
PHP7 内核实现原理 - 数组的实现
PHP 的数组是基于 HashTable 实现的,并且在其上增加了顺序访问的特性。这里分 PHP 5 和 PHP 7 两个版本看数组的演进。
PHP 5.6.31 源码:https://github.com/php/php-src/blob/php-5.6.31/Zend/zend_hash.h#L67
PHP 7.2.1 源码: https://github.com/php/php-src/blob/php-7.2.1/Zend/zend_types.h#L234
PHP 数组特点
PHP 中的数组有两个最突出的特点,也即 PHP 数组满足两个语义:
PHP 数组是一个字典,支持 key value 访问,key 支持整型或字符串。
PHP 数组是有序的,即遍历数组时会按照添加顺序遍历,不像传统意义上的字典是无序的。
传统 HashTable
一个传统的 HashTable 大致结构如下:
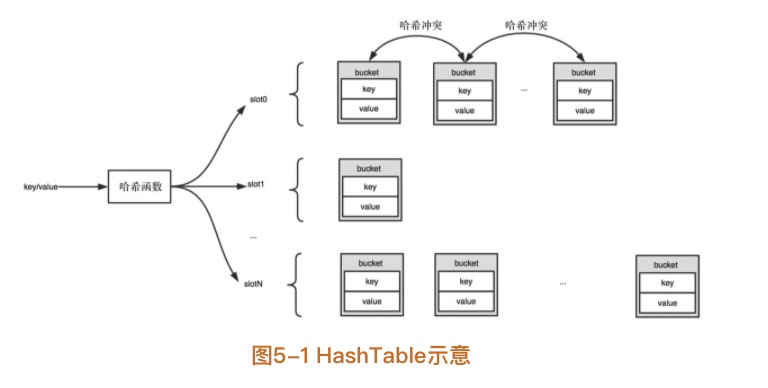
首先一个 key 经过哈希函数计算,得出属于哪个 slot。key 值和 value 值使用 bucket 结构体保存,放在对应的 slot 下。如果不同 key 经过哈希计算后得到相同 slot 值,即发生哈希冲突时,使用链表法接在 slot 的 bucket 链后面。这里提一句有的语言解决哈希冲突会使用红黑树。
PHP 中的 HashTable
PHP 中的 HashTable 在此基础上做了一些调整,增加了一个哈希函数,以及这个新增哈希函数对应的哈希值 h :
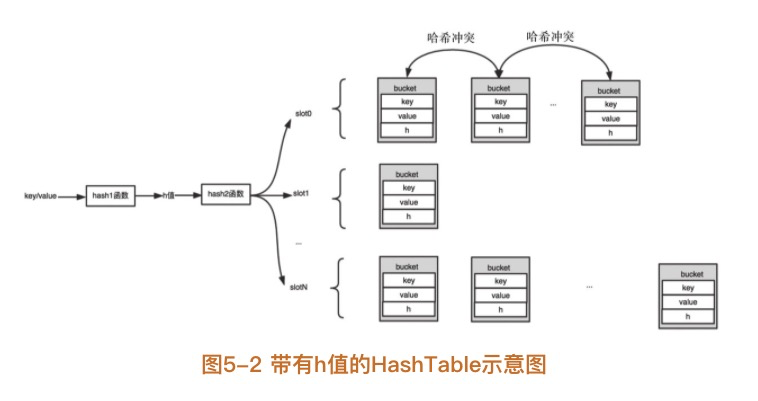
其中 key 经过 hash1 函数得到 h 值,h 值是一个无符号整型(ulong),之后 h 值再通过 hash2 函数计算得到 slot,分配时与之前一样。另外 bucket 中也增加了对 h 值的保存。
为什么的要增加这个 h 值,作用是什么?
