
AQS 的今生,构建出 JUC 的基础
《AQS的前世,从1990年的论文说起》中我们已经对 AQS 做了简单的介绍,并学习了先于 AQS 出现的 3 种基于排队思想的自旋锁。今天我们深入到 AQS 的设计中,探究 Doug Lea 是如何构建 JUC 框架基础组件的。不过在正式开始前,我们先来回顾上一篇中提到的面试题:
原理相关:AQS 是什么?它是怎样实现的?
设计相关:如何使用 AQS 实现 Mutex?
希望今天可以帮你解答上面的问题。
Tips:
本文基于 Java 11 完成,与 Java 8 存在部分差异,注意区分;
Doug Lea The java.util.concurrent Synchronizer Framework 2004
非常幸运,2017 年就有大佬完成了论文的翻译:《The java.util.concurrent Synchronizer Framework》 JUC同步器框架(AQS框架)原文翻译
初衷与目的
《The java.util.concurrent Synchronizer Framework》中清晰的阐述了 Doug Lea 设计 AQS 的目的:
This framework provides common mechanics for atomically managing synchronization state, blocking and unblocking threads, and queuing.
(AQS)框架为同步状态的原子性管理,线程的阻塞和唤醒以及排队提供了一种通用的机制。也就是说,可以通过 AQS 去构建不同的同步器,如:基于 AQS 而诞生的 ReentrantLock。
基于构建通用同步机制的目的,Doug Lea 分析了各种同步器,总结出它们共同的特性:
acquire 操作:阻塞调用线程,直到同步状态允许其继续执行;
release 操作:改变同步状态,唤醒被阻塞的线程。
除此之外,论文中也提到了对 AQS 的性能要求,Doug Lea 认为大家在分析synchronized时提到的 2 个问题:
如何最小化空间开销(因为任意 Java 对象都可以作为锁)
如何最小化单核处理器的单线程环境下的时间开销
都不是 AQS 要考虑的,他认为 AQS 需要考虑的是 scalability(可伸缩性),即大部分场景中,即便存在竞争,也能提供稳定的效率。原文中是这样描述的:
Among the main goals is to minimize the total amount of time during which some thread is permitted to pass a synchronization point but has not done so.
(AQS)主要目标之一是使某一线程被允许通过同步点但还没有通过的情况下耗费的总时间最少,即从一个线程释放锁开始,到另一个线程获取锁,这个过程锁消耗的时间。
设计与实现
Doug Lea 先是完成了acquire操作和release操作的伪代码设计:
为了实现上述的操作,需要以下组件的协同工作:原子管理的同步状态,线程的阻塞与唤醒,以及队列。
同步状态
AQS 使用volatile修饰的int类型变量 state 保存同步状态,并提供getState,setState和compareAndSetState方法。
AQS 中,state 不仅用作表示同步状态,也是某些同步器实现的计数器,如:Semaphore中允许通过的线程数量,ReentrantLock中可重入特性的实现,都依赖于state作为计数器的特性。
早期,Java 对long类型变量的原子操作需要借助内置锁来完成,性能较差,并且除了CyclicBarrier外,其余同步器使用 32 位的int类型已经能够满足需求,因此在 AQS 诞生初期,state可以使用int类型。
Tips:
CyclicBarrier通过锁来实现;
Java 1.6 中提供了使用
long类型的AbstractQueuedLongSynchronizer;
注意要区别同步状态与线程在队列中的状态。
阻塞与唤醒
早期,线程的阻塞与唤醒只能通过Thread.suspend和Thread.resume实现,但存在竞态问题,即一个线程先调用了Thread.resume后调用Thread.suspend,那么Thread.resume不会产生任何作用。
AQS 使用LockSupport.park和LockSupport.unpark实现阻塞与唤醒,特点是如果LockSupport.unpark发生在LockSupport.park前,则此次的LockSupport.park无效。
Tips:无论提前调用多少次LockSupport.unpark,都只会使后一次LockSupport.park无效。
CLH 队列
队列的设计是构建 AQS 的关键,Doug Lea 在论文中使用“The heart of”来形容:
The heart of the framework is maintenance of queues of blocked threads, which are restricted here to FIFO queues.
