
EasyCV 带你复现更好更快的自监督算法 -FastConvMAE
作者: 夕陌、谦言、莫申童、临在
导读
自监督学习(Self-Supervised Learning)利用大量无标注的数据进行表征学习,在特定下游任务上对参数进行微调,极大降低了图像任务繁重的标注工作,节省大量人力成本。近年来,自监督学习在视觉领域大放异彩,受到了越来越多的关注。在 CV 领域涌现了如 SIMCLR、MOCO、SwAV、DINO、MoBY、MAE 等一系列工作。其中 MAE 的表现尤为惊艳,大家都被 MAE 简洁高效的性能所吸引,纷纷在 MAE 上进行改进,例如 MixMIM,VideoMAE 等工作。MAE 详解请参考往期文章:MAE自监督算法介绍和基于EasyCV的复现。
ConvMAE 是由上海人工智能实验室和mmlab联合发表在 NeurIPS2022 的一项工作,与 MAE 相比,训练相同的 epoch 数, ImageNet-1K 数据集的 finetune 准确率提高了 1.4%,COCO2017 数据集上微调 25 个 epoch 相比微调 100 个 epoch 的 MAE AP box 提升 2.9, AP mask 提升 2.2, 语义分割任务上相比 MAE mIOU 提升 3.6%。在此基础上,作者提出了 FastConvMAE,进一步优化了训练性能,仅预训练 50 个 epoch,ImageNet Finetuning 的精度就超过 MAE 预训练 1600 个 epoch 的精度 0.77 个点(83.6/84.37)。在检测任务上,精度也超过 ViTDet 和 Swin。
EasyCV 是阿里巴巴开源的基于 Pytorch,以自监督学习和 Transformer 技术为核心的 all-in-one 视觉算法建模工具,覆盖主流的视觉建模任务例如图像分类,度量学习,目标检测,实例/语音/全景分割、关键点检测等领域,具有较强的易用性和扩展性,同时注重性能调优,旨在为社区带来更多更快更强的算法。
近期 FastConvMAE 工作在 EasyCV 框架内首次对外开源,本文将重点介绍 ConvMAE 和 FastConvMAE 的主要工作,以及对应的代码实现,最后提供详细的教程示例如何进行 FastConvMAE 的预训练和下游任务的 finetune。
ConvMAE
ConvMAE 是由上海人工智能实验室和mmlab联合发表在 NeurIPS2022 里的一项工作,ConvMAE 的提出证明了使用局部归纳偏置和多尺度的金字塔结构,通过 MAE 的训练方式可以学习到更好的特征表示。该工作提出:
