
Llama 3.2 使用指南:工作原理及示例

Meta AI 宣布发布 Llama 3.2,该版本引入了系列中的首批多模态模型。Llama 3.2 专注于两个关键领域:
启用视觉的大型语言模型(LLM):11B 和 90B 参数的多模态模型现在可以处理并理解文本和图像。
为边缘和移动设备设计的轻量级 LLM:1B 和 3B 参数模型旨在轻量化和高效,允许它们在边缘设备上本地运行。
在本文中,我将梳理要点,重点介绍新的 Llama 3.2 模型的关键方面,包括它们的工作原理、示例及如何使用。
Llama 3.2 11B 和 90B 视觉模型
Llama 3.2 的一个关键特性是引入了具有 110 亿和 900 亿参数的视觉模型。
这些模型为 Llama 生态系统带来了多模态能力,允许模型处理和理解文本和图像。
多模态能力
Llama 3.2 中的视觉模型在需要图像识别和语言处理的任务中表现出色。它们可以回答关于图像的问题,生成描述性标题,甚至可以对复杂的视觉数据进行推理。
根据 Meta 的示例,这些模型可以分析嵌入文档中的图表并总结关键趋势。它们还可以解释地图,确定远足径中最陡峭的部分,或者计算两个点之间的距离。
Llama 视觉模型的用例
文本和图像推理的集成提供了广泛的潜在应用,包括:
文档理解:这些模型可以从包含图像、图表和图表的文档中提取和总结信息。例如,企业可以使用 Llama 3.2 自动解释以视觉形式呈现的销售数据。
视觉问答:通过理解文本和图像,Llama 3.2 模型可以基于视觉内容回答问题,例如识别场景中的对象或总结图像内容。
图像字幕:模型可以为图像生成字幕,使其在数字媒体或辅助功能等领域有用,这些领域理解图像内容很重要。
开放和可定制
Llama 3.2 的视觉模型是开放和可定制的。开发者可以使用 Meta 的 Torchtune 框架对这些模型的预训练和对齐版本进行微调。
此外,这些模型可以通过 Torchchat 在本地部署,减少对云基础设施的依赖,为希望在本地或资源受限环境中部署 AI 系统的开发者提供解决方案。
视觉模型还可以通过 Meta AI 的智能助手进行测试。
Llama 3.2 视觉模型的工作原理
为了使 Llama 3.2 视觉模型能够理解文本和图像,Meta 使用特殊适配器将预训练的图像编码器集成到现有语言模型中。这些适配器将图像数据与模型的文本处理部分链接起来,允许它处理两种类型的输入。
训练过程从 Llama 3.1 语言模型开始。首先,团队对它进行了大量图像和文本描述的训练,以教模型如何将两者联系起来。然后,他们使用更干净、更具体的数据对其进行了优化,以提高其理解和推理视觉内容的能力。
在最后阶段,Meta 使用了微调和合成数据生成等技术,以确保模型提供有帮助的答案并安全地表现。
基准测试:优点和缺点
Llama 3.2 视觉模型在图表和图表理解方面表现出色。在 AI2 图表(92.3)和 DocVQA(90.1)等基准测试中,Llama 3.2 的性能超过了 Claude 3 Haiku。这使其成为涉及文档级理解、视觉问答和从图表中提取数据的任务的绝佳选择。
在多语言任务(MGSM)中,Llama 3.2 也表现良好,得分为 86.9,几乎与 GPT-4o-mini 的 86.9 分相匹配,这使其成为使用多种语言的开发者的可靠选择。
虽然 Llama 3.2 在基于视觉的任务中表现良好,但在其他领域面临挑战。在 MMMU-Pro Vision 中,它测试了对视觉数据的数学推理能力,GPT-4o-mini 以 36.5 分对 Llama 的 33.8 分取得了更好的性能。
