前言
本篇博文是《从 0 到 1 学习 Netty》中入门系列的第七篇博文,主要内容是介绍 Netty 中 ByteBuf 的性能优化,包含不同的内存模式,池化技术,内存释放以及逻辑上的切片与合并,通过源码分析和应用案例进行详细讲解,往期系列文章请访问博主的 Netty 专栏,博文中的所有代码全部收集在博主的 GitHub 仓库中;
内存模式
在上一篇博文 ByteBuf 的基本使用 中,我们阅读了 ByteBuf 创建的源码,发现在默认情况下会创建 directBuffer(),也就是基于直接内存的 ByteBuf,同时,通过 buffer() 方法也可以创建 heapBuffer(),即基于堆内存的 ByteBuf:
ByteBufAllocator DEFAULT = ByteBufUtil.DEFAULT_ALLOCATOR;
@Override public ByteBuf buffer() { if (directByDefault) { return directBuffer(); } return heapBuffer(); }
复制代码
那基于直接内存的 ByteBuf 与 基于堆内存的 ByteBuf 有什么区别呢?
两者最大的区别在于内存分配和释放的方式不同。
堆内存的分配和释放都是由 Java 虚拟机自动管理的,这意味着它们可以快速地被分配和释放,但是也会产生一些开销。
直接内存需要手动分配和释放,因为它由操作系统管理,这使得分配和释放的速度更快,但是也需要更多的系统资源。
另外,直接内存可以映射到本地文件中,这对于需要频繁读写文件的应用程序非常有用。
此外,直接内存还可以避免在使用 NIO 进行网络传输时发生数据拷贝的情况。在使用传统的 I/O 时,数据必须先从文件或网络中读取到堆内存中,然后再从堆内存中复制到直接缓冲区中,最后再通过 SocketChannel 发送到网络中。而使用直接缓冲区时,数据可以直接从文件或网络中读取到直接缓冲区中,并且可以直接从直接缓冲区中发送到网络中,避免了不必要的数据拷贝和内存分配。
通过 ByteBufAllocator.DEFAULT.directBuffer() 方法来创建基于直接内存的 ByteBuf:
ByteBuf directBuf = ByteBufAllocator.DEFAULT.directBuffer(16);
复制代码
通过 ByteBufAllocator.DEFAULT.heapBuffer() 方法来创建基于堆内存的 ByteBuf:
ByteBuf heapBuf = ByteBufAllocator.DEFAULT.heapBuffer(16);
复制代码
注意:
直接内存是一种特殊的内存分配方式,可以通过在堆外申请内存来避免 JVM 堆内存的限制,从而提高读写性能和降低 GC 压力。但是,直接内存的创建和销毁代价昂贵,因此需要慎重使用。
此外,由于直接内存不受 JVM 垃圾回收的管理,我们需要主动释放这部分内存,否则会造成内存泄漏。通常情况下,可以使用 ByteBuffer.clear() 方法来释放直接内存中的数据,或者使用 ByteBuffer.cleaner() 方法来手动释放直接内存空间。
测试代码:
public static void testCreateByteBuf() { ByteBuf buf = ByteBufAllocator.DEFAULT.buffer(16); System.out.println(buf.getClass());
ByteBuf heapBuf = ByteBufAllocator.DEFAULT.heapBuffer(16); System.out.println(heapBuf.getClass());
ByteBuf directBuf = ByteBufAllocator.DEFAULT.directBuffer(16); System.out.println(directBuf.getClass()); }
复制代码
运行结果:
class io.netty.buffer.PooledUnsafeDirectByteBufclass io.netty.buffer.PooledUnsafeHeapByteBufclass io.netty.buffer.PooledUnsafeDirectByteBuf
复制代码
池化技术
在 Netty 中,池化技术指的是通过对象池来重用已经创建的对象,从而避免了频繁地创建和销毁对象,这种技术可以提高系统的性能和可伸缩性。
通过设置 VM options,来决定池化功能是否开启:
-Dio.netty.allocator.type={unpooled|pooled}
复制代码
在 Netty 4.1 版本以后,非 Android 平台默认启用池化实现,Android 平台启用非池化实现;
这里我们使用非池化功能进行测试,依旧使用的是上面的测试代码 testCreateByteBuf(),运行结果如下所示:
class io.netty.buffer.UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeDirectByteBufclass io.netty.buffer.UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeHeapByteBufclass io.netty.buffer.UnpooledByteBufAllocator$InstrumentedUnpooledUnsafeDirectByteBuf
复制代码
可以看到,ByteBuf 类由 PooledUnsafeDirectByteBuf 变成了 UnpooledUnsafeDirectByteBuf;
在没有池化的情况下,每次使用都需要创建新的 ByteBuf 实例,这个操作会涉及到内存的分配和初始化,如果是直接内存则代价更为昂贵,而且频繁的内存分配也可能导致内存碎片问题,增加 GC 压力。
使用池化技术可以避免频繁内存分配带来的开销,并且重用池中的 ByteBuf 实例,减少了内存占用和内存碎片问题。另外,池化技术还可以采用类似 jemalloc 的内存分配算法,进一步提升分配效率。
在高并发环境下,池化技术的优点更加明显,因为内存的分配和释放都是比较耗时的操作,频繁的内存分配和释放会导致系统性能下降,甚至可能出现内存溢出的风险。使用池化技术可以将内存分配和释放的操作集中到预先分配的池中,从而有效地降低系统的内存开销和风险。
内存释放
当在 Netty 中使用 ByteBuf 来处理数据时,需要特别注意内存回收问题。
Netty 提供了不同类型的 ByteBuf 实现,包括堆内存(JVM 内存)实现 UnpooledHeapByteBuf 和堆外内存(直接内存)实现 UnpooledDirectByteBuf,以及池化技术实现的 PooledByteBuf 及其子类。
UnpooledHeapByteBuf:通过 Java 的垃圾回收机制来自动回收内存;
UnpooledDirectByteBuf:由于 JVM 的垃圾回收机制无法管理这些内存,因此需要手动调用 release() 方法来释放内存;
PooledByteBuf:使用了池化机制,需要更复杂的规则来回收内存;
由于池化技术的特殊性质,释放 PooledByteBuf 对象所使用的内存并不是立即被回收的,而是被放入一个内存池中,待下次分配内存时再次使用。因此,释放 PooledByteBuf 对象的内存可能会延迟到后续的某个时间点。为了避免内存泄漏和占用过多内存,我们需要根据实际情况来设置池化技术的相关参数,以便及时回收内存;
Netty 采用了引用计数法来控制 ByteBuf 对象的内存回收,在博文 「源码解析」(二)ByteBuf 的引用计数机制 中将会通过解读源码的形式对 ByteBuf 的引用计数法进行深入理解;
每个 ByteBuf 对象被创建时,都会初始化为 1,表示该对象的初始计数为 1。
在使用 ByteBuf 对象过程中,如果当前 handler 已经使用完该对象,需要通过调用 release() 方法将计数减 1,当计数为 0 时,底层内存会被回收,该对象也就被销毁了。此时即使 ByteBuf 对象还在,其各个方法均无法正常使用。
但是,如果当前 handler 还需要继续使用该对象,可以通过调用 retain() 方法将计数加 1,这样即使其他 handler 已经调用了 release() 方法,该对象的内存仍然不会被回收。这种机制可以有效地避免了内存泄漏和意外访问已经释放的内存的情况。
一般来说,应该尽可能地保证 retain() 和 release() 方法成对出现,以确保计数正确。
使用 release() 方法将 ByteBuf 的计数减为 0 时,再次调用 ByteBuf,测试代码:
public static void testRelease() { ByteBuf buf = ByteBufAllocator.DEFAULT.heapBuffer(16); System.out.println("ByteBuf 的引用计数为 " + buf.refCnt()); buf.writeBytes("sidiot.".getBytes()); log(buf); buf.release(); log(buf); }
复制代码
运行结果:
ByteBuf 的引用计数为 1
read index:0 write index:7 capacity:16 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 73 69 64 69 6f 74 2e |sidiot. |+--------+-------------------------------------------------+----------------+