使用 block-wise mask 策略来确保计算效率。
输出编码器的多尺度特征,同时捕获细粒度和粗粒度图像信息。
原文参考:https://arxiv.org/abs/2205.03892
实验结果显示,上述两项策略是简洁而有效的,使得 ConvMAE 在多个视觉任务中相比 MAE 获得了明显提升。以 ConvMAE-Base 和 MAE-Base 相比为例:在图像分类任务上, ImageNet-1K 数据集的微调准确率提高了 1.4%;在目标检测任务上,COCO2017 微调 25 个 epoch 的 AP box 达到 53.2%,AP mask 达到 47.1%,与微调 100 个 epoch 的 MAE-Base 相比分别提升 2.9% 和 2.2% ;在语义分割任务上,使用 UperNet 网络头,ConvMAE-Base 在 ADE20K 上的 mIoU 达到 51.7%,相比 MAE-Base 提升 3.6%。
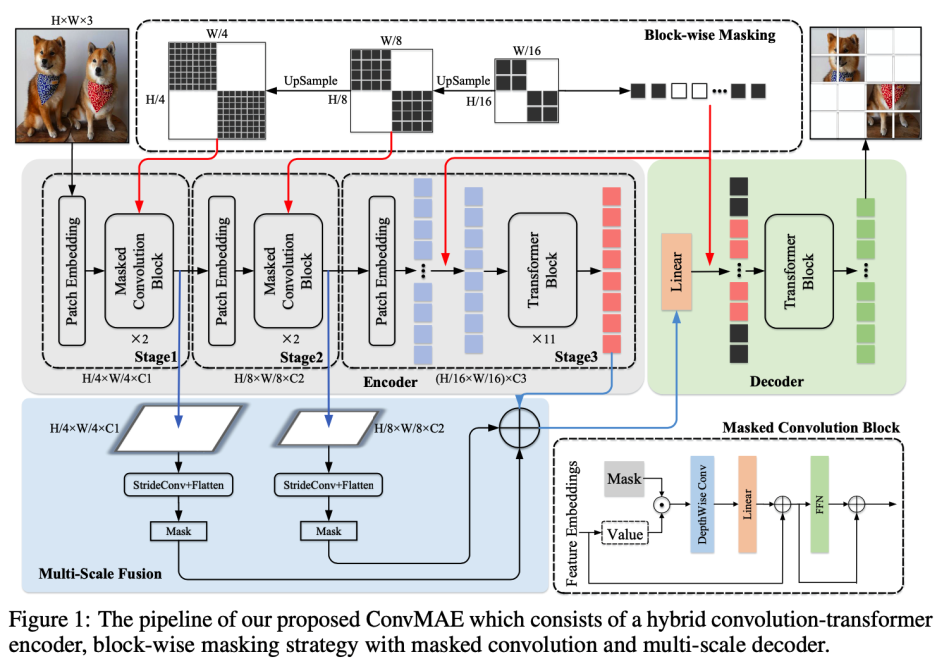
与 MAE 不同的是,ConvMAE 的编码器将输入图像逐步抽象为多尺度 token embedding,而解码器则重建被 mask 掉的 tokens 对应的像素。对于前面 stage 部分的高分辨率 token embedding,采用卷积块对局部进行编码,对于后面的低分辨率 token embedding,则使用 transformer 来聚合全局信息。因此,ConvMAE 的编码器在不同阶段可以同时获得局部和全局信息,并生成多尺度特征。
当前的 masked auto encoding 框架,如 BEiT,SimMIM,所采用的 mask 策略不能直接用于 ConvMAE,因为在后面的 transformer 阶段,所有的 tokens 都需要保留。这导致对大模型进行预训练的计算成本过高,失去了 MAE 在 transformer 编码器中省去 masked tokens 的效率优势。此外,直接使用 convolution-transformer 结构的编码器进行预训练会导致卷积部分因为随机的 mask 而造成预训练的信息泄露,因而也会降低预训练所得模型的质量。
