
架构与思维:漫谈高并发业务的 CAS 及 ABA
1 高并发场景下的难题
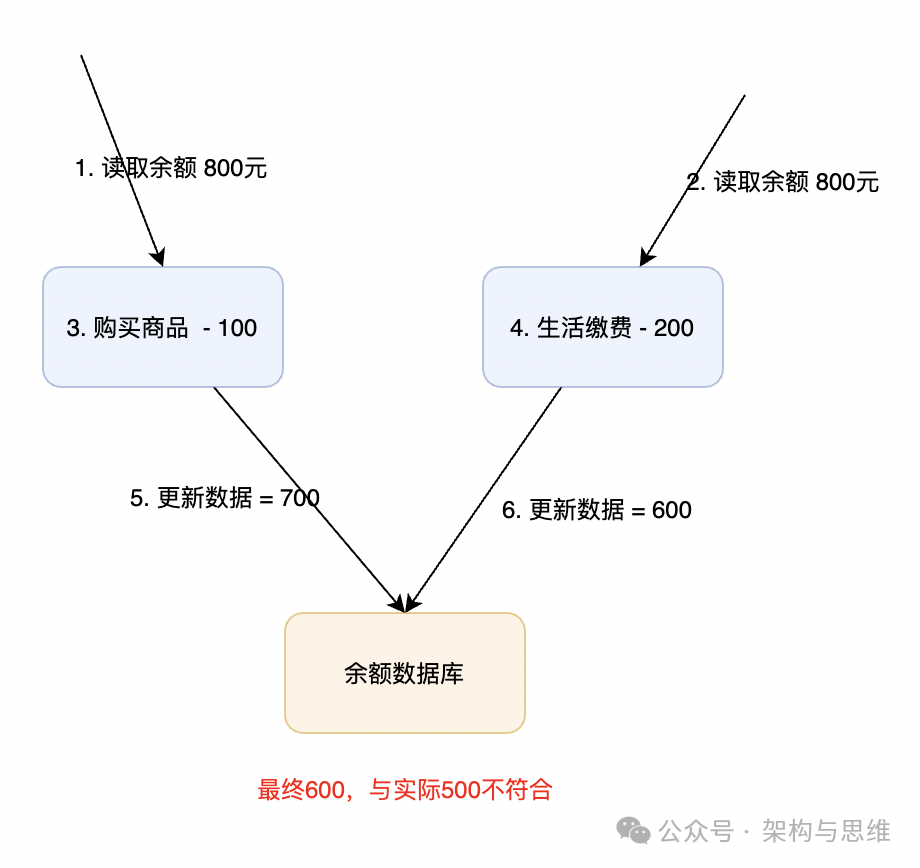
1.1 典型支付场景
这是最经典的场景。支付过程,要先查询买家的账户余额,然后计算商品价格,最后对买家进行进行扣款,像这类的分布式操作,如果是并发量低的情况下完全没有问题的,但如果是并发扣款,那可能就有一致性问题。在高并发的分布式业务场景中,类似这种 “查询+修改” 的操作很可能导致数据的不一致性。
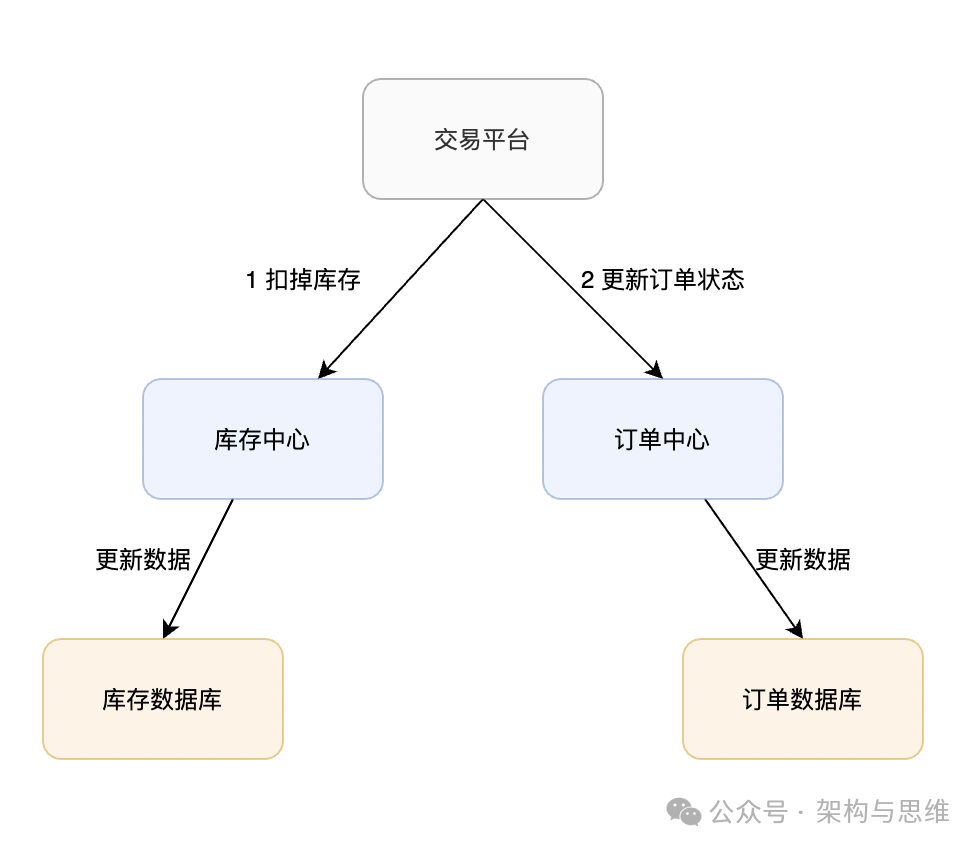
1.2 在线下单场景
同理,买家在电商平台下单,往往会涉及到两个动作,一个是扣库存,第二个是更新订单状态,库存和订单一般属于不同的数据库,需要使用分布式事务保证数据一致性。
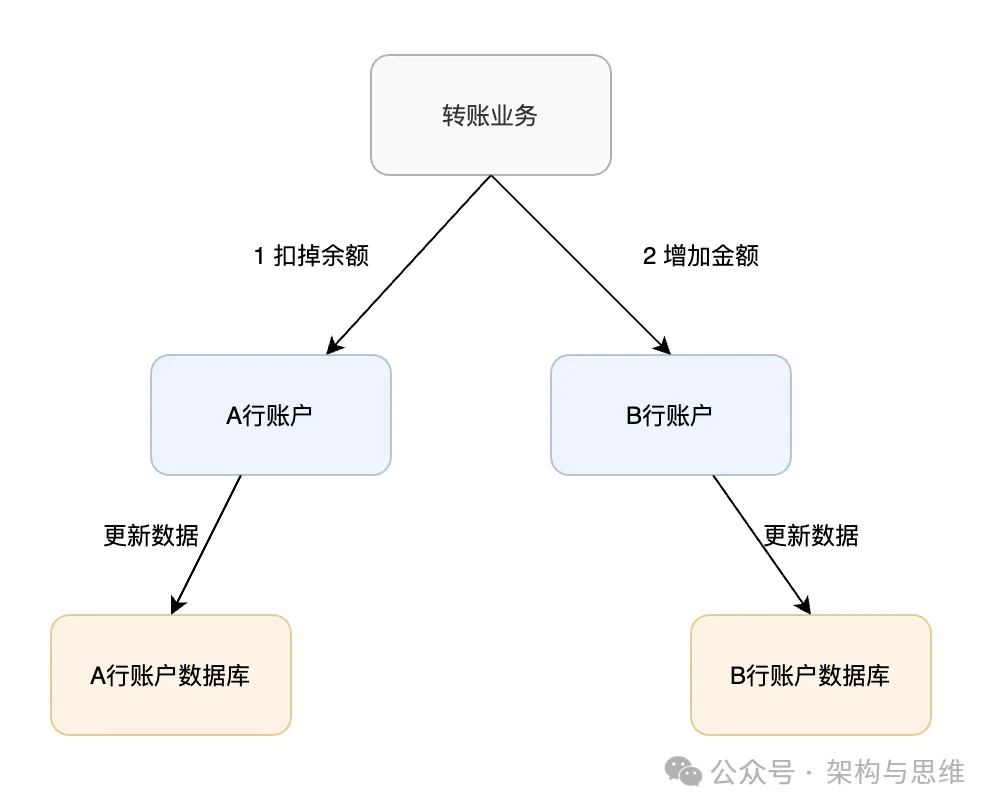
1.3 跨行转账场景
