1.丘秉宜;2.邵伟;3.黄文;4.郭梦杰;5.刘利;6.刘波
1.亚马逊云科技 Hero;2.启科开发者生态负责人;3.启科 DEVOPS 工程师;4.启科量子资深研发工程师;5 和;6.C++高级开发工程师
1、概述
QuTrunk 是启科量子自主研发的一款免费、开源、跨平台的量子计算编程框架,包括量子编程 API、量子命令转译、量子计算后端接口等。它提供多种量子计算体验,提供本地量子计算 Python 计算后端,提供 OMP 多线程、MPI 多节点并行、GPU 加速等计算模式。本文将介绍如何使用 QuTrunk 的 MPI 并行计算模式利用亚马逊云科技的 ParallelCluster3 进行并行计算。在展示之前先和大家简要介绍所使用的到的相关技术的几个概念。
1.1 MPI 及 SLURM 集群简介
首先我们看下什么是 MPI?在程序中,不同的进程需要相互的数据交换,特别是在科学计算中,需要大规模的计算与数据交换,集群可以很好解决单节点计算力不足的问题,但在集群中大规模的数据交换是很耗费时间的,因此需要一种在多节点的情况下能快速进行数据交流的标准,这就是 MPI。MPI 是一组用于多节点数据通信的标准,而非一种语言或者接口。具体的使用方法需要依赖它的具体实现 (mpich or openmpi 等)。
我们通常通过 SLURM 集群来处理 MPI 高性能计算,Slurm (Simple Linux Utility for Resource Management, http://slurm.schedmd.com/ ) 是一个开源、容错、高度可扩展的集群管理和作业调度系统,适用于大型和小型 Linux 集群。Slurm 不需要对其操作进行内核修改,并且相对独立。作为集群工作负载管理器,Slurm 有三个关键功能。首先,它为用户分配一段时间内对资源(计算节点)的独占和/或非独占访问,以便他们可以执行工作。第二,它提供了一个框架,用于启动、执行和监视所分配节点集上的工作(通常是并行作业)。最后,它通过管理待定工作队列来仲裁资源争用。
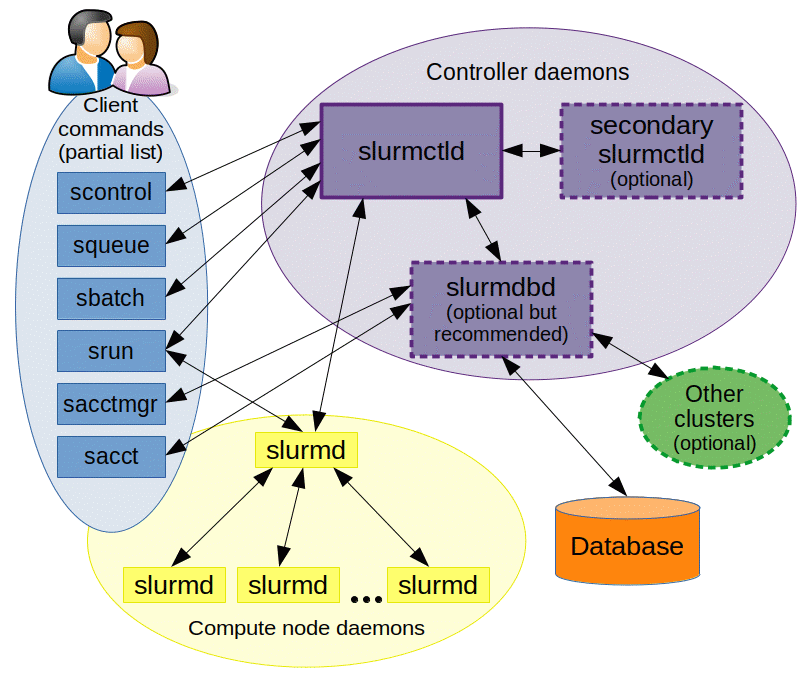
Slurm 的结构图如下所示,它采用 slurmctld 服务(守护进程)作为中心管理器用于监测资源和作业,为了提高可用性,还可以配置另一个备份冗余管理器。各计算节点需启动 slurmd 守护进程,以便被用于作为远程 shell 使用:等待作业、执行作业、返回状态、再等待更多作业。