
数仓安全:数据脱敏技术深度解析
1. 前言
适用版本:8.2.0 及以上版本
GaussDB (DWS)产品数据脱敏功能,是数据库产品内化和夯实数据安全能力的重要技术突破。提供指定用户范围内列级敏感数据的脱敏功能,具有灵活、高效、透明、友好等优点,极大地增强产品的数据安全能力,实现敏感数据的可靠保护。
大数据时代的到来,颠覆了传统业态的运作模式,激发出新的生产潜能。数据成为重要的生产要素,是信息的载体,数据间的流动也潜藏着更高阶维度的价值信息。对于数据控制者和数据处理者而言,如何最大化数据流动的价值,是数据挖掘的初衷和意义。然而,一系列信息泄露事件的曝光,使得数据安全越来越受到广泛的关注。各国各地区逐步建立健全和完善数据安全与隐私保护相关法律法规,提供用户隐私保护的法律保障。如何加强技术层面的数据安全和隐私保护,对数据仓库产品本身提出更多的功能要求,也是数据安全建设最行之有效的办法。
GaussDB (DWS)产品 8.1.1 版本发布数据脱敏特性,提供指定用户范围内列级敏感数据的脱敏功能,具有灵活、高效、透明、友好等优点,极大地增强产品的数据安全能力。
2. 数据脱敏概念
数据脱敏(Data Masking),顾名思义,是对于敏感数据进行屏蔽。任何泄露后可能会给社会或个人带来严重危害的数据都属于常见的敏感数据。个人身份信息,如姓名、身份证号、住址、手机号、邮箱,企业不适合公开信息,如营业执照号码、税务登记证、员工薪水,设备信息如 IP 地址、MAC 地址,银行卡号、受保护的健康信息、知识产权等都属于敏感信息。对这些敏感信息通过脱敏规则进行数据的变形,实现隐私数据的可靠保护。业界常见的脱敏规则有,替换、重排、加密、截断、掩码,用户也可以根据期望的脱敏算法自定义脱敏规则。
通常,良好的数据脱敏实施,需要遵循如下两个原则,第一,尽可能地为脱敏后的应用,保留脱敏前的有意义信息;第二,最大程度地防止黑客进行破解。
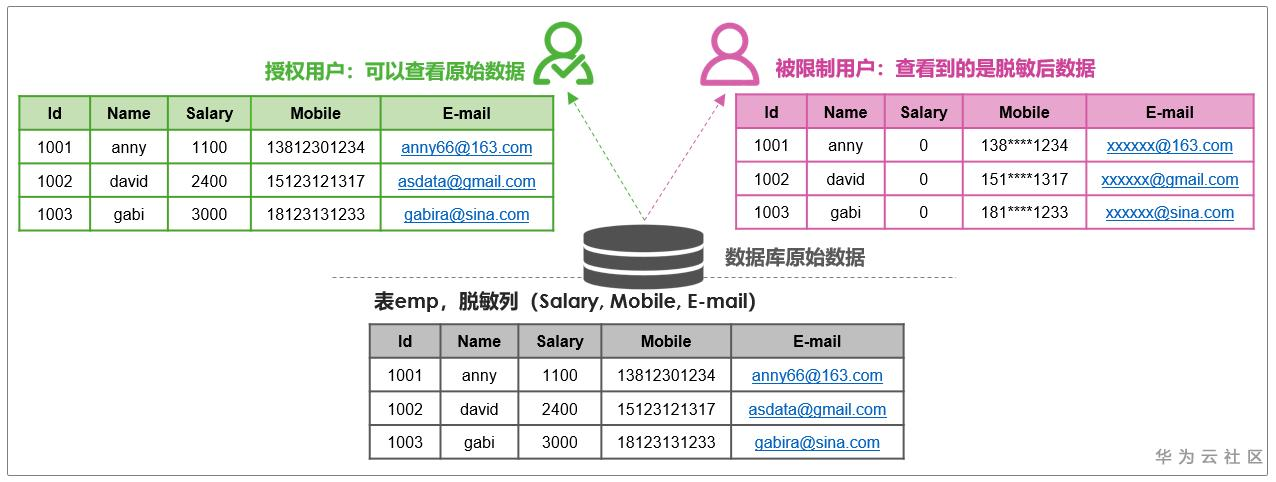
数据脱敏分为静态数据脱敏和动态数据脱敏。静态数据脱敏,是数据的“搬移并仿真替换”,是将数据抽取进行脱敏处理后,下发给下游环节,随意取用和读写的,脱敏后数据与生产环境相隔离,满足业务需求的同时保障生产数据库的安全。而动态数据脱敏则是在访问敏感数据的同时实时进行脱敏处理,可以为不同角色、不同权限、不同数据类型执行不同的脱敏方案,从而确保返回的数据可用而安全。
2.1 DWS 动态数据脱敏
GaussDB (DWS)的数据脱敏功能,摒弃业务应用层脱敏依赖性高、代价大等痛点,将数据脱敏内化为数据库产品自身的安全能力,提供了一套完整、安全、灵活、透明、友好的数据脱敏解决方案,属于动态数据脱敏。用户识别敏感字段后,基于目标字段,绑定内置脱敏函数,即可创建脱敏策略。脱敏策略(Redaction Policy)与表对象是多对一的关系。一个脱敏策略包含表对象、生效条件、脱敏列-脱敏函数对三个关键要素,是该表对象上所有脱敏列的集合,不同字段可以根据数据特征采用不同的脱敏函数,根据生效条件、脱敏列-脱敏函数对的不同也可以在同一张表上设置不同的脱敏策略。当且仅当生效条件为真时,查询语句才会触发敏感数据的脱敏,而脱敏过程是内置在 SQL 引擎内部实现的,对生成环境用户是透明不可见的。