Exception in thread "main" io.netty.util.IllegalReferenceCountException: refCnt: 0 at io.netty.buffer.AbstractByteBuf.ensureAccessible(AbstractByteBuf.java:1464) at io.netty.buffer.AbstractByteBuf.checkIndex(AbstractByteBuf.java:1388) at io.netty.buffer.AbstractByteBuf.checkIndex(AbstractByteBuf.java:1384) at io.netty.buffer.AbstractByteBuf.getByte(AbstractByteBuf.java:361) at io.netty.buffer.AbstractByteBuf.getUnsignedByte(AbstractByteBuf.java:374) at io.netty.buffer.ByteBufUtil$HexUtil.appendPrettyHexDump(ByteBufUtil.java:1143) at io.netty.buffer.ByteBufUtil$HexUtil.access$300(ByteBufUtil.java:982) at io.netty.buffer.ByteBufUtil.appendPrettyHexDump(ByteBufUtil.java:978) at io.netty.buffer.ByteBufUtil.appendPrettyHexDump(ByteBufUtil.java:969) at com.sidiot.netty.c4.TestByteBuf.log(TestByteBuf.java:93) at com.sidiot.netty.c4.TestByteBuf1.testRefCount(TestByteBuf1.java:49) at com.sidiot.netty.c4.TestByteBuf1.main(TestByteBuf1.java:10)
复制代码
使用 retain() 方法将 ByteBuf 的计数加为 3 时,再次调用 ByteBuf,测试代码:
public static void testRetain() { ByteBuf buf = ByteBufAllocator.DEFAULT.heapBuffer(16); System.out.println("ByteBuf 的引用计数为 " + buf.refCnt()); buf.writeBytes("sidiot.".getBytes()); log(buf); buf.retain(); buf.retain(); System.out.println("ByteBuf 的引用计数为 " + buf.refCnt()); log(buf); }
复制代码
运行结果:
ByteBuf 的引用计数为 1
read index:0 write index:7 capacity:16 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 73 69 64 69 6f 74 2e |sidiot. |+--------+-------------------------------------------------+----------------+
ByteBuf 的引用计数为 3
read index:0 write index:7 capacity:16 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 73 69 64 69 6f 74 2e |sidiot. |+--------+-------------------------------------------------+----------------+
复制代码
在博文 Pipeline 与 ChannelHandler 中,ByeBuf 实例通过 Pipeline 传递给下一个 ChannelHandler,这时,我们要确保 ByeBuf 实例的计数大于 0,否则将不能被下一个 ChannelHandler 所使用,除非 ByeBuf 实例完成了它的使命,不需要再往下传递,此时,通过 release() 进行内存释放;
因此,ByeBuf 有一个基本的内存释放规则,谁最后使用,谁来释放内存;
将 ByteBuf 通过 ctx.fireChannelRead(msg) 方法传递给下一个 ChannelHandler,无需 release();
将 ByteBuf 转换为其他类型对象,ByteBuf 使命结束,必须 release();