Doug Lea 参考了 CLH 的设计, 保留了基本的设计,由前驱节点做阻塞与唤醒的控制,但是在队列的选择上做出了改变,AQS 选择双向链表来实现队列,节点中添加了prev和next指针。
添加prev指针主要是为了实现取消功能,而next指针的加入可以方便的实现唤醒后继节点。
AQS 源码分析
再次强调,本文基于 Java 11 完成,与 Java 8 的源码存在差异,如,操作同步状态state时,Java 8 借助了UnSafe,而 Java 11 中使用了VarHandle。另外,本文只讨论 AQS 的独占(EXCLUSIVE)模式,因此会跳过共享(SHARED)模式。
队列的结构
有了《AQS的前世,从1990年的论文说起》的铺垫,再结合 Doug Lea 论文中的描述,我们可以很容易想象到 AQS 中队列节点的结构:线程状态,前驱节点指针,后继节点指针以及用于保存线程的变量。事实也和我们的猜想十分接近:
注意,Node的waitStatus表示线程在队列中的状态,AQS 的state表示同步器的状态。Node中定义了waitStatus的 5 种状态:
CANCELLED:1,线程获取锁的请求已经取消;
SIGNAL :-1,节点释放后,需要唤醒后继节点;
CONDITION:-2,节点处于条件队列中;
PROPAGATE:-3,共享(SHARED)模式下使用;
0,初始化
Node时的默认值。
AQS 的实现中,并不是后继节点“监听”前驱节点的状态,来决定自身是否持有锁,而是通过前驱节点释放锁,并主动唤醒后继节点来实现排队的。
AQS 的结构
AQS 的结构就更加简单了:
总共 4 个成员变量,除了我们意料之中的,队列的头尾节点和 AQS 的同步状态外,还有SPIN_FOR_TIMEOUT_THRESHOLD。看名字会有些误解,以为是自旋的阈值,实际上并不是,AQS 提供了带有超时时间的方法,例如doAcquireNanos方法:
可以看到只有在剩余的nanosTimeout大于SPIN_FOR_TIMEOUT_THRESHOLD时,才会调用LockSupport.parkNanos(this, nanosTimeout)。
Tips:
Java 11 中,无论是 AQS 还是
Node中都使用了VarHandle,定义了大量的成员变量,我们跳过这部分;
删除了
doAcquireNanos方法中大部分内容,重点展示nanosTimeout和SPIN_FOR_TIMEOUT_THRESHOLD的关系。
获取锁
如果是你,你会如何设计 AQS 的加锁过程?
我可能会“按部就班”的构建队列,并将等待线程逐个的加入的队列中。那 Doug Lea 是如何设计 AQS 加锁过程的呢?
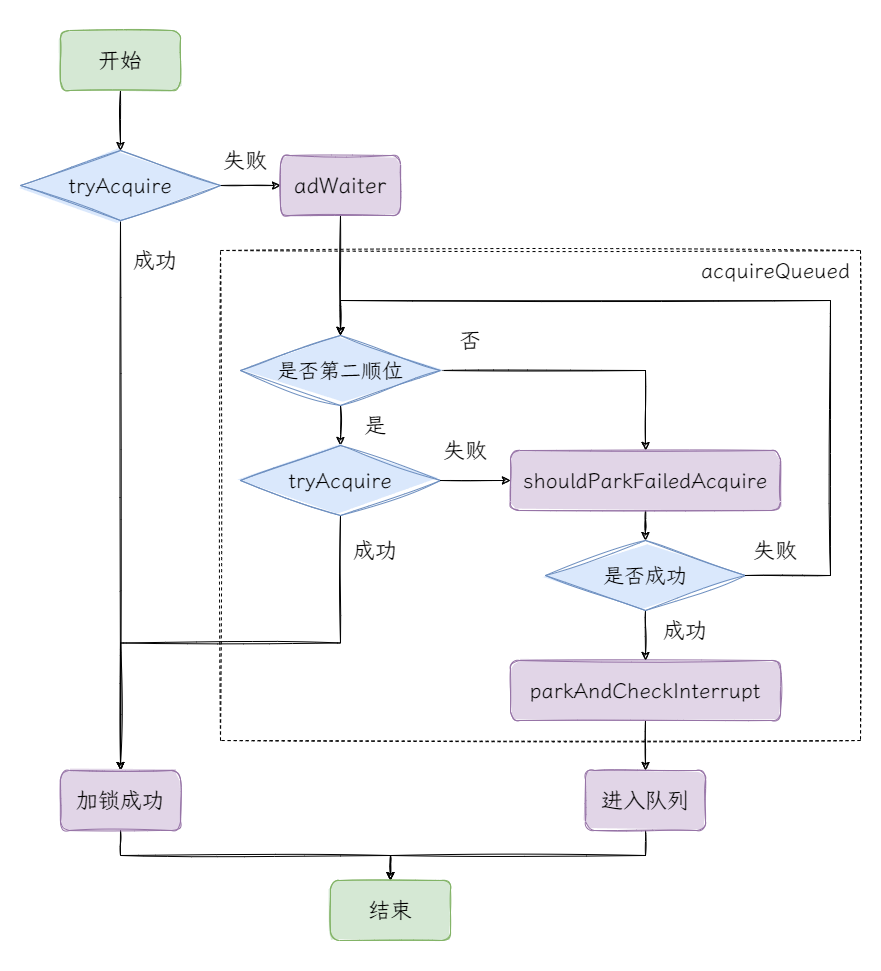
acquire方法中,Doug Lea 设计了 4 步操作,如果仅从名字来看,首先tryAcquire尝试获取锁,如果获取失败,则通过addWaiter加入等待,然后调用acquireQueued方法进入排队状态,最后是通过调用selfInterrupt方法使当前线程中断。先来看 AQS 中的tryAcquire方法。
AQS 中并未给出任何实现,它要求子类必须重写tryAcquire方法,否则抛出异常。、
addWaiter 方法
接着是addWaiter方法:
addWaiter的逻辑并不复杂:
注释 1:创建节点
node;
注释 2:获取 AQS 的尾节点
oldTail,并判断是否存在尾节点;
注释 3:初始化队列;
注释 4:创建空节点
h,作为 AQS 的头尾节点;
注释 5:更新 AQS 的尾节点为
node,并与oldTail关联。
我们知道,只有tryAcquire失败后,才会调用addWaiter方法,也就是说,如果实现了tryAcquire获取锁的逻辑,那么在没有竞争的场景下,AQS 就不会构建等待队列。
回过头来看addWaiter做了什么?它的核心功能是初始化的等待队列,并返回当前队列的尾节点。
acquireQueued 方法
当addWaiter创建了等待队列并返回尾节点后,就进入了acquireQueued方法中:
注释 1 的部分,获取到 node 的前驱节点 p,如果 p 为头节点,则当前线程直接通过tryAcquire尝试获取锁。如果 p 不是头节点的话可以直接调用tryAcquire吗?
