
火山引擎 DataLeap 构建 Data Catalog 系统的实践(三):关键技术与总结

更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
关键技术
构建一个好的 Data Catalog 系统,需要考虑的核心产品设计和技术设计有很多。篇幅所限,本文只概要介绍技术设计中最核心重要的部分,更多细节展开可参照后续的文章。
数据模型统一
将不同元数据的数据模型统一,是降低接入成本和维护成本的重要前提。系统的数据模型,火山引擎 DataLeap 研发人员基本参照了 Apache Atlas 的设计与实现。一些基本概念简单介绍如下:
类型(Type):描述一类元数据,由多个属性组成。例如,hive table 是一类元数据,hive_db 也是一类元数据。Type 可具备继承关系。按面向对象的编程思想,可以理解 type 为一个 Class。
实例(Entity):代表一个 type 的具体事例。一个 entity 可能作为一个属性存在于另一个 entity 中,例如 hive_table 中的 db 属性,db 本身也是一个 entity。在面向对象的编程思想中,一个 entity 可以认为是一个 class 的 instance。
属性(Attribute):属性的集合组合而成为一个 Type。属性本身的类型(typeName)可能是一个自定义的 type,也可能是一种基础类型,包括 date,string 等。例如,db 是 hive_table 的一个属性,column 也是 hive_table 的一个属性。
关系(Relationship):一种特殊的 Entity,用以描述两个 Entity 之间的关联模式。
在实际应用这套类型系统时,我们有两个方面比较有特点:
继承与组合的广泛使用
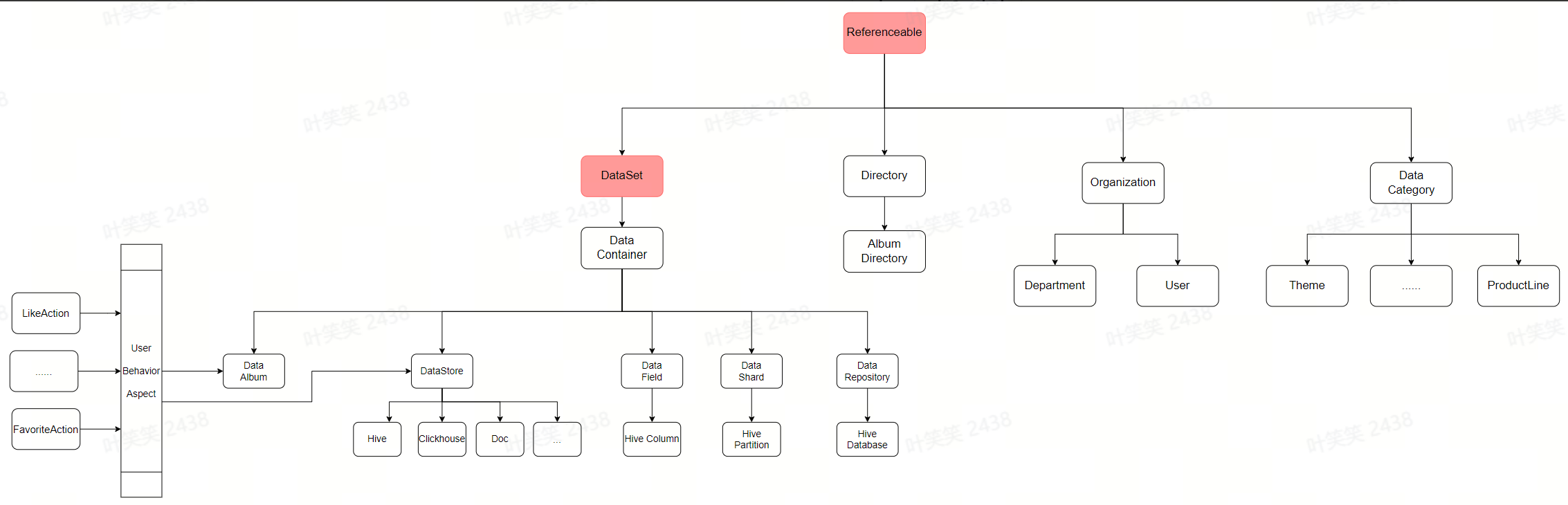
