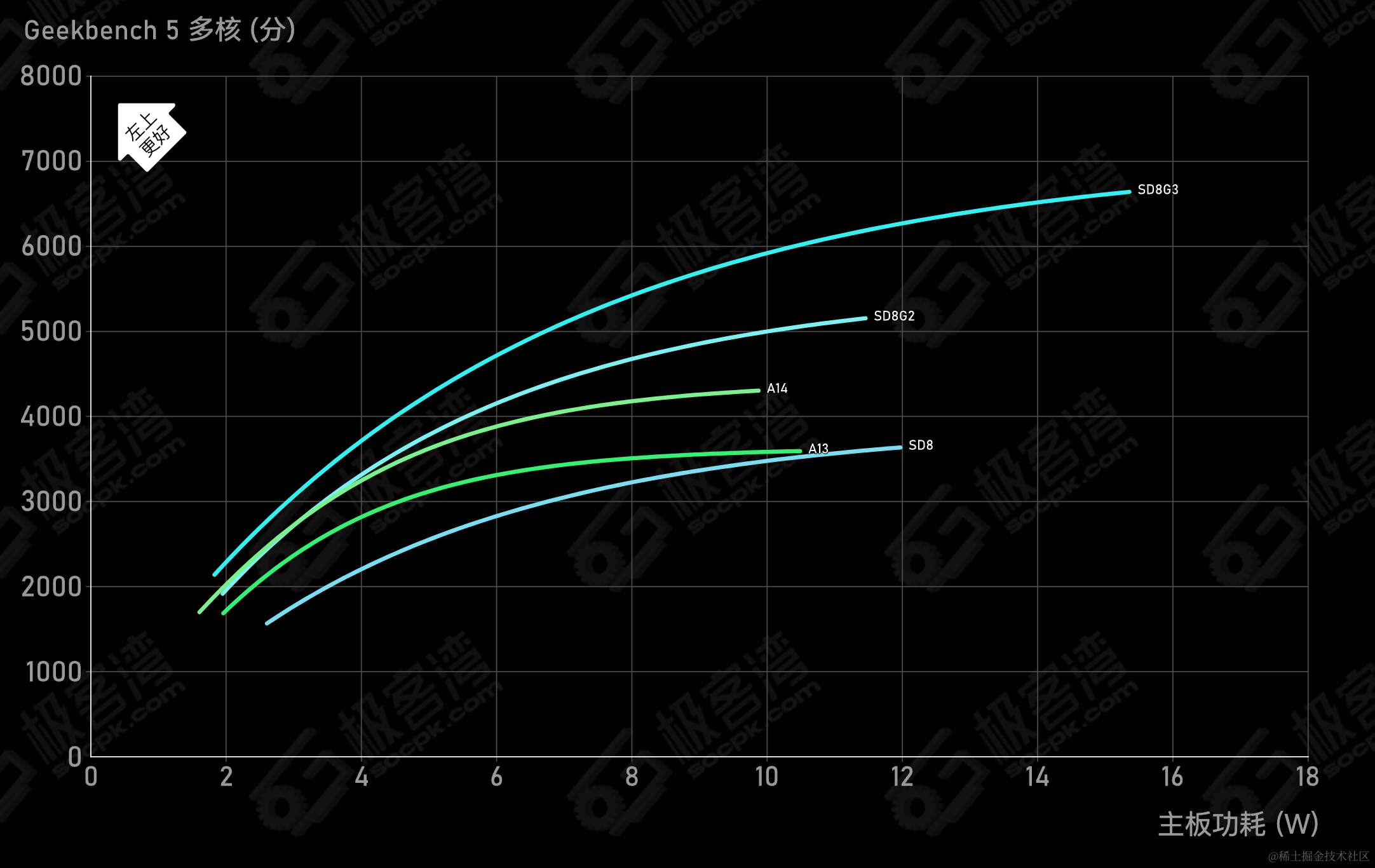
更高的性能需要更高的
时钟频率和电压运行,导致能效急剧提升
时钟频率发展

处理器时钟频率提升幅度逐渐放缓
半导体工艺发展
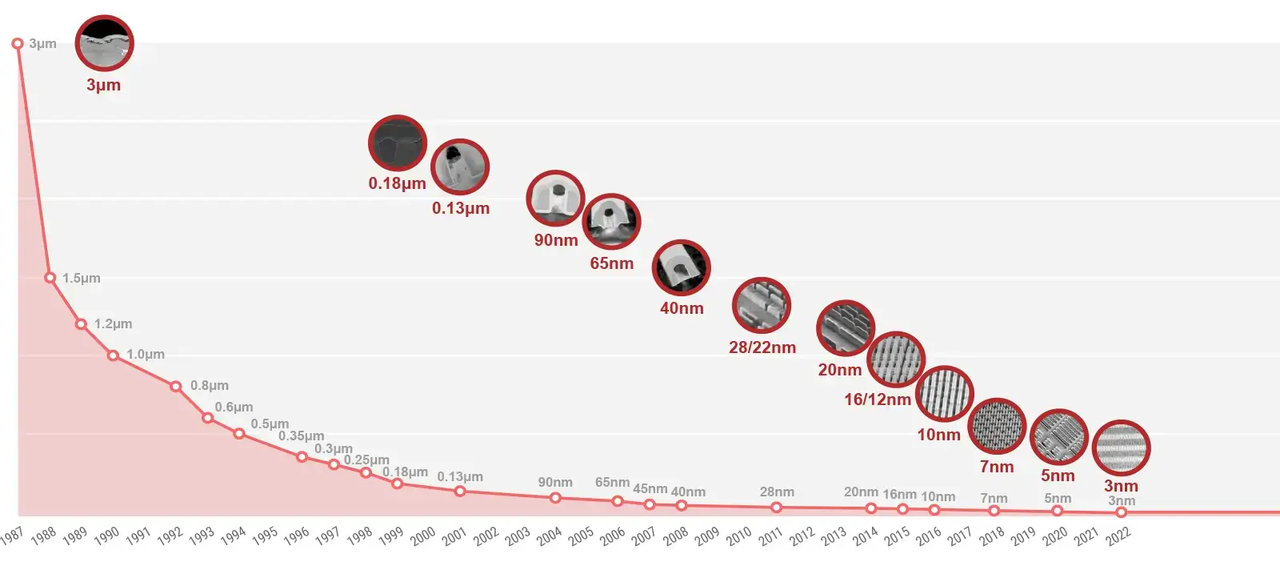
半导体工艺发展主要是依赖光刻技术进步以及更优秀的晶体管设计,下面简单列一下最近10年半导体工艺发展的重要节点:
32nm-2010年Intel量产了首批32nm处理器第二代酷睿处理器,使用了林本坚发明的沉浸式光刻技术。
22nm-2011年Intel首先在 22 纳米工艺节点上使用了胡正明发明的FinFET(鳍式场效晶体管)晶体管。FinFET减少50%+漏电并提高了性能。目前使用在22nm节点以下的半导体芯片中。
5nm-2020年台积电使用ASML的新一代EUV光刻机,为苹果生产了第一个5nm处理器A14。相比7nm工艺密度提高80%、速度提高15、能耗降低30%。
3nm-2022年台积电开始量产3nm芯片。
2nm-2025年台积电计划开始量产2nm芯片,使用GAAFET(围栅场效晶体管)代替FinFET晶体管。GAAFET可以降低漏电、降低尺寸和提高性能。
FinFET、GAAFET
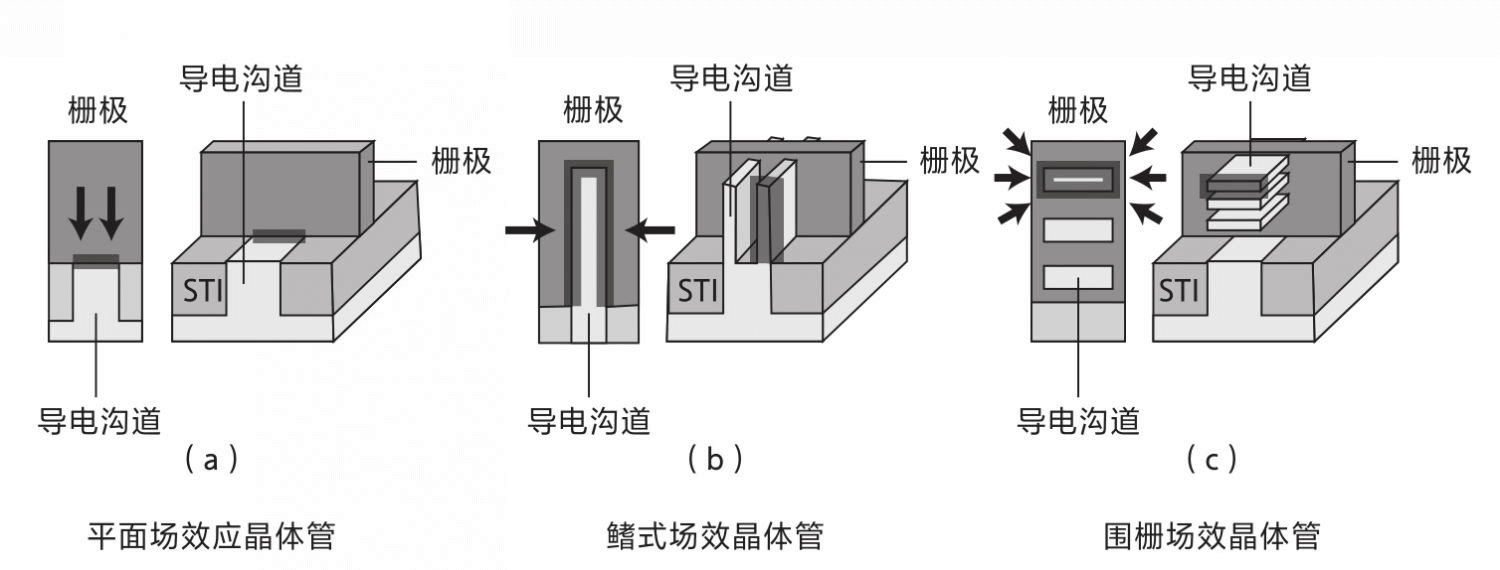
晶体管栅长发展
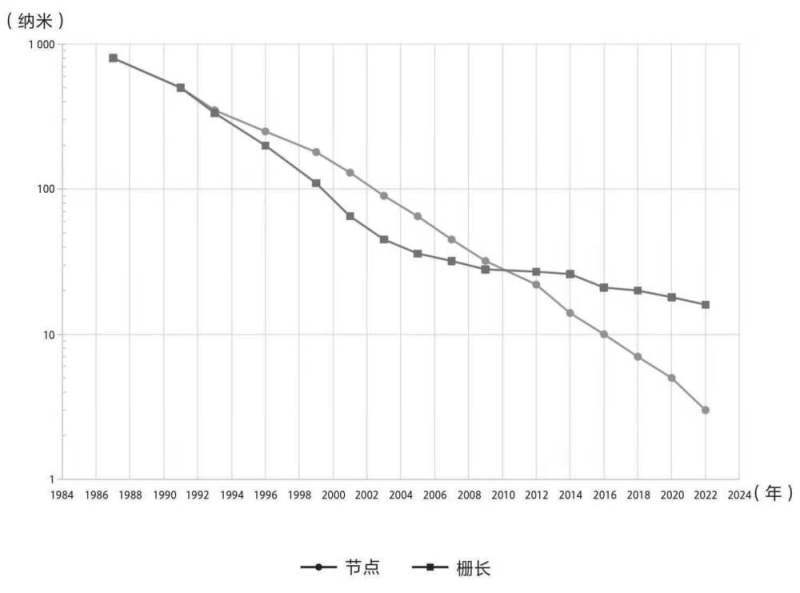
虽然晶体管制造技术节点在不断降低,但是栅长缩小速度越来越慢
指令级并行:微架构和 IPC 提升
IPC提升主要是提高指令的吞吐量,通过优化处理器流水线的微架构,提高一个周期可以执行的指令数量。
流水线介绍
在理解流水线之前我们先看简单了解一下程序执行的步骤。通常一个程序指令可能会经历五个执行步骤:
读取指令- 根据PC寄存器的地址,从内存中读取下一条执行指令到CPU中。
解码指令- 将二进制指令解码成具体需要执行的指令,复杂指令可能需要解码为多条指令。
执行指令- 调用执行单元进行运算。
读写内存数据- 从内存中读写计算的数据。
写寄存器- 将运算完的数据写会寄存器。
早期的CPU设计只能按照程序指令的顺序进行执行,每个指令都需要经过这五个执行步骤。如果每个步骤需要200ps的话,一个时钟周期需要1000ps并且只能执行1个指令。3个指令需要3000ps。之后就诞生了流水线技术,通过在一个时钟周期内执行多条不同指令的不同步骤,提高流水线的吞吐量实现指令集并行。虽然不能降低单个指令的耗时,但是可以降低多条指令的总耗时。
五级流水线优化执行

理想情况下三条指令在每个周期都执行多个不同的步骤,降低了三条执行执行的总耗时
一个时钟周期的耗时取决于这个周期内最长耗时的操作
现代流水线设计
现代CPU核心中的流水线设计很复杂,也会导致CPU中的控制单元占比很大。现代CPU流水线设计主要为了让运算单元每个周期都可以满负载执行,通常有10级流水线,加入了更多的功能模块用于增加流水线的吞吐量提高IPC。流水线通常分为前端和后端,前端主要负责读取指令和解码指令,后端主要负责调度发射指令和执行指令。接下来我们通过下图的流水线示例来了解现代CPU中的流水线设计,参考了当前主流的CPU性能核心的微架构实现。
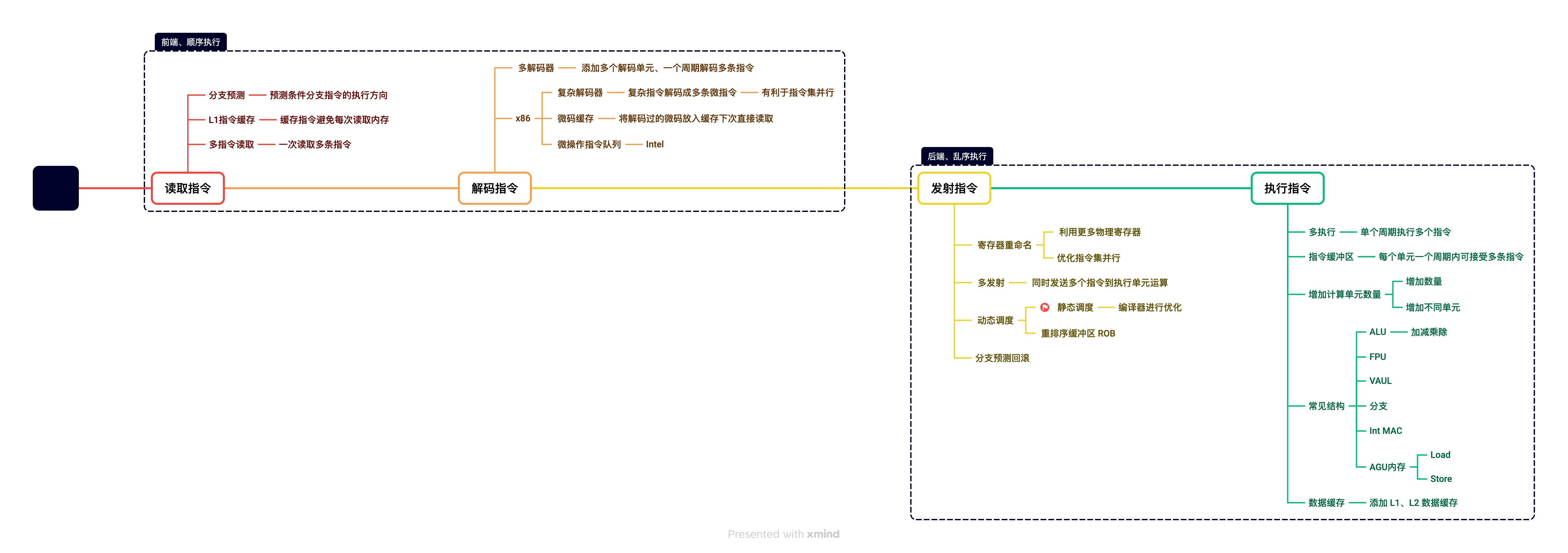
提示:
Intel最早在2004年推出了30+级流水线的CPU,但是流水线数量太长会导致微架构设计非常复杂,同时分支预测失败惩罚更高。这些原因导致目前CPU通常使用10级左右的流水线。