slurmdbd(Slurm DataBase Daemon) 数据库守护进程(非必需,建议采用,也可以记录到纯文本中等),可以将多个 slurm 管理的集群的记账信息记录在同一个数据库中。还可以启用 slurmrestd(Slurm REST API Daemon) 服务(非必需),该服务可以通过 REST API 与 Slurm 进行交互,所有功能都对应的 API。用户工具包含 srun 运行作业、 scancel 终止排队中或运行中的作业、 sinfo 查看系统状态、 squeue 查看作业状态、 sacct 查看运行中或结束了的作业及作业步信息等命令。 sview 命令可以图形化显示系统和作业状态(可含有网络拓扑)。 scontrol 作为管理工具,可以监控、修改集群的配置和状态信息等。用于管理数据库的命令是 sacctmgr ,可认证集群、有效用户、有效记账账户等。
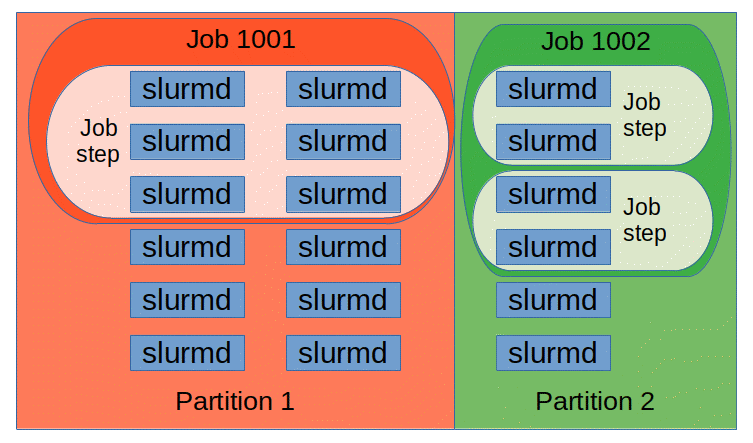
如下图所示,Slurm 守护进程管理的实体包括节点、Slurm 中的计算资源、将节点分组为逻辑(可能重叠)集合的分区、作业或在指定时间内分配给用户的资源分配,以及作业步骤,这些步骤是作业中的一组(可能并行)任务。分区可以被视为作业队列,每个队列都有各种约束,例如作业大小限制、作业时间限制、允许使用它的用户等。优先级排序的作业被分配给分区内的节点,直到该分区内的资源(节点、处理器、内存等)耗尽。一旦作业被分配了一组节点,用户就可以在分配中的任何配置中以作业步骤的形式启动并行工作。例如,可以启动单个作业步骤,该步骤利用分配给该作业的所有节点,或者多个作业步骤可以独立地使用分配的一部分。
1.2 Amazon ParallelCluster3 介绍
Amazon ParallelCluster 是亚马逊云科技支持的开源集群管理工具,可帮助您在亚马逊云中部署和管理高性能计算(HPC)集群。Amazon ParallelCluster 基于流行的开源 CfnCluster 项目构建,并通过 Python 包索引(PyPI)发布。ParallelCluster 的源代码托管在 GitHub 上的 Amazon Web Services 存储库中。Amazon ParallelCluster 免费提供,您只需支付运行应用程序所需的亚马逊云科技资源。
借助 ParallelCluster 工具用户能够在亚马逊云科技中快速构建 HPC 计算环境。它自动设置所需的计算资源和共享文件系统。用户可以将 Amazon ParallelCluster 与批处理调度器一起使用,例如 Amazon batch 和 Slurm。Amazon ParallelCluster 有助于快速启动概念验证部署和生产部署。也可以在 Amazon ParallelCluster 基础之上构建更高级别的工作流程,例如 CFD 高性能计算。
