
DeepSeek 太火,但老板们别慌,这里有份 AI 项目开展手册
这两天有老板陆续在咨询:到底应该如何基于 DeepSeek 开展 AI 项目?
抛开一些偏细节、偏敏感的付费内容,其实有一套方法论倒是可以分享。
第一,也是最重要一点:目标是什么?
AI 产品的目标是什么?
据群里的粉丝反馈,开工第一天几乎所有的老板都在讨论 AI、讨论 DeepSeek。
并有多个 CEO 表示:后续业务开展,全面拥抱 AI,并期待实现行业应用的领先!
说实话,这个味道很熟悉,基本又回到了两年前 ChatGPT 刚诞生的情况,很多公司出于焦虑或者想要抢占行业注意力,都做好了准备 All In AI,但这里我要泼一点冷水:你的急迫可能导致巨大损失!
一、DeepSeek 并没有领先于 GPT
首先,所有人必须认识到的一个事实是:虽然 DeepSeek 非常优秀,但他并没有领先于 GPT!
换句话说,之前各位可以根据 GPT 的 API 调用完成的功能,如果基座模型换成 DeepSeek 后,他的表现可能还会差点。
DeepSeek 真正的价值在于两点:
第一、合规性,他是国内的开源模型,并且能力优秀,这可以为医疗、金融等相对敏感的行业松绑,他们有更优的基座模型选择了。
而由于基座模型的进化可能带来的价值是:实现路径的大幅成本降低!这可以节约不少钱。
第二、可以私有化部署,并且训练的成本极低!
常规的 AI 产品基础技术架构事实上只有两条:API、API+知识图谱。
之前多数人认为预训练+微调是错误的技术选择,其核心是高昂的成本。
现在基于 DeepSeek 的微调貌似成本也不高,这会导致新的技术路径产生,而 API、API+知识图谱、基于微调的 AI 产品三者之间差异是什么,到底如何选择,很多人是模糊的。
二、可以兴奋但别焦虑
老板们逐渐相信 AI 会重塑所有,于是他们会想用 AI 的方式将公司产品重塑一次。
这会引发第一轮的焦虑,因为没有可以抄的对象,多数人是不知道怎么做的!所以多公司现在是既迷茫又兴奋:
兴奋的点在于,行业洗牌的机会来了,抓住了就是下一个头部;
迷茫的点在于,那是真的不知道该怎么做;
首先是 AI 对于自己的产品意义是什么,比如是产品用上 AI 的能力,还是用 AI 能力去重塑产品,不清楚;
其次是 AI 能力的边界在哪里,比如数据对于大模型幻觉的意义是什么,是否要投入大量资源去整理数据,不敢赌;
然后是具体的技术路径是什么,比如是 API 还是微调,不明白;
其实这里有个判断依据:在 DeepSeek 出现前,GPT 的表现已经足够优秀,如果你们公司在之前没出太多创新,今年也很难马上做出什么。
这里的原因是 AI 产品的非对称性。
三、非对称性
无论是 GPT 还是 DeepSeek,他们都太强大了,基于他们做出来的 AI 产品容易让我们产生一个幻觉:我们公司的 AI 太强大了!
醒醒吧,这是幻觉!AI 很容易产出一个 demo,但很难得到一个应用!
大白话是:业务判断 AI 产品能不能用的标志是能不能完全接管业务,如果不能就是玩具!
对于 AI 应用,你可以用一周时间完成一个 demo;但半年后,实现的产品效果依旧不能超越这个 demo!
这里非对称性也就出来了,花费 10%的资源可以得到一个 70 分的 demo;想要将 70 分推到 90 分,可能你需要 1000%的资源!
入门简单,精通难!大模型是很容易造成老板/产品/技术错误判断的存在,如果轻易承诺,肯定会坑了自己。
所以,想要 AI 在应用上表现出现,必须要有耐性!
四、耐心很重要
做 AI 项目,耐心是很很重要的,简单来说:你认为 Prompt 提示词困难吗?