针对这些问题,ConvMAE 提出了混合 convolution-transformer 架构。ConvMAE 采用分块 mask 策略 (block-wise masking strategy):,首先随机在后期的获取 transformer token 中生成后期的 mask,然后对 mask 固定位置逐步进行上采样到早期卷积阶段的高分辨率。这样,后期处理的 token 可以完全分离为 masked tokens 和 visible tokens,从而并继承了 MAE 使用稀疏 encoder 的计算效率。
下面将分别针对 encoder、mask 策略以及 decoder 部分展开介绍。
Encoder
如总体流程图所示,encoder 包括 3 个阶段,每个阶段输出的特征维度分别是:H/4 × W/4, H/8 × W/8, H/16 × W/16,其中 H × W 为输入图像分辨率。前两个是卷积阶段,使用卷积模块将输入转换为 token embeddings E1 ∈ R^(H/4 × W/4 ×C1) and E2 ∈ R^(H/8 × W/8 ×C2) 。其中卷积模块用 5 × 5 的卷积代替 self-attention 操作。前两个阶段的感受野较小主要捕捉图像的局部特征,第三个阶段使用 transformer 模块,将粗粒度特征融合, 并将感受野扩展到整个图像,获得 token embeddings E3 ∈ R(H/16 × W/16 ×C3)。在每个阶段之间,使用 stride 为 2 的卷积对 tokens 进行下采样。
其他包含 transformer 的结构,如 CPT、Container、Uniformer、CMT、Swin 等,在第一阶段的输入用相对位置编码或零填充卷积替代绝对位置编码,而作者发现在第 3 个 transformer stage 中使用绝对位置编码可获得最优性能。class token 也从编码器中移除。
Mask 策略
MAE、BEiT 等,对输入 patch 采用随机 mask。但同样的策略不能直接应用于 ConvMAE 编码器:如果独立地从 stage-1 的 H/4 × W/4 个 tokens 中随机抽取 mask,将导致降采样后的 stage-3 的几乎所有 token 都有部分可见信息,使得编码器不再稀疏。因此作者提出,从 stage-3 的输入 tokens 中以同样比例 (例如 75%)生成 mask,再对 mask 上采样 2 倍和 4 倍,分别作为 stage-2 和 stage-1 的 mask。这样,ConvMAE 在 3 个阶段都只含有很少的(例如 25%)可见 token,从而使得预训练时编码器的效率不受影响。而解码器的任务 e 则保持相同,即重建编码过程中被 mask 掉的 tokens。