读取指令
读取指令将内存中的指令读取到CPU中的指令缓冲区中,相关的优化是为了降低读取指令延迟和读取更多指令到CPU中,提高流水线的吞吐量。
多指令读取
由于从内存中读取程序指令延迟比较长,现代CPU会按照PC寄存器的地址一次性读取多条后面需要执行的程序指令CPU中,减少后续流水线空闲时间。将指令放在指令缓冲区中,等待解码器的使用。
分支预测
由于一次性读取多条程序指令,会遇到一个问题就是当分支判断的时候由于分支还未执行无法知道后续分支执行的方向。通过添加分支预测单元提前预测分支可能的执行方向读取后续需要执行的程序指令。
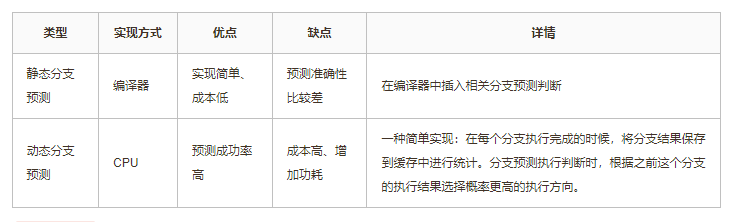
分支预测分为动态分支预测和静态分支预测。高性能CPU核心都会使用动态分支预测的方式,分支预测成功率可以达到80%-90%。分支预测错误会导致分支预测惩罚需要回滚错误分支的指令执行,通常会导致10+个周期的流水线惩罚。
静态分支预测和动态分支预测
L1 指令缓存
为了避免每次从内存中读取指令延迟比较长,将读取过的指令存入缓存中。经常使用的指令就可以直接从缓存中读取,但是L1缓存由于读取性能的限制容量有限,通常只有几十 KB,在缓存缺失的时候可能会从内存中读取指令导致流水线卡顿。
TLB 缓存
由于CPU访问内存时,会将程序空间的虚拟地址映射为物理内存地址,这个映射过程有一定的耗时。通过加入TLB缓冲区将转换后的映射加入到缓存中,下次读取程序指令地址时就可以直接读取无需再进行地址转换。
解码指令
解码指令将指令缓冲区中的指令按照顺序微码为多个微操作放入微操作队列中,相关的优化是为了降低解码耗时和同时解码更多的指令。
预解码
将指令缓冲区中几十个字节的指令解析成多个单独的程序指令,后续再发送到解码器提高解码效率。特别是对于x86指令由于指令长度不同,预解码阶段会更加复杂。
多解码器
解码器将程序指令解码成CPU微操作指令。现代CPU核心中通常会添加多个解码器用于提高解码性能,通常会有3-10个解码器单个时钟周期可以解码多条指令。
x86平台的复杂指令可能会生成多条微操作,所以x86处理器通常包含一个复杂指令解码器,专门用于解码复杂指令。x86处理器的解码器通常比ARM更少,A17 Pro的高性能核有9个解码器,Intel i9 14900K的高性能核心只有6个解码器其中包含1个复杂指令解码器。
微指令缓存
x86平台由于复杂指令的存在,解码指令效率更低。通常会加入额外的微指令缓存,将已经解码的指令微操作映射保存到缓存中,下次可以直接读取无需再解码。
发射指令
多发射
一个周期内发射多个指令到运算单元,提高运算单元的吞吐量。有两种实现多发射的调度方式,静态调度和动态调度。现代CPU高性能核心使用动态调度一个周期可以发射6-10个指令。
静态调度和动态调度

动态调度
多发射调度主要是为了提高指令发射的效率,同一个时钟周期发射出更多的指令到计算单元,让计算单元持续处于高负载运算状态中提高吞吐量。一个时钟周期内将不同的指令发射到不同的计算单元,但是需要解决流水线冒险带来的挑战,通常存在三种类型的流水线冒险:
数据冒险- 当前指令必须依赖前面一条正在执行的指令的计算结果,例如依赖前一条加法指令的计算结果,需要等待前一个指令将结果写入到寄存器中。
控制冒险- 当前指令必须依赖前面一条正在执行的指令的分支判断结果,通常使用分支预测方式进行解决。
结构冒险- 当前指令因为硬件资源限制导致无法执行,例如多个指令需要同时使用同一个寄存器,多个指令需要同时使用某个加法计算单元。
