
大数据开发应用场景解读 & 需求产品初探
Key Takeaways:
“移动计算比移动数据更划算”;
企业有多云数据,需要一个稳定可靠的云原生大数据开发平台统一处理数据,以及基于此的附加服务,如:存储、治理、BI 等;
大数据开发产品的定位是基于数据集成、数据开发和数据运维为一体的一站式大数据开发平台;
大数据开发的核心场景是:数据集成、数据处理、数据存储、数据导出、任务编排 &调度;
引言
从谷歌在 2004 年发表的三篇经典论文(MapReduce,GFS,BigTable)开始,出现了与传统关系型数据库技术有所不同的分布式数据系统技术栈。这一趋势被后来的 Hadoop 开源生态发扬光大,在业界形成了长达十多年的深远影响。也让“移动计算比移动数据更划算”的理念深入人心。
随着 AWS 引领的云计算浪潮的崛起,云计算商业模式的出现,企业无需购买、部署自己的服务器,只需要按需购买云服务,就可以使用各种各样的计算资源,比如虚拟主机、缓存、数据库等。相比以往自建数据中心,企业可以以更低、更简单的方式、更灵活的手段使用云计算。现在,随着所有应用程序都部署在云上,数据也产生在云端,这样自然而然的,大数据也在云上处理即可,主流的云计算厂商都提供了大数据云计算服务。云计算厂商将大数据平台的各项基本功能以云计算服务的方式向用户提供,例如数据导入导出、数据存储与计算、数据流计算、数据展示等。由此,新一代的云原生数据平台已逐渐出现,而定位于数据开发场景的各类大数据产品是其中的衍生产品之一。主要为企业数据上云、多云数据(企业出于安全、议价考虑往往选择多云)集成 &开发等场景提供服务。
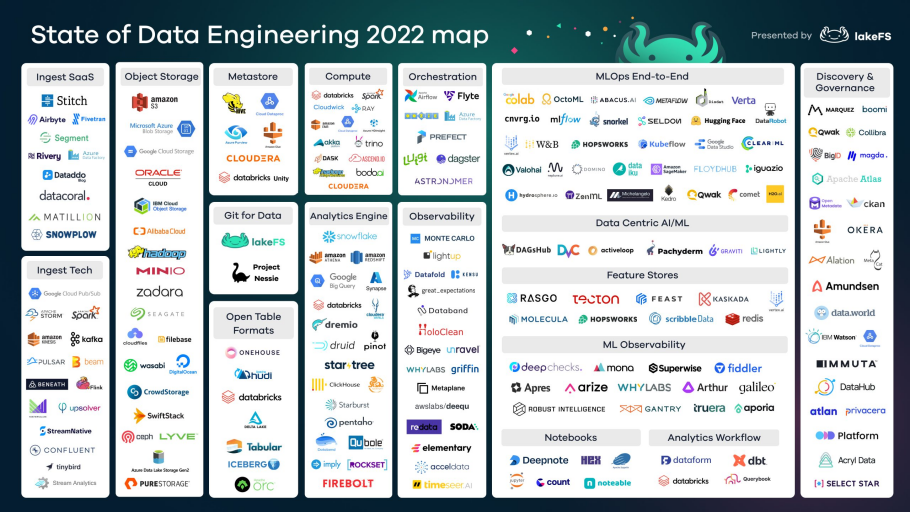
(State of Data Engineering 2022 map)
大数据开发场景解析 &产品初探
1)背景和定位
对于各种组件的组合需求,伴随着云原生时代的到来,出现了越来越多更加易于直接“组装使用”的 SaaS 数据产品。相比之前部署运维 Hadoop,Kafka 集群的复杂度,新一代的云原生产品一般都可以直接使用托管服务,按量付费,即开即用,对于非互联网类公司来说非常友好。所以常见的数据平台架构都开始往引入各种产品组件的方向发展。
在数据处理层面,会使用不同的计算引擎来执行批处理或者流式处理的任务,但对于用户接口来说,希望尽可能保持一致,也就是所谓的“流批一体”。
在存储和数据服务层面,“数据湖”和“数据仓库”在数年的交锋 &发展后发现也并不能完全替代对方。新物种 lakehouse 也就是“湖仓一体”成为最新一大趋势。同时,随着 snowflake 为代表的云数仓的成功,数据仓库也都走向了云原生化,也开始支持使用他们的计算引擎直接对数据湖上的文件进行计算处理。
因此,大数据开发产品的定位是基于“生产->采集->存储->分析->开发->治理->价值体现”这个链路过程,主要解决数据集成、数据开发、数据运维、数据治理(也可单独作为一个产品,如华为云 DataArts Studio,阿里云 Dataworks 则是以集成的方式将其作为一个模块)。
2)数据架构总览
