
日均数亿推送稳定性监控实践
前言:
得物消息中心每天推送数亿消息给得物用户,每天引导数百万的有效用户点击,为得物 App 提供了强大,高效且低成本的用户触达渠道。这么庞大的系统,如何去监控系统的稳定性,保证故障尽早发现,及时响应至关重要。为此,我们搭建了得物消息中心 SLA 体系,相关架构如图:
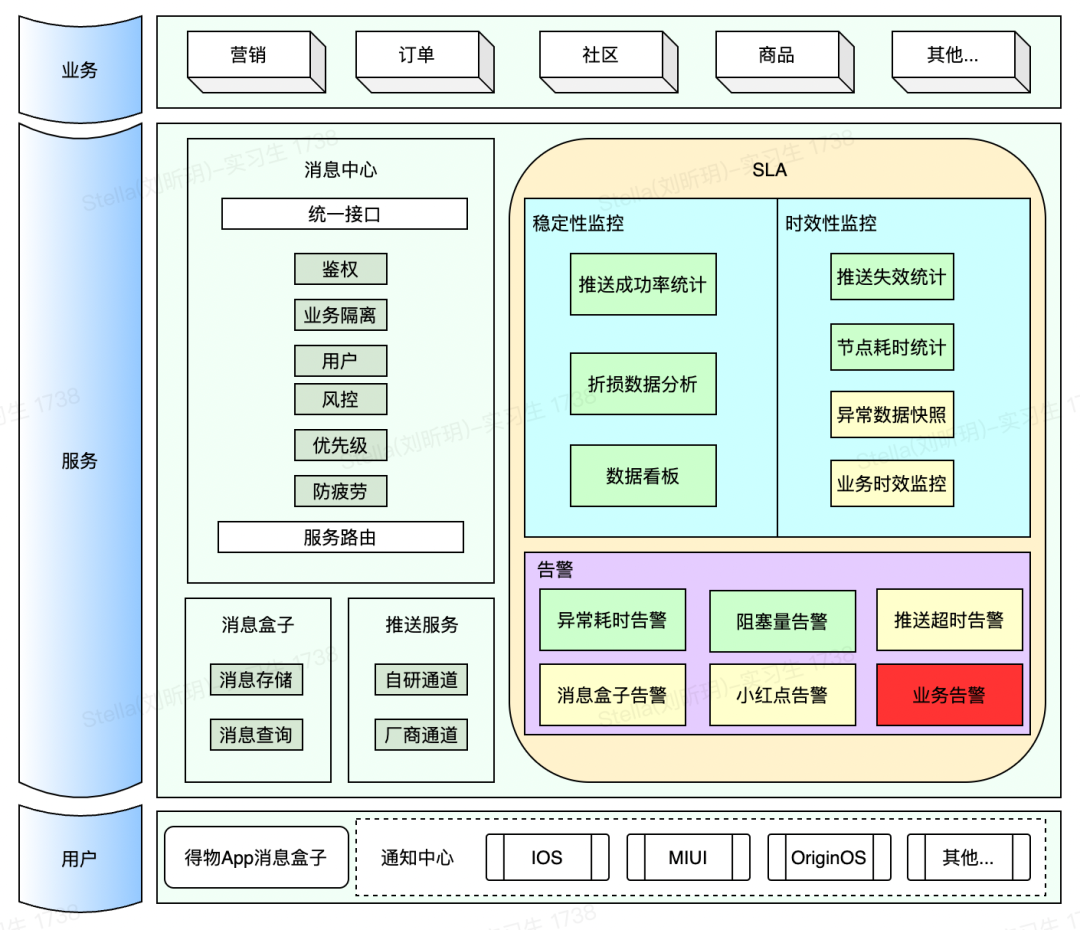
本文主要介绍我们如何实现 SLA 监控体系,并一步步重构优化的,作为过去工作的经验总结分享给大家。
1. 背景
得物消息中心主要承接上游各业务的消息推送请求,如营销推送、商品推广、订单信息等。消息中心接受业务请求后,会根据业务需求去执行【消息内容检验,防疲劳,防重复,用户信息查询,厂商推送】等节点,最后再通过各手机厂商及得物自研的在线推送通道触达用户。整体推送流程简化如下:

我们希望能够对各个节点提供准确的 SLA 监控指标和告警能力,从而实现对整体系统的稳定性保证。下面是我们设计的部分指标:
监控指标
节点推送量
节点推送耗时
节点耗时达标率
整体耗时达标率
节点阻塞量
其他指标
告警能力
节点耗时告警
节点阻塞量告警
其他告警能力
那我们如何实现对这些指标的统计呢?最简单的方案就是在每个节点的入口和出口增加统计代码,如下:
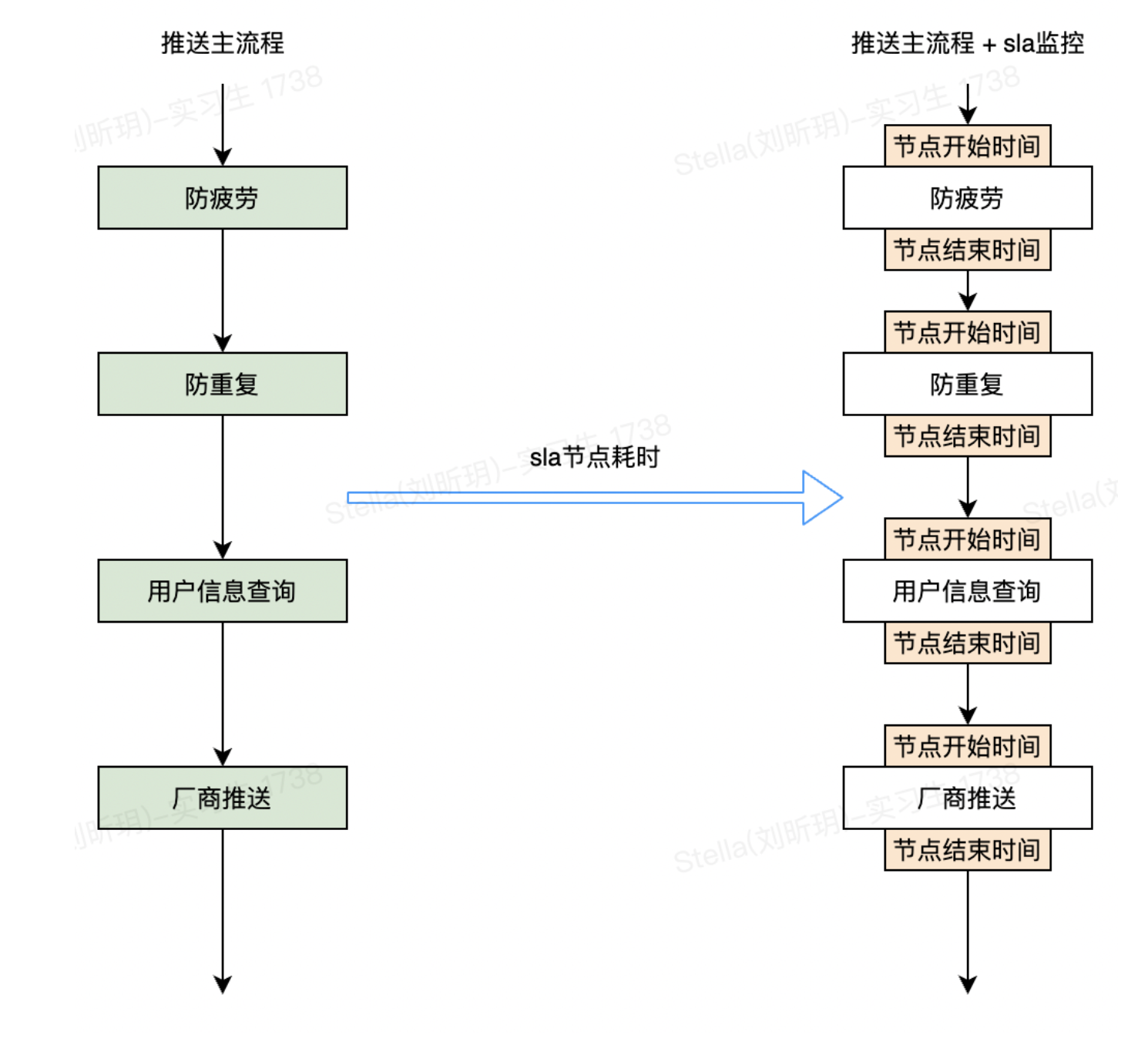
这就是我们的方案 0 我们用这种方案快速落地了 SLA-节点推送数量统计的开发。但是这个方案的缺点也很明显,考虑以下几个问题:
如何实现另一个 SLA 指标开发?比如节点耗时统计,也需要在每个节点的方法内部增加统计代码。
如果有新的节点需要做 SLA 统计,怎么办?需要把所有的统计指标在新节点上面再实现一遍。如何避免 SLA 统计逻辑异常导致推送主流程失败?到处加 try{}catch()去捕获异常吗?
如何分工?除了节点耗时统计外还有很多其他指标要实现。最简单的分工方式就是按照 SLA 指标来分工,各自领几个指标去开发,问题在于各个指标的统计逻辑都耦合在一起,按照统计指标来分工事实上变的不可能。
项目开发不好分工,通常意味着代码耦合度过高,是典型的代码坏味道,需要及时重构。
2. 痛点和目标
从上面的几个问题出发,我们总结出方案 0 的几个痛点,以及我们后续重构的目标。
2.1 痛点
监控节点不清晰。消息推送服务涉及多个不同的操作步骤。这些步骤我们称之为节点。但是这些节点的定义并不明确,只是我们团队内部约定俗成的一些概念。这就导致日常沟通和开发中有很多模糊空间。
在项目开发过程中,经常会碰到长时间的争论找不到解法。原因往往是大家对基础的概念理解没有打通,各说各话。这时候要果断停止争论,首先对基本概念给出一致的定义,然后再开始讨论。模糊的概念是高效沟通的死敌。
维护困难。
每个节点的统计都需要修改业务节点的代码,统计代码分散在整个系统的各个节点,维护起来很麻烦;
同时推送流程的主要逻辑被淹没在统计代码中。典型的代码如下,一个业务方法中可能有三分之一是 SLA 统计的代码。
影响性能
SLA 监控逻辑都在推送线程中处理,有些监控统计比较耗时,降低了推送效率。