Prompt 不是有手就行嘛,谁会中文还不会写点提示词,但 Prompt 其实很难:
首先,写出稳定输出的 Prompt 很难;
其次,在不同场景中 Prompt 要稳定输出更难;
最后,要与优质数据配合并且要稳定输出的 Prompt 很难;
这对我们的启示是什么呢?这对我们的要求是有耐心、有定力,不要因为今天产品表现得好而过分开心,也不要因为明天产品表现的弱智而过分焦虑。
保持平常心,去面对,去调整,因为提示词调优只是 AI 产品过程中最简单的部分,寻找正确的路径,试验正确的路径,才是其中的难点...
对于一般公司,AI 项目的成败取决于技术团队工程能力的强弱,以及对相关领域的认知!
所以好的程序员跨界去深入学习某行业知识,再转做产品经理会变得十分吃香。
其次,在基座模型能力上来后,大家都是在 70 分水准的基线上竞争,如何通过自身的优势快速达到 90 分会成为占领高地的关键。
不急不躁
有了以上认知后,我们会达成一个共识:我们离成熟的 AI 应用诞生还有一段时间(1-2 年),而就算已经有爆款产品出现,也不要慌张,产品层面的进步是最容易赶上的。他不会比 DeepSeek 比肩 GPT 更难!
所以,我们最应该想清楚两个问题:
目标是什么;
目标对 AI 能力的要求是什么;
如果 GPT 的能力值是 100 分(大学生水平),也许你的产品其实只需要 70 分(初中生水平)就够了呢?
在目标清晰后,就应该坚定的执行在这个窗口期(1-2 年)将配套设施打磨好,而不是急于推出产品去吸引注意力。
在这个基础上,我们再来探讨如何做技术选型。