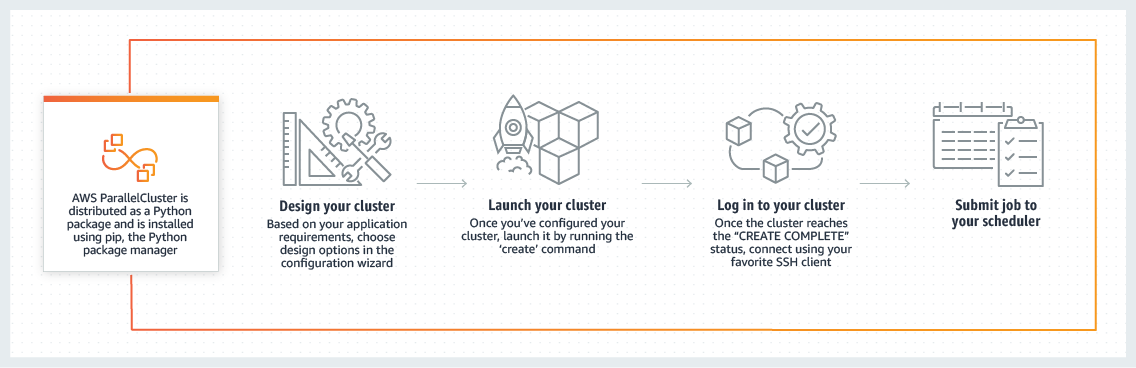
使用 ParallelCluster 的工作流程如下:1、设计集群;2、启动集群;3、登录集群;4、提交作业
下面章节将详细介绍通过如何通过 Amazon ParallelCluster 创建 HPC 集群环境,然后通过 qutrunk 编写程序在 Amazon HPC 环境下执行并行计算。
2、Amazon ParallelCluster 安装部署
2.1 安装准备
2.1.1 本地 Python 环境准备
Amazon ParallelCluster 作为 Python 包分发,并使用 Python pip 包管理器安装,Amazon ParallelCluster 需要 Python 3.7 或更高版本。
如果没有安装需要先进行安装。本文不介绍如何安装,用户可以从 Python 官网下载安装,查询 Python 版本命令如下
elven@pc-elvenhuang:~$ python3 --versionPython 3.10.6
复制代码
2.1.2 亚马逊云科技账号注册
登录亚马逊云科技的官网,点击创建亚马逊云科技账号进行注册,Amazon Console - Signup (amazon.com),注册好根账号后,登录到 Amazon Console,然后点击右上角账号名下拉,选择安全凭证,打开安装凭证设置页面。
在这里可以设置 MFA,还有访问秘钥,我们创建一个访问秘钥,并下载这个秘钥 rootkey.csv 保存备用。
2.1.3 创建秘钥对
为后面创建的 EC2 服务器登录准备,需要先创建好密钥对,密钥对与 EC2 资源相关,EC2 有 Region 属性,不同 Region 下的 EC2 需要创建不同的秘钥对,本实验中默认将使用新加坡资源,所以在此 Region 环境下的 EC2 服务下的密钥对创建一个密钥对备用。
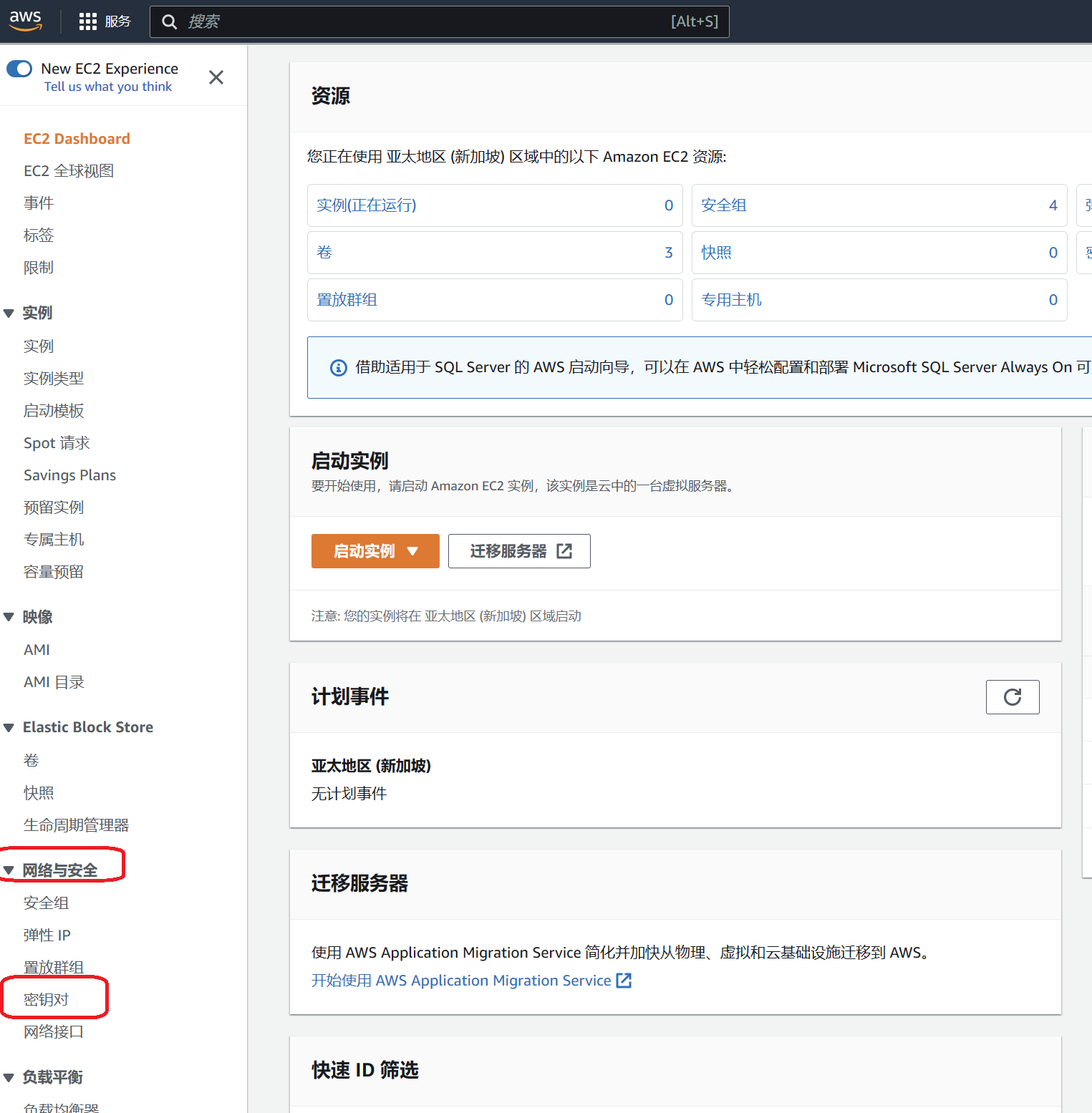
打开 EC2 服务首页,控制面板 | EC2 Management Console (amazon.com) 选择 Region 为 ap-southeast-1,然后选择左侧导航栏下的网络与安全,选择密钥对。