PHP 要支持数字和字符串两种 key,当使用字符串 key 时,h 值就是其对应的数字值。而使用数字 key 时,h 直接就等于这个 key 值。相当于将数字和字符串两种 key 归一为数字类型,统一放到 h 字段中。
在比较两个字符串 key 的 value 是否相等时,可以先通过判断对应的 h 值是否相等,且绝大部分情况下,字符串哈希冲突的概率也比较小,所以如果不相等直接返回,加快判断的速度。
PHP 5 的数组实现
先看源码:
https://github.com/php/php-src/blob/php-5.6.31/Zend/zend_hash.h#L67
PHP 5 的 bucket:
bucket 代码:
bucket 图示:
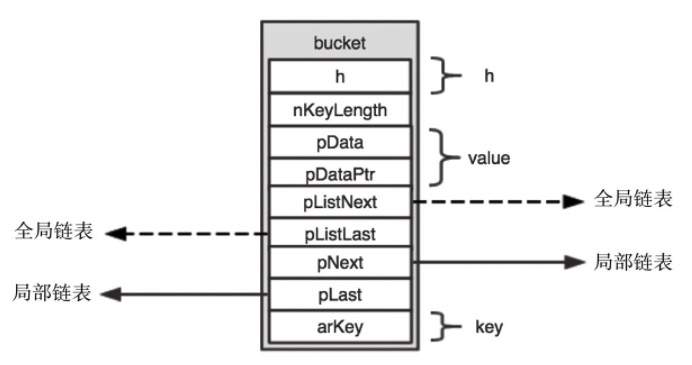
各字段含义:
h:就是前面提到的 h 值
arKey:是当前 bucket 的 key 值
pListLast、pListNext、pLast、pNext:四个指针
nKeyLength:是 arKey 的长度,当这个值为 0 时,表示当前 key 是数字类型。
pDataPtr 和 pData:指向具体的 value。这里有个优化,如果 value 的大小等于一个指针,则将 value 直接存储在 pDataPtr 上,减少内存占用
bucket 中为什么有 4 个指针?
因为要满足数组有序的语义,PHP 5 使用 pListNext 和 pListLast 分别表示全局链表上的下一个节点和上一个节点。在后面 HashTable 的实现中分别也有两个指针,指向全局链表的头部和尾部,实现正序和倒序访问。
而 pNext 和 pLast 分别表示发生哈希冲突时的局部链表。
PHP 5 的 HashTable 的结构:
HashTable 源码:
arBuckets:是一个指针,指向一段连续的数组内存,数组中每个元素指向一个 slot 。通过这个指针就可以找到所有 slot 及 slot 下的 bucket。即 slot 的数组。
nTableSize:是 arBuckets 所指向的数组的大小,即 slot 的数量。取值始终是 2 的 n 次方。最小值 8,最大 2 的 31 次方。这个值的意义在于,当 bucket 的数量大于这个值时,表示已经出现了哈希冲突,当冲突严重时 PHP 会发起 rehash ,重新均衡 slot 的分布。