统计代码会频繁的写 Redis 缓存,对缓存压力较大。最好是能把部分数据写入本地缓存,定时去合并到 Redis 中。
难以扩展
新的节点需要监控时,没办法快速接入,需要到处复制监控逻辑。
新的监控指标要实现的话,需要修改每个业务节点的代码。
2.2 目标
理清问题之后,针对系统既有的缺陷,我们提出了以下的重构目标:
主流程的归主流程,SLA 的归 SLA。
SLA 监控代码从主流程逻辑中剥离出来,彻底避免 SLA 代码对主流程代码的污染。
异步执行 SLA 逻辑计算,独立于推送业务主流程,防止 SLA 异常拖垮主流程。
不同监控指标的计算相互独立,避免代码耦合。
实现 SLA 监控代码一次开发,到处复用。
快速支持新监控指标的实现。
复用已有监控指标到新的节点,理想的方式是在节点方法上加个注解就能实现对该节点的统计和监控。
3. 分步解题
3.1 节点定义
SLA 是基于节点来实现的,那么节点的概念不容许有模糊的空间。因此在重构开始之前,我们把节点的概念通过代码的形式固定下来。
3.2 AOP
接下来考虑解耦主流程代码和 SLA 监控代码。最直接的方式当然就是 AOP 了。
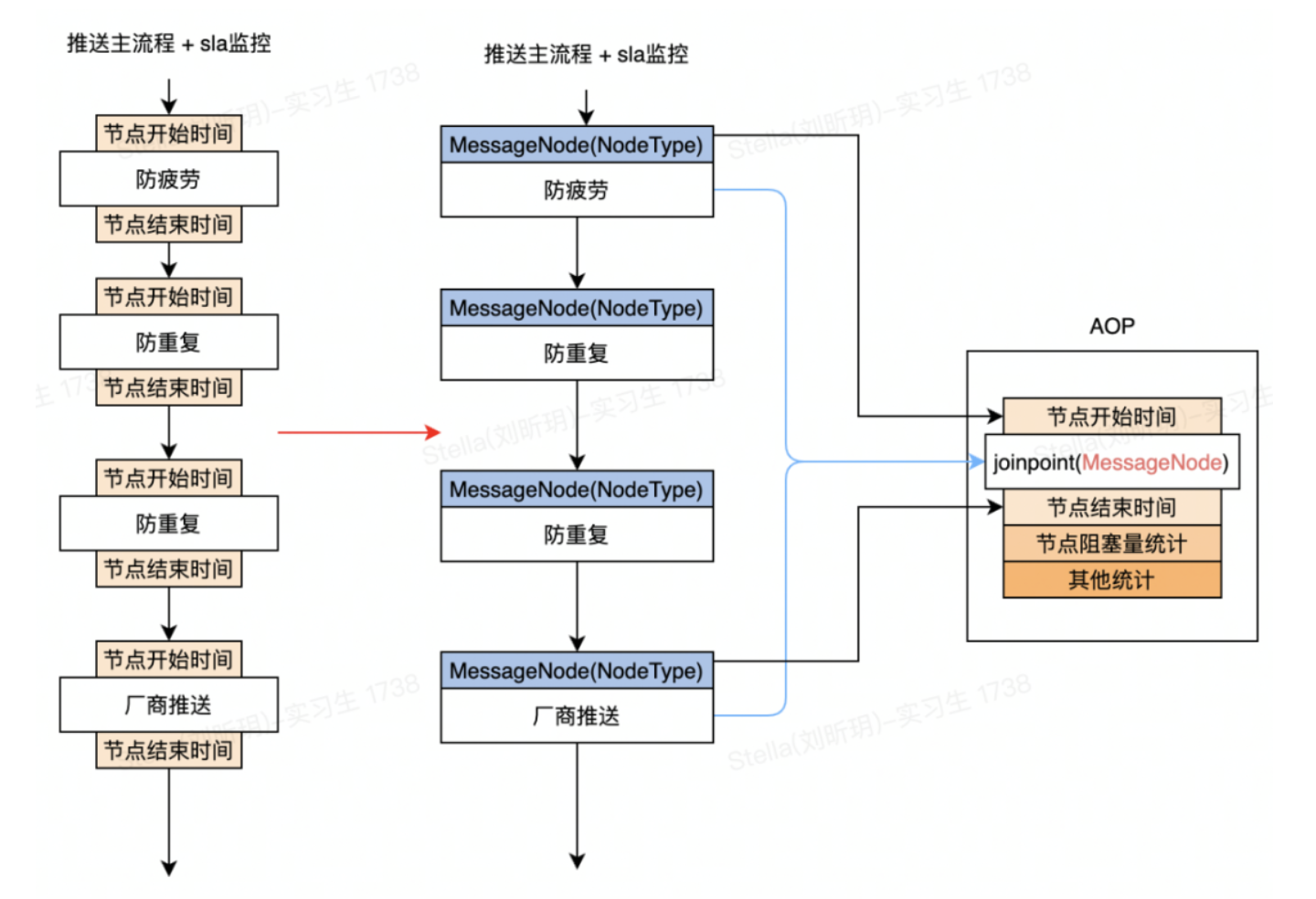
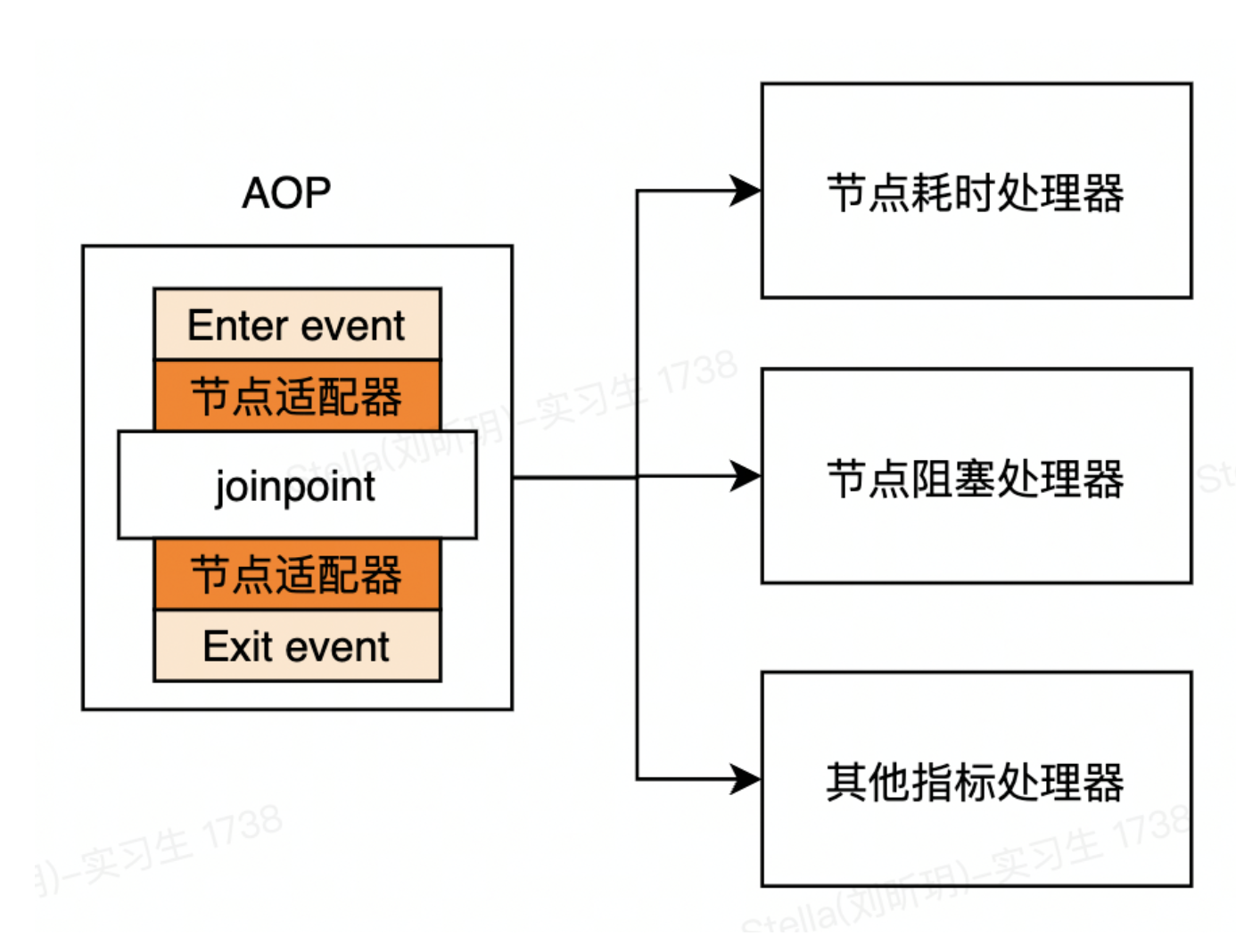
以上是节点耗时统计的优化设计图。把每个推送节点作为 AOP 切点,把每个节点上的 SLA 统计迁移到 AOP 中统一处理。到这里,就实现了 SLA 代码和主流程代码的解耦。但这还只是万里长征第一步。如果有其他的统计逻辑要实现怎么办?是否要全部堆积在 AOP 代码里面?
