
SQL 优化——深分页 & 排序
问题背景
在开发 Web 应用或处理数据库查询时,分页是一项常见需求。然而,当面对深度分页(即页码较大,偏移量较高的分页情况)时,性能问题往往接踵而至。比如对一些需要拉特定的页面查询、范围导出、范围计算等业务需求,都会涉及大量的深分页查询的 SQL,不当的 SQL 会导致执行超时,页面响应显著上升等问题。本文重点讨论 Mysql 下以 Innodb 为存储引擎时,深分页造成性能恶化的根因以及一般解决方案。
为什么 Limit 在 offset 很大时性能会变差?
假设当前存在一张 item 表,单表有千万级数据,其核心字段有 id, item_code, item_name, type, sub_type, biz_type, status 等,并且在
type, sub_type, biz_type三个字段上存在索引, id 上存在默认的主键索引当执行 SQL
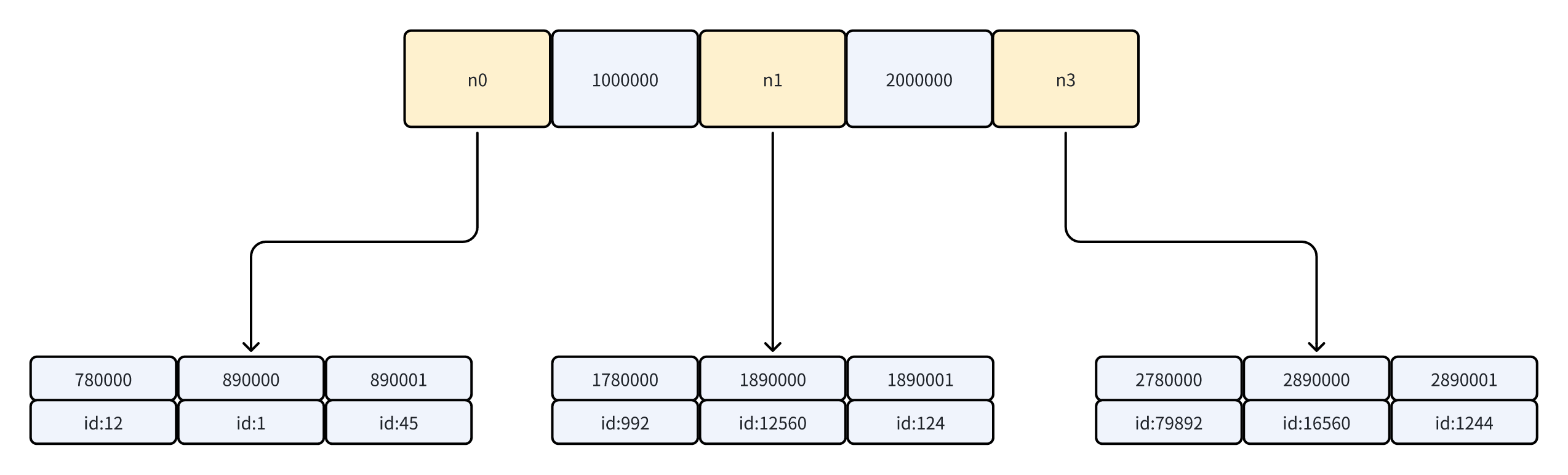
不必要的回表
我们都知道 innodb 采用 B+树作为索引(如上图),在普通索引的条件下,非叶子阶段上存储了索引列值的比较锚点,叶子节点上存储索引列值到主键 id 的 pair。在普通索引上查询到叶子节点并获取对应的主键后,若 SQL 中需要获取索引列以外的值,则需要到主键索引上,利用先前定位到的主键进行回表操作,获取完整的数据。
SQL2 和 SQL3 的对比正好是是否需要触发回表的对比,可以发现执行时间差了 4 倍以上。通过执行两者的执行计划,也可以发现,在 SQL3 的 extra 信息中,会有Using Index的信息,这代表命中了覆盖索引,不需要额外进行回表。
同时对比 SQL1 和 SQL2,两者只有在 offset 的部分存在区别,所以当 offset 变大时,会导致回表后需要扫描记录数显著增加(这也说明limit的执行逻辑是在回表之后,但是 where 条件执行是会在索引或者回表时就应用的,那么有办法把 limit 的操作前置到 where 中呢?)
延迟关联
子查询
两种方式都非常类似,都是通过避免回表,拿到数据的主键 id,再通过 join 或者 id 直接比较的方式,跳过了无意义的回表扫描。(相当于通过人为的方式将limit操作前置到回表之前了)
禁止跳页
还有一种简单的方式就是,需要客户端传入上一次调用的 last_id,然后在 where 条件里加上 last_id 的条件即可。但是这种做法使得客户端无法进行跳页访问了,只能连续的进行上一页或者下一页操作。(批处理或者导出的场景还是非常适用的)
关于 OrderBy 的影响
上述的 SQL 当 order by 条件发生变化时,SQL 的执行效率也会发生巨大的变化,甚至比 limit 本身影响更大。因为 order By 会决定 mysql 优化器的索引选择,以及会触发 FileSort(即在内存中开辟专属空间进行排序)。
全字段排序
可以看到 SQL5 仅仅是换了一个排序条件,并且查询计划显示命中的索引仍与先前一致,但是执行时间却来到了夸张的 9000ms,相比 SQL1,多了近 20 倍,为什么会产生这样的结果呢?可以先了解一下 OrderBy 的基本执行逻辑:
初始化 sort_buffer, 放入字段 id, item_code, type, sub_type
从 type 索引中找到符合 type = 'normal'的记录,获取 id
根据 id,从主键索引中获取 id, item_code, type, sub_type,放入 sort_buffer
重复 2~3,直到没有符合 type = 'normal'的记录
sort_buffer 根据 item_code 进行排序
排序结果取前 20 行返回
当排序的数据过大时,会启用外部排序(临时文件归并排序)
这里可能会有些疑问,为什么要把不排序的字段也放到 sort_buffer 中?是因为排完序后,可以直接从排序的结果集中取出完整的 Select 所需要的字段。
部分字段排序
那如果是 Select *呢?并且表的字段非常多,是否会过度浪费 sort_buffer 的资源,导致触发外部排序呢?是的,但是 Mysql 中存在一个配置,max_length_for_sort_data,当所放字段大于这个值时,就不会把所有 select 的字段放入 sort_buffer,而是选择排完序之后,再次进行回表,得到完整的数据:
初始化 sort_buffer, 放入字段 id, item_code
从 type 索引中找到符合 type = 'normal'的记录,获取 id
根据 id,从主键索引中获取 id, item_code,放入 sort_buffer
重复 2~3,直到没有符合 type = 'normal'的记录
sort_buffer 根据 item_code 进行排序
排序结果取前 20 行, 得到对应的 id,从聚簇索引中回表,得到完整的数据
通常来说,Mysql 规格够大时,不建议使用这种排序方式,因为会额外回表。
覆盖索引跳过排序
如果此时存在type, item_code的覆盖索引,则无需额外排序,即可返回结果集,执行效率是最高的。
但是如果 type 的条件变为in呢?
答案是,需要排序。因此这种情况下推荐在业务代码中,将其拆为两句 type = 'normal' 和 type = 'abnormal'的 SQL,然后业务代码中自行实现归并排序即可。
文章转载自:XinStar

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论