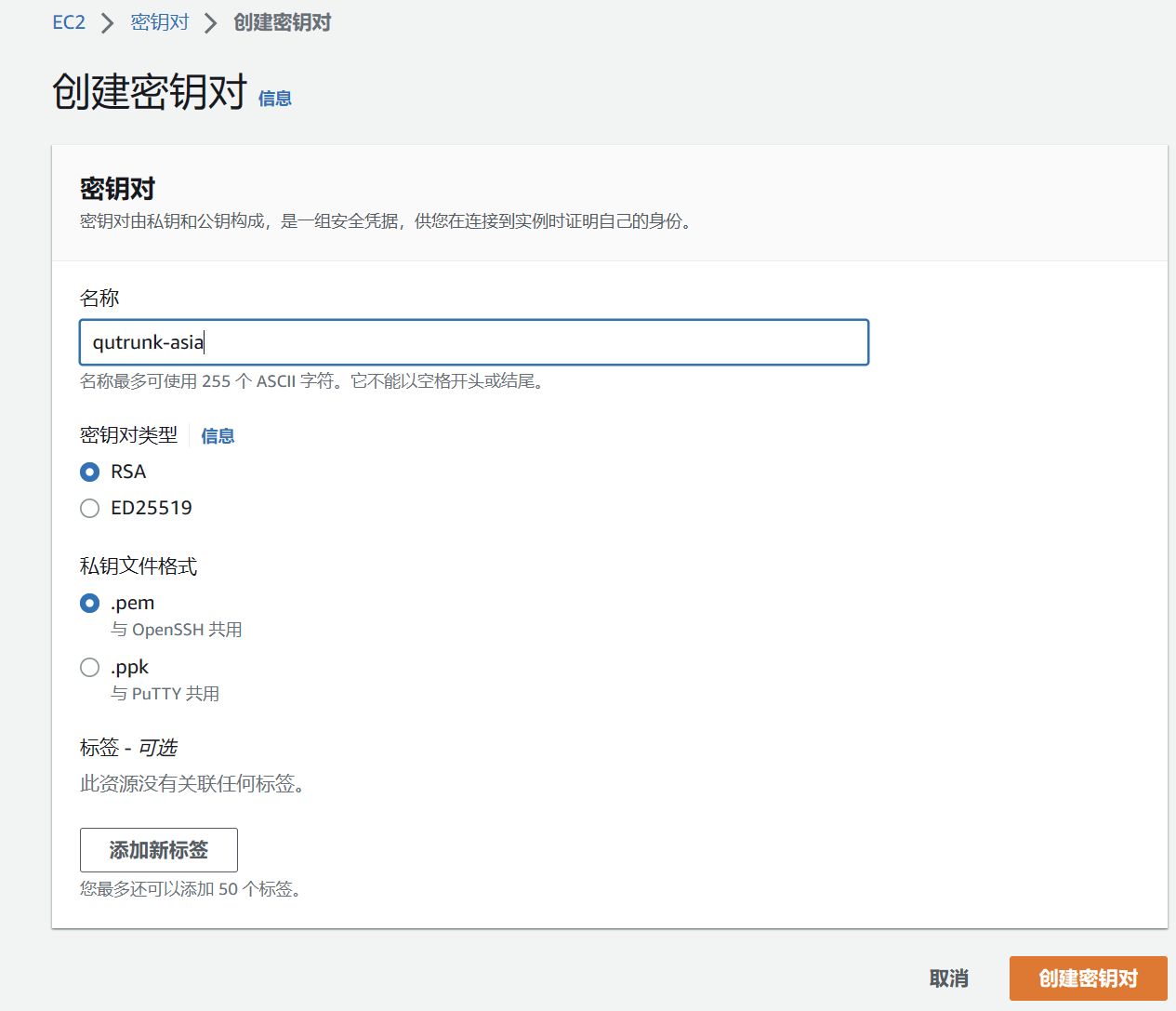
点击创建密钥对,打开创建密钥对的界面,选择 RSA 加密,秘钥格式选择与 openssh 共用,完成创建,并下载好备用。
2.2 安装 ParallelCluster
Amazon ParallelCluster 有两种安装方法:
在虚拟化环境中部署 ParallelCluster(推荐方式)
在非虚拟化环境部署 ParallelCluster
本文采用虚拟化环境下部署的方式安装 ParallelCluster。
2.2.1 安装虚拟化环境
$ python3 -m pip install --upgrade pip$ python3 -m pip install --user --upgrade virtualenv
复制代码
2.2.2 创建虚拟化环境并激活
$ python3 -m virtualenv ~/apc-ve$ source ~/apc-ve/bin/activate
复制代码
2.2.3 虚拟化环境下安装 Amazon ParallelCluster
(apc-ve)elven@pc-elvenhuang:~$ python3 -m pip install --upgrade "aws-parallelcluster"
复制代码
安装完之后,然后安装 npm,npm 的安装需要用到 github 资源,国内网络环境访问较慢,我们这里采用加速方式下载,在 github 的 url 前添加加速:https://ghproxy.com/ 命令行如下:
(apc-ve)elven@pc-elvenhuang:~$ curl -o- https://ghproxy.com/https://raw.githubusercontent.com/nvm-sh/nvm/v0.38.0/install.sh | bash(apc-ve)elven@pc-elvenhuang:~$ chmod ug+x ~/.nvm/nvm.sh(apc-ve)elven@pc-elvenhuang:~$ source ~/.nvm/nvm.sh(apc-ve)elven@pc-elvenhuang:~$ nvm install --lts(apc-ve)elven@pc-elvenhuang:~$ node --version
复制代码
安装完成后,查询 ParallelCluster 安装版本
(apc-ve)elven@pc-elvenhuang:~$ pcluster version
复制代码
安装的是最新的版本 3.4.
