
数据库的性能调优:如何正确的使用索引?
在当今的数据驱动时代,数据库的性能优化成为每个开发者和数据库管理员必须掌握的技能之一。而在众多优化手段中,索引的使用无疑是最为重要和有效的。然而,索引的滥用或误用不仅不会提升性能,反而可能带来额外的开销。那么,如何正确地使用索引,才能真正提升数据库性能呢?
为什么有时我们精心创建的索引却没有带来预期的性能提升?究竟该如何正确地使用索引,才能确保数据库在查询时迅速高效?
Mysql 是一款广泛应用于各种规模和类型的应用程序的关系型数据库管理系统。在实际数据库应用中,我们常常面临这各种性能瓶颈和问题,据不完全统计,性能测试过程中发现的性能瓶颈有 70%以上的都是来自于数据库;而且当数据库的性能遭遇瓶颈的时候,应用程序的响应时间会延长,TPS 会降低,甚至严重的时候会导致系统崩溃和宕机。
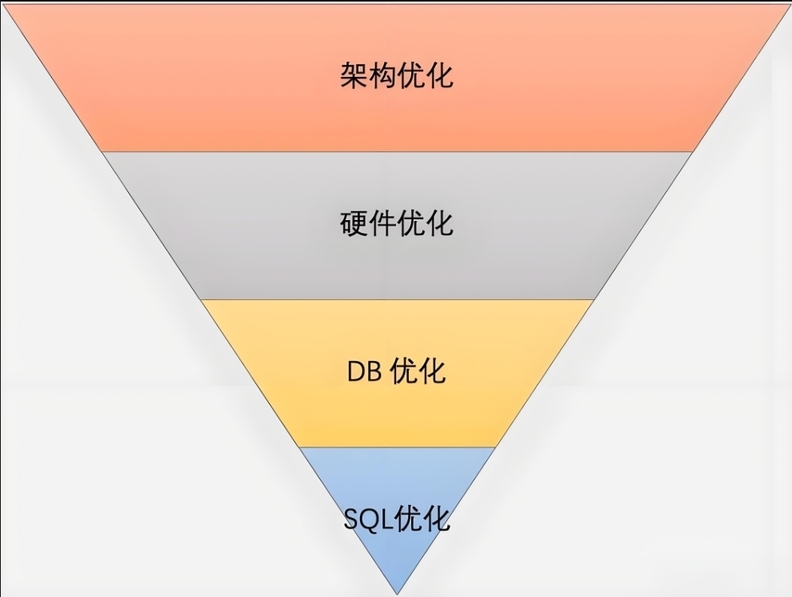
所以,对数据库进行性能调优就非常的重要,也是确保应用程序高效运行的关键一环。
Mysql 是一款广泛应用于各种规模和类型的应用程序的关系型数据库管理系统。在实际数据库应用中,我们常常面临这各种性能瓶颈和问题,据不完全统计,性能测试过程中发现的性能瓶颈有 70%以上的都是来自于数据库;而且当数据库的性能遭遇瓶颈的时候,应用程序的响应时间会延长,TPS 会降低,甚至严重的时候会导致系统崩溃和宕机。
所以,对数据库进行性能调优就非常的重要,也是确保应用程序高效运行的关键一环。
那么,数据库的性能瓶颈可能表现在哪些方面呢?主要总结如下:
1、数据库查询性能低下:某些查询语句执行速度缓慢,导致应用程序的响应时间变慢,用户体验下降;
2、并发访问问题:当多个用户同时访问数据库时,可能会出现锁竞争、死锁等问题,从而导致系统性能下降;
3、数据库配置不当:Mysql 的默认配置可能无法满足特定应用程序的需求,需要对参数进行释放的调整,比如数据库最大连接数等配置,可以获得更好的性能;
4、数据库存储引擎选择:不同的引擎具有不同的性能特点,选择合适的引擎也至关重要。
5、数据库的设计不合理:比如业务表数据过于庞大,没有进行分表分库,导致数据查询更新都很慢。
面对这些问题,我们需要对数据库采取一系列的调优措施,以提升 Mysql 数据库的性能和用户体验。我们今天主要给大家讲一下平时用的最多的索引调优。
索引概念
索引是一种数据结构,用于帮助我们在大量数据中快速定位我们要查找的数据,主要作用是加快我们查找数据的速度,类似于汉语字典和书籍目录。
大家有环境可以拿自己的项目试一下,加了索引和没有加索引的 sql 语句的执行速度。
这条语句的执行速度是 0.02s,因为 id 是主键索引;
这条 SQL 的执行速度是 0.118s,同一个库和表,慢出一个数量级,因为 mobile 字段不是索引。
给这张表的 mobile 字段加一个索引,然后再查询:
同一个 sql 语句速度立马提升到 0.020s
通过以上的简单的案例演示,我们发现索引确实可以很大程度的提高查询的速度,特别是数据量比较大的时候,这种速度提升的效果就尤其明显。
索引分类
索引主要的类型有如下几种:一张表,可以没有主键;如果有主键,主键这一列的值,一定是唯一,不重复,不存在‘空’
创建主键索引的方法:create index 索引名 on 表名(字段);
创建主键索引的语法:create unique index 索引名 on 表名(字段);
创建主键索引的语法:create index 索引名 on 表名(字段 1,字段 2,......);
主键索引 primary key :也叫做单值索引,如果一张表创建了主键,就默认会生成一个主键索引,不用再额外创建。
唯一索引(unique index):不可重复,但是可以存储 NULL
复合索引,也叫做组合索引:由表的多列按顺序组合成为索引;使用时,按照组合顺序使用索引,也可以使用组合索引中部分索引字段。
创建索引的原则
索引虽然可以大大的提升数据库的查询的性能,但是也不能盲目加索引,因为索引有一定大小,会占磁盘\内存空间。