跨行转账问题也是一个典型的分布式事务,用户 A 同学向 B 同学的账户转账 500,要先进行 A 同学的账户-500,然后 B 同学的账户+500,既然是 不同的银行,涉及不同的业务平台,为了保证这两个操作步骤的一致,数据一致性方案必然要被引入。
2 CAS 方案
分布式 CAS(Compare-and-Swap)模式就是一种无锁化思想的应用,它通过无锁算法实现线程间对共享资源的无冲突访问,既保证性能高效,有保证数据的强一致性,避免了上面集中问题的产生。CAS 模式包含三个基本操作数:内存地址 V、旧的预期值 A 和要修改的新值 B。在更新一个变量的时候,只有当变量的预期值 A 和内存地址 V 当中的实际值相同时,才会将内存地址 V 对应的值修改为 B。
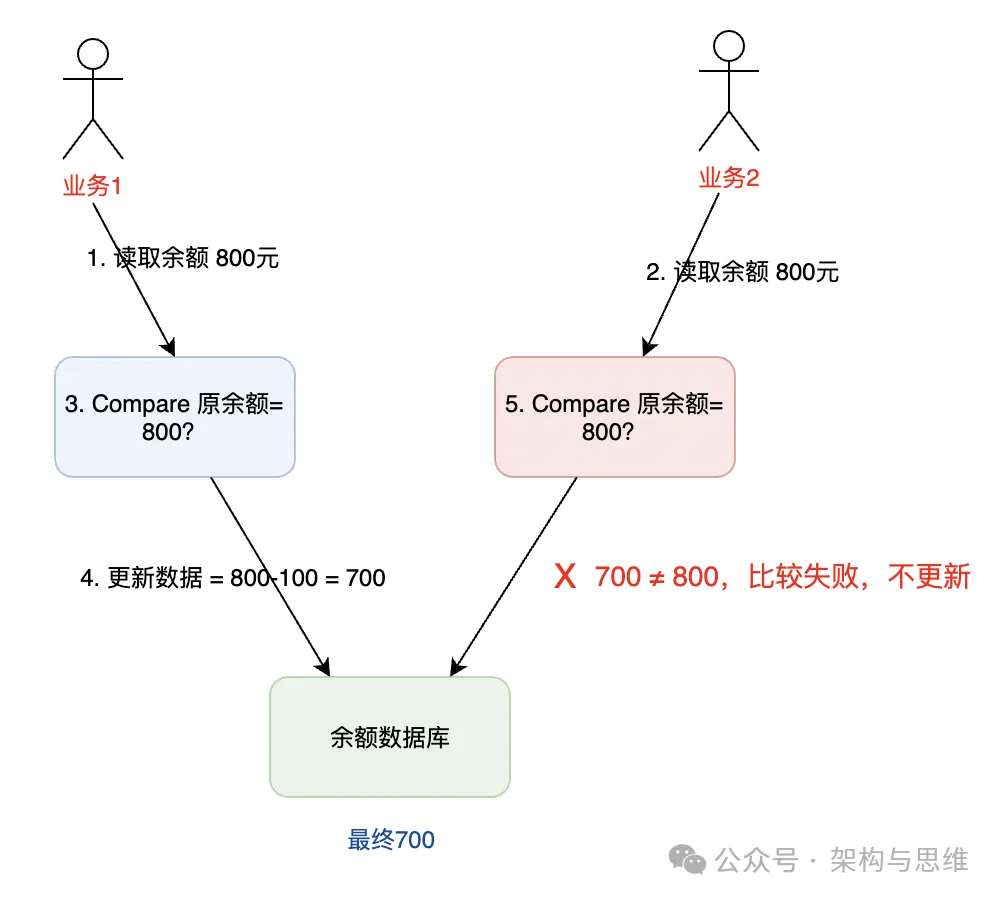
我们以 1.1 节 的 典型支付场景 作为例子分析(参考下图):
初始余额为 800
业务 1 和业务 2 同时查询余额为 800
业务 1 执行购买操作,扣减去 100,结果是 700,这是新的余额。理论上只有在原余额为 800 时,扣减的 Action 才能执行成功。