3.3 观察者模式
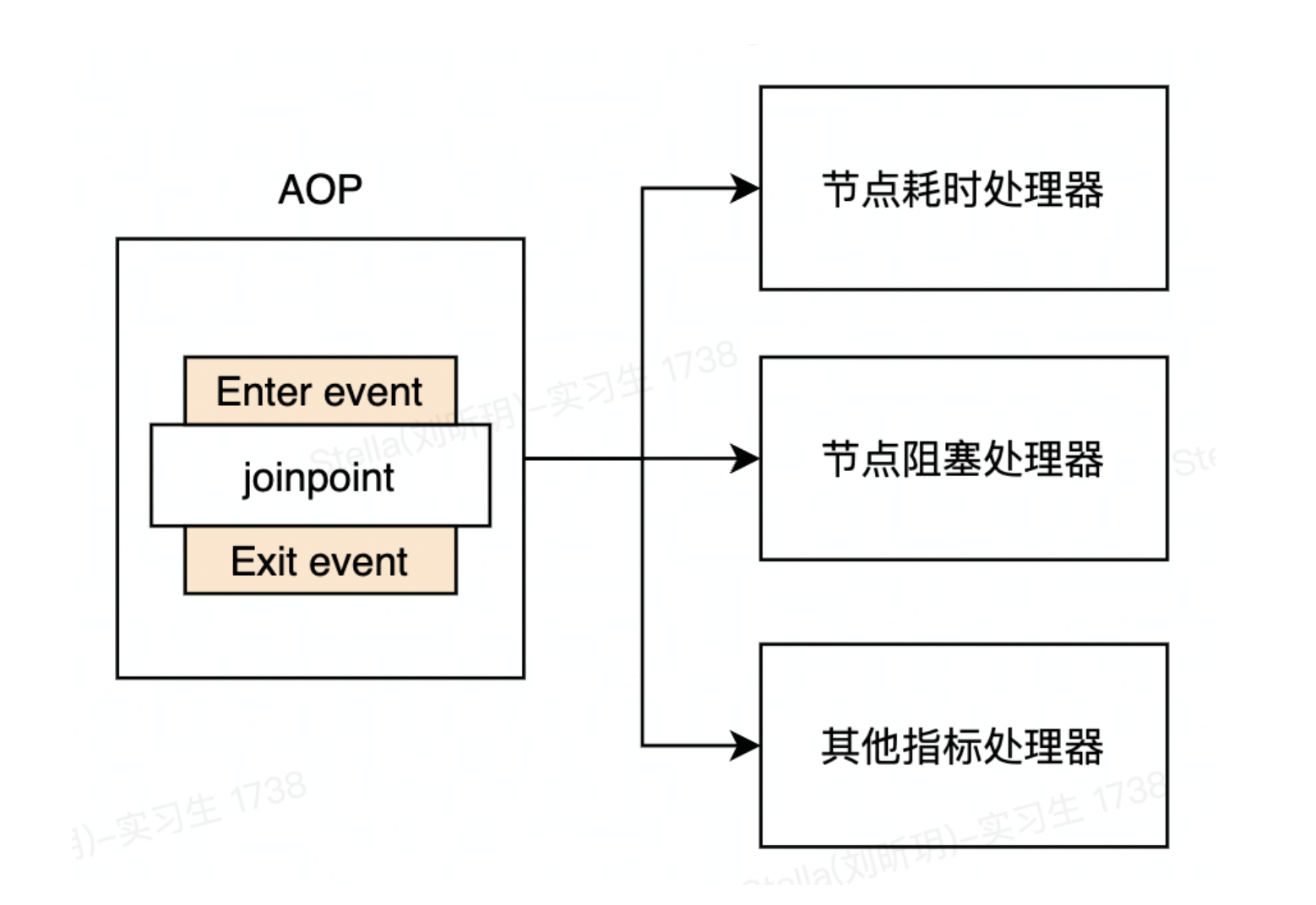
SLA 有很多个统计指标。我们不希望把所有指标的统计逻辑都堆积在一起。那么如何进行解耦呢?答案是观察者模式。我们在 AOP 切点之前发出节点进入事件(EnterEvent),切点退出之后发出节点退出事件(ExitEvent)。把各个指标统计逻辑抽象成节点事件处理器。各个处理器去监听节点事件,从而实现统计指标间的逻辑解耦。
3.4 适配器
这里还需要考虑一个问题。各个节点的出参和入参都不一致,我们如何才能把不同节点的出入参统一成 event 对象来分发呢?如果我们直接在 AOP 代码中去判断切点所属的节点,并取出该节点的参数,再去生成 event 对象,那么 AOP 的逻辑复杂度会迅速膨胀,并且需要经常变动。比较好的方式是应用适配器模式。AOP 负责找到切点对应的适配器,由适配器去负责把节点参数转为 event 对象,于是方案演变如下:
4. 整体方案
现在我们对每个问题都找到了相应的解法,再把这些解法串起来,形成完整的重构方案。重构之后,SLA 逻辑流程如下:
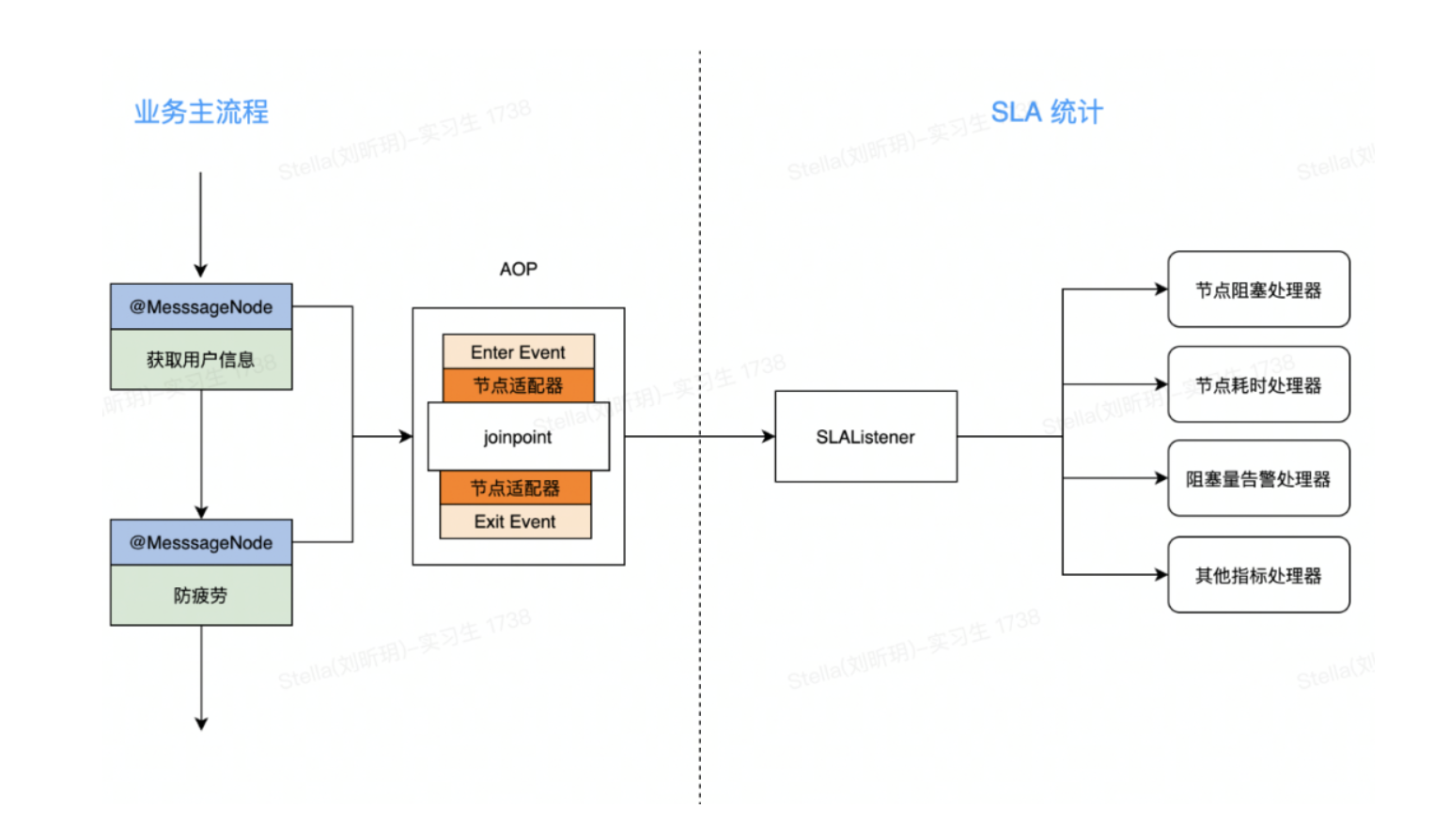
到这里方案整体设计完成。在动手实现之前,还需要和方案相关成员同步设计方案,梳理潜在风险,并进行分工。涉及到全流程的重构,光有纸面的方案,很难保证方案评估的完整性和有效性。我们希望能够验证方案可行性,尽早的暴露方案的技术风险,保证项目相关小伙伴对方案的理解没有大的偏差。这里推荐一个好的方式是提供方案原型。
4.1 原型
方案原型是指对既有方案的一个最简单的实现,用于技术评估和方案说明。
正所谓 talk is cheap, show me the code。对程序员来说,方案设计的再完美,也没有可运行的代码有说服力。我们大概花了两个小时时间基于现有设计快速实现了一个原型。原型代码如下:
AOP 切面类 EventAop,负责把增强代码织入切点执行前后。
事件配置类 EventConfig, 这里直接使用 Spring event 广播器,负责分发 event。
MessageEvent, 继承 Spring event 提供的 ApplicationEvent 类。
节点适配器工厂类, 获取节点对应的适配器,把节点信息转换为 MessageEvent 对象。