创建索引,其实本质上就是使用空间换时间,以磁盘和内存的空间来换取查询时间更少;如果索引创建很多和很复杂,那么就会占用大量的内存空间,性能损耗就会很大;所以我们需要正确加索引,在空间和时间上取最佳平衡点。
我们创建索引的时候要遵循如下原则:
可以创建索引的列:
1、主键列可以创建索引,外键列用于表关联和链接查询的条件, 也可以用于创建索引
2、频繁查询的数据列可以用于创建索引
3、频繁用在 where 语句中的列可以创建索
不应该创建索引的列:
表修改操作远频繁于查询操作时 :因为修改表是需要修改索引的,所以维护索引成本比用索引的成本高了;
数据很少的列,比如 type 字段只有 0 和 1 两个值,提升不明显;
查询很少用到的列,或者经常会变化列值的 【类型会变化的列】
如何正确的使用索引索引的最左前缀规则当索引类型为复合索引的时候,我们要遵循组合索引的“最左前缀”规则,否则使用就会失效,无法达到提高查询效率的目的。
比如创建组合索引(c1,c2,c3),实际包含三个索引(c1),(c1,c2),(c1,c2,c3),索引里必须有一个最左边的字段。必须要按照这个索引来使用才是会正确使用索引,否则就不会使用索引。
我们建索引的时候,使用的列,只要列的名称,与表列的顺序没有关系,因为表中的列是没有顺序的,
我们做个小练习:如果在表里有如下字段,我们创建一个复合索引:
如上组合索引,就相当于加了 3 个索引:
mobile
mobile,email
mobile,email,gqid
我们的 SQL 语句就需要按照如上三个索引去查询,才会使用索引提高速度,所以要正确的使用索引。我们做个判断练习,以下 SQL 语句哪些会使用索引,哪些不会使用索引?
索引失效其他场景
1、sql 向右匹配遇到查询范围就会停止匹配,后面的索引就无效了:比如 between like 等 ;
2、like %value% 这种 % 出现在开头,也不会使用索引【索引失效】:
3、列上做了函数或者表达式运算,也会导致索引失效:
4、查询条件里有 or 的时候,除非所有的查询条件都有索引,否则索引失效:
5、如果列类型是字符串,那么查询条件中需要将数据用引号引用起来,否则不走索引:
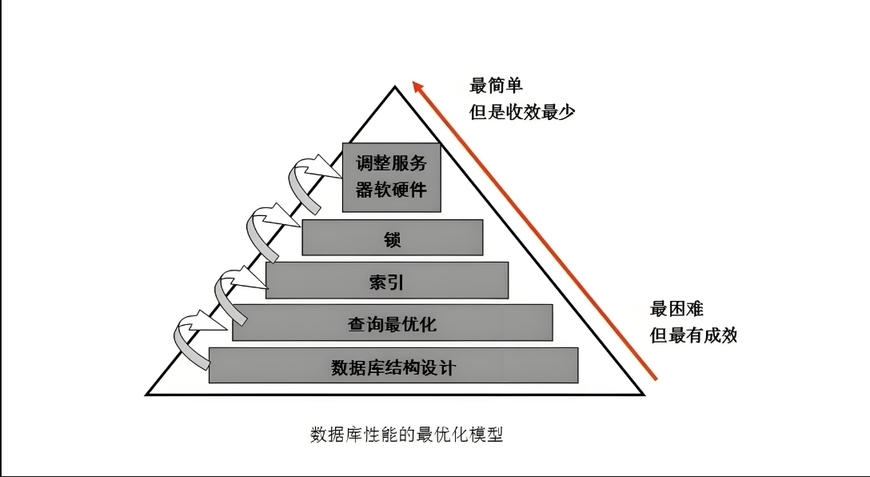
索引的利弊总结
索引的弊端
a、索引本身很大,通常存在在磁盘(也可以存在内存) ,所以不要随便见索引,占用空间;
b、不是所有情况都可以用索引:数据量很少的情况,以及列值频繁变更 ,还有列很少使用的情况都不推荐使用索引;
c、索引会提升查的效率但是会降低增删改的效率, 因为增删改需要修改更新索引本身,所以加了索引反而会降低增删改的速度。
索引的优势 a、降低 IO、CPU 使用率:查询的时候,一行一行比对 需要 CPU 大量操作,每一行都读取 IO 也会高;索引就会降低这些小消耗
b、索引列,可以保证行的唯一性:想让某个字段唯一 可以把这个字段设置为唯一索引,那么就在功能上保证它的唯一了。
c、可以有效缩短数据检索时间
d、加快表与表之间的连接 :多表关联查询,一般会把关联字段 【外键】创建索引,大大提升查询的效率。
所以,索引要设置,但是不能滥用,合理设置索引就很重要。一般,数据库的表数据量级别在十万级以内,有无索引,查找数据的速度差异不大,没必要建索引。
在大数据时代,数据量的爆炸式增长给数据库的性能带来了巨大挑战。随着企业对实时数据分析和快速响应需求的增加,数据库性能优化的重要性愈加凸显。正确使用索引是解决这一问题的关键之一,但也需要结合实际业务场景和数据特点,避免盲目创建索引。
索引如利剑,用之得当,所向披靡;用之不当,反受其累。
通过详实的案例和社会现象分析,这篇文章展示了正确使用索引在数据库性能优化中的重要性,并通过引人入胜的开头和有力的金句收尾,使读者对索引优化产生了浓厚的兴趣和实际操作的动机。
文章转载自:WanWuJieKeLian

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论