字节的业务场景十分复杂,为了充分复用各种元数据类型之间的相似能力,又获得足够的定制灵活性,火山引擎 DataLeap 研发人员为每类元数据设计了父 Type。比如,Hive Table 和 Clickhouse Table,都含有名称、描述、字段等属性,他们都继承自 DataStore 这个父 Type。
另外一种情况,有些类型的实体可以作用于多种其他的实体,比如一张 Hive 表和一堆被组织在一起的业务报表,都可以被用户收藏或点赞。我们将收藏、点赞这些行为也抽象为实体,并通过关系与 Hive 表、业务报表集合等相关联。这种思想,类似编程中的组合或者是切面的概念。
调整类型加载机制
在实践中我们意识到,跟某种数据源相关联的能力,应该尽可能收敛到一起,这可以极大的降低后续的维护成本。对于一种元数据类型定义,也在这种考虑的范围之内。火山引擎 DataLeap 研发人员调整了 Apache Atlas 加载类型文件的机制,使其可以从多个 package,以我们定义过的目录结构和先后顺序加载。这也为后面的标准化奠定了基础。
数据接入标准化
为了最终达成降低接入和维护成本的目标,统一了类型系统之后,第二步就是接入流程的标准化。
火山引擎 DataLeap 研发人员将某一种元数据类型的接入逻辑封装为一个 connector,并通过提供 SDK 的方式简化 connector 的编写成本。
以使用最广泛的 T+1 bridge 接入的 connector SDK 为例,我们参照时下流行的 Flink 流式处理框架,结合 T+1 bridge 的业务特点,实现了如下模型:

Source:从外部存储计算系统等批量拉取最新的全量元数据。数据结构和字段通常由外部系统决定。概念上可对齐 Flink 的 source operator。
Diff Operator:接收 source 的输出,并从 Catalog Service 拉取当前系统中的全量元数据,做差异对比,产出差异的部分。概念上对齐 Flink 中的某一种自定义的 ProcessFunction。
Event Generate Operator:接收 Diff Operator 的输出,根据 Catalog 系统定义好的格式,将差异的 metadata 转化成 event 格式,比如对于新建的 metadata,转换成 CreateEvent。概念上对齐 Flink 中的某一种自定义的 ProcessFunction。