4.2 技术审查
在整体方案和原型代码的基础上,我们还需要审查方案中所用的技术,是否有风险,评估这些风险对既有功能,分工排期等的影响面。比如我们这边用到的主要是 Spring AOP, Spring Event 机制,那么他们可能潜在以下问题,需要在开发前就做好评估的:
Spring AOP 的问题:Spring AOP 中私有方法无法增强。bean 自己调用自己的 public 方法也无法增强。
Spring Event 的问题:默认事件处理和事件分发是在同一个线程中运行的,实现时需要配置 Spring 事件线程池,把事件处理线程和业务线程分隔开。
潜在的技术问题要充分沟通。每个成员的技术背景不同,你眼里很简单的技术问题,可能别人半天就爬不出来。方案设计者要充分预知潜在的技术问题,提前沟通,避免无谓的问题排查,进而提升开发效率。
4.3 成本收益分析
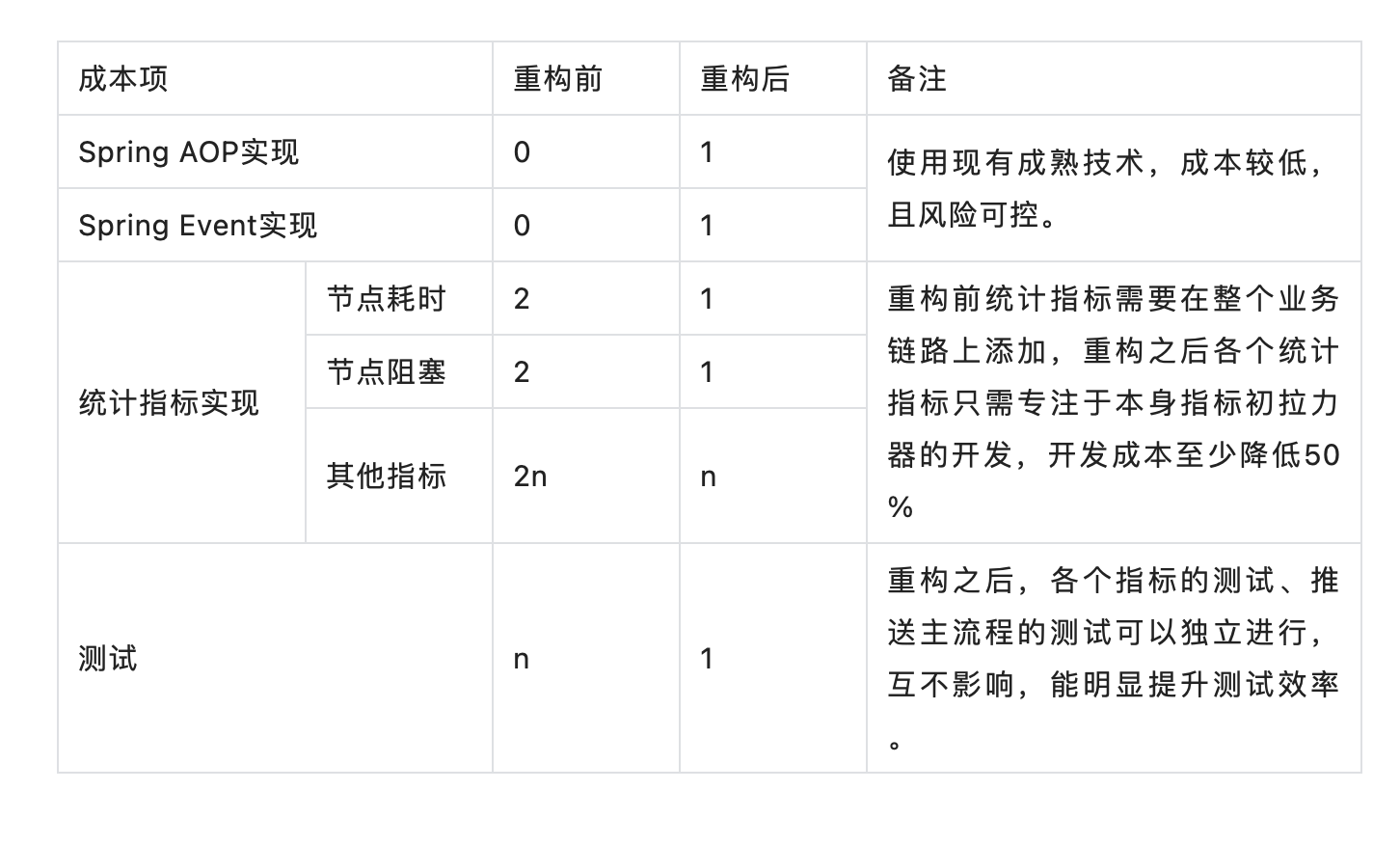
成本
一套完整的方案考虑的不仅仅是技术可行性,还需要考虑实现成本。我们通过一个表格来简单说明我此次重构前后的成本对比。
收益
代码清晰。SLA 统计逻辑和流程逻辑解耦。SLA 各个指标的统计完全解耦,互不依赖。
提升开发效率。SLA 指标统计一次开发,到处复用。只要在需要监控的代码上加上节点注解。
提高性能。SLA 逻辑在独立的线程中执行,不影响主流程。
提高稳定性。SLA 逻辑和主流程解耦,SLA 频繁变更也不影响主流程代码,也不会由于 SLA 异常拖垮主流程。
方便分工排期。重构也解决了不好分工的难题。由于各个指标通过重构实现了逻辑隔离,实现时完全可以独立开发。因此我们可以简单的按照 SLA 统计指标来安排分工。
代码重构最难的不是技术,而是决策。决定系统是否要重构,何时重构才是最难的部分。往往一个团队会花费大量时间去纠结是否要重构,但是到最后都没人敢做出最终决策。之所以难是因为缺乏决策材料。可以考虑引入成本收益表等决策工具,对重构进行定性、定量分析,帮助我们决策。
5. 避坑指南
实现的过程也碰到的一些比较有意思的坑,下面列出来供大家参考。
5.1 AOP 失效
Spring AOP 使用 cglib 和 jdk 动态代理实现对原始 bean 对象的代理增强。不管是哪种方式,都会为原始 bean 对象生成一个代理对象,我们调用原始对象时,实际上是先调用代理对象,由代理对象执行切片逻辑,并用反射去调用原始对象的方法,实际上运行如下代码。