同样,在 MATH 基准测试中,GPT-4o-mini 的性能(70.2)显著超过了 Llama 3.2(51.9),表明 Llama 在数学推理任务上仍有改进的空间。
Llama 3.2 1B 和 3B 轻量级模型
Llama 3.2 的另一个重要进步是引入了为边缘和移动设备设计的轻量级模型。这些模型具有 10 亿和 30 亿参数,旨在在较小的硬件上运行,同时在性能上保持合理的折衷。
设备上的 AI:实时和私密
这些模型旨在在移动设备上运行,提供快速的本地处理,无需将数据发送到云端。在边缘设备上本地运行模型提供了两个主要好处:
更快的响应时间:由于模型在设备上运行,它们可以几乎立即处理请求并生成响应。这对于速度至关重要的实时交互特别有用。
增强的隐私:通过本地处理,用户数据永远不需要离开设备。这使得敏感信息(如个人消息或日历事件)安全,并由用户控制,而不是被发送到云端。
Llama 3.2 的轻量级模型针对 Arm 处理器进行了优化,并已在 Qualcomm 和 MediaTek 硬件上启用,这些硬件如今为许多移动和边缘设备提供动力。
Llama 3.2 1B 和 3B 的应用
轻量级模型旨在用于各种实用的设备上应用,例如:
摘要:用户可以直接在设备上总结大量文本,如电子邮件或会议记录,而无需依赖云服务。
AI 个人助理:模型可以解释自然语言指令并执行任务,如创建待办事项列表或安排会议。
3. 文本重写:这些模型能够即时增强或修改文本,使其适用于自动编辑或改写工具等应用。
Llama 3.2 轻量级模型的工作原理
Llama 3.2 轻量级模型(1B 和 3B)旨在高效地适应移动和边缘设备,同时保持强大的性能。为了实现这一点,Meta 使用了两种关键技术:剪枝和蒸馏。
剪枝:使模型更小
剪枝有助于通过移除网络中不太关键的部分来减小原始 Llama 模型的大小,同时尽可能保留知识。在 Llama 3.2 的 1B 和 3B 模型中,这个过程是从较大的 Llama 3.1 8B 预训练模型开始的。
通过系统剪枝,Meta AI 团队能够创建出更小、更高效的模型版本,而不会显著损失性能。这在上面的图表中表示,8B 预训练模型(紫色框)被剪枝和提炼,成为较小的 Llama 3.2 1B/3B 模型的基础。
蒸馏:教较小的模型
蒸馏是将知识从较大的、更强大的模型(“老师”)转移到较小的模型(“学生”)的过程。在 Llama 3.2 中,使用了来自较大的 Llama 3.1 8B 和 Llama 3.1 70B 模型的 logits(预测)来教导较小的模型。
这样,尽管尺寸减小,但 1B 和 3B 模型仍然可以更有效地执行任务。上面的图表显示了这个过程如何使用来自较大模型的 logits 数据在预训练期间指导 1B 和 3B 模型。
最终优化
剪枝和蒸馏后,1B 和 3B 模型经历了与之前 Llama 模型相似的后训练。这涉及到如监督微调、拒绝采样和直接偏好优化等技术,以使模型的输出与用户期望保持一致。
还生成了合成数据,以确保模型能够处理广泛的任务,如摘要、重写和指令遵循。
如上图所示,最终的 Llama 3.2 1B/3B 指令模型是剪枝、蒸馏和广泛后训练的结果。
基准测试:优点和缺点
Llama 3.2 3B 在某些类别中表现出色,特别是在涉及推理的任务中。例如,在 ARC Challenge 中,它得分为 78.6,超过了 Gemma(76.7),并且略低于 Phi-3.5-mini(87.4)。同样,在 Hellawag 基准测试中,它得分为 69.8,击败了 Gemma,并与 Phi 保持竞争力。