Sink:接收 Event Generate Operator 的输出,将差异的 metadata 写入 Ingestion Service。概念上对齐 Flink 的 sink operator。
Bridge Job:组装 pipeline,做运行时控制。概念上对齐 Flink 的 Job。
当需要接入新的元数据时,通常只需要重新编写 Source 和 Diff Operator,其他组件都是可直接复用的。标准化的 connector 极大的节省接入和运维成本。
搜索优化
搜索是 Data Catalog 中,除了详情浏览外,最广泛使用的功能,也是数据消费者找数最主要的手段。在火山引擎 DataLeap 系统中,每天有 70%以上的用户都会使用搜索功能。
搜索是一个相对成熟的技术领域,针对元数据的检索可以看作是垂直领域的搜索引擎。本节概要介绍在设计实现元数据搜索引擎时的收获,更多的细节展开,会有后续的文章。
在实际场景中,火山引擎 DataLeap 研发人员发现公司内的元数据搜索,与通用搜索引擎相比,有两个十分显著的特点:
搜索中存在部分很强的 Pattern:用户搜索元数据时,有一些隐式的习惯,通过挖掘埋点中的固定 pattern,给了我们针对性优化的机会。
行为数据规模有限:公司内部的元数据搜索用户,通常是千级别,而每天搜索的点击次数是万级别,这个规模远远小于对外的通用搜索引擎,也造成很多模型没法及时收敛,但也一定程度上给与我们简化问题的机会。
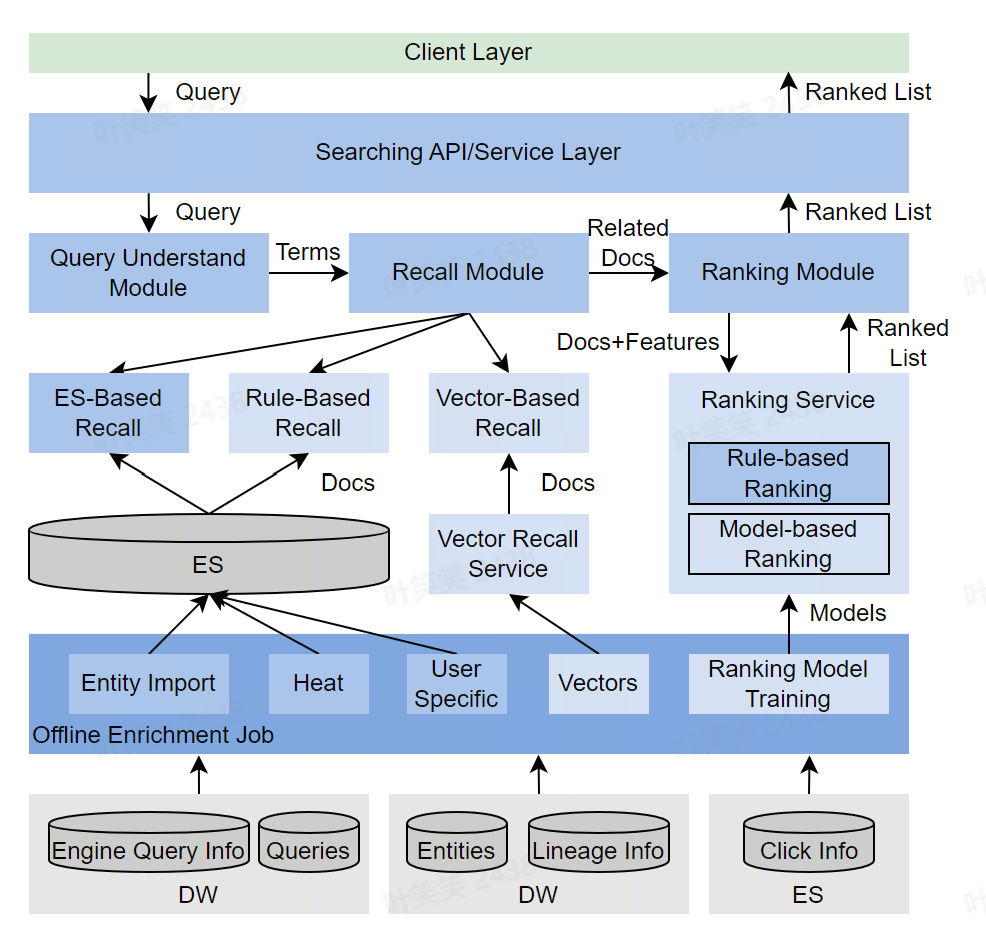
火山引擎 DataLeap 研发人员设计的元数据搜索,架构如上图所示。粗略来看,可以划分为两大部分:
离线部分:负责汇集各类与搜索相关的数据,做数据清洗或者模型训练,根据不同的用途,写入不同的存储,供给在线搜索模块使用。
在线部分:分为搜索理解、召回、精排三个主要阶段,步骤和概念上与通用搜索引擎对齐。