三方代理脱敏工具 vs 数仓 DWS 脱敏引擎
三方代理工具是用户与数仓集群的中转站,是底座之外的外挂脱敏工具,无法直接参与生成环境,复杂场景较难处理
DWS 则是基于数仓底座与存储引擎、SQL 引擎直接交互的脱敏引擎,在查询执行过程中实时脱敏,脱敏结果直接返回给用户
代理脱敏工具是静态脱敏,DWS 脱敏引擎是动态脱敏
DWS 动态脱敏引擎的优势
良好的底座协同。脱敏引擎贯穿于数仓底座的诸多环节,基于预置脱敏策略,参与 SQL 引擎的解析、重写、优化与执行。脱敏过程用户无感知。
策略可配置。客户可结合自身业务场景识别敏感数据并对业务表的指定列灵活预置脱敏策略。
策略可扩展。产品内置脱敏函数,可以涵盖大部分常见脱敏效果,支持用户自定义脱敏函数。
数据可用性。数据库内原始敏感数据参与运算,仅在出库时刻(返回结果时)才会做脱敏处理。
数据访问受控。脱敏策略生效条件的用户均对原始敏感数据不可见。
全场景数据不泄露。底座交互,可减少敏感数据传输链路潜在的泄露风险,
更加安全可靠,且充分识别各种恶意套取潜在场景并有效防护。
3. 数据脱敏使用方法
动态数据脱敏,是在查询语句执行过程中,根据生效条件是否满足,实现实时的脱敏处理。生效条件,通常是针对当前用户角色的判断。敏感数据的可见范围,即是针对不同用户预设的。系统管理员,具有最高权限,任何时刻对任何表的任何字段都可见。确定受限制用户角色,是创建脱敏策略的第一步。
敏感信息依赖于实际业务场景和安全维度,以自然人为例,用户个体的敏感字段包括:姓名、身份证号、手机号、邮箱地址等等;在银行系统,作为客户,可能还涉及银行卡号、过期时间、支付密码等等;在公司系统,作为员工,可能还涉及薪资、教育背景等;在医疗系统,作为患者,可能还涉及就诊信息等等。所以,识别和梳理具体业务场景的敏感字段,是创建脱敏策略的第二步。
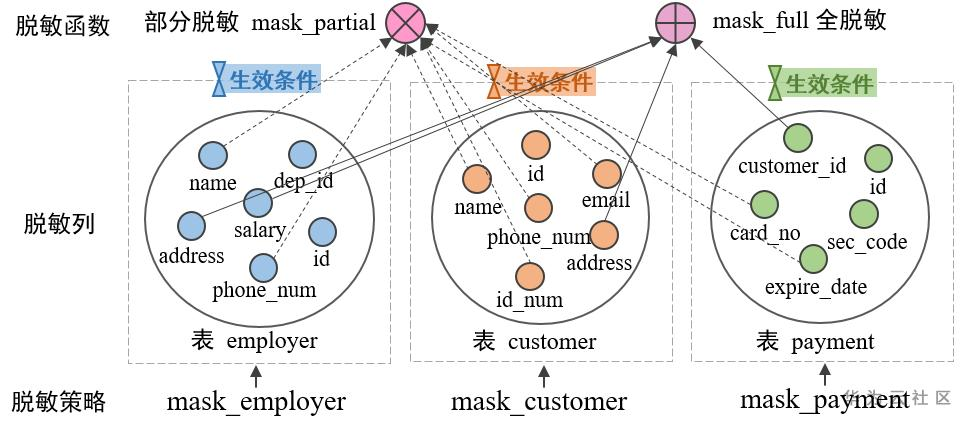
产品内置一系列常见的脱敏函数接口,可以针对不同数据类型和数据特征,指定参数,从而达到不一样的脱敏效果。脱敏函数可采用如下三种内置接口,同时支持自定义脱敏函数。三种内置脱敏函数能够涵盖大部分场景的脱敏效果,不推荐使用自定义脱敏函数。
MASK_NONE:不作脱敏处理,仅内部测试用。
MASK_FULL:全脱敏成固定值。
MASK_PARTIAL:使用指定的脱敏字符对脱敏范围内的内容做部分脱敏
不同脱敏列可以采用不同的脱敏函数。比如,手机号通常显示后四位尾号,前面用"*"替换;金额统一显示为固定值 0,等等。确定脱敏列需要绑定的脱敏函数,是创建脱敏策略的第三步。
以某公司员工表 emp,表的属主用户 alice 以及用户 matu、july 为例,简单介绍数据脱敏的使用过程。其中,表 emp 包含员工的姓名、手机号、邮箱、发薪卡号、薪资等隐私数据,用户 alice 是人力资源经理,用户 matu 和 july 是普通职员。