答案是不可以,如果 p 不是头节点,也就证明当前线程不在获取锁的第二顺位上,前面可能还有若干节点在等待锁,如果任意节点都直接调用tryAcquire,那就失去了acquireQueued方法的意义。
注释 2 的部分,p 不是头节点的情况,也就是当前线程非第二顺位获取锁。那么 node 就要根据前驱节点的状态来判断是否中断执行了:
addWaiter的流程中可以看到,处理 node 的过程中并没有处理node.waitStatus,此时waitStatus == 0,那么对于 node 的前驱节点 pred 也是一样的,因次第一次执行shouldParkAfterFailedAcquire方法时,会进入注释 1 的部分,并返回false。
再次进入acquireQueued的循环后,shouldParkAfterFailedAcquire返回 true,执行parkAndCheckInterrupt方法,需要注意LockSupport.park(this)会让线程暂停在此处,也就是说如果没有线程唤醒,线程会一直停留在此处。
至此,AQS 的加锁过程已经结束了,我们画张图来回顾下这个过程:
释放锁
接着来看解锁的过程:
按照 AQS 的风格tryRelease必然是要交给子类实现的:
果不其然。
假设tryRelease执行成功,接下来会发生什么?
获取头节点 h;
判断头节点的状态
h.waitStatus != 0;
执行
unparkSuccessor。
来看unparkSuccessor的代码:
如果一切顺利,那么unparkSuccessor时会跳过注释 2 的部分,直接执行注释 1 的LockSupport.unpark。
不过别忘了,待唤醒的线程此时还在acquireQueued方法中阻塞着,唤醒的线程会继续执行acquireQueued中的内容,调用tryAcquire获取锁,并更新 AQS 的头节点。
我们设想一个场景:
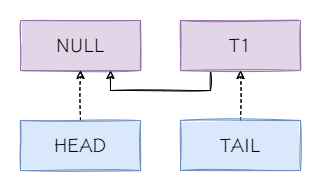
当addWaiter执行到compareAndSetTail(oldTail, node)时调用了unparkSuccessor,可能会出现一种情况:
即 T1 已经与 HEAD 建立了联系,但 HEAD 却没有与 T1 建立联系。因此注释 2 中,判断 HEAD 节点没有后继节点时,会通过 TAIL 节点,从后向前遍历等待队列,查找待唤醒的线程。
好了,AQS 的核心源码分析到这里就结束了,至于条件队列,共享模式等就留给大家自行探索了。
构建互斥锁
学习完 AQS 的核心原理后,我们来实践一下,借助 AQS 来构建构建互斥锁:
通过 AQS 实现只有基础功能的互斥锁还是非常简单的,甚至在重写tryAcquire方法时可以不设置独占线程(虽然在现在也没起到作用),只是简单的使用 CAS 替换掉 AQS 的 state 即可:
当然了,这只是一把“玩具锁”,还存在许多问题,比如,非上锁线程依旧可以解锁。其次除了阻塞还排队外,也不支持诸如可重入等高级特性。
结语
好了,关于 AQS 的部分就到这里了。如果你有看过《AQS 的前世,从 1990 年的论文说起》中基于排队思想自旋锁的演进过程,并理解了 MCS 锁和 CLH 锁的实现,那么理解 AQS 对你来说是非常容易的,虽然它们看起来是不同的东西,但核心原理是相同的,只是在技术实现上有些许差别。
最后,希望通过 AQS 的前世和今生,能够帮助你重新认识 AQS,理解 Doug Lea 设计这样一个同步器基础组件的意义。
文章转载自:王有志

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论