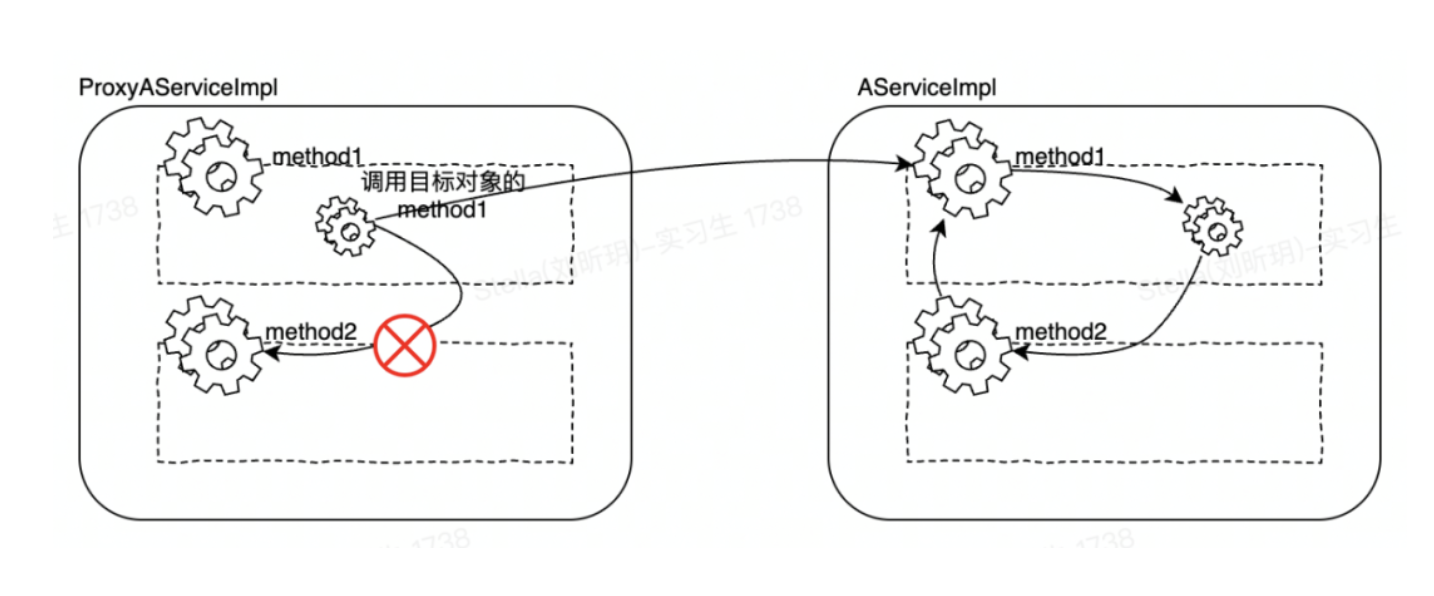
这时候如果被调用方法是原始对象本身的方法,那就不会调用代理对象了。这就导致代理对象逻辑没有执行,从而不触发代码增强。具体原理参考以下例子,假设我们有一个服务实现类 AServiceImpl,提供了 method1(), method2()两个方法。其中 method1()调用了 method2()。
我们的 AOP 代码通过 @MessageNode 注解作为切点织入统计逻辑。
Spring 启动的时候,IOC 容器会为 AserviceImpl 生成两个实例,一个是原始 AServiceImpl 对象,一个是增强过后的 ProxyAserviceImpl 对象,方法 method1 的调用过程如下,可以看到从 method1()去调用 method2()方法的时候,没有走代理对象,而是直接调用了目标对象的 method2()方法。
5.1.1 解决办法
注入代理对象 aopSelf,主动调用代理对象 aopSelf 的方法。
示例代码如下:
以上方法治标不治本。我们从头探究为何会出现自调用的代码增强?原因是我们要对两个不同的节点进行 SLA 统计增强。但是这两个节点的方法定义在同一个 Service 类当中,这显然违反了编码的单一功能原则。因此更好的方式应该是抽象出一个单独的类来处理。代码如下:
重构能够帮助我们发现并且定位代码坏味道,从而指导我们对坏代码进行重新抽象和优化。
5.2 通用依赖包
实现中碰到的另一个问题,是如何提供通用依赖。由于消息中心内部分很多不同的微服务,比如我们有承接外部业务推送请求的 Message 服务,还有把业务请求转发给各个手机厂商的 Push 服务,还有推送到达后,给得物 App 打上小红点的 Hot 服务等等,这些服务都需要做 SLA 监控。这时候就需要把现有的方案抽象出公共依赖,供各服务使用。
我们的做法是把【节点定义,AOP 配置,Spring Event 配置,节点适配器接口类】抽象到 common 依赖包,各个服务只需要依赖这个 common 包就可以快速接入 SLA 统计能力。