假设表、用户及用户对表 emp 的查看权限均已就绪。
1.创建脱敏策略 mask_emp,仅允许 alice 查看员工所有信息,matu 和 july 对发薪卡号、薪资均不可见。字段 card_no 是数值类型,采用 MASK_FULL 全脱敏成固定值 0;字段 card_string 是字符类型,采用 MASK_PARTIAL 按指定的输入输出格式对原始数据作部分脱敏;字段 salary 是数值类型,采用数字 9 部分脱敏倒数第二位前的所有数位值。
切换到 matu 和 july,查看员工表 emp。
2.由于工作调整,matu 进入人力资源部参与公司招聘事宜,也对员工所有信息可见,修改策略生效条件。
切换到用户 matu 和 july,重新查看员工表 emp。
3.员工信息 phone_no、email 和 birthday 也是隐私数据,更新脱敏策略 mask_emp,新增三个脱敏列。
切换到用户 july,查看员工表 emp。
4.考虑用户交互的友好性,GaussDB (DWS) 提供系统视图 redaction_policies 和 redaction_columns,方便用户直接查看更多脱敏信息。
5.突然某一天,公司内部可共享员工信息时,直接删除表 emp 的脱敏策略 mask_emp 即可。
更多用法详情,请参考 GaussDB (DWS)产品文档。
4. 可算不可见的数据脱敏
在使用数据脱敏功能时,存在先对敏感数据进行加工计算在进行输出的情况。对于这种情况,如果采用经过脱敏后的数据进行库内计算,那么在例如聚集函数、过滤条件等条件下经过脱敏的数据本身会对查询结果产生影响,因此针对这一现象对数据脱敏引入了可算不可见功能。所谓可算不可见,就是在数据库内使用原始的敏感数据参与加工计算,只在出库时对敏感数据进行脱敏处理。想要使用可算不可见功能,需要设置开关 enable_redactcol_computable=on。
目前支持将敏感数据直接参与加工计算的场景如下:
SELECT nullif(salary, 1) FROM emp;投影列表达式 nullif
SELECT email LIKE ‘%.com’ FROM emp;投影列 LIKE 表达式
SELECT to_days(birth) FROM david.emp;投影列函数 to_days
SELECT count(*) FROM emp;聚集函数
SELECT * FROM emp WHERE cardid IS NOT NULL; 过滤条件
SELECT name, avg(salary) * 12 FROM emp GROUP BY name; 分组条件(name 是脱敏字段)
SELECT (SELECT salary+10 FROM emp ORDER BY id LIMIT 1);子查询位置投影列表达式
两表使用敏感字段作关联条件
CTE 表达式投影列
出库时刻会触发数据脱敏的场景如下:
表查询
视图查询
DML RETURNING 子句
COPY 导出