2.2.4 安装 Amazon CLI 工具
Amazon CLI 工具需要在 root 权限下安装,首先下载安装包,然后解压后进行 sudo 安装。
(apc-ve)elven@pc-elvenhuang:~$ curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"(apc-ve)elven@pc-elvenhuang:~$ unzip awscliv2.zip(apc-ve)elven@pc-elvenhuang:~$ sudo ./aws/install(apc-ve)elven@pc-elvenhuang:~$ /usr/local/bin/aws --version
复制代码
安装完成后查询安装的版本
2.2.5 执行 Amazon Configure
打开前面准备阶段生成的 rootkey.csv 文件,Amazon Configure 需要使用到 ak 和 sk,执行如下命令:
(apc-ve) elven@pc-elvenhuang:~$ aws configure
复制代码
根据提示分别输入 CLI 访问亚马逊云科技的 rootkey.csv 中的 ak 和 sk,默认的 Region 根据个人需求设置,本示例中设置为 ap-southeast-1,默认的输出格式设置为 json 格式。
2.2.6 规划集群配置
安装好 Amazon CLI 工具之后,我们开始进行集群规划配置,资源分区我们选择亚太新加坡站点:ap-southeast-1,登录 ec2 的密钥对选择提取创建好的密钥对:qutrunk-asia,调度器使用 slurm,操作系统选择 ubunutu20.04 系统,选择创建 vpc,Headnode 节点配置公网 IP。
HeadNode 节点的规格选择 t2.medium,computenode 的规格默认为 t2.micro。命令行执行如下:
(apc-ve) elven@pc-elvenhuang:~$ pcluster configure --config cluster-config.yamlINFO: Configuration file cluster-config.yaml will be written.Press CTRL-C to interrupt the procedure.
Allowed values for AWS Region ID:1. ap-northeast-12. ap-northeast-23. ap-south-14. ap-southeast-15. ap-southeast-26. ca-central-17. eu-central-18. eu-north-19. eu-west-110. eu-west-211. eu-west-312. sa-east-113. us-east-114. us-east-215. us-west-116. us-west-2AWS Region ID [ap-southeast-1]: 4Allowed values for EC2 Key Pair Name:1. qutrunk-asia #需要提前创建好的keypairEC2 Key Pair Name [qutrunk-asia]: 1Allowed values for Scheduler:1. slurm2. awsbatchScheduler [slurm]: 1Allowed values for Operating System:1. alinux22. centos73. ubuntu18044. ubuntu2004Operating System [alinux2]: 4Head node instance type [t2.micro]: t2.mediumNumber of queues [1]:Name of queue 1 [queue1]:Number of compute resources for queue1 [1]:Compute instance type for compute resource 1 in queue1 [t2.micro]:Maximum instance count [10]:Automate VPC creation? (y/n) [n]: yAllowed values for Availability Zone:1. ap-southeast-1a2. ap-southeast-1b3. ap-southeast-1cAvailability Zone [ap-southeast-1a]:Allowed values for Network Configuration:1. Head node in a public subnet and compute fleet in a private subnet2. Head node and compute fleet in the same public subnetNetwork Configuration [Head node in a public subnet and compute fleet in a private subnet]: 1Beginning VPC creation. Please do not leave the terminal until the creation is finalizedCreating CloudFormation stack...Do not leave the terminal until the process has finished.