流水线调度过程中需要解决流水线冒险的问题,现代CPU微架构设计会通过ROB(重排序缓冲区)对执行进行动态调度,ROB越大可以保存的指令数越多性能越好:
寄存器重命名- 现代CPU内核中通常有更多的物理寄存器数量,超过指令集中定义的寄存器数量。需要对寄存器进行重命名放置到不同的寄存器中提高指令级并行,例如两条指令都使用同一个寄存器可以放置到不同的寄存器中进行处理。
指令重排序- 因为需要同时发射多条指令提高吞吐量,所以需要对指令的执行顺序进行调整导致乱序执行。但是会保证最终的执行结果符合原本的预期。
数据预读取- 提前将后面程序指令需要使用的内存数据加载到缓存中,避免缓存缺失导致的延时。
分支预测惩罚- 流水线执行过程中会将分支预测相关的指令执行结果暂时保存,等待最终分支预测正确时才会执行完成。如果分支预测错误需要回滚这些错误预测的指令。
指令发射- 将对应的指令发射到计算单元
执行指令
多执行
一个时钟周期可以并行执行不同的计算单元,只要当前计算单元有空闲。
计算单元缓冲区
将指令和指令数据发射到计算单元的缓冲区中等待执行,当计算单元空闲时即可开始执行。
增加计算单元
增加更多的整数运算、浮点运算、分支判断和内存读写单元数量,一个时钟周期可以执行更多的运算和内存读写操作。现代CPU性能核心通常有10+个算数单元和多个内存加载单元。
L1/L2 数据缓存
通过L1、L2缓存读取内存数据,将常用的数据保存到高速缓存中,提高下一次读取的性能。
主流 CPU 核心的微架构设计
现代CPU通常使用大小核设计,性能核有更复杂的流水线设计性能更好,能效核流水线设计更简单性能会差一些。
Intel
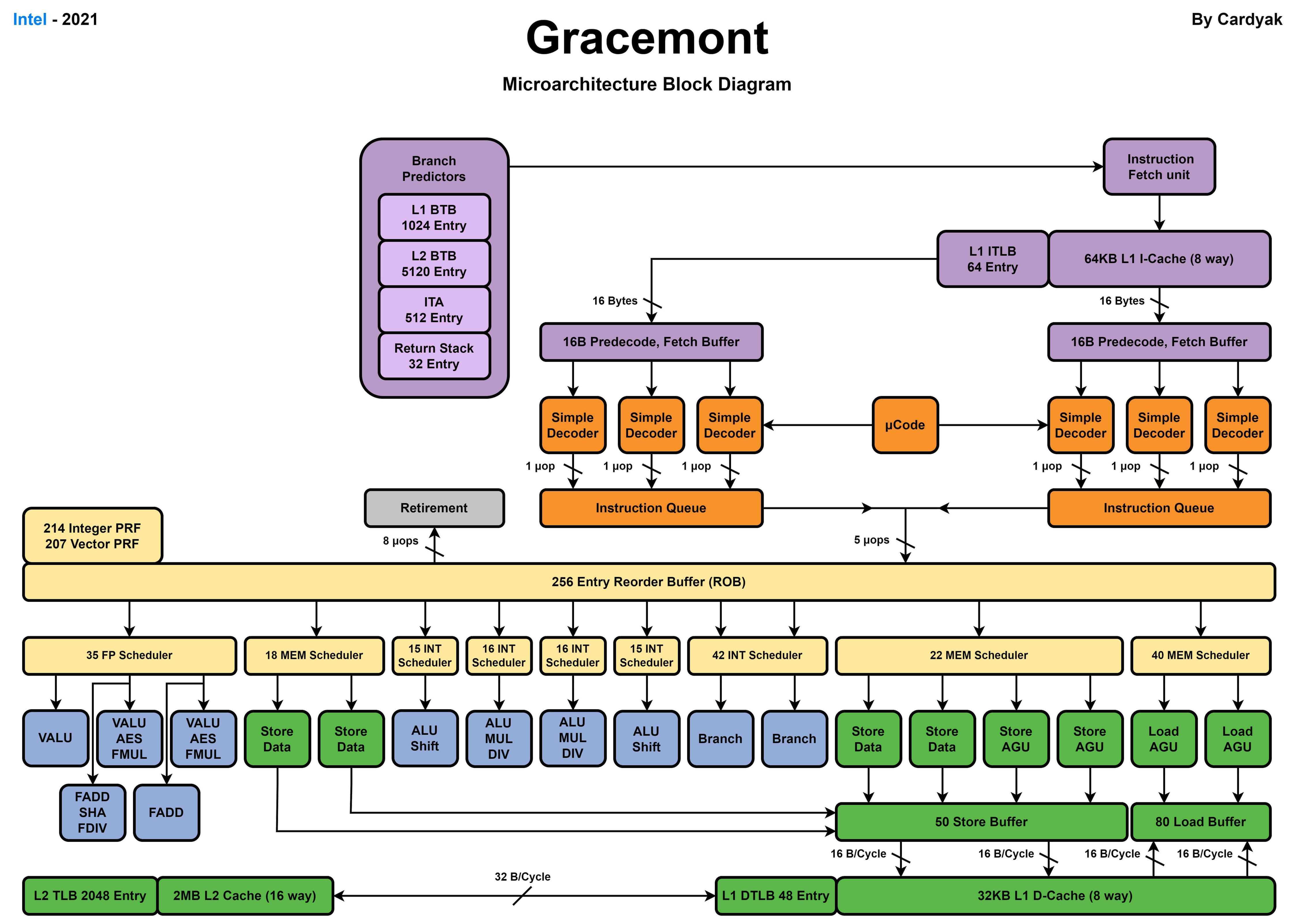
Intel最新的桌面级别处理器Core i9 14900K使用了8个Raptor Cove性能核和16个Gracemont能效核。
Raptor Cove 性能核
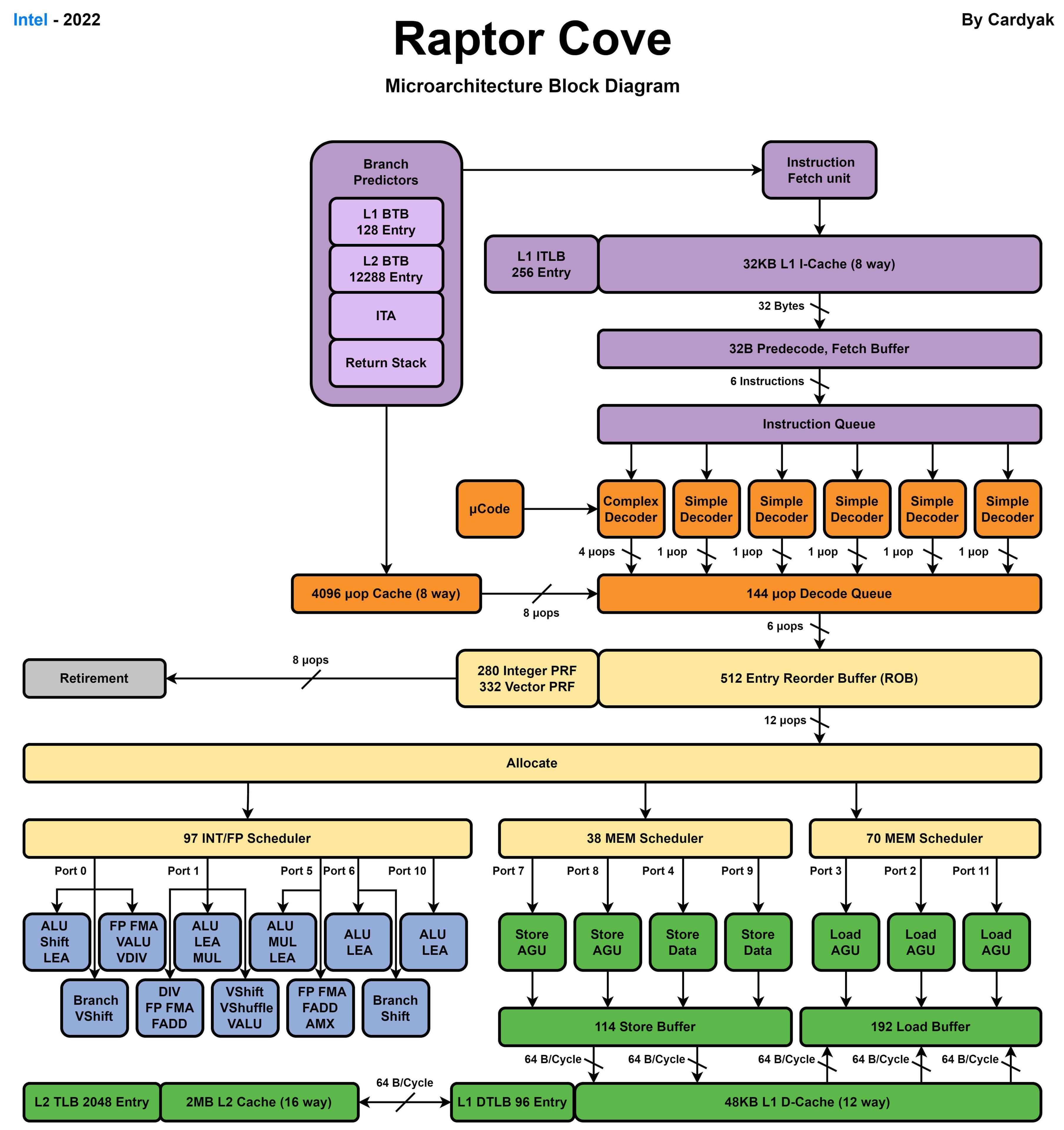
Gracemont 能效核
Apple
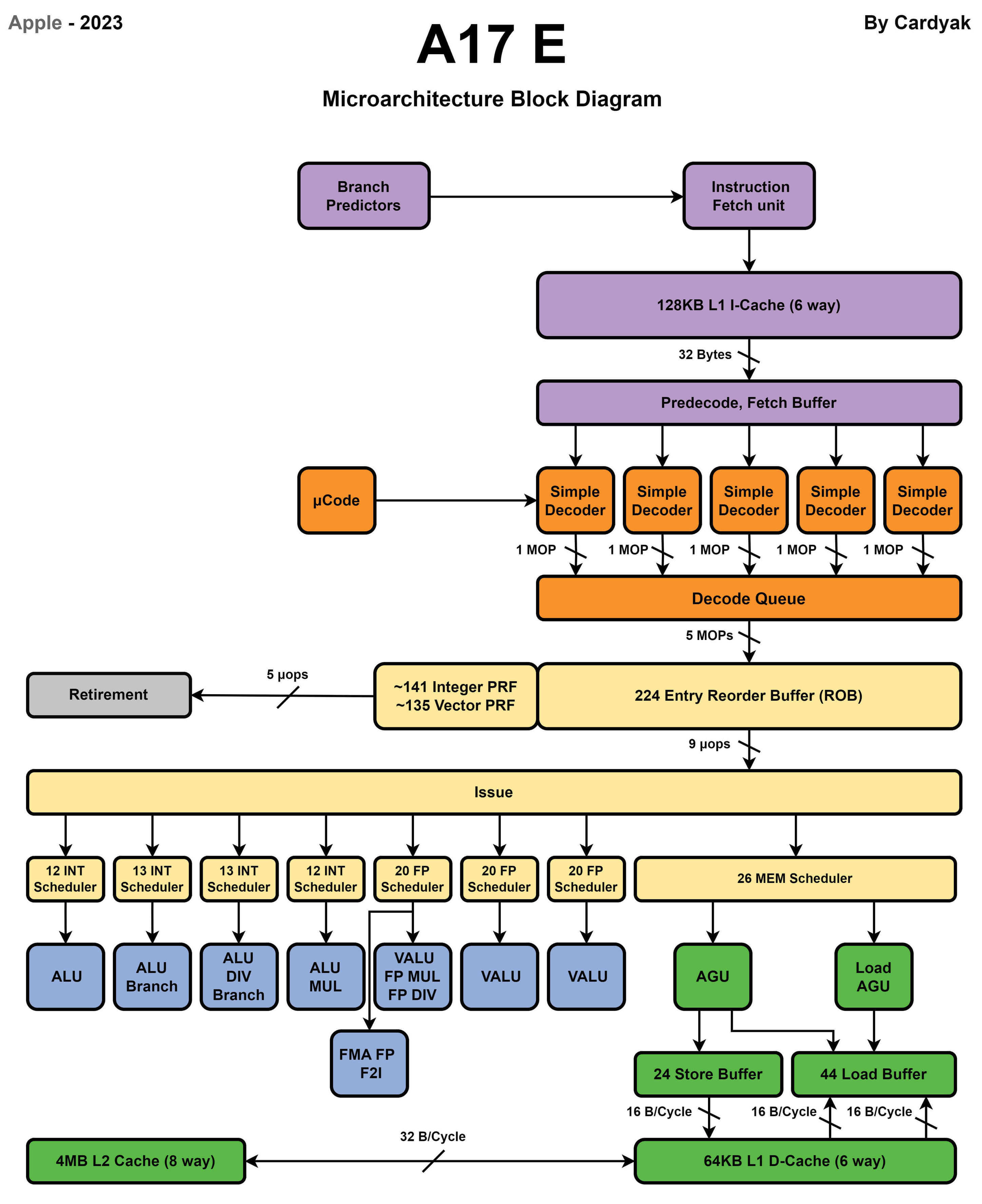
Apple最新的A17 Pro处理器使用了2个性能核和4个能效核。
性能核
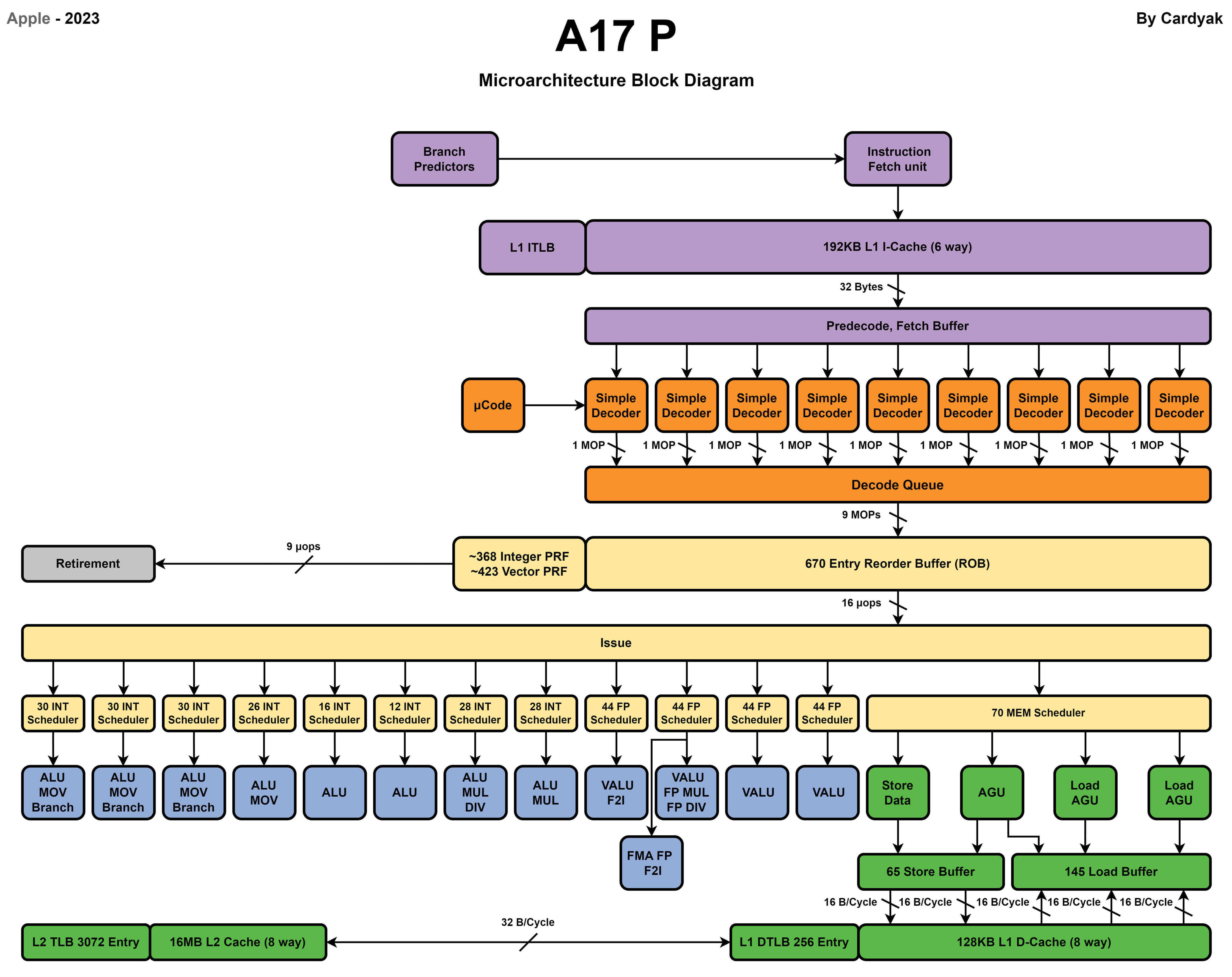
能效核
ARM
高通最新的8 Gen 3处理器使用了1个X4超大核,5个A710性能核,2个A520能效核。
X4 超大核
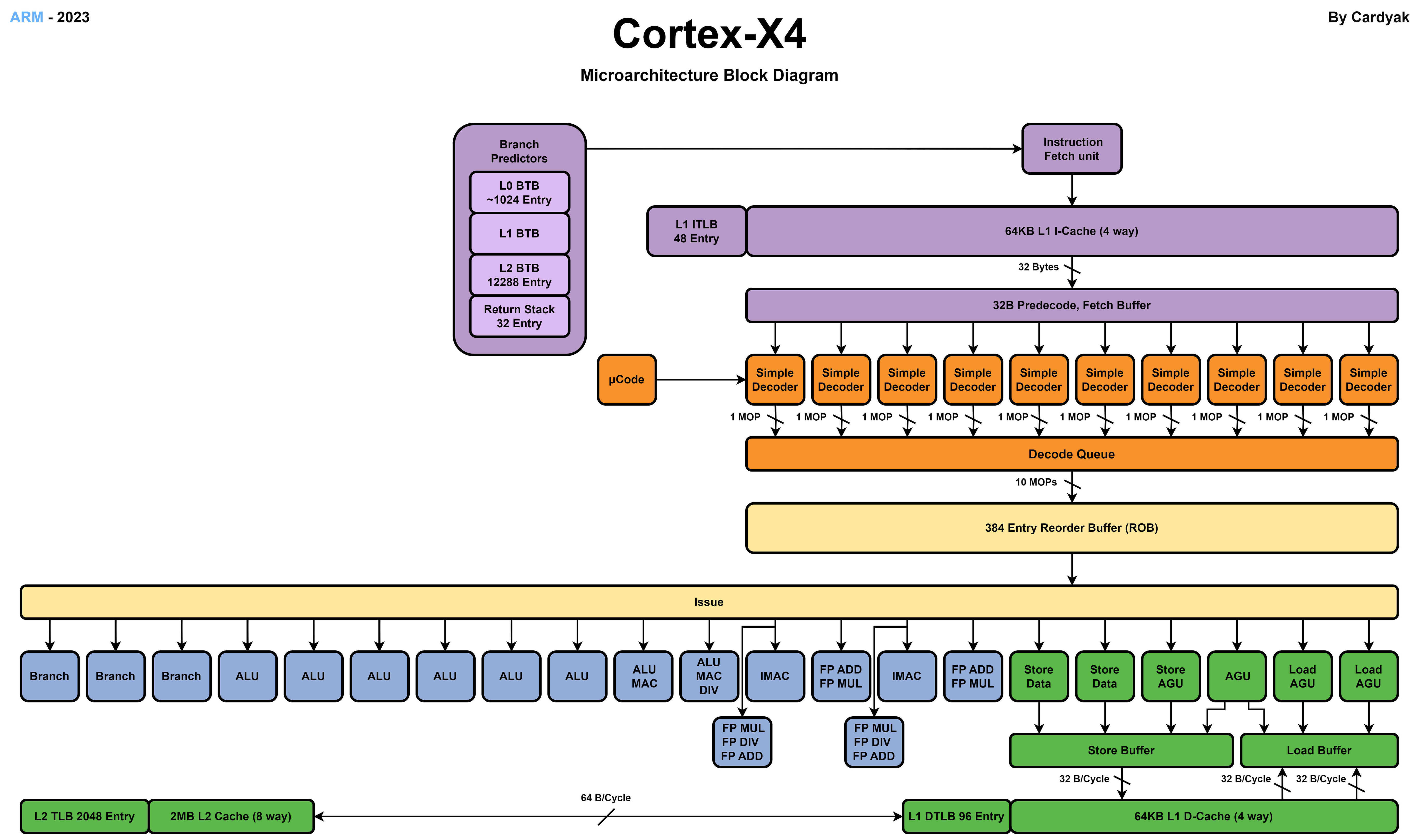
A720 性能核
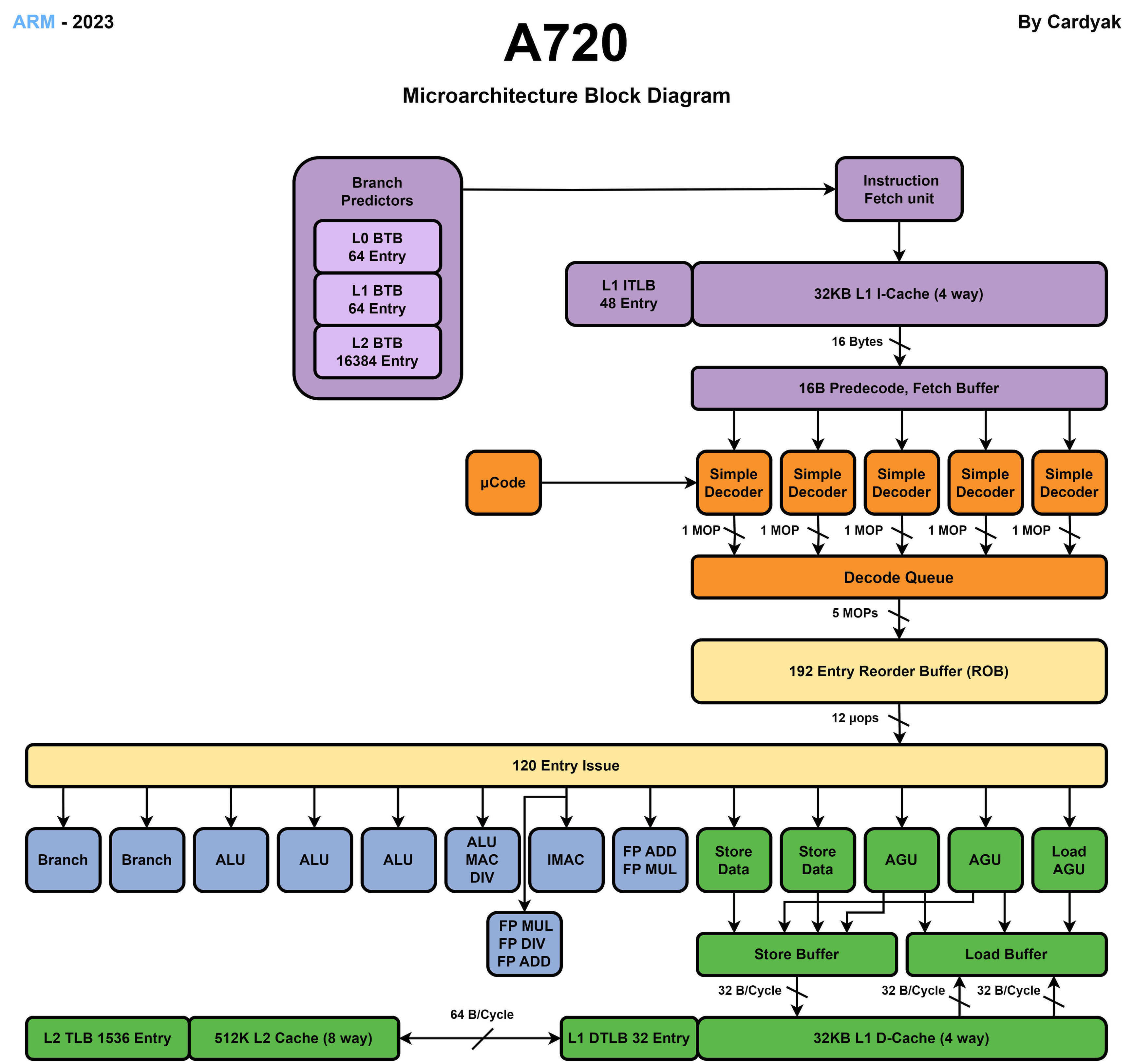
A520 能效核
小结
CPU核心微架构通过加入更多的流水线单元提高IPC,这些优化单元都需要消耗额外的晶体管数量增加能耗,同时IPC更高的核心会使用更高的时钟频率运行。在20世纪90年代流水线技术的发展带来了处理器性能的快速提升,但是随着功耗墙的限制,高性能核心在性能上比能效核心快几倍,但是在功耗上可能有几十到上百倍的消耗。CPU技术发展不再追求大幅提高IPC来提高性能,而是转向对晶体管更好的利用追求能耗比。
从现代CPU的微架构设计中也能看到,不同指令集的CPU在微架构上也有很多相似之处,更多的差异在解码单元对于不同指令的解码。
提示:
IPC高的核心需要使用更高的时钟频率进行执行,主要是因为IPC高的核心有更复杂流水线设计和更积极的流水线调度避免流水线停顿,所以提高时钟频率可以提升性能。IPC低的核心会遇到更多的流水线停顿,提高频率也会导致很多周期流水线处于停顿等待内存读取或分支计算完成造成浪费。
数据级并行:SIMD 和 GPU
SIMD
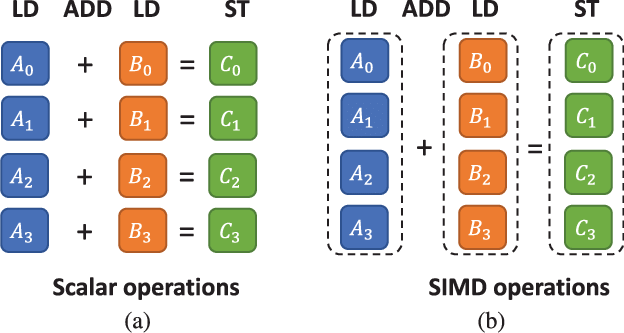
SIMD(Single instruction, multiple data)单指令多数据,是一种通过单个指令同时进行多个数据运算的方式,主要是用于音视频、图像处理、向量运算这些计算场景。通过增加运算单元位宽、计算单元数量数量、寄存器位宽可以同时进行更多数据的运算,普通指令单个周期通常只能支持 2 个数据的运算,SIMD指令单个周期可以同时几十个数据的运算。同时一次性读取多个内存数据也可以降低多次读取内存数据带来的数据延迟。大部分常见编程语言都提供对SIMD的支持,可以直接进行使用。
很多图像、音视频等场景,通常只需要更低的数据位宽进行运算,SIMD指令可以同时进行更多数据的运算。目前x86平台的SIMD指令发展到最新的AVX-512,运算宽度提升到 512 位,可以单指令执行 512 位的运算。ARM平台的SIMD指令发展到SSE,最高可执行2048位的运算。
SIMD虽然带来了性能的提升,但是芯片需要使用更多的晶体管用来支持SIMD指令更高的位宽计算和更多的寄存器数量。同时SIMD指令一次性传输数据量更大、指令复杂度更高、占用更多的寄存器和运算器,也带来了更多的计算功耗。SIMD也需要软件开发者针对特定场景选择使用SIMD指令进行优化才能得到性能提升。
普通运算和 SIMD 运算的区别
GPU
从某种角度讲,SIMD和GPU的运算方式很相似。通过一次性并行处理更多的数据带来性能提升,同时一次性读取大量数据也可以降低内存数据延迟带来的影响。GPU很像同时并行多线程执行SIMD的多核心处理器,只不过相比CPU设计更复杂性能更高,同时GPU的线程数更多、SIMD通道数更多、SIMD单元数量更多。
SIMD 和 GPU
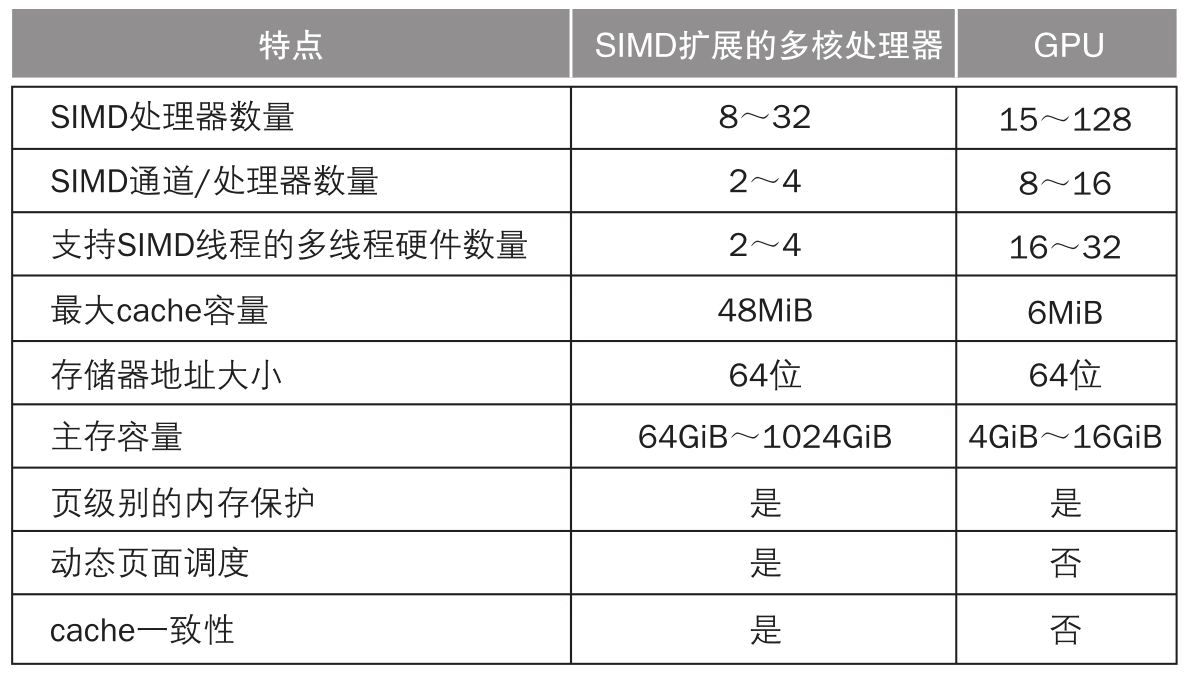
小结
近些年更多AI运算场景增加了对于高性能向量运算的要求。虽然CPU通过添加SIMD指令增加了向量运算的能力,但是CPU本身是用于通用计算设计,CPU中只有小部分用于SIMD运算。虽然类似Pytorch、TensorFlow这些AI训练框架都支持SIMD指令,但是使用SIMD进行大规模AI训练相比GPU性能更低,同时成本更高。SIMD更像是传统CPU运算的一种补充,用于简单的小规模运算场景用于提高性能。
多线程并行:超线程、多核心
超线程
超线程是一种STM(同时多线程)技术,通过在单个CPU核心中模拟运行多个线程提高CPU的多线程并行能力。Intel最早在2002年推出了超线程技术,一个核心同时支持2个线程。利用SMT可以避免处理器中长延时事件导致的暂停,提高计算单元的利用率。
超线程技术通过给每个线程增加一套寄存器和PC单元,多个线程共享流水线中的多发射、动态调度等模块,通过寄存器重命名和动态调用可以在一个周期内执行不同线程的多条指令。减少单个线程中发生类似缓存缺失这样的长延时等待事件,让计算单元一直在执行状态提高性能和吞吐量。
超线程技术会增加流水线调度的复杂度,现代CPU核心通常只支持2个线程的SMT。超线程技术需要依赖流水线的动态调度能力,所以现代CPU中通常只有高性能核心才支持。同时超线程技术虽然可以提高20%-30%的多线程性能,但是会增加7%的能耗和降低单核峰值性能。