这里有一个比较有意思的点,像【AOP 配置,Spring Event 配置, 节点适配器】这些 Bean 的配置,是要开放给各个服务自己配置,还是直接在 common 包里默认提供配置?比如下面的这个 Bean 配置,决定了 Spring Event 处理线程池的关键配置项,如核心线程数,缓存池大小。
这个配置交给各个服务自己管理,灵活性会高一点,但同时意味着服务对 common 包的使用成本也高一点,common 包使用者需要自己去决定配置内容。相对的,在 common 包中直接提供呢,灵活性降低,但是用起来方便。后面参照 Spring Boot 约定大于配置的设计规范,还是决定直接在 common 包中提供配置,逻辑是各个服务对这些配置的需求不会有太大差别,为了这点灵活性提升使用成本,不是很有必要。当然如果后续有服务确实需要不同的配置,还可以根据实践需求灵活支持。
约定大于配置,也可以叫做约定优于配置(convention overconfiguration),也称作按约定编程,是一种软件设计范式,指在减少软件开发人员需做决定的数量,获得简单的好处,而又不失灵活性。
我们都知道 Spring, Spring Boot 的理念很先进,而实践中能够借鉴先进理念指导开发实践也算是一种工程人员的幸福,正如孔老夫子所说:就有道而正焉,可谓好学矣。
5.3 业务结果
代码实现之后,又进行了性能压测,线上灰度发布,线上数据观察等等步骤,在这里就不再赘述。那么 SLA 技术演进到这里,为我们的推送业务获取了哪些业务结果呢?下面提供比较典型的结果。
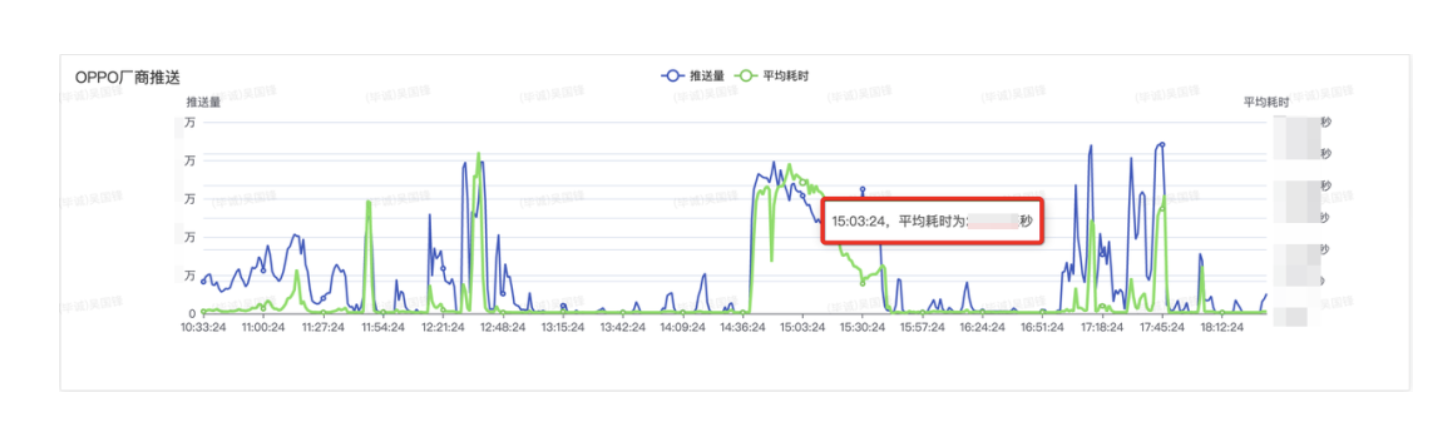
消息推送服务会调用手机厂商的推送服务接口,我们要监控厂商推送接口的耗时性能怎么办呢?在重构之前,我们需要在各个厂商推送接口之前和之后增加统计代码,计算耗时并写入缓存。在重构之后,我们要做的,只是简单的添加一个节点注解即可实现。比如我们想统计 OPPO 推送接口的 SLA 指标,只需添加如下注解:
然后我们在控制台就能很快发现 OPPO 推送的统计信息。比如我们看控制台上 OPPO 推送瓶颈耗时 20s,那说明 OPPO 的推送连接肯定有超时,连接池的配置需要优化。
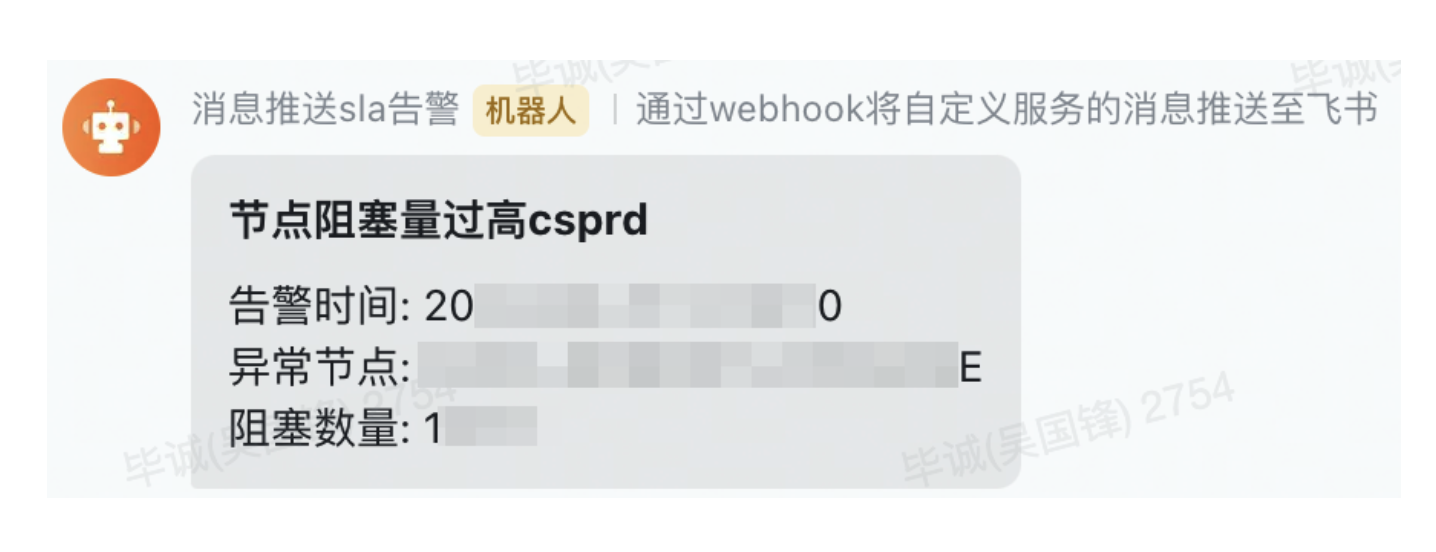
除了监控指标,我们还支持实时告警,比如下面这个节点阻塞告警,我们能够及时发现系统中堆积多的节点,迅速排查是否节点有卡顿,还是上游调用量猛增,从而把潜在的线上问题扼杀在摇篮之中。