nTableMask:掩码。始终等于 nTableSize - 1,所以他的每一位都是 1。HashTable 要经过两层 hash 函数, 第二个 hash 函数就是 slot = h & nTableMask 以此来计算出 slot 。相当于取余操作。这里在 PHP 7 中会发生变化。
nNumOfElements:bucket 元素的个数。
pListHead 和 pListTail:为实现 HashTable 有序而维护的双向链表。这两个指针分别指向第一个 bucket 和最后一个 bucket 。
pInternalPointer:指向当前元素的指针,foreach 遍历时就是使用这个指针遍历的,这也是为什么 PHP 5 中 foreach 遍历数组比用索引遍历快的原因。
bucket 和 HashTable 联动图示:
按顺序插入四个 key a、b、c、d,假设 a 被映射到了 slot1,而 b、c、d 被映射到了 slot0 中:
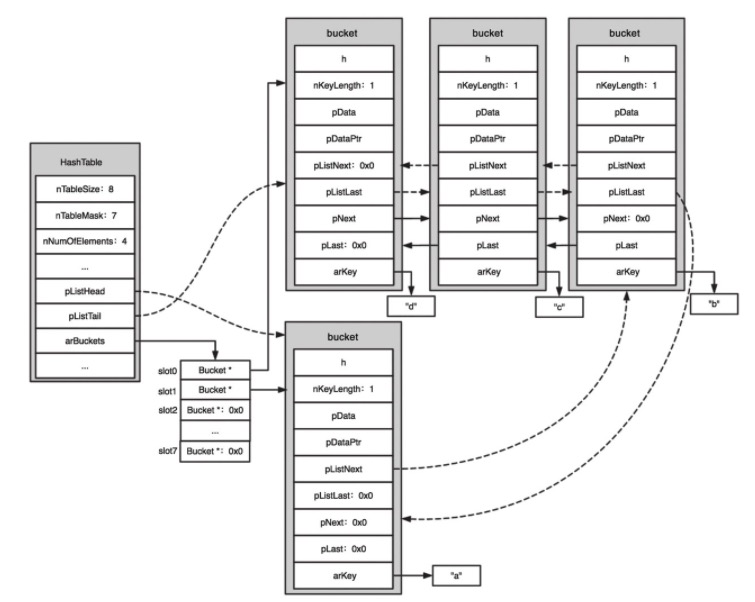
其中 HashTable 上的 pListHead 作为全局链表头指向了第一个 bucket a,pListTail 作为全局链表尾指向最后一个 bucket d。通过 pListHead 和 pListTail 就可实现数组的正序和倒序遍历。
可见 PHP 的数组有序指的是插入的顺序,例如鸟哥的博客也讲到这一点,提了一个问题:
https://www.laruence.com/2009/08/23/1065.html
答案是一样的,即插入的顺序。
PHP 5 数组的不足
整体来说,有两处可以优化:
使用的字段是比较多的,而且每个 bucket 都要有四个指针,占用空间大。
其次 bucket 的分配位置是随机的,不连续的,导致无法利用到 CPU 的局部性原理,无法利用 cache。
PHP 7 的数组实现
PHP 7 主要针对上面提到的两个不足之处做了改进。首先精简了字段,且不再使用指针维护节点间的顺序,改为了连续内存。这样既减少了空间占用,又使用顺序读写利用了 CPU 的局部性原理,提高了数据读取速度。