同时,前 2 个阶段的 5X5 卷积操作会在 masked patches 的边缘处泄漏不可见 token 的重建答案。为了避免这种情况保证预训练的质量,作者在前两个阶段采用了 masked convolution, 使被 mask 掉的区域不参与编码过程。
Decoder
原始 MAE 的 decoder 的输入以编码器的输出和 mask 掉的 tokens 作为输入,然后通过堆叠的 transformer blocks 进行图像重建。ConvMAE 编码器获得多尺度特征 E1、E2、E3,同时捕获细粒度和粗粒度图像信息。为了更好地的预训练,作者通过 stride-4 和 stride-2 卷积将 E1 和 E2 下采样到 E3 的相同大小,并进行多尺度特征融合,再通过一个 linear 层得到最终要输入给 decoder 的可见 token。目标函数和 MAE 相同,仅采用 MSE 作为损失函数,计算预测向量和被 mask 掉像素值之前的 MSE loss,即只考虑 mask 掉的 patches 的重建。
下游任务
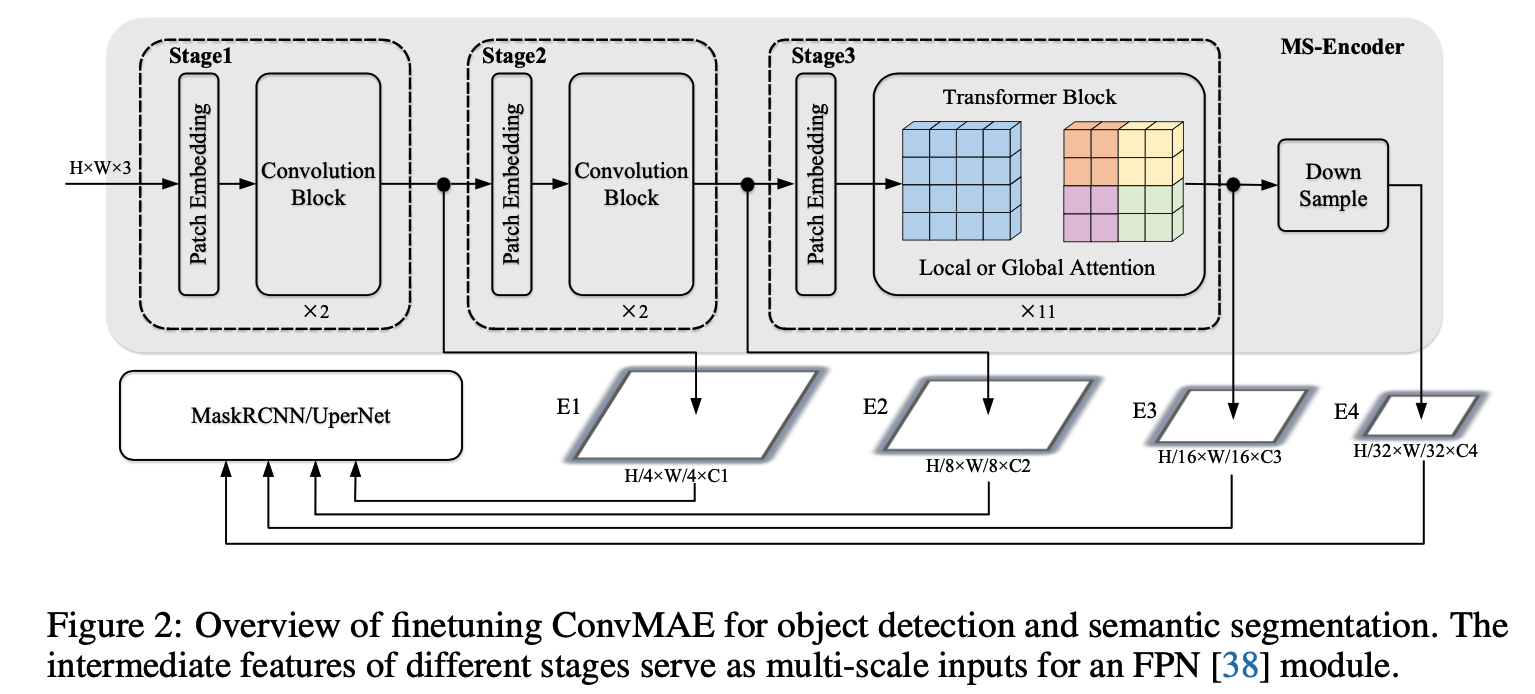
预训练之后,ConvMAE 可以输出多尺度的特征用于检测分割任务。
检测任务中,先将第 stage-3 的输出特征 E3 通过 2x2 最大池化获得 E4。由于 ConvMAE stage-3 有 11 个 self-attention 层(ConvMAE-base),计算成本过高,作者参考 ViT 的 benchmark 将 stage-3 中除第 1、4、7、11 之外的所有 global self-attention layers 替换为了 Window size7×7 的 local self-attention 层。修改后的 local self-attention 仍然由预训练的 global self-attention 进行初始化。global transformer blocks 之间共享 global relative position bias,local transformer blocks 之间共享 local relative position bias,这样就大大减轻了 stage-3 的计算和 GPU 内存开销。然后将多尺度特征 E1、E2、E3、E4 送入 MaskRCNN head 进行目标检测。