超线程调度
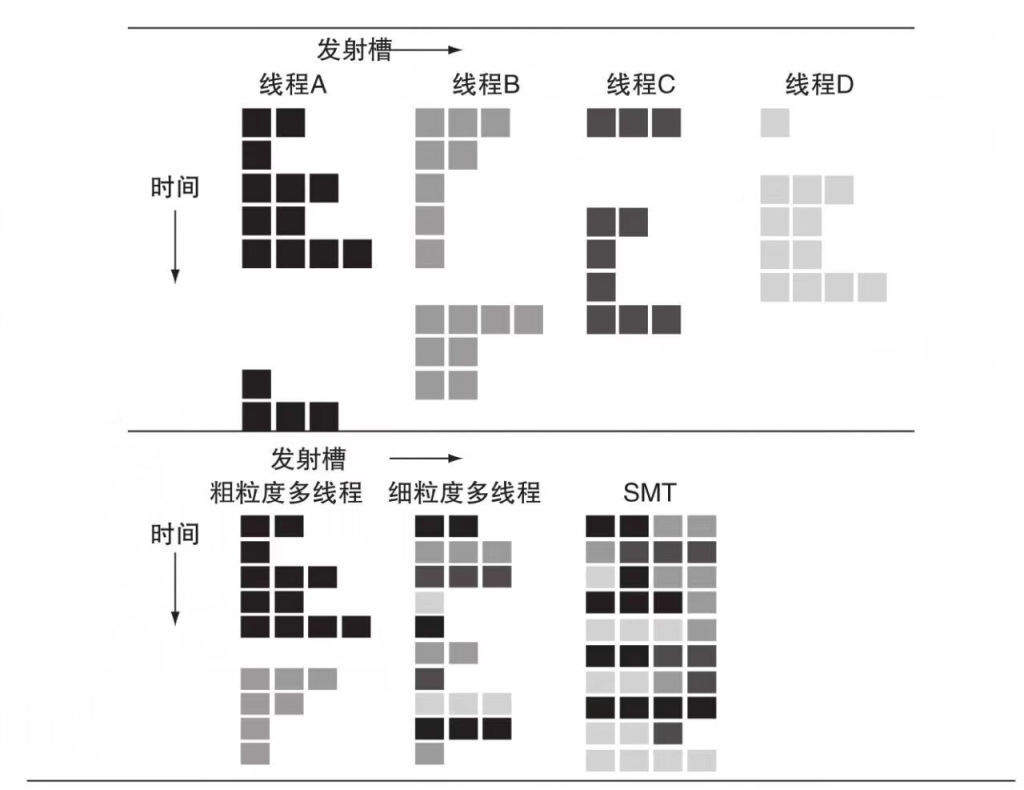
粗粒度多线程- 只有流水线发生等待事件长的停顿时才切换线程
细粒度多线程- 每个时钟周期都切换线程
多核心
由于IPC提升和时钟频率提升都因为功耗墙的限制而放缓,现代CPU通过提供更多的物理核心提高多线程并行能力提升指令吞吐量提高性能。通过增加CPU核心数带来的多线程性能提升,带来的能耗增加相比提升IPC、时钟频率更低。现在手机端CPU中也有5-9个核心,PC 级CPU中通常有10-30个核心,服务器CPU中核心数更多。
增加核心数可以复用核心内部的微架构设计,根据CPU的功耗、成本、性能诉求选择核心数量。例如Intel在桌面级酷睿处理器和服务器至强处理器可能会使用同样的核心,只是会增加更多的核心数量。Apple在A系列和M系列芯片也会使用同样的核心。
增加核心数也能带来一定的能耗优势,操作系统内核会根据运算负载动态的调度不同数量的核心进行执行,在运算负载低的时候可以调度更少的核心降低功耗。
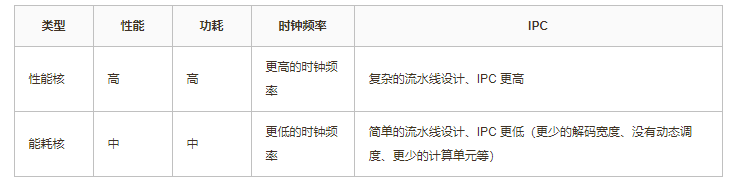
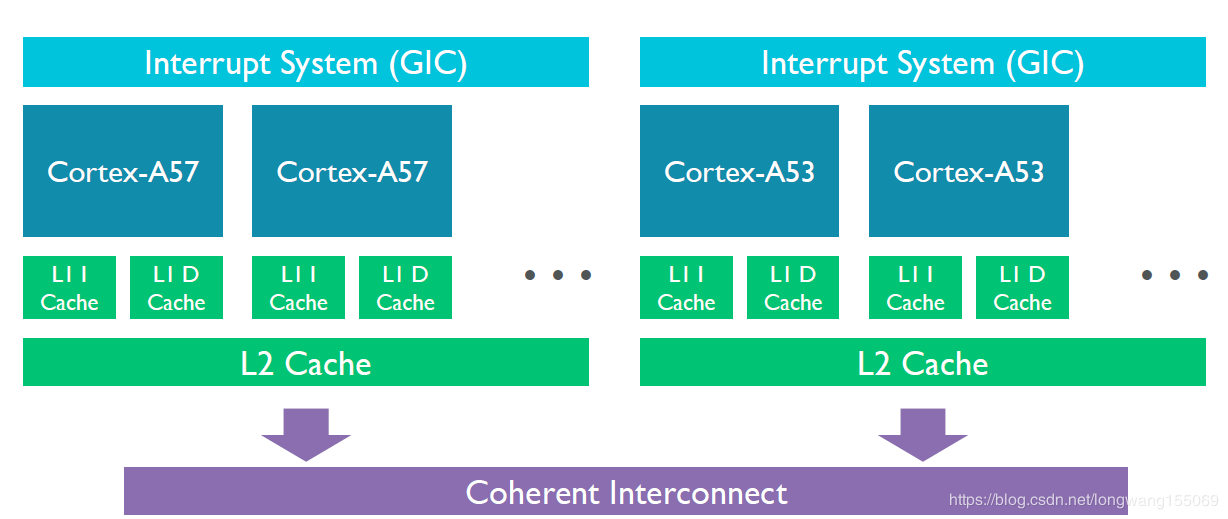
大小核
现代CPU中通常还会使用大小核异构架构设计来提升能耗比降低功耗。性能核心用于高性能计算场景最大化执行性能,能耗核心用于日常低负载计算场景降低能耗。相同的核心会使用同样的时钟频率来运行,通常会共享使用L2缓存。大小核的设计也增加了操作系统内核对于多核心调度的难度。
性能核心、能效核心区别
大小核设计
小结
近些年CPU通过增加更多的核心数量提高CPU的多线程并行能力,但是这也带来了一些新的问题限制了核心数一直快速增加。首先CPU核心数更多增加缓存一致性的复杂度会影响性能,操作系统内核如何更好的对更多核心进行调度达到最高的能耗比。
同时对于软件开发者来讲,利用越来越多的核心进行编程会更复杂。编程语言以及开发框架也需要进行调整利用更多的核心。同时对于不同的软件类型,可以利用多线程并行执行的部分也是不一样的。(如果一个程序只有10%的运算工作可以并行执行,即使添加更多核心带来的提升也很有限)
虽然增加核心数带来的能耗增加相比IPC、时钟频率更低,但是依然会增加功耗,功耗墙也是限制核心数增加的限制之一。
高速缓存和内存提升
虽然内存不属于处理器内部的结构,但是处理器运行时会依赖内存中的程序指令和程序数据,所以内存性能对处理器性能的影响很大。因为内存性能提升相比处理器时钟频率提升非常缓慢,当前处理器对内存读写通常需要50-100个时钟周期。关于内存访问速度的提升,一个方向是通过引入多级缓存减少处理器对内存的直接访问,另一个方向是内存自身性能的提升。
引入高速缓存
为了减少处理器对内存的直接访问,现代处理器引入了SDRAM(Synchronous dynamic random-access memory)存储作为处理器的缓存集成在处理器芯片中。SDRAM的优点是访问速度比内存快很多,缺点是功耗高、成本高(1 位需要 6-7 个晶体管)、容量低。
处理器对内存的所有访问都通过缓存进行加载,缓存会保存最近使用过的内存数据,这样下次访问这些数据时就可以直接从缓存中返回避免直接从内存中读取。
内存读写过程
以下是一个简单的具有二级缓存的处理器内存读写过程原型,不过现代处理器设计通常会比这个过程更加复杂:
读取
L1- 处理器核心需要读取数据时,将数据内存地址发送给L1缓存。L1缓存检查是否有缓存数据,如果L1缓存中有缓存数据直接返回。如果缓存缺失将数据内存地址发送给L2。