PHP 7 数组的源码:https://github.com/php/php-src/blob/php-7.2.1/Zend/zend_types.h#L234
bucket 结构:
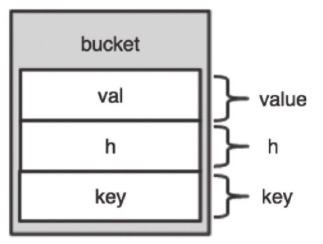
首先因为不再使用指针维护顺序,bucket 的结构精简了很多。
val:指向具体的变量,zval 结构体
h:跟以前一样的 h 值,无符号数字类型
key:字符串 key,不再使用 char *,而是直接用了 zend_string 结构体
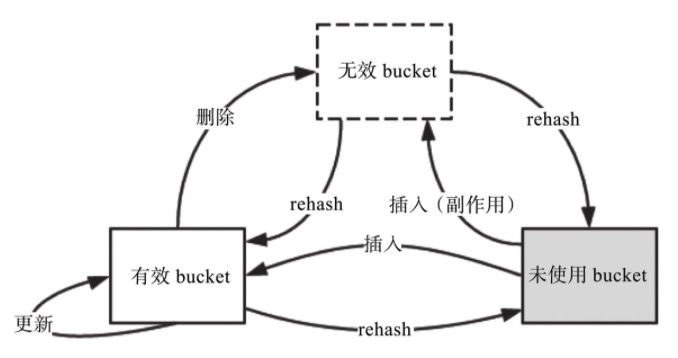
之后 bucket 引入了状态的概念,分为:未使用、有效、无效。有效和无效 bucket 始终排列在未使用 bucket 前面:

状态机:
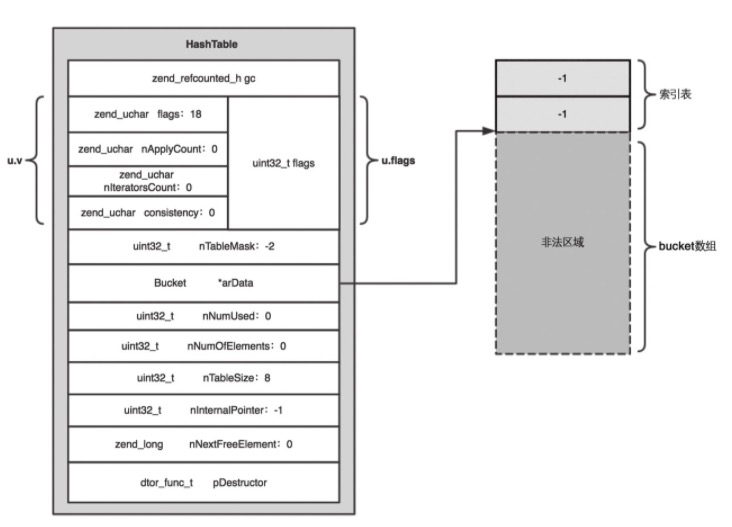
HashTable 结构:
图示:
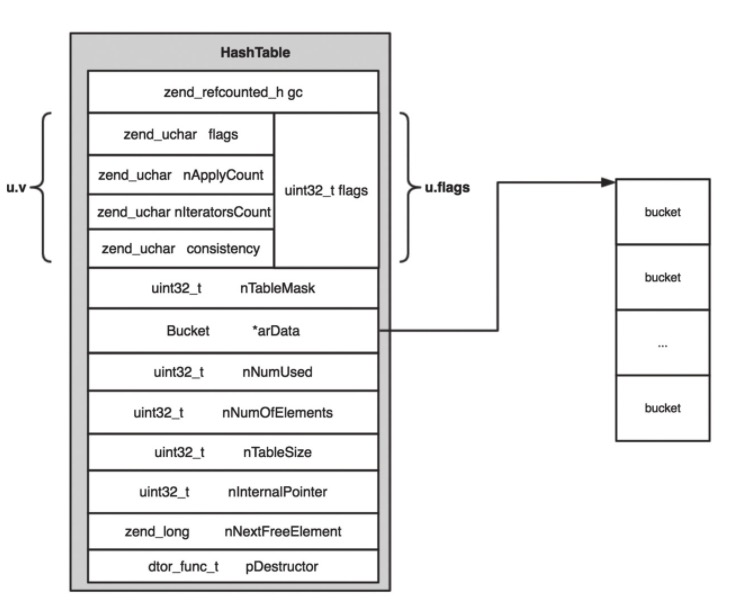
各字段含义:
gc:引用计数
arData:一块连续的内存空间,存放 bucket 数组。
nTableSize:arData 指向的 bucket 数组的大小,即所有 bucket 的数量。该字段取值始终是 2 的 n 次方,最小值是 8
nNumUsed:指所有已使用 bucket 的数量,包括有效 bucket 和无效 bucket 。
nNumOfElements:有效 bucket 的数量。该值总是小于或等于 nNumUsed。
nTableSize、nNumUsed、nNumOfElements 三者的关系:

nTableMask:掩码。一般为 -nTableSize。
nInternalPointer:游标指针,由于现在 bucket 都是连续存储的,所以不再使用指针而改用无符号整数存储索引值即可。
nNextFreeElement:下一个自然索引值,默认是 0。即如果使用 $arr[] = 1 的方式插入元素,相当于插入到索引 0 的位置。
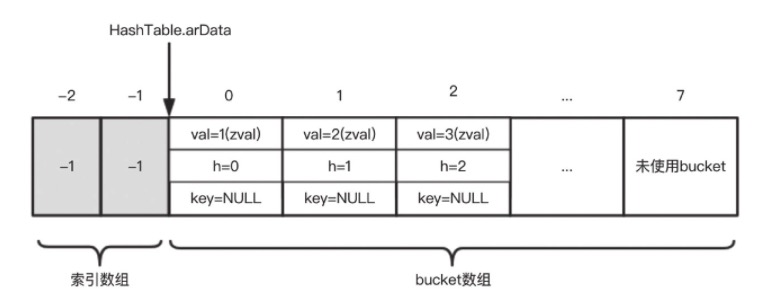
基于以上前提,如何实现 key 对应到 slot 再到 bucket 链表呢?