基于前一小节所述,著名的投资机构 a16z 给出的统一数据架构总览比较完整的描述了整个基于云的大数据开发平台的经典数据架构。基架构范围包含了整个数据场景链路,围绕其架构所衍生出的各环节的产品也已取得市场上的成功。
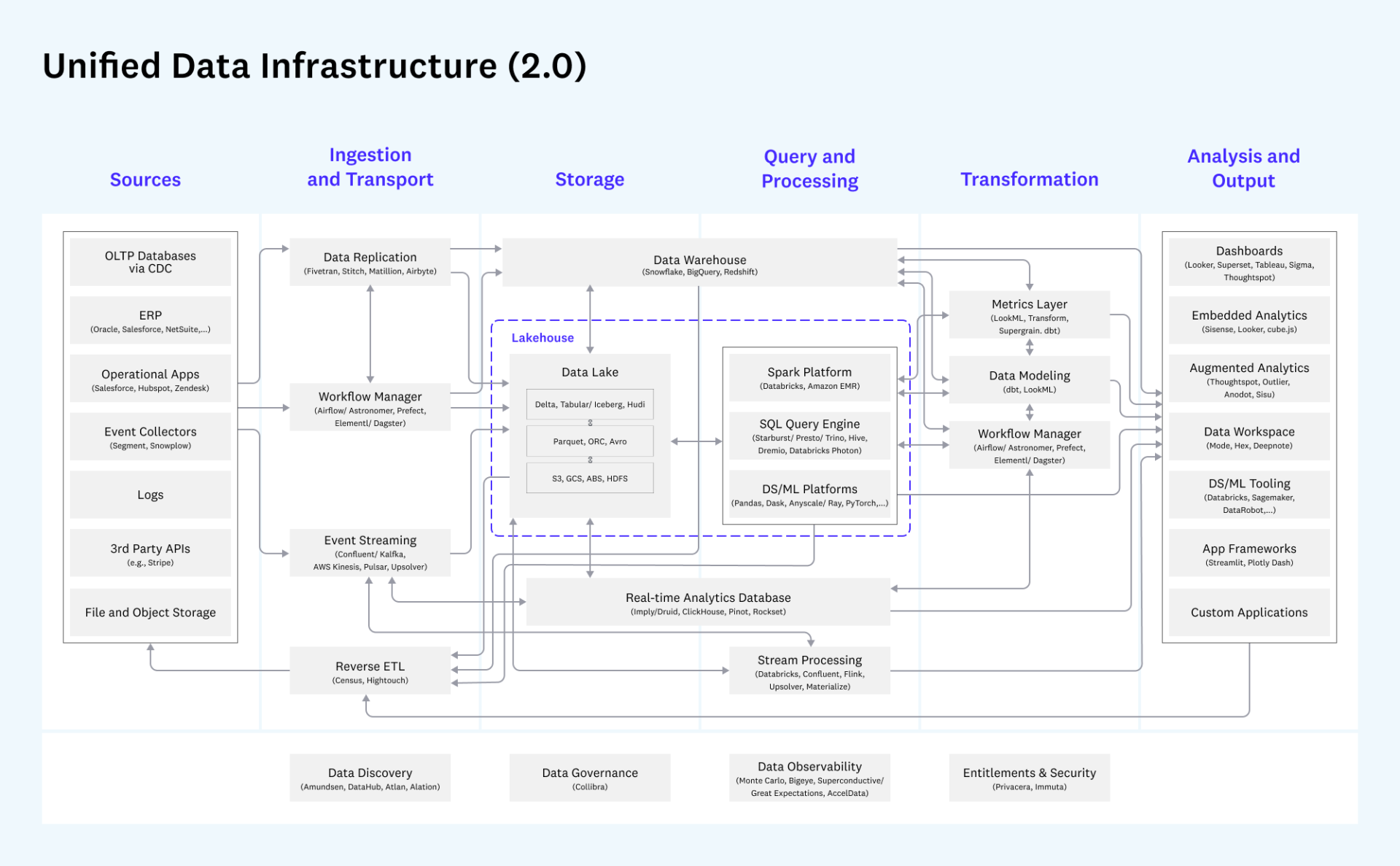
来源:https://future.com/emerging-architectures-modern-data-infrastructure/
这张图画得非常详细,把整个数据流转的过程分成了数据源(一般不包含在数据平台里),数据获取与传输、存储、数据转换、查询处理、分析输出这几大块,而且每一块中的各个模块,相关的产品都做了详细的标注。
核心场景 &需求产品
1)核心场景
大数据开发主要面临的业务场景可分为以下 4 类:
数据集成:批量数据接入+流式数据接入;
数据存储:fast storage+slow storage;
数据处理 &导出:批处理+流处理;
ETL&任务编排:一个任务开发链路中,任务间存在依赖关系和先后执行顺序,需要支持多任务 workflow 式编排;
下面以两个具体场景为例:
场景 1---批处理:
从 ftp 服务器获取日志数据,经过清洗后导入 hive:
job1:从 ftp1 获取日志;
job2:从 ftp2 获取日志;
job3:将日志文件上传至 hdfs;
job4:调用 mr 清洗 hdfs 数据;
job5:将清洗完的数据导入 hive 库;
其中,依赖关系为:job3 依赖 job1 和 job2,job4 依赖 job3,job5 依赖 job4,job1 和 job2 没有依赖关系。
场景 2---流式处理(例如 Delta-live-tables 处理的场景):
json 数据->映射成 table->过滤有效数据后存入 lakehouse->实时表查询/BI 展示
2)数据集成 &需求产品
数据集成是将多个分散的数据源,在逻辑或物理上有机地集中,为企业解决数据孤岛问题。最早的数据集成系统可以追溯到 1991 年, 明尼苏达大学在构建人口数据库系统 IPUMS[1]时,使用了一种数据仓库方法,从不同的数据源中进行数据提取、数据转换并加载到一个统一的模式中,实现了数据集成。 从实际应用场景出发,大数据开发平台要解决的是两类数据集成场景。
批量集成
对于批处理数据,比如各种上传文件,ftp,或者其它无法支持实时消费的第三方 API 数据源。大多数企业目前基本都是以批处理的形式为主的。典型的做法是定时触发任务,通过组件去数据源中获取全量或者增量更新的数据内容,存放到数据平台中。如果把这个任务触发设置的比较频繁,我们也可以通过批处理的方式得到一个“准实时”更新的数据内容进行后续分析和使用。
流式集成
对于一些自动决策场景,例如推荐系统,交易风控,其对时效性要求较高,必须对接流式数据系统。一般通过引入 flink 等组件实现。
需求产品
对于此类需求,用户对于此类产品组件一般有如下诉求(见下表),市面上相应地也已经出现了多种不同程度上满足其场景需求的产品组件(见下图)。
3)数据存储 &需求产品

