
火山引擎 DataLeap 数据质量解决方案和最佳实践(三):最佳实践
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
最佳实践
前面介绍了 DataLeap 数据质量平台的一些实现方式,下面为大家介绍一些我们在数据量和资源这两个方面的最佳实践。
表行数信息-优先 HMS 获取
内部的离线监控中,表行数的监控占比非常大,可能至少 50% 以上的离线规则都是表行数的监控。对于表行数,之前我们是通过 Spark,Select Count* 提交作业,对资源的消耗非常大。后来我们对其做了一些优化。在任务提交的过程中,底层引擎在产出表的过程中将表行数记录写入相应分区信息中,我们就可以直接从 HMS 分区里直接获取表行数信息,从而避免了 Spark 任务的提交。
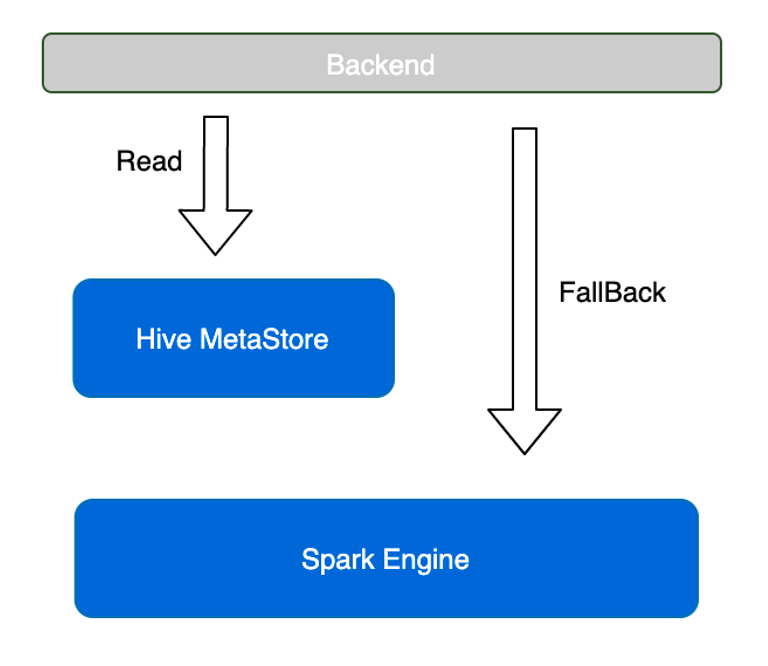
优化后的效果非常明显,目前对于表行数的监控,HMS 获取行数占比约 90 %,HMS 行数监控平均运行时长在秒级别。
注:这个功能需要推动底层服务配合支持,比如 Spark 需要把保存在本地 metric 里面的信息写入到 HMS 中,其他数据传输系统也需要支持。
离线监控优化
这一块是基于 Griffin 的 Measure 来进行,Measure 本身有丰富的功能,我们对其进行了裁剪以节约耗时。主要的裁剪和优化包括:
裁剪掉部分异常数据收集功能;
优化非必要的 join 流程。
另外,我们也对离线监控的执行参数进行了优化,主要包括:
根据不同的监控类型,添加不同的参数 (shuffle to hdfs 等);
根据监控特性,默认参数优化(上调 vcore 等)。
举个例子:用户写了 SQL 进行数据的 join,执行引擎可以分析出执行计划。对于 join 类的操作,shuffle 可能非常大,这种情况下我们默认会开一些 Spark 参数。根据表行数来预判数据表的大小,如果判断数据表比较大,会默认微调 vcore 和 memory。以上这些优化都能在一定程度上提升性能,目前平台上各类监控的平均运行时长缩短了 10% 以上。
引入 OLAP 引擎
平台上很多数据表和业务表(除了日志表以外),在数仓上层的表监控数据量不是很大,这种情况很适合进行 OLAP 的查询。
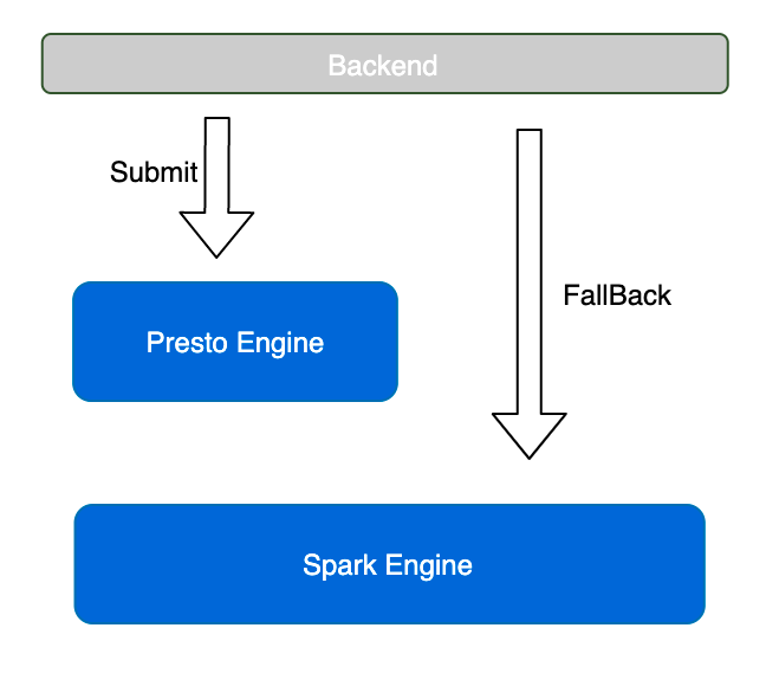
这种情况下我们在数据探查场景引入了 presto。之前在该场景下通过 Spark 做探查,引入 presto 之后通过快速 fail 机制,大数据量、计算复杂的探查任务 fallback 到提交 Spark 作业,探查时间中位数从之前的 7min 缩短到目前的不到 40s,效果非常显著。