L2-L2缓存检查是否有缓存数据。如果L2缓存中有缓存数据将数据写入L1缓存同时读取到处理器中。如果缓存缺失将数据内存地址发送给内存。
内存- 从内存中读取数据,之后分别写入L2缓存、L1缓存,然后读取到处理器中。
保存
处理器核心将寄存器中的数据保存到内存时,分别写入L1缓存、L2缓存,之后保存到内存中。
缓存提升方向
缓存性能提升方向主要是提高缓存命中率、降低缓存缺失耗时、降低缓存命中耗时,主要是通过以下这些技能进行提升:
增加容量
增加缓存的容量,缓存中可以存储的数据越多,缓存命中率也就越高。功耗和成本会限制容量增长的速度,同时因为增加容量会影响访问速度,所以L1缓存容量增长很慢。
使用多级缓存
现代处理器通常有2-3级缓存,多核处理器每个核心包含一个L1缓存,L2、L3缓存是多个核心共享。读取速度L1 > L2 > L3,容量L3 > L2 > L1,成本L1 > L2 > L3。
这么设计的目的主要是通过局部性原理提高缓存性能。L1缓存关注读取性能,将更常用的内存数据放到容量更小的L1缓存中更快的读取。同时L1缓存设计会将指令和数据分离,提高缓存性能和缓存命中率。
L2/L3缓存关注缓存缺失率,将更多的内存数据防止在缓存中减少缓存缺失耗时。
时间局部性- 被引用过一次的内存数据在未来会被多次引用。
空间局部性- 一个内存数据被引用,那么未来它临近的内存地址也会被引用。
现代CPU多级缓存设计
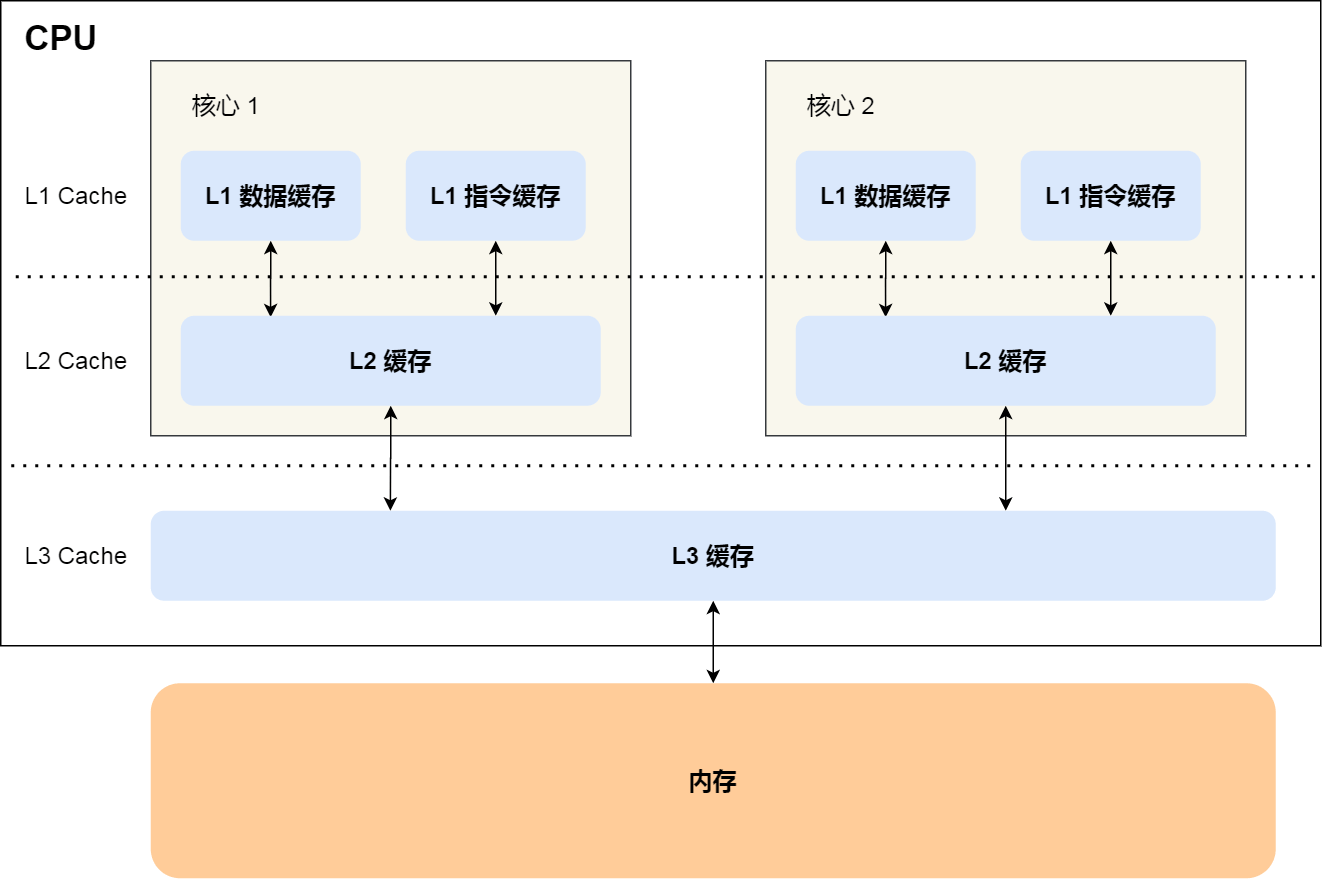
提示:通常
L1缓存是单核心独占、L2缓存可能是单核心独占或多核心共享、L3缓存/内存是所有核心共享。通过MESI协议来解决缓存一致性的问题。
多级缓存和内存性能
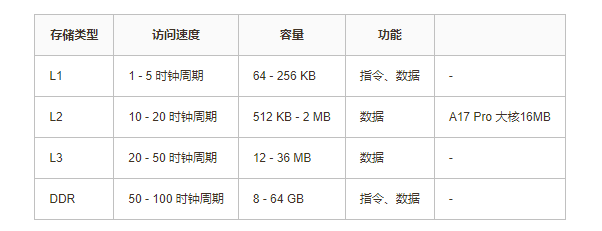
降低缓存命中时间
通过更优秀的缓存涉及,减少缓存命中时的耗时。但是通常减少命中缓存耗时和增加缓存容量通常会有不可调和的矛盾。
缓存预加载
根据前面流水线的介绍,现代处理器通常会对一次性读取内存多条程序指令到放入缓存中,同时也会提前读取后面可能会使用的内存数据到缓存中。但是当提前预加载到缓存中的数据并没有使用到时,会造成额外的功耗浪费。(例如分支预测错误)
优化缓存更新算法
将新的数据写入到缓存时,由于容量限制通常需要替换掉旧的缓存数据。常见的替换算法有LRU算法,使用更好的算法可以提高缓存命中率。
内存性能提升
虽然通过加入多级缓存可以提高内存读写的性能,但是处理器高速缓存的容量很有限,遇到缓存缺失时还是需要直接访问内存。所以对内存的性能提升依然很重要,内存性能提升主要是从以下四个方向进行提升:
读取延迟- 持续减少内存读取延迟,可以降低缓存缺失从内存中读取数据的耗时。
功耗- 由于移动设备等低功耗场景的出现,对内存产生的功耗也有更低的要求。
带宽- 因为内存性能提升很慢,同时现代处理器不断的引入新的协处理器例如GPU、NPU需要进行更多的内存数据传输。增加内存带宽虽然无法降低单次内存读取延迟但是可以同时传输更多的数据。
成本- 更低的成本可以使商品价格更低,同时可以增加更多的内存容量。
更多内存类型
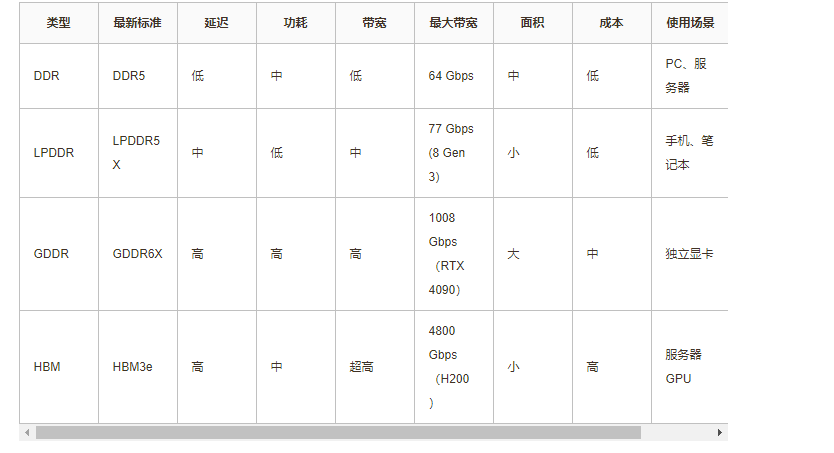
由于内存无法同时满足对延迟、功耗、带宽、成本的要求,现代内存逐渐发展出了多种不同的内存类型。针对不同的计算场景选择使用不同类型的内存,主要是基于处理器对延迟、功耗、带宽、成本的要求进行选择。每一代内存新标准的推出也会逐渐提高延迟、功耗、带宽的性能,同时降低上一代标准的成本。(通常新标准成本更高)