业务 2 执行生活缴费操作(比如自动交电费),原余额 800,扣减去 200,结果是 600,这是新的余额。理论上只有在原余额为 800 时,扣减的 Action 才能执行成功。可实际上,这个时候数据库中的金额已经变为 600 了,所以业务 2 的并发扣减不应该成功。
根据上面的 CAS 原理,在 Swap 更新余额的时候,加上 Compare 条件,跟初始读取的余额比较,只有初始余额不变时,才允许 Swap 成功,这是一种常见的降低读写锁冲突,保证数据一致性的方法。
3 引出 ABA 问题
在 CAS(Compare-and-Swap)操作中,ABA 问题是一个常见的挑战。这边假设三个操作数——内存位置(V)、预期原值(A)和新值(B)。ABA 问题是指当某个线程读取一个共享变量 V 的值为 A,之后准备将其更新为 B 时,另一个线程可能已经将其从 A 改为了 B,然后又改回了 A。此时,当前线程仍认为 V 的值是原始的 A,因此 CAS 操作会将 V 的值更新为 B,但实际上 V 的值已经被其他线程改变过。
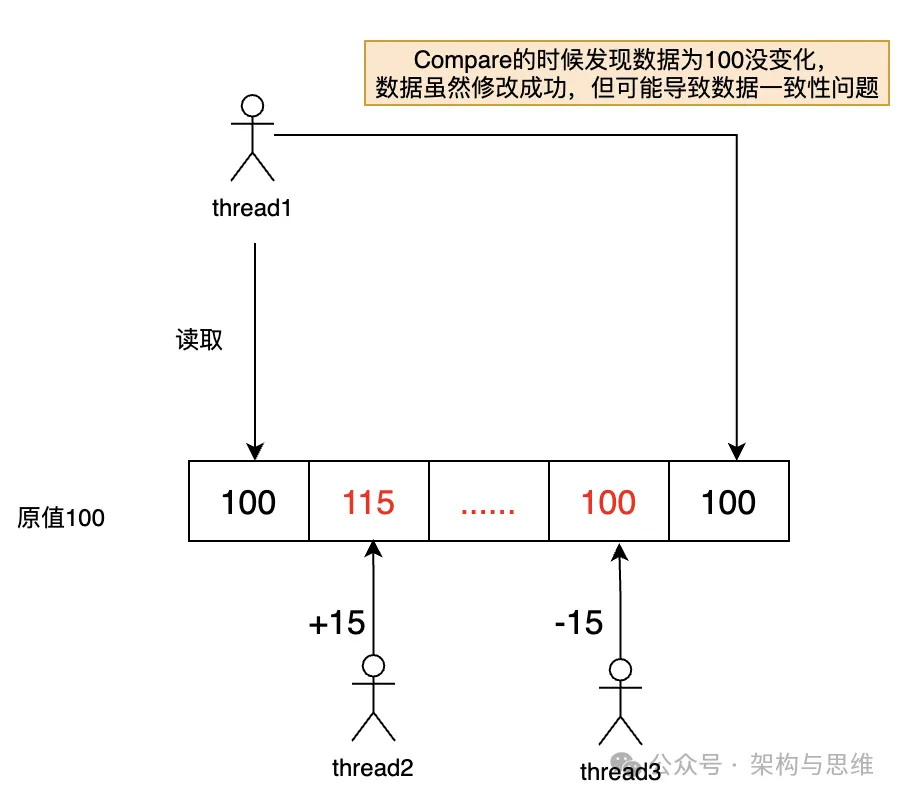
它有如下危害:
1. 数据一致性受损,并导致业务逻辑错误在复杂的业务逻辑中,共享变量的值往往代表了某种业务状态或条件。ABA 问题可能导致这些状态或条件被意外地改变,从而引发业务逻辑错误,如库存超卖、资金重复发放等。★ 以下的图详细描述了 ABA 是怎么导致库存逻辑出错的:
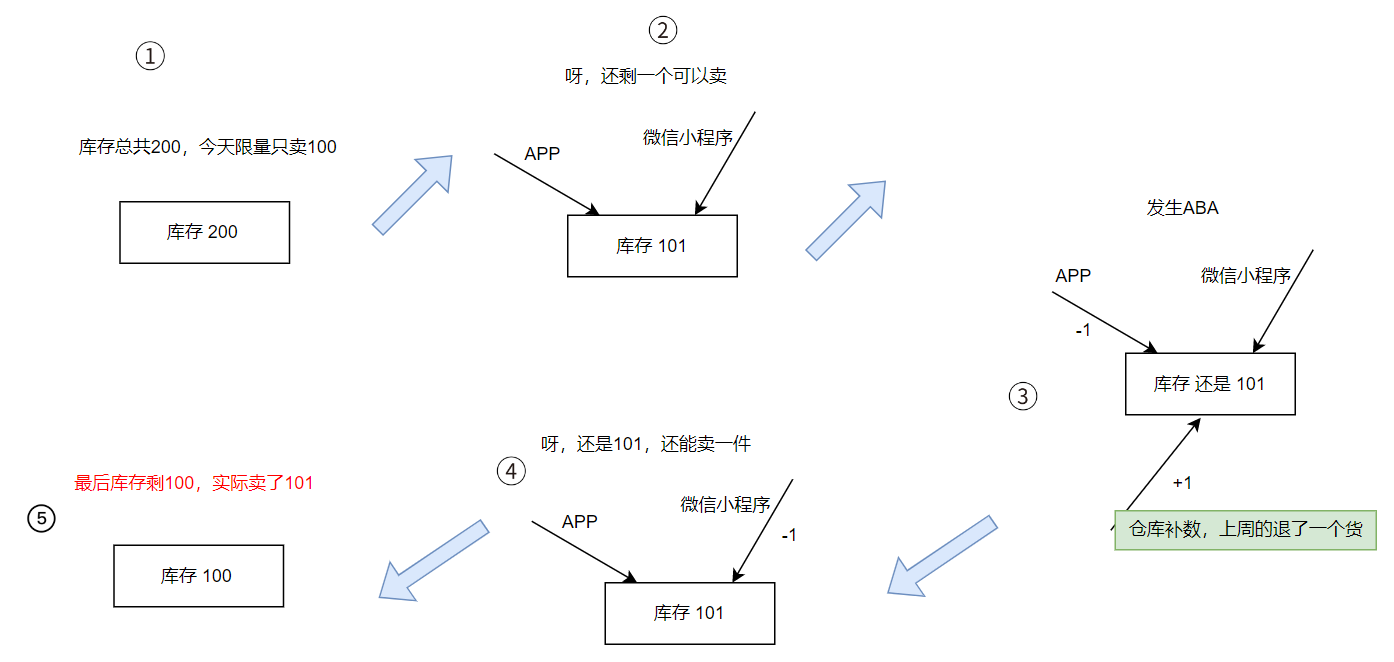
2. 难以调试与定位 ABA 问题通常发生在多线程环境下,且其触发条件较为隐蔽。因此,当系统出现由 ABA 问题导致的异常时,往往难以快速定位问题原因,增加了调试的复杂性和时间成本。
4 不同维度的处理方式
ABA 出现的原因,是 CAS 的过程中,只关注 Value 值的校验。但是忽略了这个值还是不是之前的那个值,可以参考上面的库存图例。所以某些情况下,Value 虽然相同,却已经不是原来的数据了。
解决方案:CAS 不能只比对 Value,还必须确保的是原来的数据,才能修改成功。一般的做法是,给 Value 设置一个 Version(版本号),用来比对,一个数据一个版本,每次数据变化的时候版本跟随变化,这样的话就不会随随便便修改成功。
4.1 应用程序层
Java 中的 java.util.concurrent.atomic 包提供了解决 ABA 问题的工具类。在 Go 语言中,通常使用 sync/atomic 包提供的原子操作来处理并发问题,并引入版本号或时间戳的概念。示例代码如下:
4.2 数据层
1、CAS 策略
2、CAS 策略+Version,避免 ABA 问题
5 总结
高并发下的难题:支付、下单、跨行转账
CAS 方案以及引发的 ABA 问题
不同维度的处理方式:应用层、数据层
文章转载自:Hello-Brand

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论