这里就谈到为什么 nTableMask 是负值的原因了。实际上在分配 bucket 数组内存的时候,即 arData,在这个数组最前面额外多申请了一些内存,这段内存的作用是充当索引,也叫索引表或 arHash。索引表里面的每个元素代表一个 slot,其值为其下第一个 bucket 在 arData 中的下标。如果当前 slot 没有任何 bucket 元素,那么其值为 -1。到此就实现了 key 到 slot 再到 bucket 的映射。
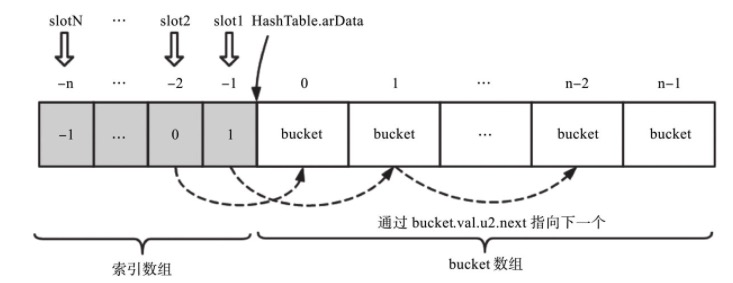
从而 PHP 7 中的第二个哈希函数,即使用 h 值取得 slot 值,变成了:slot = h | nTableMask 。
如,当 nTableSize=8,则 nTableMask=-8 ,二进制即:11111111111111111111111111111000。那么任何数与之做或运算,只能是 000 - 111 这 8 种值,即 -1 到 -8,这 8 个 slot 在分别存一个具体的 bucket 索引值。就完成了 key → h → slot → bucket 的查找了。
关于 -8 的二进制表示,需要回顾下计算机组成原理二进制表示:
负数 = 其正值的补码 -8 正值就是 8
8 的原码表示为 00001000
8 的反码表示为 11110111 ,即按位取反
8 的补码表示为 11111000 ,即反码 + 1
这样一来扩展到 32 位时就可知 -8 的二进制为 11111111111111111111111111111000
参考:https://www.cnblogs.com/zhangziqiu/archive/2011/03/30/computercode.html
PHP 7 数组几种初始化过程:
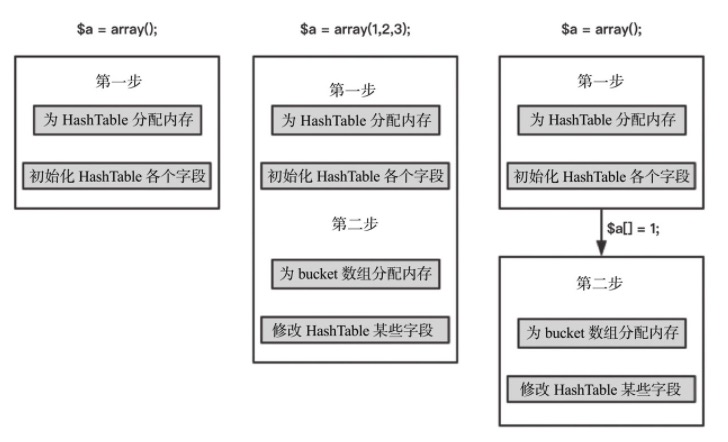
packed array 和 hash array
注意前面提到 nTableMask = - nTableSize ,但这个不绝对,当数组是 packed array 类型时其实是用不到索引表的,所以一般初始化数组时,在未确定数组类型时,nTableSize 一般只分配 2 个。
初始化数组时,数组的内存分配状态:
什么是 packed array 和 hash array
当 HashTable 的 u.v.flags 的 HASH_FLAG_PACKED 位 > 0 时表示 packed array ,否则是 hash array。
packed array 具有以下约束和特性。
key 全是数字类型的。
key 按插入顺序排列,仍然是递增的。
每一个 key-value 对的存储位置都是确定的,都存储在 bucket 数组的第 key 个元素上。