An exception occurred while creating the CloudFormation stack: parallelclusternetworking-pubpriv-20221226053603. For details please check log file: /home/elven/.parallelcluster/pcluster-cli.log]:
复制代码
编辑集群规划文件 config-cluster.ymal,设置集群最小数量为 2(默认为 0),修改后如下
2.2.7 创建集群
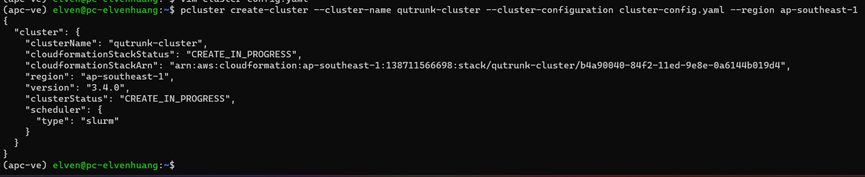
通过 Amazon configure 产生的集群配置文件进行集群创建,执行命令行如下,执行完成后 console 将显示集群创建信息,状态显示为:CREATE_IN_PROGRESS
(apc-ve) elven@pc-elvenhuang:~$ pcluster create-cluster --cluster-name qutrunk-cluster --cluster-configuration cluster-config.yaml --region ap-southeast-1{ "cluster": { "clusterName": "qutrunk-cluster", "cloudformationStackStatus": "CREATE_IN_PROGRESS", "cloudformationStackArn": "arn:aws:cloudformation:ap-southeast-1:138711566698:stack/qutrunk-cluster/b4a90040-84f2-11ed-9e8e-0a6144b019d4", "region": "ap-southeast-1", "version": "3.4.0", "clusterStatus": "CREATE_IN_PROGRESS", "scheduler": { "type": "slurm" } }}
复制代码
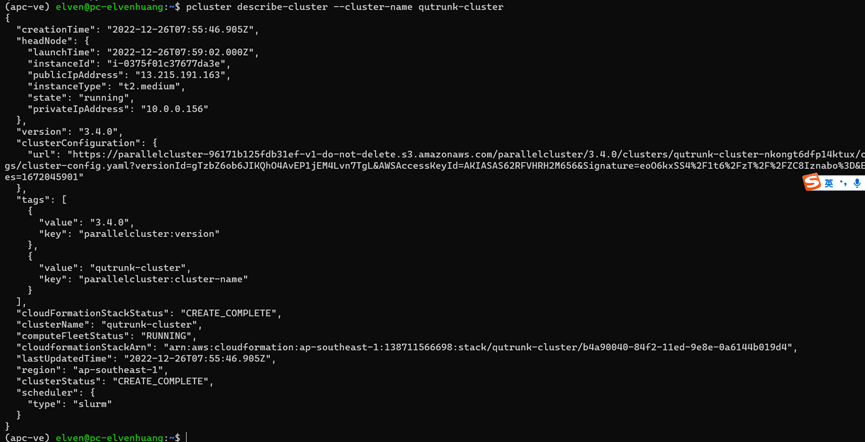
集群创建需要时间,等待几分钟后,创建完成集群就可查询集群的信息:
(apc-ve) elven@pc-elvenhuang:~$ pcluster describe-cluster --cluster-name qusprout-cluster
复制代码
2.2.8 登录集群,安装 qutrunk
查询 HeadNode 节点的公网 IP,在 EC2 服务首页上,查询账号下创建好的集群资源,如下图,公网 IP 为 18:141.186.170
(apc-ve) elven@pc-elvenhuang:~$ pcluster ssh --cluster-name qutrunk-cluster -i qutrunk-asia.pem
Welcome to Ubuntu 20.04.5 LTS (GNU/Linux 5.15.0-1026-aws x86_64)
* Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage
System information as of Mon Dec 26 08:17:40 UTC 2022
System load: 0.0 Processes: 167 Usage of /: 48.3% of 33.74GB Users logged in: 0 Memory usage: 14% IPv4 address for eth0: 10.0.0.156 Swap usage: 0%
* Ubuntu Pro delivers the most comprehensive open source security and compliance features.
https://ubuntu.com/aws/pro
0 updates can be applied immediately.
New release '22.04.1 LTS' available.Run 'do-release-upgrade' to upgrade to it.
Last login: Mon Dec 26 08:07:38 2022 from 116.30.100.20To run a command as administrator (user "root"), use "sudo <command>".See "man sudo_root" for details.
复制代码
2.2.9 编写 slurm 任务脚本及 grover 量子计算程序
激活虚拟化环境,然后登录集群
elven@pc-elvenhuang:~$ source ~/apc-ve/bin/activate(apc-ve) elven@pc-elvenhuang:~$ pcluster ssh --cluster-name qusprout-cluster -i /root/qusprout.pem
复制代码
创建任务文件:
ubuntu@ip-10-0-0-156:~$ vi sleep.jab #!/bin/bash #SBATCH -J sleep #SBATCH -N 2 #SBATCH -n 2 #SBATCH -o %j.sleep #SBATCH -e %j.sleep module load openmpi/4.1.4 srun --mpi=pmix python3 /home/ubuntu/grover_distribute.py
复制代码
创建 QuTrunk 编写的 grover 程序:
ubuntu@ip-10-0-0-156:~$ vi grover_distribute.py"""Grover's search algorithm."""