而分割任务保留了 stage-3 的结构。
Benchmark
图像分类
ConvMAE 基于 ImageNet-1K,mask 掉 25%的 input token 做预训练,Decoder 部分是一个 8 层的 transformer,embedding 维度是 512,head 是 12 个。预训练参数和分类 finetuning 结果如下:
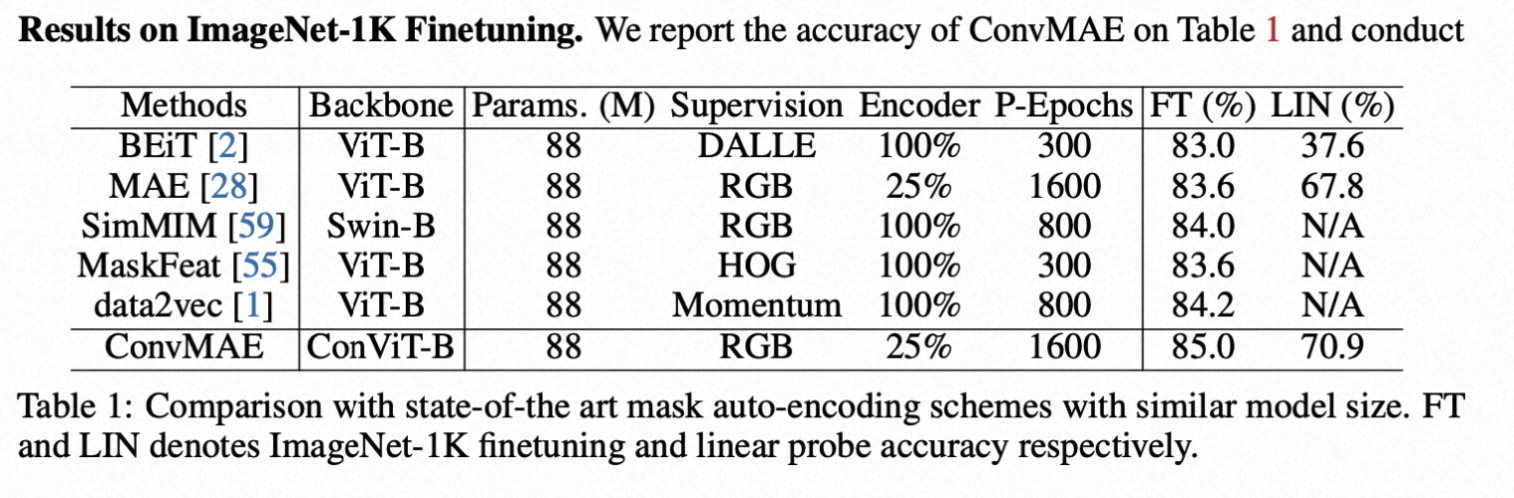
BEiT 预训练 300 个 epoch,finetune 的精度达到 83.0%,linear-prob 的精度是 37.6%。与 BEiT 相比,ConVMAE 仅需要 25%的 token 和一个轻量级的 decoder finetune 可达到 85%,linear-prob 可以达到 70.9%。与原来的 MAE 相比,预训练相同的 1600 个 epoch,ConVMAE 比 MAE 提升 1.4 个点。与 SimMIM(backbone 使用 Swin-B)相比提升了 1 个点。
检测
作者用 ConvMAE 替换 Mask-RCNN 的 backbone,加载 ConvMAE 的预训练模型训练 COCO 数据集。


与 ViT 在 COCO 数据集上 finetune100 个 epoch 的结果相比,ConVMAE 仅 finetune 25 个 epoch 在 APbox 和 APmask 就提升了 2.9 和 2.2 个点。
与 ViTDet 和 MIMDet 相比,ConvMAE finetune epoch 更少、参数更少,分别超过了它们 2.0%和 1.7%。
与 Swin 和 MViTv2 相比,在 APbox/APmask,其性能分别高出 4.0%/3.6%和 2.2%/1.4%。
分割
作者用 ConvMAE 替换 UperNet 的 backbone,加载 ConvMAE 的预训练模型训练 ADE20K 数据集。
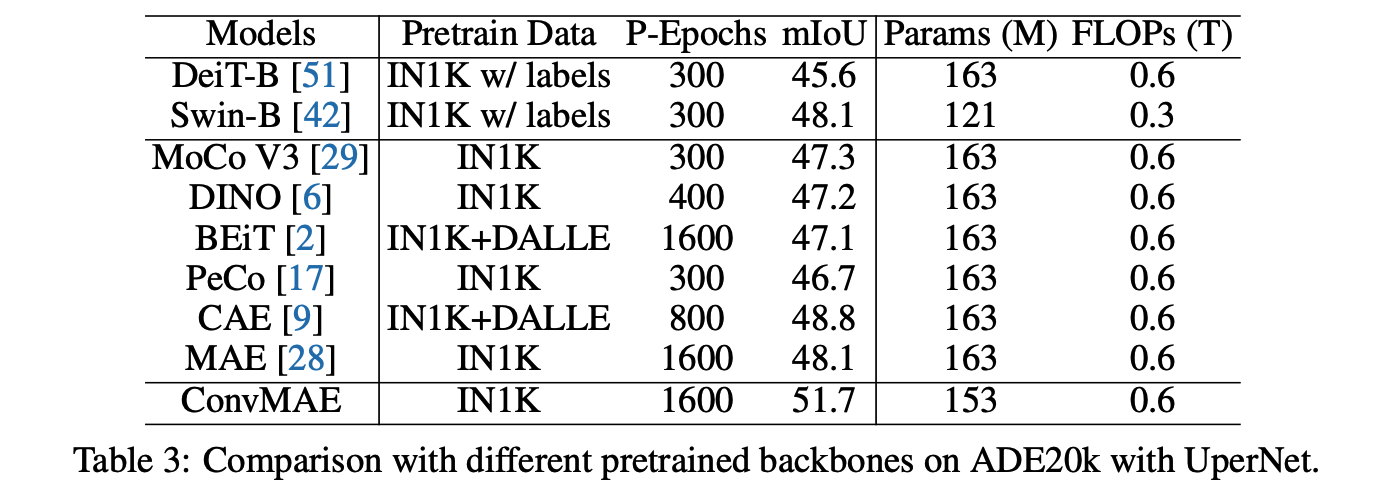
从结果中可以看出,相比与 DeiT, Swin,MoCo-v3 等网络 ConvMAE 取得了更高的性能(51.7%)。表明 ConvMAE 的多尺度特征大大缩小了预训练 Backbone 和下游网络之间的传输差距。
Fast ConvMAE
