
【LLM】提示工程技术提炼精华分享
一、提示工程概述
提示工程(Prompt Engineering)是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型(Large Language Model, LLM)用于各场景和研究领域。 掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。
提示工程相比较于微调(Fine-tuning)的成本和复杂度更低,但是不能对模型本身的能力进行优化,只能基于模型已有能力进行应用。
二、基本概念
2.1)提示词要素
提示词可以包含以下任意要素:
指令:想要模型执行的特定任务或指令。
上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
输入数据:用户输入的内容或问题。
输出指示:指定输出的类型或格式
注意,提示词所需的格式取决于您想要语言模型完成的任务类型,并非所有以上要素都是必须的。
2.2)关键原则
设计高效 Prompt 的两个关键原则:编写清晰、具体的指令和给予模型充足思考时间。掌握这两点,对创建可靠的语言模型交互尤为重要。
编写清晰、具体的指令
具体来说主要包括:明确描述需要大模型完成的任务、使用分隔符来表示输入的不同部分、提供示例。
给予模型充足思考时间
“充足时间”主要是指面对复杂问题的时候,不要指望大模型直接输出正确答案,而是应该尝试让它逐步推理,按步骤输出内容也可以约束大模型过于发散的行为。
关于提示工程的技术基本上都是围绕如何清晰描述任务、如何提供更多信息和如何逐步解决问题这三个方面来深入的。
三、零样本提示和少样本提示
零样本提示(zero-shot)差不多是最简单的提示词结构,只是在尽量清晰地描述任务。如:
少样本提示(few-shot)则是在此基础上给出一些输出的示例。
这里所说的“少”可以是一个也可以是数十个,主要是指固化在提示词中的有限个静态示例。如:
这个例子中前三行文本即提供给大模型的示例样本,最后一行内容则是需要求解的问题。
这两个例子都使用了“续写模式”,即通过提供不完整的语句让大模型来进行补全,可以达到明确输出内容、固化输出格式等目的。
四、思维链 CoT
在面对一些相对复杂问题的时候,少样本提示也不能很好地进行解决,于是出现了思维链 Chain of Thought。
比如这样一个少样本思维链:
输出:
这个例子就是将问题求解拆分成了“找到所有奇数”、“求和”、“判断是否为偶数”三个步骤,将各步骤串连成链条,顺序求解子任务,最终得到原始问题的答案。
当使用思维链模式的时候,零样本提示甚至可以得到比少样本提示更好的结果,如:
其中第二行文本是一个通用的固定内容提示词,可以作为大模型应用中的“套话”来使用。英文原文如下:
当问题更加复杂的时候,可能需要明确地将各个步骤的处理动作告诉给大模型,如:
五、自我一致性思维链 CoT-SC

自我一致性思维链 CoT-Self Consistency 是对 CoT 的一种改进,其思想非常简单清晰,相比于 CoT 只进行一次采样回答,SC 则是进行多次采样,选择具有一致性的回答结果作为最终答案。
如上图中大模型两次对同一个问题有两次输出结果是“$18”,在 majority vote 方法下认为它是比“$26”更具一致性的答案。此外虽然 CoT-SC 的作者还在最终结论选择方法上尝试了 weighted avg 和 weighted sum,但它们的效果都不如 majority vote。
六、思维树 ToT
上文中提到的所有例子都是单论对话,即通过一个提示词,从大模型得到一次输出,这一次输出即包含了最终的结果。
在引入思维树 Tree of Thought 之前,需要简单讲述一下“多轮对话”的概念,即:
将复杂问题拆解为多个子任务,每一个子任务单独设计一个提示词,根据前一个子任务输出内容来决定后一个任务的输入,形成多次交互的 CoT,最后一次输出得到最终结果。
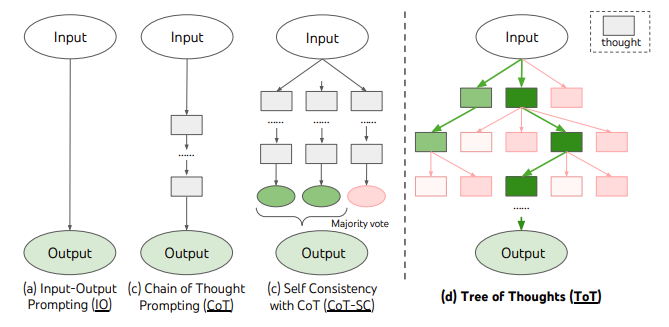
思维树的思想则是结合多轮交互 CoT 和自我一致性,每一轮对话都进行一致性判断,最终得到一致性最高的答案。
七、思维图 GoT

