本系列的前几篇文件,详细了介绍了 Vision 框架中关于静态图片区域识别的内容。本篇文章,我们将着重介绍静态图片中物体的识别与分类。物体识别和分类也是 Machine Learning 领域重要的应用。通过大量的图片数据进行训练后,模型可以轻易的分析出图片的属性以及图片中物体的属性。
1 - 文字识别
文字识别是应用非常广泛的一种图片识别技术。在 Vision 框架中,使用 VNRecognizeTextRequest 来进行文字识别,并且其支持多种语言,且有不错的识别精度。VNRecognizeTextRequest 的创建示例如下:
private lazy var recognizeTextRequest: VNRecognizeTextRequest = { let textDetectionRequest = VNRecognizeTextRequest { request, error in DispatchQueue.main.async { self.drawTask(request: request as! VNRecognizeTextRequest) } } // 设置语言 textDetectionRequest.recognitionLanguages = ["zh-Hans"] // 设置识别级别 accurate为最精准 fast为最快速 textDetectionRequest.recognitionLevel = .accurate // 设置是否使用语言矫正 textDetectionRequest.usesLanguageCorrection = true // 获取所支持的语言 let set = try? textDetectionRequest.supportedRecognitionLanguages() print(set) return textDetectionRequest}()
复制代码
可以通过对 VNRecognizeTextRequest 实例进行配置来调整识别精度,识别的语言,是否进行矫正的选项,VNRecognizeTextRequest 类的定义如下:
open class VNRecognizeTextRequest : VNImageBasedRequest, VNRequestProgressProviding { // 所支持的语言列表 open class func supportedRecognitionLanguages(for recognitionLevel: VNRequestTextRecognitionLevel, revision requestRevision: Int) throws -> [String] open func supportedRecognitionLanguages() throws -> [String] // 识别过程中所使用的语言 open var recognitionLanguages: [String] // 自定义的词汇,在识别单词时,自定义的词汇优先级会高于默认词典 open var customWords: [String] // 识别等级,精度优先会更加消耗性能 // accurate: 精度优先 fast: 速度优先 open var recognitionLevel: VNRequestTextRecognitionLevel // 设置是否使用自动矫正,自动矫正会更加消耗性能 open var usesLanguageCorrection: Bool // 设置是否自动识别语言类型,当不确定输入的语种时,可以设置其自动识别,会更消耗性能 open var automaticallyDetectsLanguage: Bool // 设置可识别文本的最小高度(为相对原图的比例值) open var minimumTextHeight: Float // 结果数组 open var results: [VNRecognizedTextObservation]? { get }}
复制代码
VNRecognizeTextRequest 的识别结果为 VNRecognizedTextObservation 类,此类也是继承自 VNRectangleObservation 的,因此我们也同时可以获取到所识别的文本所在原图的位置。VNRecognizedTextObservation 类的定义如下:
open class VNRecognizedTextObservation : VNRectangleObservation { // 获取候选结果 open func topCandidates(_ maxCandidateCount: Int) -> [VNRecognizedText]}
复制代码
topCandidate 会返回一组候选结果,其参数设置最多返回的候选结果个数,需要注意此参数所支持的最大值为 10。候选结果是指对于同一段文字,可能会识别出多个相似的结果,最终识别的文本结果 VNRecognizedText 类的定义如下:
open class VNRecognizedText : NSObject, NSCopying, NSSecureCoding, VNRequestRevisionProviding { // 识别出的文本字符串 open var string: String { get } // 本次识别结果的可信度(0-1之间) open var confidence: VNConfidence { get }}