ConvMAE 虽然在分类、检测、分割等下游任务中有了精度提升,并解决了 pretraining-finetuning 的差异问题,但是模型的预训练依然耗时,ConvMAE 的结果中,模型预训练了 1600 个 epoch,因此作者又在 ConvMAE 的基础之上做了进一步的性能优化,提出了 Fast ConvMAE,FastConvMAE 提出了 mask 互补和 deocder 融合的方案,来实现快速的 mask 建模方案,进一步缩短了预训练的时间,从原来预训练的 1600epoch 缩短到了 50epoch。FastConvMAE 的正式论文作者会在未来发出。
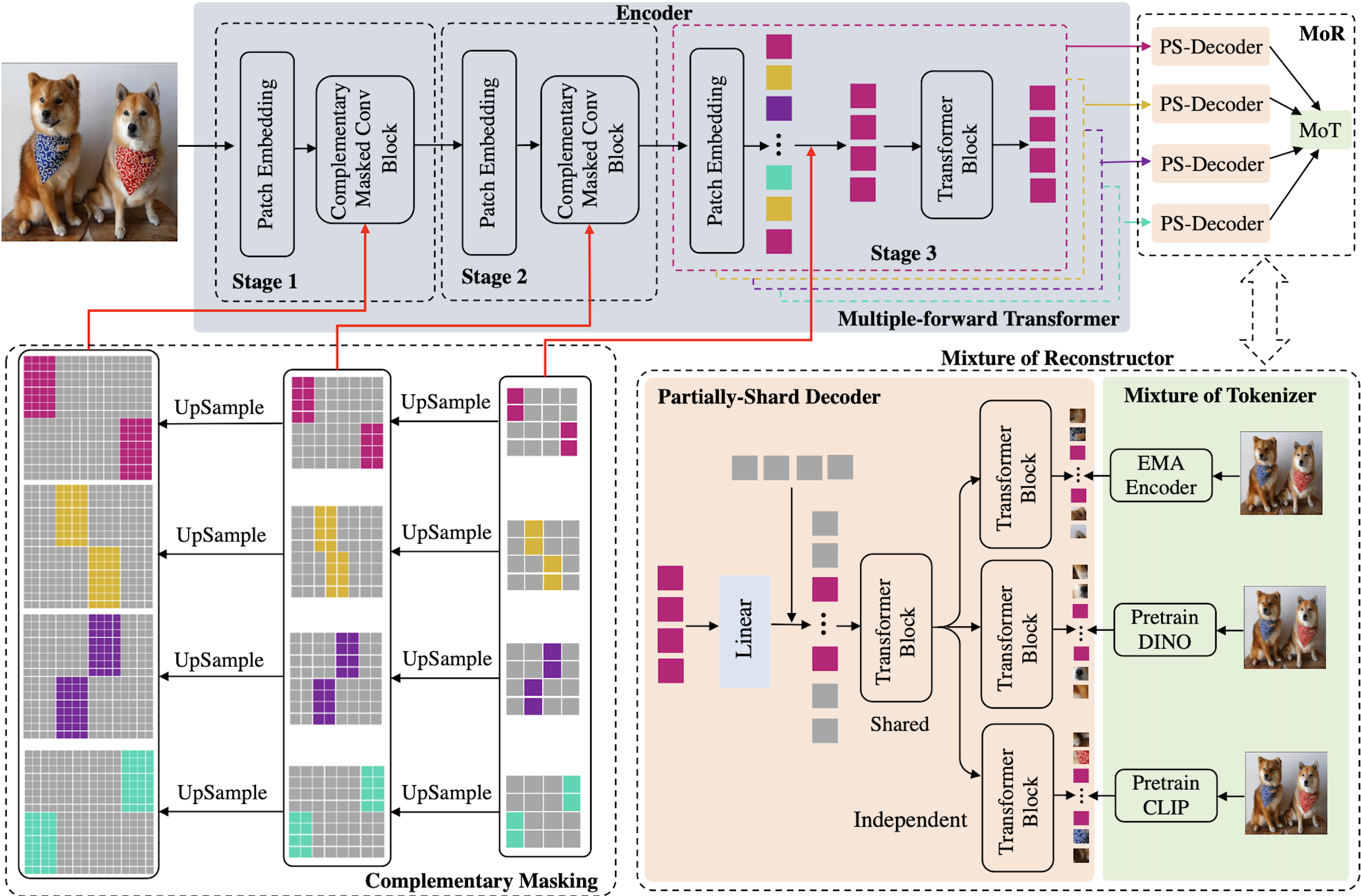
首先,FastConvMAE 创新地设计出 decoder 互相融合的 Mixture of Reconstructor (MoR),可以让 masked patches 从不同的 tokenizer 中学习到互补的信息,包括 EMA 的 self-ensembling 性质,DINO 的 similarity-discrimination 能力,以及 CLIP 的 multimodal 知识。MoR 主要包括两个部分,Partially-Shared Decoder(PS-Decoder)和 Mixture of Tokenizer(MoT), PS-Decoder 可以避免不同 tokenizer 的不同知识之间会产生梯度的冲突,MoT 是用来生成不同的 token 作为 masked patches 的 target。
同时 Mask 部分采用了互补策略,原来的 mask 每次只会保留例如 25%的 tokens,FastConvMAE 将 mask 分成了 4 份,每一份都保留 25%,4 份 mask 之间互补。这样,相当于 1 张图片被分成了 4 张图片进行学习,理论上达到了 4 倍的学习效果。
前两个卷积阶段将输入转换为 embeddings tokens E1 和 E2。然后 E1 和 E2 分别从 4 份 mask 中获取 4 份可见的 tokens 并进行拼接,作为 decoder 的输入,Decoder 处理的是拼接后的 tokens。代码参考如下:
Benchmark
EasyCV 复现的结果如下:
ImageNet Pretrained

ImageNet Finetuning

Object Detection