在实际的问题求解过程中,自我一致性的判断并不总是可行,很多任务或子任务的结果不是非黑即白可以通过一致性判断来决定是否采纳的。
特别是面对一些需要大模型提供创造性的问题,比如我们需要大模型对一篇论文概括一个中心思想的列表,多次输出的结果可能都是正确但不完整的,我们并不能用一致性的思想来决定 ToT 的走向。
思维图 Graph of Thought 就是基于以上前提出现的,它主要是在 ToT 的基础上结合了“自我优化 Refining”、“回溯 Backtracking”和“整合 Aggregating”这三个操作。
自我优化:在生成结果大体准确的情况下,让大模型基于此结果进行优化。
回溯:在生成结果不可用的情况下,可以考虑丢弃掉分支上的部分或全部节点。
整合:同一步骤的多个结果进行整合,再作为下一步骤的输入依据。
八、检索增强生成 RAG
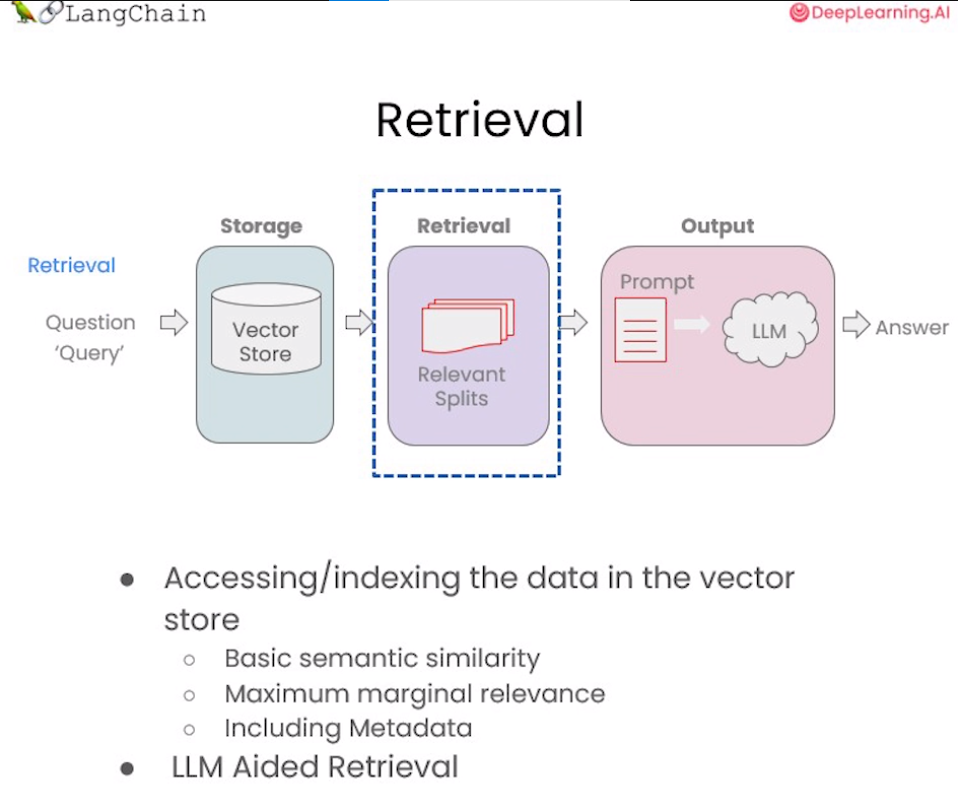
CoT、ToT、GoT 等技术都是在围绕“给予模型充足思考时间”这一原则,而检索增强生成 Retrival Augmented Generation 则是丰富“上下文”这一提示词要素的技术。
RAG 的整体流程如上图所示:
①用户输入问题
②根据用户输入的问题在向量知识库中进行检索
③检索得到与问题相关的知识片段
④将知识片段组装到提示词模板中
⑤大模型针对组装后的提示词进行回答
使用 RAG 技术可以弥补通用大模型对特定领域知识了解不足的问题,其中知识库本身的质量非常关键,低质的知识可能反而产生副作用。
目前最常用的 RAG 框架是 LangChain,它不仅能够用于检索组装提示词,LangChain 还提供了组合使用多种大模型的能力,这在使用不同模型分别处理各自擅长领域的子任务时将非常有用。
九、其他提示词技巧
9.1)指定大模型在任务中的角色
使用形如“你是一个在 xxx 领域具有专业知识的 xxx”的内容指定大模型在任务中扮演的角色,一方面是对任务本身的辅助描述,另一方面也是对大模型解决问题的方式进行限定。
比如指定的角色是“软件工程师”,大模型更有可能输出代码来解决问题,而如果指定的角色是“产品经理”,则更有可能输出产品维度的解决方案。
这个技巧在概括总结类的任务过程中尤为有效,大模型会根据其角色来判断输出内容的受众,使用更容易被受众理解的语言来进行回答。
9.2)使用正向描述取代否定描述
大模型通常对否定描述的注意力不够,比如想要大模型使用 JSON 格式进行输出时,使用“不要输出描述性的文字”的效果会劣于“只输出 JSON 代码内容”。
这个现象与大模型本身的能力有很大关系,在 GPT3.5 上比较明显,但是在 GPT4 上则几乎不需要可以避免否定描述。
9.3)对大模型的输出给予评价
在多轮对话的任务中,如果能够对大模型输出内容判断优劣,那么及时给出肯定或否定的评价可以提高大模型对正确知识的注意力,或避免继续输出相同的错误信息。
不过在系统化的应用中,如果判断大模型输出内容质量不佳,更应该考虑丢弃本轮回答或进行自我优化。
9.4)承诺“小费”

近期有网友使用 Python 单行代码任务对 GPT4 接口进行测试,承诺“如果完美解决任务,我可以支付 xx 美元小费”。
测试结果显示出这个“技巧”对生成效果确实有提升,主要表现在回答的长度上,但这里并不是单纯的“凑字数”,而是真的在更详细地分析并回答问题。
国内网友给出了进一步的猜想,对于国产大模型,敬酒或者送礼的效果可能更好🤣
文章转载自:VD630

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论