不同内存类型特点
集成封装工艺提升
现代面向移动场景的处理器通常会将LPDDR内存使用3D集成封装技术直接集成到处理器芯片上。优点是可以减少传输物理距离提高传输性能、降低功耗,缺点是无法灵活更换内存。
内存集成封装到处理器芯片上

小结
近些年高速缓存技术发展逐渐放缓,同时缓存缺失是导致流水线停顿的主要原因之一。由于读取延迟限制了L1缓存容量的提升,L1容量提高很少。半导体工艺发展放缓,晶体管数量增长速度降低以及功耗问题,也降低了L2、L3缓存容量增加的速度。同时高速缓存的引入也给编译器和软件开发者带来了更大的挑战,如何更好的利用局部性原理提高缓存命中率:开发者需要编写缓存命中率更高的代码、编译器需要生成缓存命中率更高的程序指令。
提示:增加缓存容量的成本很高。以 A17 Pro 芯片为例,总共 190 亿个晶体管,因为包含
GPU、NPU等协处理器,CPU使用的晶体管数量不超过 30%。缓存大小L2 20MB + L1 192KB,以一个缓存位需要几个晶体管来计算,缓存大概需要耗费几亿个晶体管。
内存技术每一代新标准在增加带宽、容量和能耗比上都有不错的提升,但是读取延迟降低缓慢很多。内存读取延迟导致的内存墙依然是限制处理器性能的主要因素之一。因为内存墙的限制,现在也有一种存算一体的探索方向,将内存和计算单元集成在一起减少数据传输延迟。
现代处理器核心数越来越多,每个核心都有自己的L1缓存,多个核心需要共享L2缓存、L3缓存、内存数据。多核缓存一致性的复杂度越来越高,额外的开销可能会降低读取延迟和增加功耗,限制多核处理器的性能。
提示:从高速缓存和内存上看,更小的程序体积、更小的内存占用是可以增加程序的运行性能的。
SOC、DSA 和 Chiplet
SOC
SOC(System on Chip)片上系统是一种将多个不同模块封装在一个芯片中的技术。现代CPU基本上都属于SOC芯片,将CPU、GPU、NPU、WIFI、蓝牙、Modem等模块集成到同一个芯片中。由于半导体技术的发展可以集成在芯片上的晶体管数量越来越多,可以将更多的模块集成到一个芯片中带来集成度、性能、系统单元复用率的提升:
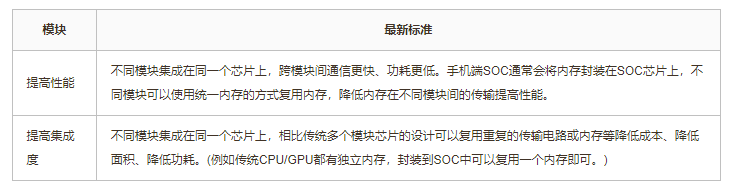
虽然带来了性能的优势,但是由于SOC集成了更多模块同时需要模块间互联,芯片设计、制造复杂度更高,导致成本也更高。
SOC 组成结构
现代SOC通常由一个 CPU 单元、多个协处理器(NPU/GPU)、无线模块(WIFI/蓝牙/蜂窝网络)、多媒体单元(ISP、DSP)、内存控制器、I/O 单元组成:

高通 8 gen 3

Hexagon Processor- AI 模块
FastConnect- WIFI、蓝牙
Apple M3
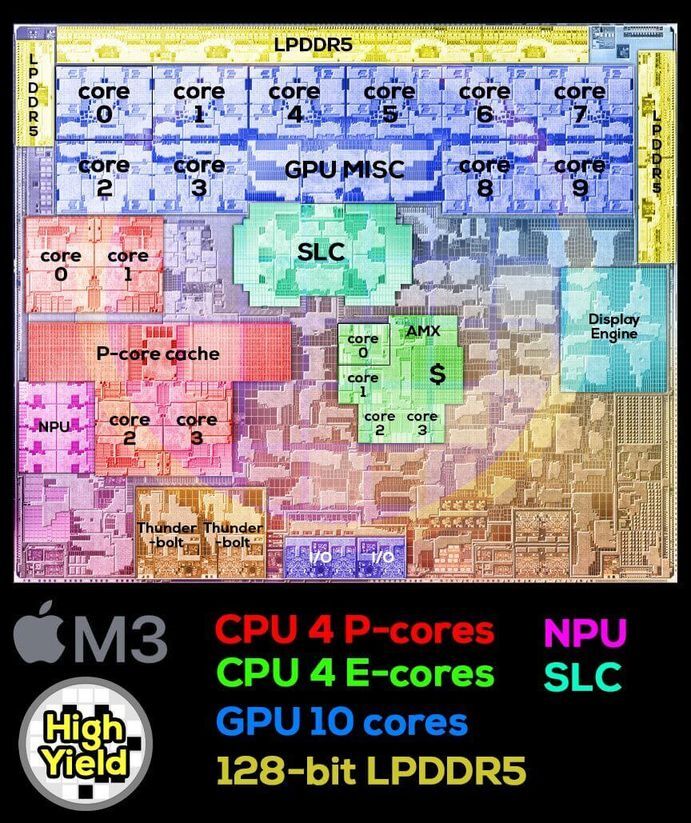
从
M3的设计上可以看出,现代SOC中CPU部分占用的硅面积不超过30%
DSA
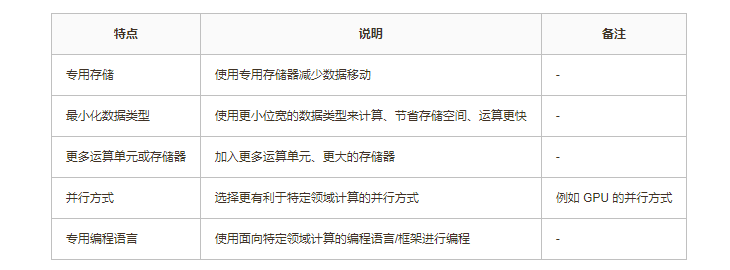
DSA(Domain Specific Architecture)领域特定架构是一种用于特定领域计算的结算机体系。由于CPU是一种追求通用计算的计算机体系结构,对于特定领域计算(音视频、图形、AI 等)的性能和能效比都比较差。DSA通过面向特定领域计算的设计大幅提高性能和能耗比,解决CPU对于特定领域计算的性能劣势。