针对上面分析的特点,火山引擎 DataLeap 研发人员在搜索优化时,有两个对应的策略:
对于强 Pattern,广泛使用 Rule-Based 的优化手段:比如,火山引擎 DataLeap 研发人员发现很大一部分用户在搜索 Hive 时,会使用“库名.表名”的 pattern,在识别到 query 语句中有“.”时,火山引擎 DataLeap 研发人员会优先尝试根据库名和表名检索
激进的个性化:因用户规模可控,且某位用户通常会频繁使用某个领域的元数据,火山引擎 DataLeap 研发人员记录了很多用户的历史行为细节,当 query 语句与过去浏览过元数据有一定文本相关性时,个性化相关的得分会有较大提升
血缘能力
血缘能力是 Data Catalog 系统的另外一个核心能力。自动化的,端到端的血缘能力,是很多业界系统宣称的亮点功能。构建完备的血缘能力,既可以帮助生产者梳理、组织他们负责的元数据,也可以帮助数据消费者找数和理解数据的上下文。
字节非常关注数据价值,业务也复杂,对我们数据血缘链路的建设也提出了很高的要求。本节只概要介绍火山引擎 DataLeap 研发人员搭建血缘链路时考虑的核心问题,更多细节可以参照之前的文章:字节跳动内部的数据血缘用例与设计。
首先,数据血缘的系统边界是:从 RDS 和 MQ 开始,一路途径各种计算和存储,最终汇入指标、报表和数据服务系统。
其次,在设计系统时,火山引擎 DataLeap 研发人员充分考虑了血缘链路的多样性和复杂性。如下图所示,火山引擎 DataLeap 研发人员通过 T+1 和近实时的方式,获取各类任务系统中的信息,根据任务类型,调用不同的解析服务,将格式化过的血缘数据写入 Data Catalog 系统,供给下游的 API 调用或者 MQ、离线数仓消费。
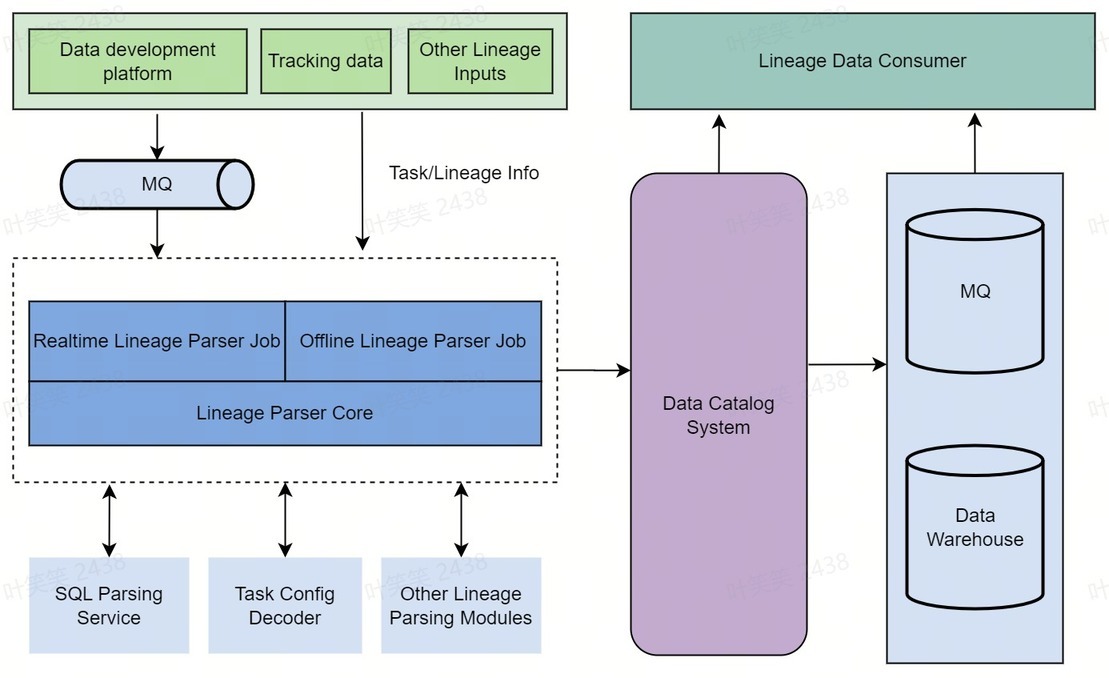
最后,在血缘质量衡量上,火山引擎 DataLeap 研发人员通过定义有效的血缘准确率、覆盖率和时效性,来确保血缘信息的准确、全面和实时性。