流式监控支持抽样 & 单 Topic 多 Rule 优化 Kafka 数据抽样
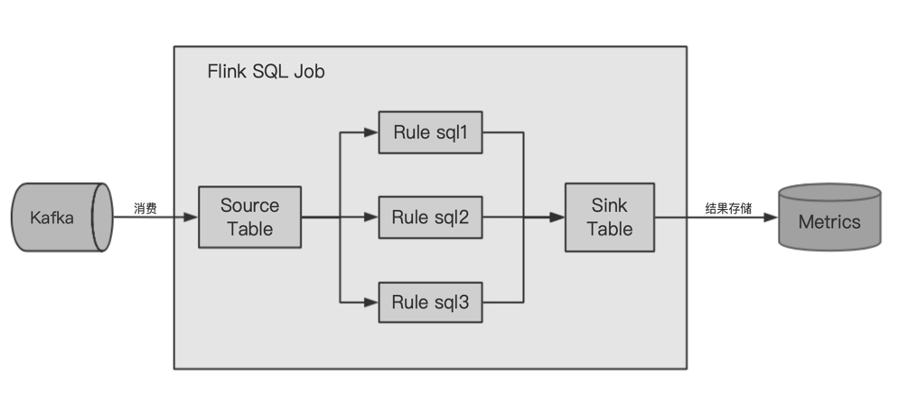
一般流式数据的问题都是通用性问题,可以通过数据采样发现问题。因此我们开发了数据采样的功能,减少数据资源的占比消耗。Flink Kafka Connector 支持抽样,可直接操作 kafka topic 的 offset 来达到抽样的目的。比如,我们按照 1% 的比例进行抽样,原来上 W 个 partition 的 Topic,我们只需要 ** 个机器就可以支撑。
单 Topic 多 Rule 优化
最早的时候我们是对一个 Topic 定义一个 Rule,然后开启一个 Flink 任务进行消费,执行 Rule。后来我们发现一些关键的数据需要对多个维度进行监控,也就是要定义多个维度的 Rule,对每一条 Rule 都开任务去消费是非常耗资源的,所以我们利用监控不是 CPU 密集型作业的特性,复用读取部分,单 slot 中执行多个 Rule,对 Topic 级别进行单一消费,在一个任务中把相关 Rule 都执行完。
未来演进方向
本文介绍了 Dataleap 数据质量平台的实现和最佳实践,最后谈谈平台未来的演进方向。
底层引擎统一,流批一体:目前平台的离线任务大部分是基于 Spark 完成的,流式数据采用了 Flink 处理,OLAP 引擎又引进了 presto,导致这套系统架构的运维成本比较高。我们看到 Flink 目前的 presto 能力和 Flinkbatch 的能力也在不断发展,因此我们后续会尝试切一些任务,做到真正意义上的统一引擎。
智能:引入算法进行数据驱动。考虑引入 ML 方法辅助阈值选取或者智能报警,根据数据等级自动推荐质量规则。举几个例子,比如我们可以基于时序算法智能的波动率监控来解决节假日流量高峰和平常的硬规则阈值的提升。
便捷:OLAP 对性能提升比较显著,但是目前我们只用在了数据探查功能上。后续可以将 OLAP 引擎应用于质量检测、数据据探查、数据对比应用与数据开发流程。
优化:比如通过单一 Job,同时运行多个监控,将监控和数据探查结合。我们现在在尝试将数据质量的规则生成和数据探查做结合,做到所见即所得的数据和规则的对应关系。
点击跳转大数据研发治理套件 DataLeap了解更多

小助手微信号:Bytedance-data 2021-12-29 加入
字节跳动数据平台团队,赋能字节跳动各业务线,对内支持字节绝大多数业务线,对外发布了火山引擎品牌下的数据智能产品,服务行业企业客户。关注微信公众号:字节跳动数据平台(ID:byte-dataplatform)了解更多









评论