(快慢存储,图片来源:a16z)
如上图,slow storage 主要用于存放批数据(固定数据),在数仓时代就是 warehouse 系统里的存储部分,在数据湖时代,之前比较流行的是 HDFS 这类分布式文件系统,目前越来越往存算分离的方向发展,主流的存储方式基本都选择了各种对象存储,如 S3,GCS,ABS 、OBS 等。近年 Databricks 提出了 lakehouse 的概念,其中存储方面在底层对象存储之上又搭建了相应的元数据和存储协议,能够支持 schema 管理,数据版本,事务支持等特性。
fast storage 一般指对数据消费者提供即席查询,实时分析服务的存储系统,例如我们可以用一些实时性较高的分析型数据库(Presto,ClickHouse),或者针对性的存储服务如 KV 系统,RDBMS 等。而在上图里,fast storage 其实代表的含义更简单,就是流式数据系统的自带存储。

4)数据处理/导出 &需求产品
数据处理方面主要解决 3 种场景:批数据处理及导出、流式数据处理及导出、批流一体处理及导出。主要依赖于各开源大数据计算框架。

5)ETL/ELT/反向 ETL&需求产品
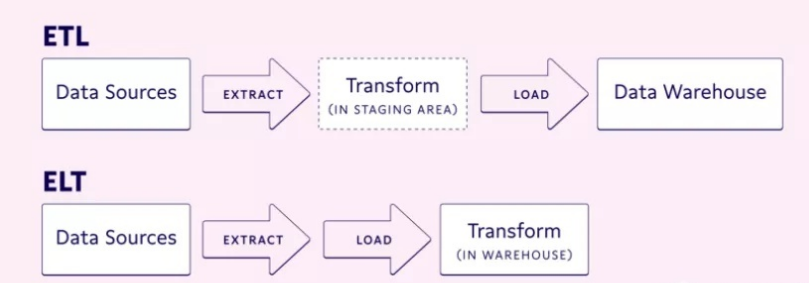
传统的 ETL 即抽取、转换、加载,目的是把数据经加工后存储起来。它是以数据作为资产的视角对数据进行处理。
ELT 则是先把数据从不同的数据源抽取出来,加载到数据仓库或者数据湖中,然后再根据不同的使用场景进行转换和使用。它是以数据作为服务的视角对数据进行消费从而产生价值。
Fivetran 2019 年提出 Modern ELT 口号:
https://www.fivetran.com/blog/competitive-analytics-requires-modern-architecture
反向 ETL 则是把数据从一个中心的数据仓库拷贝到客户的运营系统中,用于支持客户基于数据的后续动作,例如把数据装入到用来做增长、市场营销的 SaaS 系统中。

6)任务编排 &需求产品
编排流程中执行的具体任务,一般都是各种数据接入,数据转换操作,也就是我们俗称的 ETL 了。除了通过 SQL 或者计算引擎的 SDK(如 PySpark)来开发业务逻辑,市面上也有不少产品支持通过 no-code/low-code 方式做开发,大大降低了用户门槛。

种一颗树最好的时间是10年前,其次是现在。 2020.07.16 加入
数据产品经理,曾在Shareit、汽车之家等公司任职,也在创业公司摸爬滚打过,业余时间运营个人公号及网店,长期关注互联网大数据、电商&社群、旅游领域。









评论