import mathimport randomimport time
from numpy import pi
from qutrunk.circuit import QCircuitfrom qutrunk.circuit.gates import Measure, Allfrom qutrunk.circuit.ops import PLUS, QAAfrom qutrunk.backends import BackendLocal
def run_grover(qubits=10, backend=None): # Quantum qubits num_qubits = qubits
# Number of amplitudes num_elems = 2**num_qubits
# Count of iteration num_reps = math.ceil(pi / 4 * math.sqrt(num_elems)) print("num_qubits:", num_qubits, "num_elems:", num_elems, "num_reps:", num_reps)
# Choose target state randomly random.seed(int(time.time())) sol_elem = random.randint(0, num_elems - 1) print(f"target state: |{str(sol_elem)}>")
# Create quantum circuit with local python simulator circuit = QCircuit(backend=backend, resource=True)
# Allocate quantum qubits qureg = circuit.allocate(num_qubits)
# Set inital amplitudes to plus state PLUS * qureg
# Apply quantum operator(gates) QAA(num_reps, sol_elem) * qureg
# Measure for all qubits All(Measure) * qureg
# Run circuit in local simulator res = circuit.run()
# Get measure result and print as int outlist = res.get_bitstrs() for out in outlist: print("measure result: " + str(int(out, base=2)))
# Print quantum circuit resource information circuit.show_resource()
# Print quantum circuit execution information print(res.running_info())
return circuit
if __name__ == "__main__": # Run locallycircuit = run_grover(backend=BackendLocal(run_mode='mpi'))
复制代码
2.2.10 Amazon HPC 集群上执行 QuTrunk 编写的 grover 算法程序
使用 sbatch 提交作业,根据 job 任务脚本,生成的日志文件为 jobid.sleep,运行完成后打印出 jobid,通过 jobid.sleep 查询执行结果
ubuntu@ip-10-0-0-156:~$ sbatch -N 2 sleep.jabSubmitted batch job 15ubuntu@ip-10-0-0-156:~$ ls1.sleep 14.sleep 2.sleep 4.sleep 8.sleep grover_mpi.py qutrunk-0.1.16-py3-none-any.whl13.sleep 15.sleep 3.sleep 5.sleep grover_distribute.py qutrunk-0.1.15-py3-none-any.whl sleep.jabubuntu@ip-10-0-0-156:~$ cat 15.sleepnum_qubits: 10 num_elems: 1024 num_reps: 26target state: |49>prob of state |49> = 0.008766189217567406prob of state |49> = 0.02422384859551111prob of state |49> = 0.047108250571214524prob of state |49> = 0.07706217555206976prob of state |49> = 0.1136180505208738prob of state |49> = 0.15620524772962407prob of state |49> = 0.2041589920509928prob of state |49> = 0.2567307379460278prob of state |49> = 0.31309985406630053prob of state |49> = 0.37238643309688396prob of state |49> = 0.43366502688182906prob of state |49> = 0.4959790924303827prob of state |49> = 0.5583559233055302prob of state |49> = 0.6198218333197522prob of state |49> = 0.6794173555244317prob of state |49> = 0.7362122192406237prob of state |49> = 0.7893198713436073prob of state |49> = 0.8379113151277344prob of state |49> = 0.8812280507304697prob of state |49> = 0.9185939151189513prob of state |49> = 0.949425636819952prob of state |49> = 0.9732419406366319prob of state |49> = 0.9896710602298116num_qubits: 10 num_elems: 1024 num_reps: 26target state: |49>prob of state |49> = 0.008766189217567406prob of state |49> = 0.02422384859551111prob of state |49> = 0.047108250571214524prob of state |49> = 0.07706217555206976prob of state |49> = 0.1136180505208738prob of state |49> = 0.15620524772962407prob of state |49> = 0.2041589920509928prob of state |49> = 0.2567307379460278prob of state |49> = 0.31309985406630053prob of state |49> = 0.37238643309688396prob of state |49> = 0.43366502688182906prob of state |49> = 0.4959790924303827prob of state |49> = 0.5583559233055302prob of state |49> = 0.6198218333197522prob of state |49> = 0.6794173555244317prob of state |49> = 0.7362122192406237prob of state |49> = 0.7893198713436073prob of state |49> = 0.8379113151277344prob of state |49> = 0.8812280507304697prob of state |49> = 0.9185939151189513prob of state |49> = 0.949425636819952prob of state |49> = 0.9732419406366319prob of state |49> = 0.9896710602298116prob of state |49> = 0.9984565412943175prob of state |49> = 0.9994612447443189prob