
MAR:针对动作识别的视频掩码建模
出品人:Towhee 技术团队 王翔宇、顾梦佳
视频识别的标准方法通常会对完整的视频输入进行操作,这往往会由于视频中广泛存在的时空冗余导致效率低下。视频掩码建模(即 VideoMAE)的最新进展表明,普通视觉 Transformer (ViT) 能够在仅给定有限视觉内容的情况下补充时空上下文。受此启发,掩码动作识别(MAR)提出丢弃一部分 patch 并仅对部分视频进行操作,以此减少冗余计算。相比 ViT 模型,MAR 能够在大量降低计算成本的同时,还能始终展现出显著的性能优势。尤其是由 MAR 训练的 ViT-Large,在动作识别数据集 Kinetics-400 和 Something-Something v2 上均具有令人信服的优势。
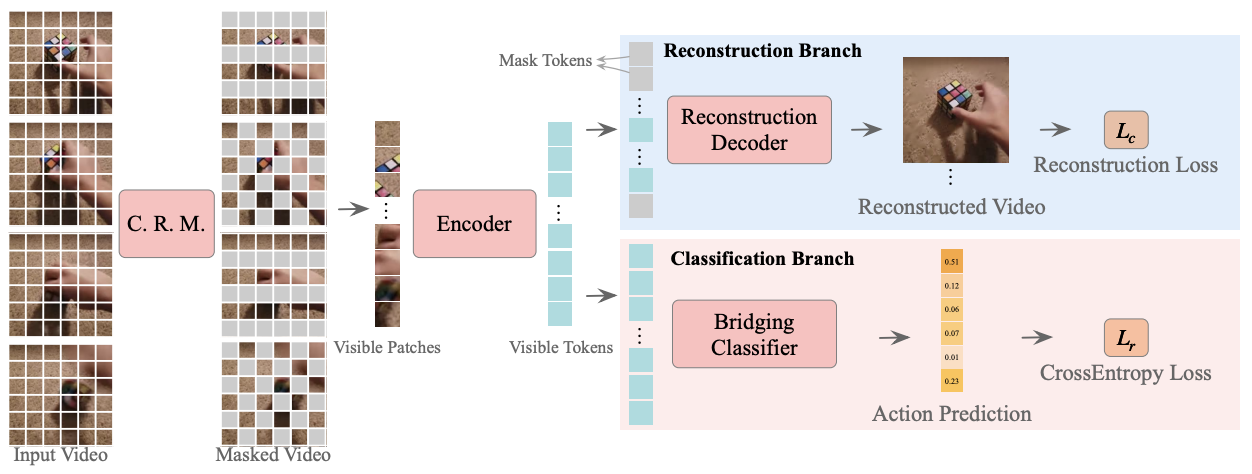
Overview of Masked Action Recognition (MAR).
MAR 包含以下两个不可或缺的组件:cell running masking 和 bridging classifier。具体来说,为了使 ViT 能够轻松感知可见 patch 之外的细节,cell running masking 保留了视频中的时空相关性。它能够确保可以依次观察相同空间位置的 patch,以便于重建。 此外,虽然部分观察到的特征可以重建语义显式的不可见 patch,但它们无法实现准确的分类。为此,bridging classifier 被用来弥合用于重建的 ViT 编码特征与专门用于分类的特征之间的语义鸿沟。
相关资料:

Data Infrastructure for AI Made Easy 2021-10-09 加入
还未添加个人简介









评论