
基于昇腾 MindSpeed RL 复现 R1-Zero 优秀实践
DeepSeek 开启全新的后训练范式,带来 AI 模型技术平权时代,行业纷纷构建自己的高质量高性能的行业 RL 模型。然而,训练高性能的大尺寸模型通常需要庞大的计算资源和海量数据,这对研究社区的可复现性和进一步探索提出了挑战。为了降低研究门槛并促进开源生态的发展,昇腾 MindSpeed RL 强化学习开源套件支持大尺寸模型的强化学习高效训练,提供用户方便易用的复现指导,目前已完成在 Qwen25-7B/32B 基座模型为例复现 R1-Zero 的实践,模型数学能力大大提升。

R1-Zero 复现面临的挑战
目前,针对大规模集群强化学习 RL 复现 R1-Zero,在效率、易用性和训练效果上存在诸多挑战。业界开源 RL 框架在大尺寸模型 RL 训练中有权重更新时延高、硬件利用率低、并行策略转换 OOM 等问题,业界开源 RL 仓的 readme 太简单无法支撑用户快速上手,同时,RL 训练过程依赖人工经验,较好的规则奖励定义、训练超参调整尤为重要。
基于 MindSpeed RL 套件
复现 R1-Zero
数学能力大幅提升
MindSpeed RL 提供了从环境安装、程序运行、训练效果的详细指导,并提供典型配置文件和脚本供用户一键启动,同时采用训推共卡、异步流水、分布式打分器等核心技术进行训练加速。
基于以上能力,分别使用 Qwen25-7B 和 Qwen25-32B 作为 base 模型为例,使用昇腾 MindSpeed RL 套件复现 DeepSeek-R1-Zero 范式在 Math 领域的工作效果,在数学等逻辑推理评测集上,MATH500 的分数提升幅度 15 分左右,达到 70.6 和 83.2,32B 模型下的 AIME24 的提升幅度高达 26 分。
01 MindSpeed RL 以 Qwen2.5-7B 为基座模型为例复现 R1-Zero 的效果
训练输入:使用 Qwen2.5-7B base 模型在 orz 数据集上训练,使用标准的格式奖励和准确性奖励,训练超参如下

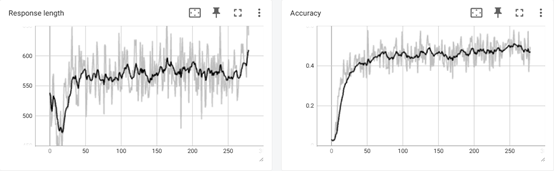
训练过程监控:训练过程用 Tensorboard 可视化工具监控,可以看到模型的回复长度 Response length 呈现典型的先下降后上升趋势,准确性奖励 Accuracy 持续上升并逐渐稳定在 0.4~0.5 之间。
模型效果评估:使用开源榜单评测系统 OpenCompass 进行模型评估,分数如下:
对于 MATH500,Qwen-2.5-7B 原模型的得分是 54.4,开源社区 Open-R1 获得 69 分,而 Qwen-2.5-7B+MindSpeed RL 得分高达 70.6,超越了开源社区;对于 AIME24 和 GPQA,Qwen-2.5-7B+MindSpeed RL 的效果也提升了近 10 分,分别达到 16.2 和 37.3 分。

MindSpeed RL 以 Qwen25-7B 为例
复现 R1-Zero 的模型在数学能力效果超越开源社区
02 MindSpeed RL 以 Qwen2.5-32B 为基座模型为例复现 R1-Zero 的效果
训练输入:使用 Qwen2.5-32B 模型在 deepscaler 数据集上使用标准的格式奖励和准确性奖励训练,训练超参如下:

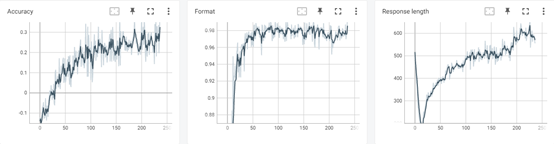
训练过程监控:训练过程用 Tensorboard 可视化工具监控,可以看到模型的回复长度 Response length 呈现典型的先下降后上升的趋势,准确性奖励 Accuracy 保持持续上升;格式奖励 Format 很快上升到较高的水平。
模型效果评估:使用开源榜单评测系统 OpenCompass 进行模型评估,分数如下:
对于 MATH500,Qwen-2.5-7B 原模型的得分是 68.6,开源社区 SimpleRL-Zoo 复现 R1-Zero 效果获得 82.4 分,而 MindSpeed RL 复现 R1-Zero 得分 83.2,超越开源社区;对于 AIME24,开源社区 SimpleRL-Zoo 复现 R1-Zero 效果获得 27.2 分,MindSpeed RL 复现 R1 得分 30.4,超越开源社区;而对于 GPQA,MindSpeed RL 复现 R1 得分 41.1,相比基座模型也有 9 分提升。

MindSpeed RL 以 Qwen25-32B 为例
复现 R1-Zero 的模型在数学能力效果超越开源社区
03 训练后模型出现 Aha-moment 的自我反思现象
训练前,通过 prompt 可以引导模型部分遵从的格式,但回答的思考过程较短没有自我反思,样例如下:

训练后,我们观察到经过几十个 iterations 后模型就有一定概率出现 Aha-Moment,从“But wait”上看模型在进行自我反思,出现了 R1 范式中的模型产生 CoT 思维链现象,样例如下:

R1-Zero
(以 Qwen2.5-32B 为例)
复现指南
环境配置
配置 MindSpeed RL 基础环境以及准备代码,参考安装指南
https://gitee.com/ascend/MindSpeed-RL/blob/master/docs/install_guide.md
模型选择
Qwen2.5-32B 下载:
https://gitee.com/link?target=https%3A%2F%2Fhuggingface.co%2FQwen%2FQwen2.5-32B%2Ftree%2Fmain
权重转换
在进行 RL 训练之前,模型需要从 HuggingFace 权重转换为 megatron 权重,可参考权重转换部分:https://gitee.com/ascend/MindSpeed-RL/blob/master/docs/algorithms/grpo.md
source /usr/local/Ascend/ascend-toolkit/set_env.sh
# 设置需要的权重转换参数
# actor 使用 TP8PP2,将脚本里改成 TP8PP2 配置
# reference 使用 TP8PP1,将脚本里改成 TP8PP2 配置
bash examples/ckpt/ckpt_convert_qwen25_hf2mcore.sh
# 训练完后如需要转回 HF 格式
bash examples/ckpt/ckpt_convert_qwen25_mcore2hf.sh
模板构造
R1-Zero 复现需要在数据处理时加上 prompt 模板激发......$\boxed{}
<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n<|im_start|>user\nA conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed withinandtags, respectively, i.e.,reasoning process hereanswer herePut your final answer within \\boxed{}.\n{你真正的问题}<|im_end|>\n<|im_start|>assistant\n{模型真正的回答}
数据集
对于 32B 模型应使用更高难度的数据集,所以我们使用 DeepScale 40K 来训练。
数据预处理
需要先配置数据处理的 yaml 文件(examples\datasets\r1_zero_qwen25_32b.yaml) 自定义数据集需要设置--map-keys 映射,或重写自定义 handler;具体参考数据集处理部分
Qwen2.5-32B
处理的时候默认使用 qwen_r1 的模板
# 启动转换
bash examples/data/preprocess_data.sh r1_zero_qwen25_32b
训练配置准备
模型结构的配置文件位于 configs/model 下,训练配置文件位于 configs/目录下,我们以 qwen2.5-32b 为例[r1_zero_qwen25_32b.yaml],该配置用到了 32 卡,为了进一步加速可以不断增加推理 DP 的数量。以下为参数配置:
defaults:
- model:
- qwen25-32b <-- 网络结构需要定义在 model 目录的 yaml 文件下
megatron_training:
global_batch_size: 128 <-- 每个迭代的总样本数
...
dataset_additional_keys: ['labels',] <-- 使用打分器时需要的额外字段
actor_config:
model: qwen25-32b
micro_batch_size: 1 <-- 训练的 mbs
...
lr: 1e-6
lr_decay_style: constant <-- 学习率衰减方式
weight_decay: 0.0 <-- 正则化强度系数
lr_warmup_fraction: 0.0 <-- 控制学习率预热
...
no_load_optim: false <-- 续训加载优化器状态
no_load_rng: false <-- 续训加载数据随机数生成器
no_save_optim: false <-- 保存权重时同时保存优化器状态
no_save_rng: false <-- 保存权重时同时保存数据随机数生成器
ref_config:
model: qwen25-32b
...
rl_config:
blocking: false <-- 开启异步流水
...
adv_estimator: group_norm <-- 优势计算方法
mini_batch_size: 2048 <-- 训练更新梯度的 bs, 一般为 gbs*n_samples_per_prompt
...
max_prompt_length: 1024 <-- 最大的 prompt 长度
clip_ratio: 0.2 <-- 策略裁剪比例
shuffle_minibatch: false <-- minibatch 里的数据是否打乱
n_samples_per_prompt: 16 <-- GRPO 中一个 group 内生成的 response 条数
colocate_actor_ref: false
colocate_all_models: false
rule_reward: true <-- 开启规则奖励
verifier_function: ["acc", "strict_format"] <-- 规则奖励模型方法
verifier_weight: [1.0, 1.0] <-- 规则奖励模型权重
use_tensorboard: true <-- 开启 tensorboard 日志功能
actor_resource: <-- actor worker 资源分配
num_npus: 16
reference_resource: <-- ref worker 资源分配
num_npus: 16
generate_config:
trust_remote_code: true <-- tokenizer 相关配置
infer_tensor_parallel_size: 4 <-- 推理时的并行配置
infer_pipeline_parallel_size: 1
infer_expert_parallel_size: 1
max_num_seqs: 128 <-- vllm 推理并发最大样本限制
max_num_batched_tokens: 128000 <-- vllm 推理并发最大 token 限制
max_model_len: 4096
dtype: "bfloat16"
gpu_memory_utilization: 0.9
offload_train_optimizer: true <-- 卸载训练节点优化器
offload_train_grad: true <-- 卸载训练节点梯度
offload_train_param: true <-- 卸载模型权重
sampling_config: <-- vllm 采样配置
max_tokens: 3072 <-- 单条 response 最大生成 token 数量
logprobs: 1 <-- 是否生成 logprobs
max_tokens: 3072
top_p: 0.9
top_k: 50
min_p: 0.01
temperature: 0.9
detokenize: false
...
手动启动训练
与基于 ray 的其他强化训练一样,我们多机需要先在主节点初始化 ray:
# 创建一个集群,端口 6344,dashboard 端口 8260
ray start --head --port 6344 --dashboard-host=0.0.0.0 --dashboard-port=8260
随后,在其他节点加入主节点的集群:
# IP_ADDRESS 处填写主节点 IP 地址
ray start --address="IP_ADDRESS:6344"
最后,在主节点上启动训练:
export HCCL_CONNECT_TIMEOUT=1800
export CUDA_DEVICE_MAX_CONNECTIONS=1
python cli/train_grpo.py --config-name r1_zero_qwen25_32b | tee logs/r1_zero_qwen25_32b_full.log
脚本启动训练
注意:所有节点的代码、权重、数据等路径的层级要保持一致,且启动 ray 的时候都位于 MindSpeed RL 目录下
更多详细复现指导见 MindSpeed RL 开源 readme 文件
Qwen25-7B R1-Zero 复现
https://gitee.com/ascend/MindSpeed-RL/blob/master/docs/solutions/r1_zero_qwen25_7b.md
Qwen25-32B R1-Zero 复现
https://gitee.com/ascend/MindSpeed-RL/blob/master/docs/solutions/r1_zero_qwen25_32b.md

还未添加个人签名 2021-05-31 加入
还未添加个人简介












评论