packed array 不需要索引数组。
packed array 不需要索引表,直接用 key 作为 arData 的索引,节省了前面一段索引表的空间。
packed array 示意图:
hash array 示意图:

如:

其中最后一个特殊,也是数字 key,也是递增,为什么不是 packed array?因为用 1 和 8 做索引,数组太过于稀疏,利用率不高,在时间效率和空间效率的平衡下,使用了 hash array 。
来自鸟哥博客的一段代码,这段代码展示了从 packed array 切换到 hash array 的内存占用情况:
打印结果:
鸟哥代码地址:https://www.laruence.com/2020/02/25/3182.html
packed array 转换成 hash array
从 packed array 到 hash array 转换需要调用 zend_hash_packed_to_hash 函数。首先将 u.flags 中设置标志位 HASH_FLAG_PACKED ,之后新生成一个 arData,再调用 memcpy 拷贝过去,最后释放掉老的 arData 。
PHP 7 数组的 CRUD
基本步骤:
先查找 key 存不存在
插入时分为字符串 key 插入,数字 key 插入,nextIndex 插入
如何解决哈希冲突
发生冲突时,把新的元素放在 nextFreeIndex 处,然后新 zval 的 next 指针指向老元素在 arData 中的索引,之后在 arHash 索引表中,指向新元素的位置。即索引表永远指向新元素,新元素的 next 再指向老元素,串起来。
扩容 resize 和重建索引 rehash
扩容 resize 看书:zend_hash_do_resize
重建索引 rehash 函数:zend_hash_rehash,因为扩容导致数组容量变化,需要重新分配索引
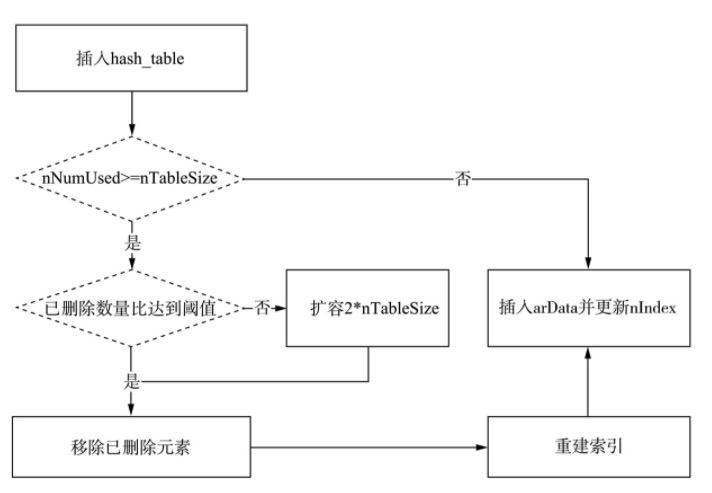
在插入元素时判断是否要 resize 和 rehash,基本步骤是:
判断数组空间是否够用
不够用时,看是不是无效 bucket 太多太多就真删除一波,之后 rehash 不是很多,说明真的没地方了,那就先扩容 resize,再真删除,再 rehash
比较 PHP 5 和 PHP 7 的数组实现:
精简了 bucket 的字段
使用 bucket.zval.u2.next 取代旧的局部冲突链表
将 bucket 存储在连续的 arData 数组中,取消了全局链表。并且由于内存连续,利用局部性原理,提高读取性能。
packed array 节省了索引表 arHash 的空间。

全干程序员 2018-08-08 加入
还未添加个人简介









评论