
度小满与哈工大共同推出 SmartTrim,自适应剪枝技术提升多模态大模型效率
在视觉语言大模型(VLM)的研究和应用中,高计算成本一直是制约其广泛部署的主要障碍。近日,哈尔滨工业大学联合度小满共同研发出一种创新的自适应剪枝算法——SmartTrim。该算法针对多模态大模型的冗余计算进行有效削减,实现了显著的效率提升,相关研究成果已被国际自然语言处理领域顶级会议 COLING 24 接收。
据介绍,SmartTrim 技术的核心在于其自适应剪枝能力,通过分析模型中每层的 token 表示和 attention head 的冗余性,智能识别并剪除不必要的计算负担。这一过程中,SmartTrim 不仅考虑了 token 在单一模态序列中的重要性,还特别强调了跨模态交互中的关键作用。通过这种精细化的剪枝策略,SmartTrim 能够在保持模型性能的同时,大幅提升计算效率。
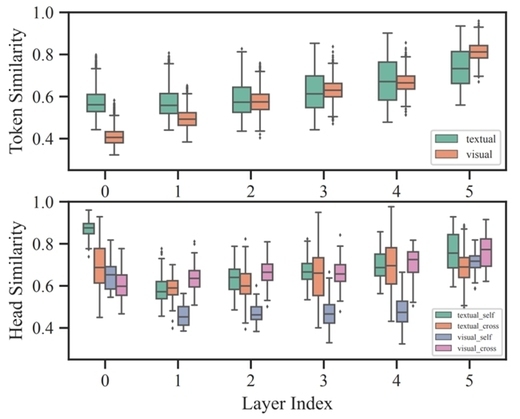
在基于 VQA 微调的 METER 的跨模态编码器中,层内不同 token(上)和 attention head(下)表示的相似性。
SmartTrim 框架的实施涉及两个关键组件:跨模态感知的 Token 修剪器和模态自适应的注意力头修剪器。Token 修剪器利用多层感知器(MLP)结构,智能地识别并去除那些对于当前层不重要的 Token。这一过程不仅考虑了 Token 在文本或图像序列中的独立重要性,还综合了它们在跨模态交互中的贡献。注意力头修剪器则直接集成在模型的自注意力模块中,评估并修剪那些冗余的注意力头,从而优化了模型的计算效率。
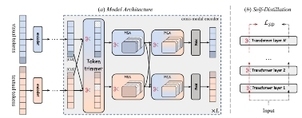
SmartTrim 框架结构图
在训练 SmartTrim 模型时,研究人员采用了一种结合任务相关目标和计算开销目标的双重优化策略。通过重参数化技巧,解决了不可导二值 mask 的问题,实现了模型的端到端训练。此外,自蒸馏和课程学习策略的引入,进一步提高了剪枝后模型的性能,确保了训练过程的稳定性。

Token 的逐步裁剪修剪过程
实验结果表明,SmartTrim 在 METER 和 BLIP 两个 VLM 上实现了 2-3 倍的加速,同时将性能损失最小化。这一成果不仅在理论上具有创新性,也为实际应用中的模型优化提供了新的思路。特别是在 1.5 倍加速比下,SmartTrim 的性能甚至超过了原始模型。在高加速比下,SmartTrim 相比其他方法展现出显著优势。
SmartTrim 技术的推出,标志着多模态大模型研究的一个重要里程碑。度小满表示,SmartTrim 技术将在未来整合到公司的轩辕大模型中,以推动大模型技术的发展。相关研究者可以通过访问https://github.com/Duxiaoman-DI/XuanYuan,了解更多关于 SmartTrim 的详细信息和研究成果。

还未添加个人签名 2021-05-31 加入
还未添加个人简介





评论