在 BFCL V2 等工具使用任务中,Llama 3.2 3B 也表现出色,得分为 67.0,超过了两个竞争对手。这表明 3B 模型有效地处理指令遵循和与工具相关的任务。
Llama Stack 分发
为补充 Llama 3.2 的发布,Meta 正在引入 Llama Stack。对于开发者来说,使用 Llama Stack 意味着他们不需要担心设置或部署大型模型的复杂细节。他们可以专注于构建应用程序,并相信 Llama Stack 会处理大部分繁重的工作。
Llama Stack 的关键特性包括:
标准化 API:开发者可以使用它们与 Llama 模型交云,而无需从头开始构建一切。
到处工作:Llama Stack 设计用于跨不同平台工作:
单节点:在仅一台计算机上运行 Llama 模型。
本地:在您自己的服务器或私有云中使用模型。
云:通过云提供商(如 AWS 或 Google Cloud)部署 Llama 模型。
移动和边缘设备:使得在不依赖云的情况下在手机或小型设备上运行 Llama 模型成为可能。
预构建解决方案:Llama Stack 提供“即用型”解决方案,这些解决方案是用于文档分析或问答等常见任务的现成设置。这些可以为开发者节省时间和精力。
集成安全性:Stack 还包括内置的安全功能,确保 AI 在部署期间负责任地行为。
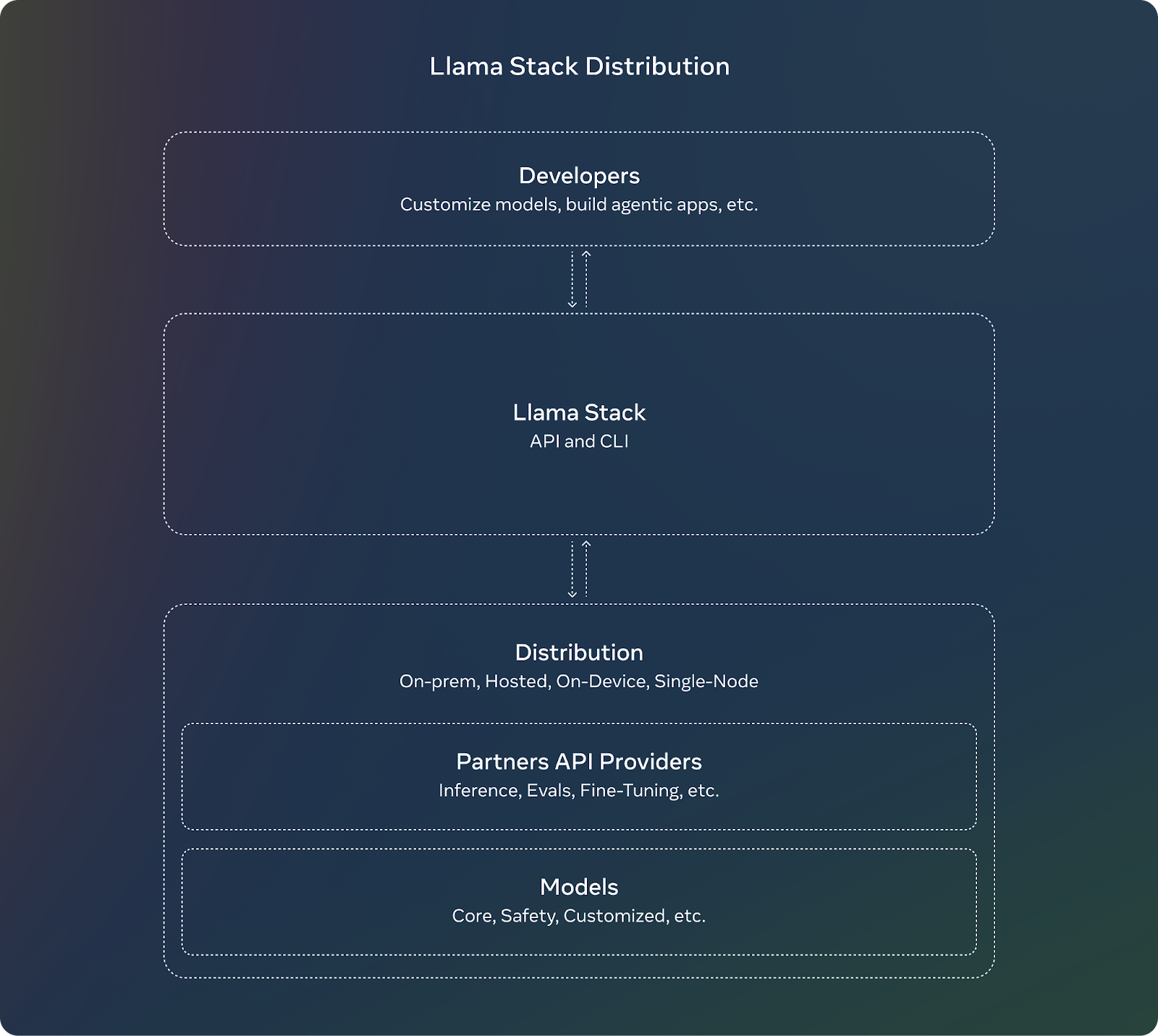
来源:Meta AI
Llama 3.2 安全性
Meta 继续专注于负责任的 AI,推出了 Llama 3.2。Llama Guard 3 已更新,包括支持 Llama 3.2 新的多模态能力的版本。这确保了使用新图像理解功能的应用程序保持安全并符合道德指导方针。
此外,Llama Guard 3 1B 已针对在资源更受限的环境中部署进行了优化,使其比之前的版本更小、更高效。
如何访问和下载 Llama 3.2 模型
访问和下载 Llama 3.2 模型非常简单。Meta 在多个平台上提供了这些模型,包括他们自己的网站和 Hugging Face,这是一个托管和共享 AI 模型的流行平台。
你可以直接从官方 Llama 网站下载 Llama 3.2 模型。Meta 提供了较小的轻量级模型(1B 和 3B)和较大的视觉模型(11B 和 90B),供开发者使用。
Hugging Face 是另一个提供 Llama 3.2 模型的平台。它提供便捷的访问方式,并通常被 AI 社区的开发者使用。
Llama 3.2 模型在我们的广泛合作伙伴平台上立即可用于开发,包括 AMD、AWS、Databricks、Dell、Google Cloud、Groq、IBM、Intel、Microsoft Azure、NVIDIA、Oracle Cloud、Snowflake 等。
结论
Meta 推出的 Llama 3.2 引入了系列中的首批多模态模型,专注于两个关键领域:启用视觉的模型和为边缘和移动设备设计的轻量级模型。
11B 和 90B 多模态模型现在可以处理文本和图像,而 1B 和 3B 模型针对在较小设备上的高效本地使用进行了优化。

AI应用开发实战营、程序员副业变现配置 2018-04-19 加入
慕课网《ChatGPT+AI项目实战,打造多端智能虚拟数字人》视频教程课程作者。












评论