of state |49> = 0.9926694874189682measure result: 49==================Counter==================Counter(quit=10)qubits = 10quantum_gates = 1476total_time = 0.2812964916229248qutrunk_time = 0.00911855697631836backend_time = 0.27217793464660645{"backend": "BackendLocal", "task_id": "5f58421b395946b5920569d89eecf6c9", "status": "success", "arguments": {"shots": 1}}prob of state |49> = 0.9984565412943175prob of state |49> = 0.9994612447443189prob of state |49> = 0.9926694874189682measure result: 49==================Counter==================Counter(quit=10)qubits = 10quantum_gates = 1476total_time = 0.2712569236755371qutrunk_time = 0.008275508880615234backend_time = 0.2629814147949219{"backend": "BackendLocal", "task_id": "777271ab058a416f8c58d00be819e9fa", "status": "success", "arguments": {"shots": 1}}
复制代码
通过执行日志结果可以看到,并行 2 个节点执行,执行时间总体月 0.27s,执行成功。
我们再看看单节点执行情况下,即对脚本直接运行,执行命令如下:
ubuntu@ip-10-0-0-156:~$ python3 grover_distribute.pynum_qubits: 10 num_elems: 1024 num_reps: 26target state: |601>prob of state |601> = 0.008766189217567406prob of state |601> = 0.02422384859551111prob of state |601> = 0.047108250571214524prob of state |601> = 0.07706217555206976prob of state |601> = 0.1136180505208738prob of state |601> = 0.15620524772962407prob of state |601> = 0.2041589920509928prob of state |601> = 0.2567307379460278prob of state |601> = 0.31309985406630053prob of state |601> = 0.37238643309688396prob of state |601> = 0.43366502688182906prob of state |601> = 0.4959790924303827prob of state |601> = 0.5583559233055302prob of state |601> = 0.6198218333197522prob of state |601> = 0.6794173555244317prob of state |601> = 0.7362122192406237prob of state |601> = 0.7893198713436073prob of state |601> = 0.8379113151277344prob of state |601> = 0.8812280507304697prob of state |601> = 0.9185939151189513prob of state |601> = 0.949425636819952prob of state |601> = 0.9732419406366319prob of state |601> = 0.9896710602298116prob of state |601> = 0.9984565412943175prob of state |601> = 0.9994612447443189prob of state |601> = 0.9926694874189682measure result: 601==================Counter==================Counter(quit=10)qubits = 10quantum_gates = 1372total_time = 0.32742834091186523qutrunk_time = 0.010069131851196289backend_time = 0.31735920906066895{"backend": "BackendLocal", "task_id": "927411ab557341c79ebc3abaaa2ef420", "status": "success", "arguments": {"shots": 1}}
复制代码
从结果可以看到单节点执行下运行结果是总体运行时间为 0.32s,对比并行下的 0.27s,使用 hpc 对 QuTrunk 量子程序计算进行了加速。
我们程序默认设置的是 10 个量子比特,通过增加 grover 算法程序中的量子比特,例如增加量子比特到 20,并行执行下的程序将比单节点直接运行时间提升将是非常明显的,有兴趣的读者可以尝试下。本文就不再测试。只是展示一种利用 Amazon Parallel 集群进行并行计算的方法供读者参考。
2.2.11 资源释放
1、删除集群
elven@pc-elvenhuang:~$ cd apc-ve/ elven@pc-elvenhuang:~/apc-ve$ source bin/activate (apc-ve) elven@pc-elvenhuang:~/apc-ve$ cd (apc-ve) elven@pc-elvenhuang:~$ pcluster delete-cluster --region ap-southeast-1 --cluster-name qutrunk-cluster
复制代码
2、删除 parallelclusternetworking
(apc-ve) elven@pc-elvenhuang:~$ aws --region ap-southeast-1 cloudformation list-stacks --stack-status-filter "CREATE_COMPLETE" --query "StackSummaries[].StackName" | grep -e "parallelclusternetworking-" "parallelclusternetworking-pubpriv-20221226074428"ubuntu@ip-10-0-0-156:~$ aws --region ap-southeast-1 cloudformation delete-stack --stack-name parallelclusternetworking-pubpriv-20221226074428
复制代码
3、删除安全组及 VPC
除默认的安全组和 vpc 外,其他创建的资源逐个删除
3、总结
以上通过 Amazon ParallelCluster 工具创建 Amazon HPC 集群环境,然后在此环境上安装 QuTrunk 编程框架,通过 QuTrunk 量子计算程序 grover 算法示例,然后使用 mpi 运行模式在 Amazon HPC 集群下执行并行计算,加速了量子计算程序的运行。QuTrunk 最新版本已经支持 hpc 集群下的 mpi 计算,本次示例也是 QuTrunk 与亚马逊云科技技术结合的一个小小尝试,QuTrunk 未来还会推出分布式量子计算的模式,也将与亚马逊云科技结合推动量子应用的在各行业的广泛应用。
本篇作者:
Keith Yan(丘秉宜)中国首位亚马逊云科技 Community Hero。
Bertran Shao(邵伟),启科量子开发者关系负责人,国内首个开源量子计算社区发起者。
黄文,启科 DEVOPS 工程师。
Marz Kuo(郭梦杰),启科量子资深研发工程师,量子计算开源框架维护人。
刘利,C++ 高级开发工程师,经历多个项目开发,C+ + 后端经验丰富,熟悉项目敏捷开发。
刘波,C++ 高级开发工程师,多年高并发分布式后台编程经验,爱好追求各种技术。





























评论