DSA 设计
现代SOC中的GPU、NPU、DSP就是一种常见的DSA模块。传统CPU通过复杂流水线设计、高速缓存、增加寄存器位数等特性提高CPU的运算性能,但是这会导致大量的晶体管消耗增加成本和能耗。DSA通过减少这些复杂的设计提高晶体管的利用率提高能效,相比CPU执行同样的特定领域运算可以带来的优势:更小的面积、更低的成本、更高的能耗比、更好的性能。
DSA 设计原则
Chiplet
Chiplet是近几年发展出的一种将不同的功能模块分离成小芯片,并通过先进封装技术组合在一起的新技术。Chiplet主要是为了解决传统SOC遇到的成本高和扩展性问题。

不过Chiplet对封装技术的要求很好,不同小芯片间的通信设计也很复杂。目前只有少量的芯片使用了这种方式进行芯片制造。
Meteor Lake
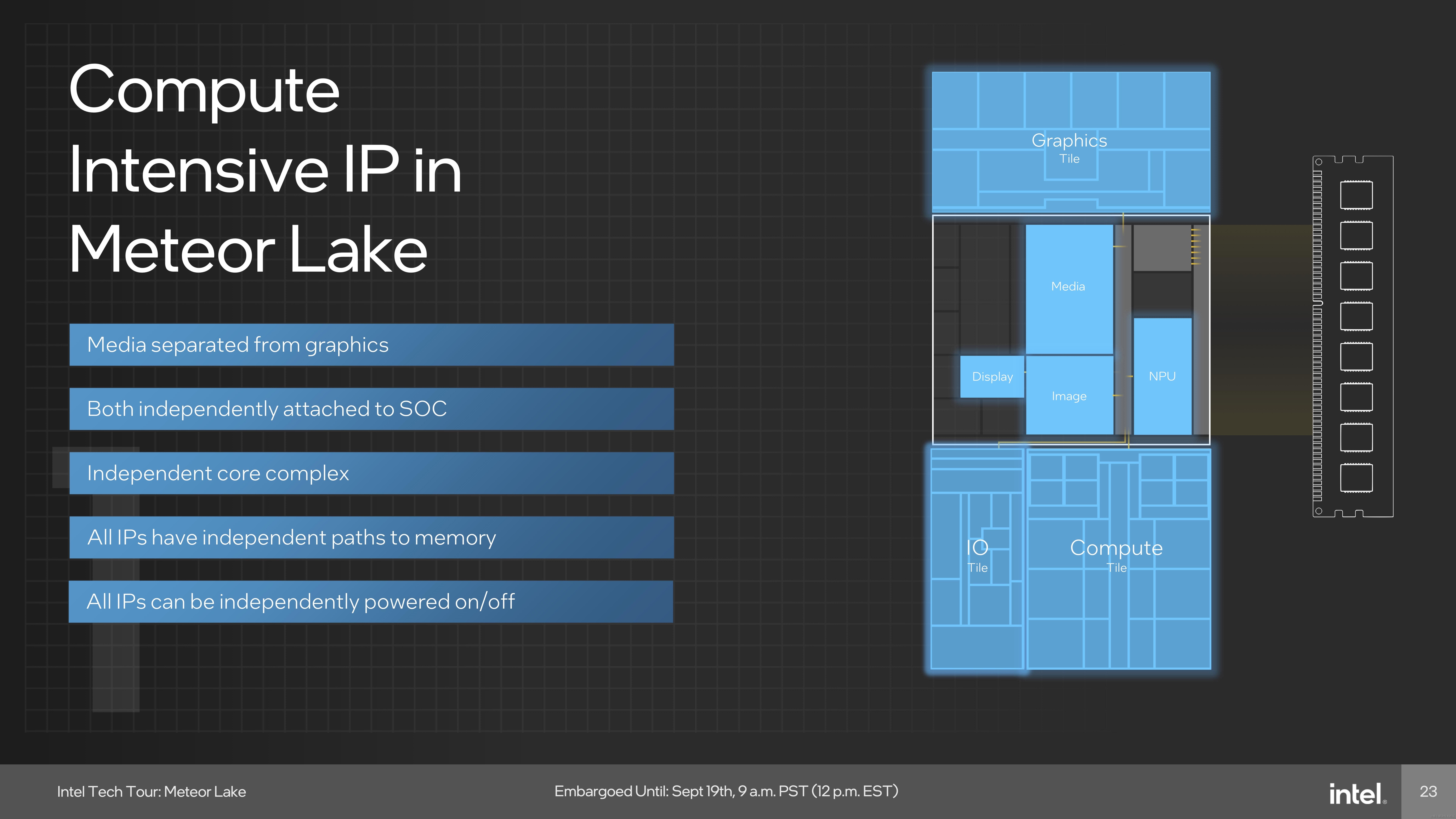
Intel2023 年推出的Meteor Lake处理器使用Chiplet封装,CPU使用 Intel4nm工艺,Graphics使用台积电5nm工艺,SOC、IO使用台积电6nm工艺。
小结
由于CPU通用处理器性能提升放缓和对特性领域计算的能耗比和成本问题,未来也许会加入更多的DSA模块用于提升特定领域计算的性能和能耗比。近些年PC端处理器也在效仿移动端处理器加强DSA单元能力,包括提高核显 GPU 的性能以及加入 NPU。同时Chiplet技术的发展也可以帮助处理器集成更多的DSA单元同时降低成本。
主流 CPU 发展
Intel 处理器发展
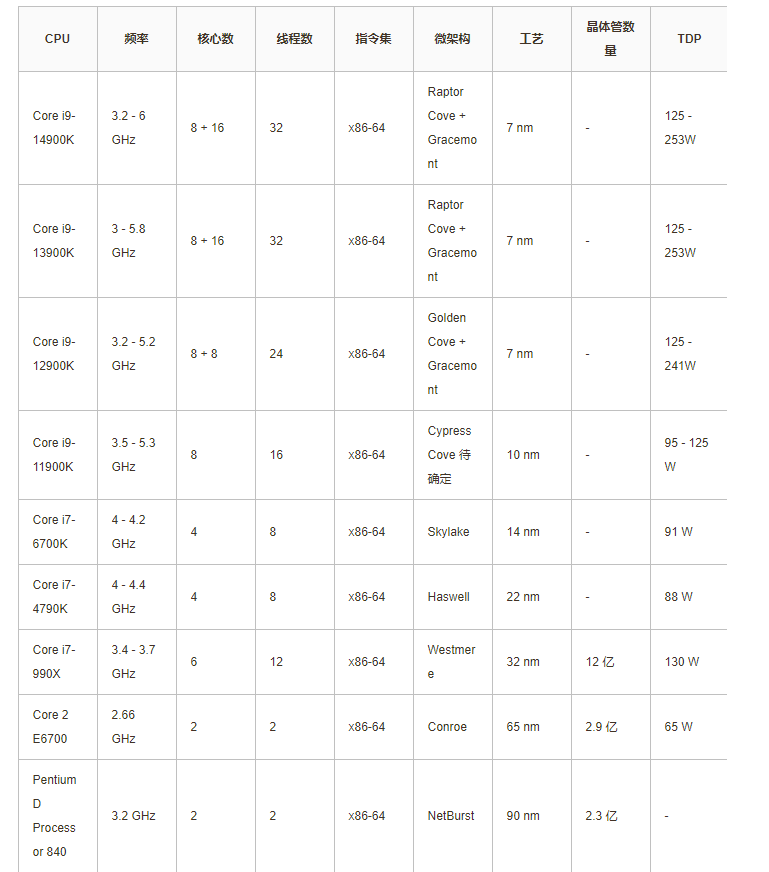


最新 CPU 微架构对比

对开发者的影响
更多核心数
CPU核心数越来越多,软件开发者需要使用面向多线程的利用更多的核心并行才能提高程序执行的性能。同时也可以导致编程语言、编程范式、框架的一些改变:
多线程编程- 更多的使用到多线程编程利用多核的性能
简化并行编程- 编程语言提供了更多特性简化并行编程,例如async/await函数、结构化并发
异步编程- 更多的跨线程异步调用
非共享内存的并发模型- 可以减少数据竞争、减少线程锁使用、减少线程切换的耗时,Go、Rust、Swift语言都提供了类似的并发模型
UI框架- 传统UI框架都是基于单线程模型设计,UI框架和浏览器需要更好的利用多核心的性能优势。同时非UI操作需要更多考虑多线程的利用减少主线程的消耗
函数式编程- 函数式编程更有利于并行执行变得更流行
SIMD、DSA单元
SOC不断增加更多的DSA单元增加特定领域运算的能耗比,未来可能需要面向更多不同类型的处理器进行编程,不同的处理器会导致编程语言和编程范式的改变。
硬件性能提升放缓
CPU性能提升放缓带给软件的性能提升更少,同时软件自身功能不断增加对于性能的消耗,软件追求更高的性能提升就需要做更多的软件性能优化。
AOT- 类似Java、C#、JS这些传统的解释执行编程语言开始追求AOT编译提高性能,新的编程语言通常也会支持AOT编译
简化内存管理- 简化传统的自动内存管理方式,使用更简单的内存管理方式。例如Rust的所有权更多利用编译器去检查内存安全
值类型- 更多的值类型使用,栈上的值类型性能更好
编译器- 编译器利用静态优化生成性能更好的代码减少运行时消耗,静态类型系统、静态方法派发
文章转载自:京东云开发者

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论