不将 ByteBuf 继续向后传递,必须 release();
捕获各种异常,如果 ByteBuf 在传递过程中抛出异常,必须 release();
消息传至 Head 或者 Tail 后,消息会被其中的方法彻底释放;
public static boolean release(Object msg) { return msg instanceof ReferenceCounted ? ((ReferenceCounted)msg).release() : false; }
复制代码
逻辑切片与合并
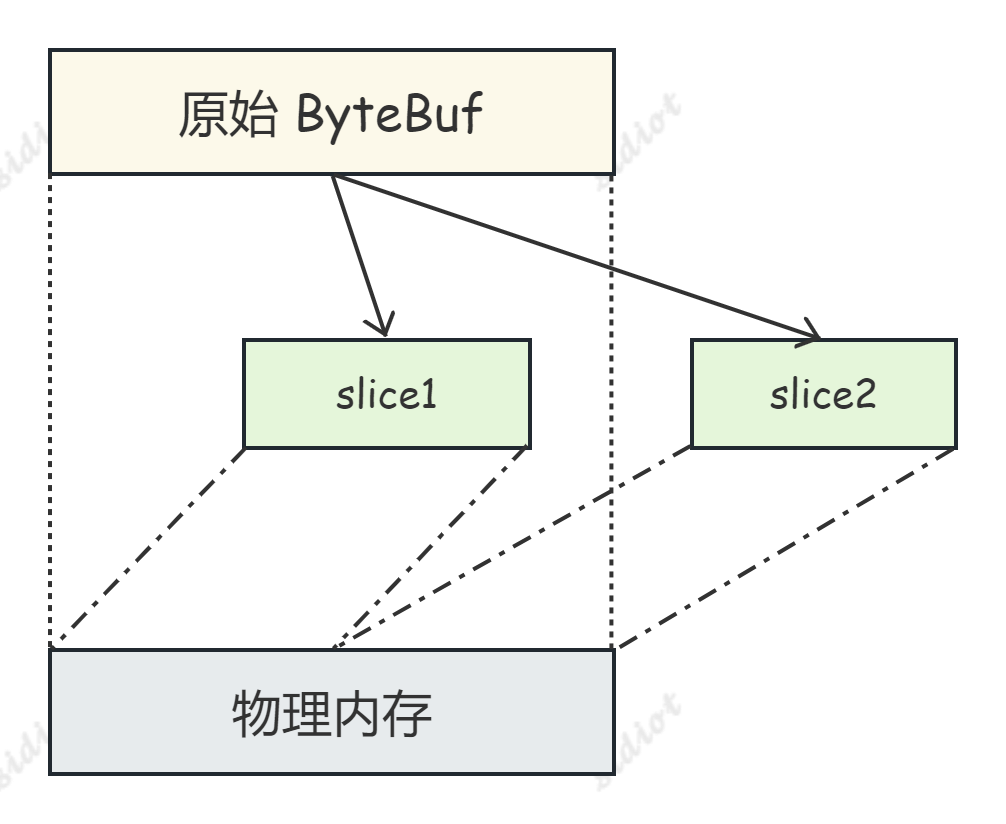
ByteBuf 切片 Slice 与 CompositeByteBuf 合并 addComponents 都是是零拷贝的表现;
ByteBuf 切片本质上就是对原始 ByteBuf 进行分段,每一段都是一个独立的 ByteBuf 对象,但是它们共享同一块内存空间,并且维护着各自的 read 和 write 指针。
由于通过切片得到的 ByteBuf 对象共享同一块内存空间,因此在进行数据读写操作时不需要进行数据拷贝或者内存复制,这样可以避免不必要的性能开销和内存占用。
值得注意的是,当我们得到分片后的 ByteBuf 对象时,需要手动调用其 retain() 方法使其内部的引用计数加一,以保证原始 ByteBuf 在使用过程中不被释放导致切片后的 ByteBuf 无法使用。在使用完毕之后,还需要手动调用 release() 方法来释放资源,以防止内存泄漏的发生。
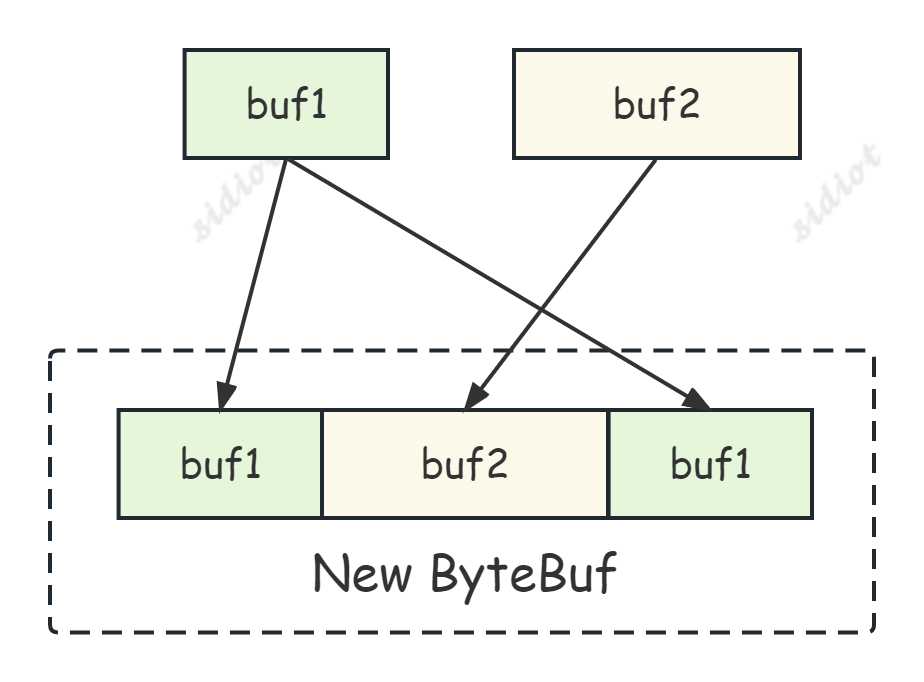
CompositeByteBuf 可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf。而 addComponents 方法就是用来向 CompositeByteBuf 中添加多个 ByteBuf 的。
具体来说,addComponents 方法接受一个参数 components,这个参数是一个 ByteBuf 数组,表示要添加的 ByteBuf 集合。调用 addComponents 方法后,会将传入的 ByteBuf 数组中的所有 ByteBuf 都添加到 CompositeByteBuf 中,然后返回值是一个 CompositeByteBuf 对象,它包含了所有添加的 ByteBuf。
需要注意的是,添加的 ByteBuf 必须已经被分配和写入了数据,否则在访问 CompositeByteBuf 时可能会出现异常。此外,在使用完 CompositeByteBuf 后,需要及时释放它所持有的所有 ByteBuf,以避免内存泄漏。
测试代码:
public static void testZeroCopy() { ByteBuf buf = ByteBufAllocator.DEFAULT.heapBuffer(16); buf.writeBytes("sidiot.".getBytes()); log(buf);
System.out.println("\n<===== 测试 slice 方法 ======>\n"); ByteBuf s1 = buf.slice(0, 1); ByteBuf s2 = buf.slice(1, 5); s1.retain(); System.out.println("=====> s1 <======"); log(s1); s2.retain(); System.out.println("\n=====> s2 <======"); log(s2);
System.out.println("\n<===== 修改原始 ByteBuf 中的值 ======>\n"); buf.setBytes(3, new byte[]{'1' , '0'}); System.out.println("=====> buf <======"); log(buf); System.out.println("\n=====> s2 <======"); log(s2);
System.out.println("\n<===== 测试 CompositeByteBuf 类 ======>\n"); CompositeByteBuf cBuf = ByteBufAllocator.DEFAULT.compositeBuffer(); cBuf.addComponents(true, s1, s2, s1); System.out.println("=====> cBuf <======"); log(cBuf); }
复制代码
运行结果:
read index:0 write index:7 capacity:16 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 73 69 64 69 6f 74 2e |sidiot. |+--------+-------------------------------------------------+----------------+