当前,我们的血缘能力已经广泛应用于字节的数据资产、数据开发和数据治理等领域。
存储层优化
如前面介绍,在存储层,火山引擎 DataLeap 研发人员借用了 Atlas 的设计与实现。Atlas 的底层使用 JanusGraph 做图引擎。JanusGraph 是基于 Gremlin 图查询语义实现的计算引擎,其底层存储支持 HBase/Cassadra/BerkeleyDB 等 KCV 结构的存储,同时,使用 ElasticSearch 作为索引查询支持。
当火山引擎 DataLeap 研发人员将越来越多的元数据接入系统,图存储中的点和边分别到达百万和千万量级,读写性能都遇到了比较大的问题。我们做了部分源码的修改,这边介绍其中比较重要的两个,更多细节请参照后续的文章。
读优化:开启 MutilPreFetch 能力
在我们的图库中,存在很多超级点,也就是关系十分庞大的元数据。举两种情况,一是列十分多的大宽表,对于一些机器学习的表,甚至会超过 1 万列;另外一种情况是被广泛引用的底表,比如埋点底表的一级血缘下游就超过了 1 万。在读取这类数据时,我们发现性能极差。
与关系型数据库慢查询优化类似,我们通过监控埋点收集到慢查询语句,借助 gremlin 的 profile 函数,分析 query plan 中的问题,并通过构建索引或者改写语句与配置等,做相应的优化。
开启 JanusGraph 的 MutilPreFetch 查询开关,是其中一种情况。该特性的大致实现原理是,在属性过滤的时候, 批量并行获取所有关联顶点的属性,再在内存做属性过滤,而未开启该特性时,则会找到对端的顶点后,每个顶点单独去获取属性再做过滤条件。

需要注意的是,该机制在触发优化时的前置条件
Janusgraph 0.4 版本以上且配置打开
语句中不包含 limit
语句中包含 has
查询结果行数不超过 cache.tx-cache-size 值
写优化:去除 Guid 全局唯一性检查
对于超大元数据的写入请求,也有比较严重的性能问题。比如超过 3000 列的写入,火山引擎 DataLeap 研发人员发现需要消耗接近 15 分钟。
