
使用 LCM LoRA 4 步完成 SDXL 推理
LCM 模型 通过将原始模型蒸馏为另一个需要更少步数 (4 到 8 步,而不是原来的 25 到 50 步) 的版本以减少用 Stable Diffusion (或 SDXL) 生成图像所需的步数。蒸馏是一种训练过程,其主要思想是尝试用一个新模型来复制源模型的输出。蒸馏后的模型要么尺寸更小 (如 DistilBERT 或最近发布的 Distil-Whisper),要么需要运行的步数更少 (本文即是这种情况)。一般来讲,蒸馏是一个漫长且成本高昂的过程,需要大量数据、耐心以及一些 GPU 运算。
但以上所述皆为过往,今天我们翻新篇了!
今天,我们很高兴地公开一种新方法,其可以从本质上加速 Stable Diffusion 和 SDXL,效果跟用 LCM 蒸馏过一样!有了它,我们在 3090 上运行 任何 SDXL 模型,不需要 70 秒,也不需要 7 秒,仅需要约 1 秒就行了!在 Mac 上,我们也有 10 倍的加速!听起来是不是很带劲?那继续往下读吧!
方法概述
到底用了啥技巧?
在使用原始 LCM 蒸馏时,每个模型都需要单独蒸馏。而 LCM LoRA 的核心思想是只对少量适配器 (即 LoRA 层) 进行训练,而不用对完整模型进行训练。推理时,可将生成的 LoRA 用于同一模型的任何微调版本,而无需对每个版本都进行蒸馏。如果你已经迫不及待地想试试这种方法的实际效果了,可以直接跳到 下一节 试一下推理代码。如果你想训练自己的 LoRA,流程如下:
从 Hub 中选择一个教师模型。如: 你可以使用 SDXL (base),或其任何微调版或 dreambooth 微调版,随你喜欢。
在该模型上 训练 LCM LoRA 模型。LoRA 是一种参数高效的微调 (PEFT),其实现成本比全模型微调要便宜得多。有关 PEFT 的更详细信息,请参阅 此博文 或 diffusers 库的 LoRA 文档。
将 LoRA 与任何 SDXL 模型和 LCM 调度器一起组成一个流水线,进行推理。就这样!用这个流水线,你只需几步推理即可生成高质量的图像。
欲知更多详情,请 下载我们的论文。
快有啥用?
Stable Diffusion 和 SDXL 的快速推理为新应用和新工作流打开了大门,仅举几例:
更易得: 变快后,生成工具可以被更多人使用,即使他们没有最新的硬件。
迭代更快: 无论从个人还是商业角度来看,在短时间内生成更多图像或进行更多尝试对于艺术家和研究人员来说都非常有用。
可以在各种不同的加速器上进行生产化部署,包括 CPU。
图像生成服务会更便宜。
为了衡量我们所说的速度差异,在 M1 Mac 上用 SDXL (base) 生成一张 1024x1024 图像大约需要一分钟。而用 LCM LoRA,我们只需约 6 秒 (4 步) 即可获得出色的结果。速度快了一个数量级,我们再也无需等待结果,这带来了颠覆性的体验。如果使用 4090,我们几乎可以得到实时响应 (不到 1 秒)。有了它,SDXL 可以用于需要实时响应的场合。
快速推理 SDXL LCM LoRA 模型
在最新版的 diffusers 中,大家可以非常容易地用上 LCM LoRA:
代码所做的事情如下:
使用 SDXL 1.0 base 模型去实例化一个标准的 diffusion 流水线。
应用 LCM LoRA。
将调度器改为 LCMScheduler,这是 LCM 模型使用的调度器。
结束!
生成的全分辨率图像如下所示:

LCM LORA 微调后的 SDXL 模型用 4 步生成的图像
生成质量
我们看下步数对生成质量的影响。以下代码将分别用 1 步到 8 步生成图像:
生成的 8 张图像如下所示:

LCM LoRA 1 至 8 步生成的图像
不出所料,仅使用 1 步即可生成细节和纹理欠缺的粗略图像。然而,随着步数的增加,效果改善迅速,通常只需 4 到 6 步就可以达到满意的效果。个人经验是,8 步生成的图像对于我来说有点过饱和及“卡通化”,所以本例中我个人倾向于选择 5 步和 6 步生成的图像。生成速度非常快,你只需 4 步即可生成一堆图像,并从中选择你喜欢的,然后根据需要对步数和提示词进行调整和迭代。
引导比例及反向提示
请注意,在前面的示例中,我们将引导比例 guidance_scale 设为 1 ,实际上就是禁用它。对大多数提示而言,这样设置就可以了,此时速度最快,但会忽略反向提示。你还可以将其值设为 1 到 2 之间,用于探索反向提示的影响——但我们发现再大就不起作用了。
与标准 SDXL 模型的生成质量对比
就生成质量而言,本文的方法与标准 SDXL 流水线相比如何?我们看一个例子!
我们可以通过卸掉 LoRA 权重并切换回默认调度器来将流水线快速恢复为标准 SDXL 流水线:
然后,我们可以像往常一样对 SDXL 进行推理。我们使用不同的步数并观察其结果:

SDXL 流水线结果 (相同的提示和随机种子),步数分别为 1、4、8、15、20、25、30 和 50
如你所见,此示例中的生成的图像在大约 20 步 (第二行) 之前几乎毫无用处,且随着步数的增加,质量仍会不断明显提高。最终图像中的细节很不错,但获得这样的效果需要 50 步。
其他模型的 LCM LoRA
该技术也适用于任何其他微调后的 SDXL 或 Stable Diffusion 模型。仅举一例,我们看看如何在 collage-diffusion 上运行推理,该模型是用 Dreambooth 算法对 Stable Diffusion v1.5 微调而得。
代码与我们在前面示例中看到的代码类似。我们先加载微调后的模型,然后加载适合 Stable Diffusion v1.5 的 LCM LoRA 权重。

基于 Dreambooth Stable Diffusion v1.5 模型使用 LCM LoRA,4 步推理
Diffusers 全集成
LCM 在 diffusers 中的全面集成使得其可以利用 diffusers 工具箱中的许多特性和工作流,如:
对采用 Apple 芯片的 Mac 提供开箱即用的
mps支持。
内存和性能优化,例如 flash 注意力或
torch.compile()。
针对低 RAM 场景的其他内存节省策略,包括模型卸载。
ControlNet 或图生图等工作流。
训练和微调脚本。
测试基准
本节列出了 SDXL LCM LoRA 在各种硬件上的生成速度,给大家一个印象。忍不住再提一句,能如此轻松地探索图像生成真是太爽了!
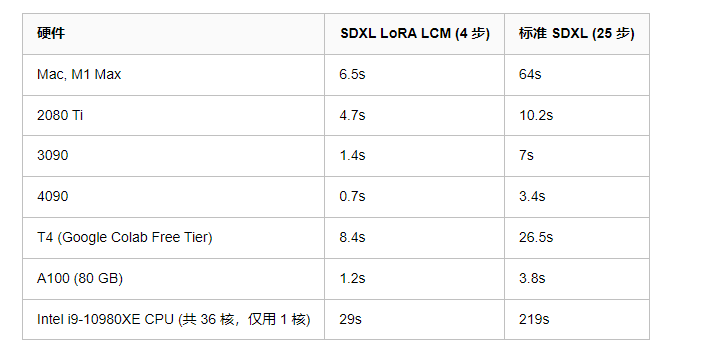
上述所有测试的 batch size 均为 1,使用是 Sayak Paul 开发的 这个脚本。
对于显存容量比较大的卡 (例如 A100),一次生成多张图像,性能会有显著提高,一般来讲生产部署时会采取增加 batch size 的方法来增加吞吐。
已公开发布的 LCM LoRA 及 LCM 模型
latent-consistency/lcm-lora-sdxl。SDXL 1.0 base 的 LCM LoRA 权重,上文示例即使用了该权重。
latent-consistency/lcm-lora-sdv1-5。Stable Diffusion 1.5 的 LCM LoRA 权重。
latent-consistency/lcm-lora-ssd-1b。segmind/SSD-1B 的 LCM LoRA 权重,该模型是经过蒸馏的 SDXL 模型,它尺寸比原始 SDXL 小 50%,速度快 60%。
latent-consistency/lcm-sdxl。对 SDXL 1.0 base 进行全模型微调而得的一致性模型。
latent-consistency/lcm-ssd-1b。对 segmind/SSD-1B 进行全模型微调而得的一致性模型。
加分项: 将 LCM LoRA 与常规 SDXL LoRA 结合起来
使用 diffusers + PEFT 集成,你可以将 LCM LoRA 与常规 SDXL LoRA 结合起来,使其也拥有 4 步推理的超能力。
这里,我们将 CiroN2022/toy_face LoRA 与 LCM LoRA 结合起来:

标准 LoRA 和 LCM LoRA 相结合实现 4 步快速推理
想要探索更多有关 LoRA 的新想法吗?可以试试我们的实验性 LoRA the Explorer (LCM 版本) 空间,在这里你可以把玩社区的惊人创作并从中获取灵感!
如何训练 LCM 模型及 LCM LoRA
最新的 diffusers 中,我们提供了与 LCM 团队作者合作开发的训练和微调脚本。有了它们,用户可以:
在 Laion 等大型数据集上执行 Stable Diffusion 或 SDXL 模型的全模型蒸馏。
训练 LCM LoRA,它比全模型蒸馏更简单。正如我们在这篇文章中所示,训练后,可以用它对 Stable Diffusion 实现快速推理,而无需进行蒸馏训练。
更多详细信息,请查阅代码库中的 SDXL 或 Stable Diffusion 说明文档。
我们希望这些脚本能够激励社区探索实现自己的微调。如果你将它们用于自己的项目,请告诉我们!
资源
文章转载自:HuggingFace

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论