6. 展望未来
SLA 上线一周之内,我们就已经依赖这套技术发现系统中的潜在问题,但是事实上对 SLA 的业务收益我们完全可以有更大的想象空间。比如说:
我们目前监控的主要还是技术上的指标,像节点耗时,节点阻塞等。后续我们可以把业务相关的统计也支持上,我们可以迅速定位是哪个业务方的调用导致系统阻塞等等业务性能数据。
其次我们可以统计各业务推送的 ROI 数据,目前消息服务支持数亿的消息,但是这里面哪些推送收益高,哪些收益低目前是没有明确的指标的。我们可以收集各业务的推送量,点击量等信息去计算业务推送的 ROI 指标。
当我们有了业务性能数据,业务 ROI 指标,我们就有机会对业务推送做精细化的管控,比如今天推送资源紧张,我是否可以暂缓低 ROI 的业务推送。比如高 ROI 推送今天已经触达过用户,我们是否可以取消当天的类似推送,防止打扰用户等等。
这些都是消息中心 SLA 能够为业务进行推送赋能的方向,而且这些方向可以基于目前的 SLA 技术架构迅速低成本的落地,真正实现技术服务于业务,技术推动业务。
7. 总结
以上是消息中心 SLA 重构演进的整个过程。对于消息服务来说,SLA 的开发没有尽头,我们要持续关注系统的核心指标,不断完善监控工具。正因为如此,我们更需要夯实 SLA 的技术基础,在灵活轻量的技术底座上去实现更复杂的功能。回过头看这个重构过程,我们也总结了以下一些经验供大家参考。
不要害怕重构,也不要过度设计。重构的目的不在于炫技,而在于解决实际问题,提高开发效率。
要有原型。复杂的设计往往难以开展,解决办法是从最小实践开始。方案原型就是方案设计的最小实践,有了原型之后再审查设计,演进方案会方便很多。
对技术充分掌控。预知所用技术的潜在风险,保证有足够的技术能力去解决。并且要把风险提前暴露给团队成员,减少踩坑几率,避免无谓的开发调试成本。
*文/吴国锋
版权声明: 本文为 InfoQ 作者【得物技术】的原创文章。
原文链接:【http://xie.infoq.cn/article/692edcfdd40869bed82717136】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

得物APP技术部 2019.11.13 加入
关注微信公众号「得物技术」









评论