技术选型
出于敏感性考虑,这块我会去除大量细节,请各位海涵
基础技术选型
最基础的技术选择无非三块,提示词、RAG 和微调,其优劣如表格所述:
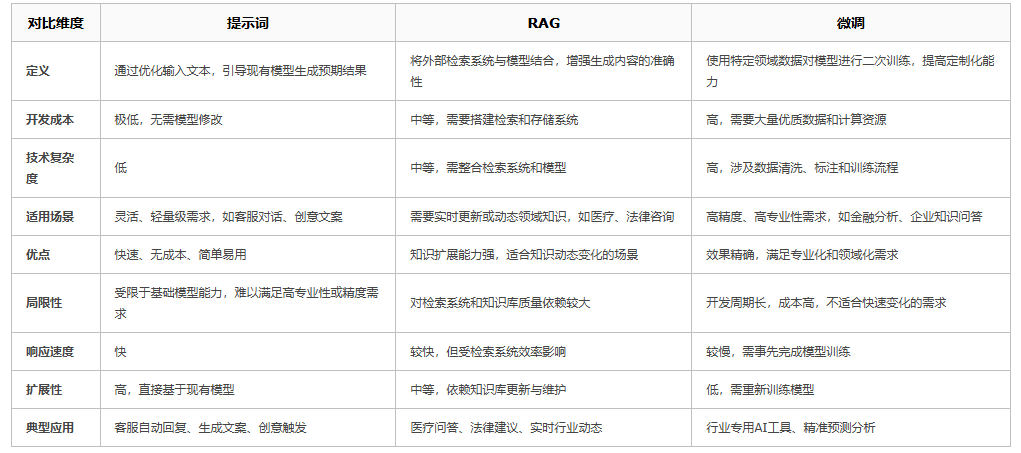
产品实现路径
PS,这里涉及敏感信息,我做简要说明即可
其实,基础技术选型问题不值一提,他们既可以混用又可以不停转换,我们实际做开发过程中大概率三条路径都会用,所以这里的重点不是基础技术的选择而是产品实现路径的思考。
这里的核心为:模型只是一个 API 调用工具,工程实现是核心。
实际实现时候需要考虑几个点:
单纯基于大模型当前 AI 产品能达到的极限是什么,问题是什么;
基于 AI 产品的行业 KnowHow 是什么;
要打破 AI 产品的极限,需要的优质数据(数据+工程规则)是什么;
如何用工程的能力组织这套 AI 架构,实现数据、工程自迭代,最终形成飞轮系统;
具体来说:大模型的工作模式是输入输出:输入 -> Prompt -> 输出。
所有的工程能力全部会体现在这个 Prompt,所谓 Prompt 就是我们对规则理解的文字化。
比如要做的是 AI 律师,这里的 Prompt 就是某著名律师这 10 多年的经验。
这个经验是理解用户问什么,然后给予他正确的法律反馈,如何给予用户正确的反馈,这就是该合伙人需要给技术工程的优质数据,也就是 AI 律师需要的输入输出规则。
而这里的“优质数据又是如何形成的呢?”答案是基于 10 几年律师问答的总结整理,他需要深刻理解关于输入输出五个部分:
大量输入(输入材料的相关性);
输入正确(输入材料的正确性)
输入可理解(输入材料的多样性,泛化相关思考)
输出假设和及时反馈(强化学习的关键)
检索强化(如果有知识图谱,可能会用到的)
但大模型是一个新生事物,他所需要的优质数据/规则数据在以往时代大概率没有系统性的、完整性的存在。
因此,很多 AI 产品的推出都会有一个优质数据准备的阶段,在这个时间窗口下,对所有人都是一个机会,所以各位老板真的不用急。
只要将“优质数据”(数据+规则)是什么搞清楚,产品的实现路径自然而然就出来了。
而后的问题就是工程侧如何将这一切循环优化起来,形成一套飞轮系统,一旦飞轮系统形成,跟其他公司的差距就拉开了。
飞轮系统
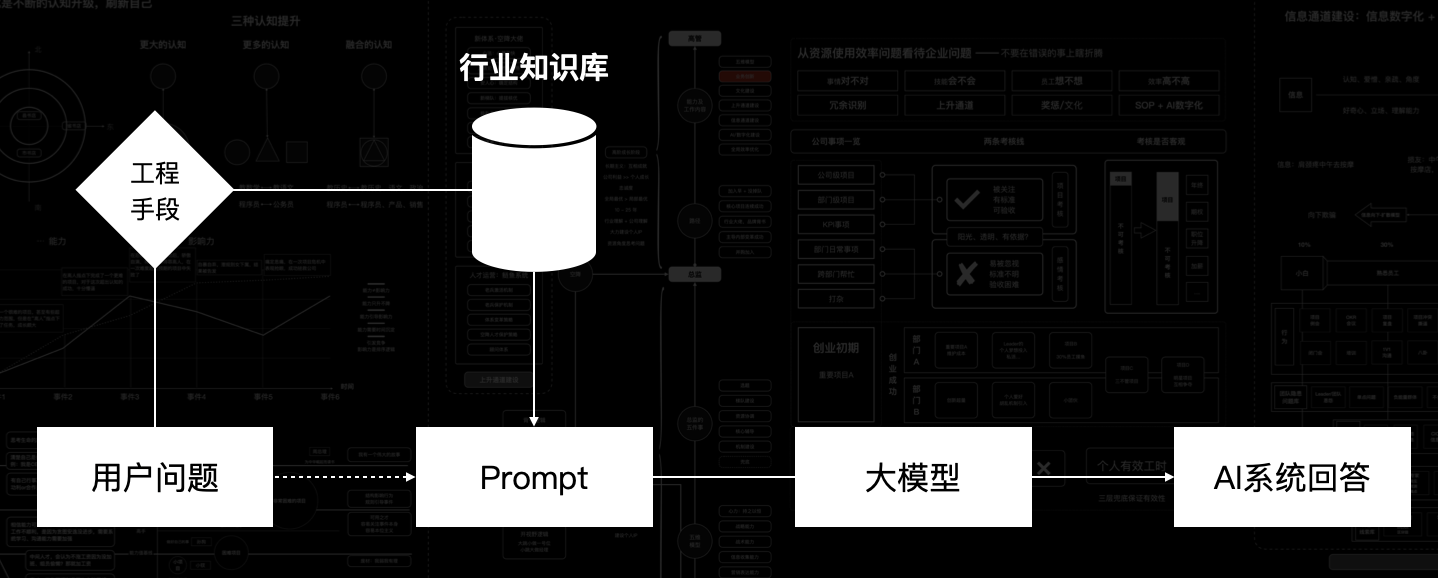
就个人认知,想要延伸基座模型的能力只有两个做法:
第一是构建一套自己的行业知识库(知识图谱)。每次输入前将相关信息带上,如图所示:
第二是基于“行业知识库”形成多套微调数据,去训练模型。每次输入输出会变成这样:
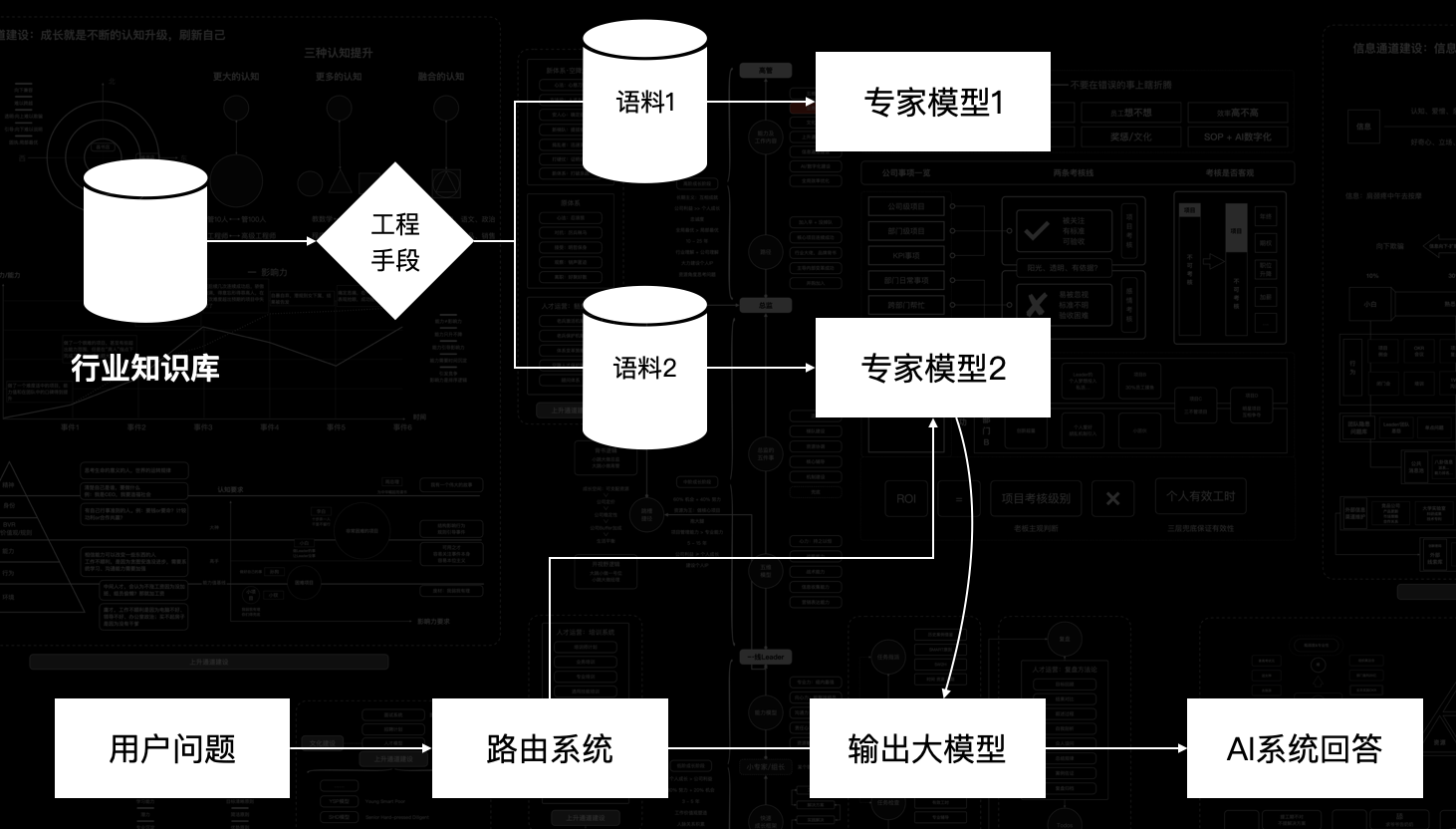
第一套架构复杂起来会形成一个庞大的知识图谱、第二套其实就是 MoE 架构的雏形。
两套系统看似不同,其核心其实类似,都包括两点:
路由规则的优化;
专家模型如何优化;
所以在基础架构搭建完成后,真正困难的是工程控制:如何用海量优质增量数据去优化模型本身,这就是所谓飞轮系统。
其实这里的核心是:优质数据哪里来?,他包括:
初期数据哪里来?