<===== 测试 slice 方法 ======>
=====> s1 <======read index:0 write index:1 capacity:1 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 73 |s |+--------+-------------------------------------------------+----------------+
=====> s2 <======read index:0 write index:5 capacity:5 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 69 64 69 6f 74 |idiot |+--------+-------------------------------------------------+----------------+
<===== 修改原始 ByteBuf 中的值 ======>
=====> buf <======read index:0 write index:7 capacity:16 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 73 69 64 31 30 74 2e |sid10t. |+--------+-------------------------------------------------+----------------+
=====> s2 <======read index:0 write index:5 capacity:5 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 69 64 31 30 74 |id10t |+--------+-------------------------------------------------+----------------+
<===== 测试 CompositeByteBuf 类 ======>
=====> cBuf <======read index:0 write index:1 capacity:1 +-------------------------------------------------+ | 0 1 2 3 4 5 6 7 8 9 a b c d e f |+--------+-------------------------------------------------+----------------+|00000000| 73 |s |+--------+-------------------------------------------------+----------------+
复制代码
需要注意的是,addComponents() 方法是不会主动去调整写入 buf 的指针位置的,因此如果第一个参数不填写 true 的话,结果会是如下所示:
=====> cBuf <======read index:0 write index:0 capacity:7
复制代码
另外还需要注意的地方就是,如果我们释放 cBuf,那么他会把逻辑上合并的 buf 全部释放一遍,我们结合代码进行理解,在刚刚的测试代码末尾加上如下代码:
System.out.println("buf 的引用计数为 " + buf.refCnt()); System.out.println("cBuf 的引用计数为 " + cBuf.refCnt()); cBuf.release(); System.out.println("cBuf 的引用计数为 " + cBuf.refCnt()); System.out.println("buf 的引用计数为 " + buf.refCnt());
复制代码
运行结果:
buf 的引用计数为 3cBuf 的引用计数为 1cBuf 的引用计数为 0buf 的引用计数为 0
复制代码
可以发现,不止 cBuf 计数为 0,buf 的计数也为 0;
如果还无法理解,我们继续测试,将 CompositeByteBuf 只用两个 buf 进行合并,即 cBuf.addComponents(true, s1, s2);,运行结果如下:
buf 的引用计数为 3cBuf 的引用计数为 1cBuf 的引用计数为 0buf 的引用计数为 1
复制代码
正如我们所预测的那样,buf 的计数为 1,因此,在释放 cBuf 时需谨慎!
后记
以上就是 ByteBuf 的性能优化 的所有内容了,希望本篇博文对大家有所帮助!
参考:











评论