从结果可以看出,仅预训练 50 个 epoch,ImageNet Finetuning 的精度就超过 MAE 预训练 1600 个 epoch 的精度 0.77 个点(83.6/84.37)。在检测任务上,精度也超过 ViTDet 和 Swin。
FastConvMAE 的更多官方结果请参考:https://github.com/Alpha-VL/FastConvMAE 。
Tutorial
一、安装依赖包
如果是在本地开发环境运行,可以参考该链接安装环境。若使用 PAI-DSW 进行实验则无需安装相关依赖,在 PAI-DSW docker 中已内置相关环境。
二、数据准备
数据准备请参考文档:https://github.com/alibaba/EasyCV/blob/master/docs/source/prepare_data.md
三、模型预训练
FastConvMAE 占用显存较大,建议使用 A100 资源。(FastConvMAE 一次 forward-backward 等价于 ConvMAE forward-backward 4 次)
在 EasyCV 中,使用配置文件的形式来实现对模型参数、数据输入及增广方式、训练策略的配置,仅通过修改配置文件中的参数设置,就可以完成实验配置进行训练。
配置 EasyCV 路径
训练
下游任务 finetune
下载预训练模型
单卡
多卡
分类任务 CONFIG_FILE 请参考:https://github.com/alibaba/EasyCV/tree/master/benchmarks/selfsup/classification/imagenet/fast_convmae_vit_base_patch16_8xb64_100e_fintune.py
分类任务 CONFIG_FILE 请参考:https://github.com/alibaba/EasyCV/blob/master/benchmarks/selfsup/detection/coco/mask_rcnn_conv_vitdet_50e_coco.py
Reference
EasyCV:https://github.com/alibaba/EasyCV/blob/master/easycv/models/backbones/conv_mae_vit.py
EasyCV 往期分享

还未添加个人签名 2020.10.15 加入
分享阿里云计算平台的大数据和AI方向的技术创新和趋势、实战案例、经验总结。









评论