中期哪里来?
后期哪里来?
初中期的数据与规则
首先,第一批少量优质数据的整理多半需要跨领域融合,比如律师+技术。
只不过,如果以律师+程序员的方式要产出数据成本是很高的,因为好的律师会很高傲;他很难配合程序员的工作,而程序员要达到律师行业的 KnowHow 是需要大量的时间的。
所以,程序员或者产品必须主动上前,软磨硬泡把核心规则与样例数据搞到手,而后必须有其他手段去处理这种矛盾,这里的核心有二:
程序员群体必须有基本 KnowHow;
对行业专家(律师、医生)的使用方式要变;
KnowHow 在这个合作模式喜爱要分为三个部分:
第一是知道怎么做——程序员必须会;
第二是知道找谁做——遇到规则问题程序员需求助领域专家;
第三是知道好不好,这里的核心是评价——让领域专家对应用打分;
经过一轮磨合,这对于程序员是比较轻松的,最终形成的合作模式是:AI 产出数据,行业专家评价效果,根据效果优化数据,最终形成数据集+规则。
数据反馈回路
AI 应用的优化依赖于数据反馈回路,即通过建立一个自我增强的飞轮系统,实现持续的自我优化。
以 DeepSeek R1 为例,初期通过少量专家标注数据启动,但关键在于后续的数据再生和强化学习。
机器通过自我探索和反复调整,逐步减少偏差,提升准确性,形成一个有效的反馈回路。
这种方式与传统监督学习不同,后者依赖人工标注数据的直接关系,而强化学习通过自主学习和数据再生,不断调整策略。
成功的飞轮系统不仅依赖专家数据,还需大量高质量数据的自动生成和修正。
技术与行业专家的合作,是推动飞轮系统有效运转的关键。然而,数据偏差和结果偏离可能是挑战,需要依赖飞轮系统的自我校正来精准化数据和反馈。
AI 应用的飞轮系统需要耐心,因为优化过程是渐进的。关键在于建立持续的反馈机制和自我修正能力,推动数据的有效利用,进而提升系统的长期表现。
结语
今天,我们对如何开展 AI 项目的思路有做了一些简单探讨。
从明确目标出发,选择适合的技术路径,到构建 AI 产品的飞轮系统,每个环节都需要不停试错。
AI 的应用和技术实现往往伴随挑战,尤其是在数据准备和工程实现方面。
构建飞轮系统、优化数据反馈回路,以及与行业专家的深度合作,这些都不是短期内能够轻松解决的问题。
虽然初期可能会面临一定的技术复杂性和高昂的成本,但这些投入和耐心,最终将为企业带来可持续的竞争优势。
文章中提到的技术选型和路径选择,可能给一些读者带来些许迷惑。
我们在此强调,AI 项目并不是一蹴而就的,选择合适的技术和实现路径,取决于具体的业务需求和行业特点。
对于没有经验的企业来说,首先要清晰定义目标,再根据目标选择合适的技术,而不是一味追求“最先进”的解决方案。对技术路径的选择应当具备灵活性,随着项目进展及时调整。
总之,AI 技术的应用和开发不仅需要深厚的技术储备,更需要扎实的行业知识和耐心。企业应理性看待 AI 应用,避免过度焦虑,逐步推动项目实施,才能确保在未来的竞争中占据有利位置。
文章转载自:叶小钗

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论