复制代码
对于 confidence 可信度属性来说,越接近 1,可信度越高。
下图演示了照片中文本的识别效果:
可以看到,Vision 对于中文印刷体的识别能力还是比较准确的。
目前,所支持识别的语种列举如下:
en-US:美式英语fr-FR:法语it-IT:意大利语de-DE:德语es-ES:西班牙语pt-BR:葡萄牙语zh-Hans:简体中文zh-Hant:繁体中文yue-Hans:粤语简体yue-Hant:粤语繁体ko-KR:韩语ja-JP:日语ru-RU:俄语uk-UA:乌克兰语
复制代码
2 - 动物识别
虽说是动物识别,但其实目前的 API 仅仅支持猫和狗的识别。使用 VNRecognizeAnimalsRequest 类来创建动物识别请求:
open class VNRecognizeAnimalsRequest : VNImageBasedRequest { // 获取所支持识别的动物种类 open class func knownAnimalIdentifiers(forRevision requestRevision: Int) throws -> [VNAnimalIdentifier] open func supportedIdentifiers() throws -> [VNAnimalIdentifier] // 结果列表 open var results: [VNRecognizedObjectObservation]? { get }}
复制代码
识别的结果 VNRecognizedObjectObservation 类也是继承自 VNDetectedObjectObservation,其会包装所识别的动物所在图片中的区域,且 VNRecognizedObjectObservation 类中会封装一组 VNClassificationObservation 对象,如下:
open class VNRecognizedObjectObservation : VNDetectedObjectObservation { // 识别的动物标签 open var labels: [VNClassificationObservation] { get }}
复制代码
VNClassificationObservatio 类即表示识别出的物体具体的标签,定义如下:
open class VNClassificationObservation : VNObservation { // 标签字符串 open var identifier: String { get }}
复制代码
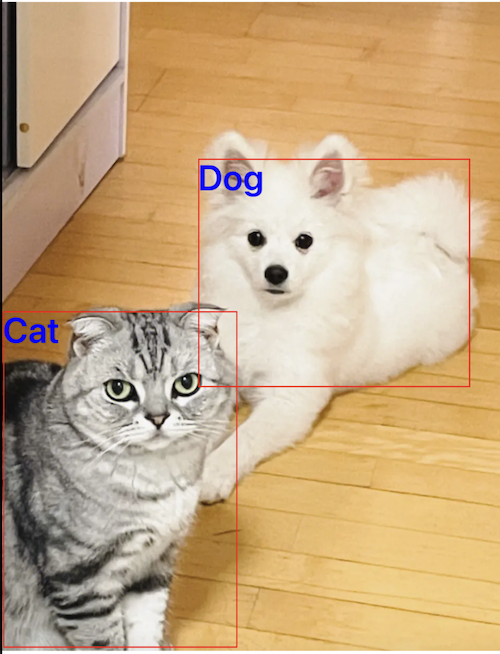
对于 VNRecognizeAnimalsRequest 请求来说,此标签的值可能为 Cat 或 Dog。识别效果如下图:
3 - 图片物体分类
图片物体分类是指对静态图片继续分析,将其中可能存在的物体分析出来。使用 VNClassifyImageRequest 创建图片物体分析请求。此类非常简单,没有太多需要配置的,定义如下:
open class VNClassifyImageRequest : VNImageBasedRequest { // 获取支持识别的物体 open class func knownClassifications(forRevision requestRevision: Int) throws -> [VNClassificationObservation] open func supportedIdentifiers() throws -> [String] // 结果数组 open var results: [VNClassificationObservation]? { get }}
复制代码
VNClassifyImageRequest 所支持识别的物体种类非常多,有千余种,这里就不再列举。其识别后的结果也是 VNClassificationObservation 类,其内部的 identifier 表示所识别出的物体的标签。
需要注意,对于略微复杂的图片来说,识别的结果可能非常多,我们需要根据需求来设置一个可信度的阈值,只有达到此可信度的才被采用,例如:
private func drawTask(request: VNClassifyImageRequest) { boxViews.forEach { v in v.removeFromSuperview() } for result in request.results ?? [] where result.confidence > 0.8 { // 解析出文本 textView.text = textView.text.appending(result.identifier + "\n") }}
复制代码
识别效果如下图所示:
可以看到,我们选择了大于 0.8 可信度的结果,所识别出的关键字有:建筑,加工木材,动物,哺乳动物,犬类,狗,博美。(不知为何对猫的识别度很差)
本中所涉及到的代码,都可以在如下 Demo 中找到:
https://github.com/ZYHshao/MachineLearnDemo
到此,我们已经将静态图片的分析做了详尽的介绍,相信很多 AI 能力都是开发中会使用到的。本系列后面文章,将介绍对象追踪的相关 API 的用法。













评论