通过模拟单个超大表写入,并使用 arthas 火焰图跟踪相关代码, 火山引擎 DataLeap 研发人员发现在每个 JanusGraph 图顶点写入时,都会做 guid 的全局唯一性校验,这里十分耗时。
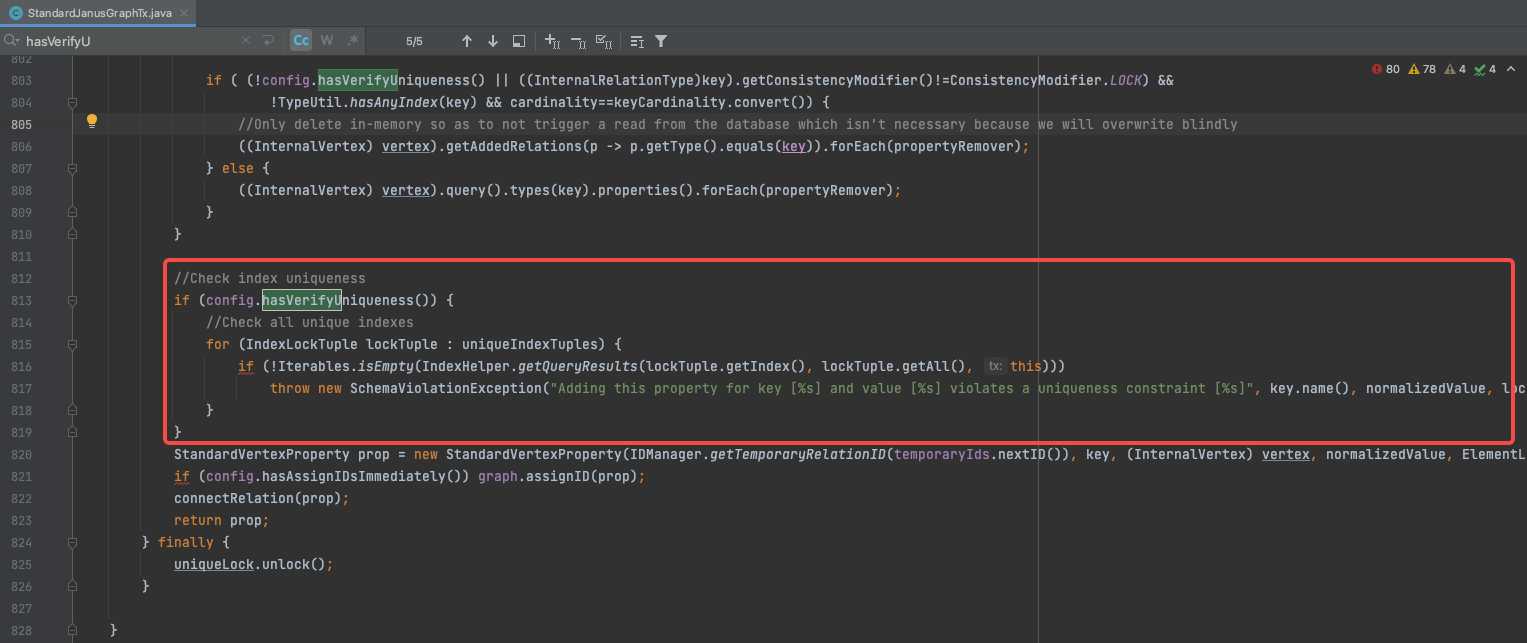
通过分析,火山引擎 DataLeap 研发人员发现 guid 在全局上默认是唯一的,没有必要做这个唯一性检查,同时,我们定义了业务语义上全局唯一的 qualifiedName,以此减少不必要的唯一性重复检查。
配合其他的优化,我们在一次写入大量节点时,节省不少开销,最终性能大致如下:

未来工作
文中阐述的部分 Data Catalog 技术和产品功能已经通过火山引擎大数据研发治理套件 DataLeap 对外开放。
接下来,火山引擎 DataLeap 研发人员提升 Data Catalog 系统,会主要集中在以下几个方面:
首先,是将元数据往数据资产转化。当前,我们收集了丰富的技术类元数据和一部分业务类元数据,如何将各类元数据,与真实的业务场景关联,将没有直接业务价值的元数据转化为有直接业务价值的数据资产,是我们正在探索的方向。
其次,是更广泛的应用智能能力。Data Catalog 中有很多可以落地的智能化场景,比如搜索推荐,自动打标等,我们已经做了一些基础的尝试,接下来会进行更广泛的推广。
最后,开放能力的搭建。在元数据接入方面,我们准备将其封装成产品能力,提供类似 connector 市场的功能,便于在 ToB 市场做更敏捷的合作与推广;另外计划与开源和商用的敏捷报表等做更好的打通,可以将系统能力展现在各类报表系统里。
点击跳转大数据研发治理套件 DataLeap了解更多

小助手微信号:Bytedance-data 2021-12-29 加入
字节跳动数据平台团队,赋能字节跳动各业务线,对内支持字节绝大多数业务线,对外发布了火山引擎品牌下的数据智能产品,服务行业企业客户。关注微信公众号:字节跳动数据平台(ID:byte-dataplatform)了解更多









评论