GDS 外表导出
游标 CURSOR… FETCH
存储过程定义使用脱敏表,查询存储过程
4.1 脱敏策略的继承
对于 INSERT/UPDATE/MERGE INTO/CREATE TABLE AS 语句,当子查询是对某个敏感字段的投影操作时,就会触发脱敏继承,从而使得包含了敏感信息的新表上含有与源表相同的脱敏策略,避免了通过在新表中插入源表敏感数据,再查询新表导致敏感数据泄露的问题。此外,脱敏策略的继承属于表维度的活动,继承活动不关注子查询部分当前会话或角色条件下脱敏策略是否生效。
继承脱敏策略的第一步是进行敏感血缘分析,对于任何用户执行 DML 语句,都遍历子查询部分源表及其目标投影列,一旦源表存在脱敏策略且目标投影列是脱敏字段,则认为使用源表插入/更新目标表数据时,存在暴露源表敏感数据的风险。
对脱敏策略进行继承时,首先从从遍历标记的源表敏感信息中,生成作用于目标表的脱敏策略信息及脱敏字段信息。随后系统内置生成策略创建语句并执行写入系统表 pg_redaction_policy/pg_redaction_column,对于内置创建的脱敏策略,统一命名为“inherited_rp”。最后再将系统表元数据 inherit 标记字段为 true。
注意,如果 INSERT 执行会话/用户满足触发条件,当带有 RETURNING 子句打印插入结果时,返回结果会脱敏,日志信息“Parent redaction policies/columns”会记录策略继承的来源。
随着脱敏策略继承行为的引入,产生了一些脱敏策略冲突的场景。例如 SELECT 语句查询目标列非原始敏感字段,而是敏感字段的复杂表达式,表达式先算后脱敏,此时如何界定脱敏行为?SETOP 集合运算两个子分支的对应同一目标列采用不同的脱敏效果,此时如何界定外层语句目标列的脱敏结果?多次 INSERT/UPDATE 操作的敏感血缘分析中,同一目标列的源表投影列采用的不一样的脱敏效果,且源表策略的生效条件也可能不同,此时脱敏策略该如何继承?
针对这些冲突场景,基于保护用户任何敏感数据不致泄露优先于敏感数据脱敏效果不具有原始特征的原则,当遇到脱敏效果冲突时,都提升为通用脱敏效果 mask_full。mask_full 是可覆盖任何数据类型的全脱敏函数,只关注表达式返回值类型,可以保证脱敏数据不会泄露,但是会导致脱敏结果无法表征原始数据特征,使得脱敏结果的可读性较差。此外,针对 length、count 等函数表达式,其计算结果不会暴露任何原始数据特征及信息,所以提供了 ALTER FUNCTION … [NOT] MASKED 语法,支持用户手动配置不脱敏函数白名单。
4.2 防护恶意套取
已知某些敏感信息,通过多次试探性匹配,反向佐证可见的用户信息,从而窃取用户的隐私数据。借助助等值判断形式表达式的过滤条件或投影操作试探性匹配敏感信息。这些通过已知常量值和等值/类等值判断表达式来进行套取用户隐私数据的行为成为恶意套取。
如上述例子所示,尽管已经对用户的 name 信息进行了脱敏,但由于查询条件是针对’张三’用户,因此即使被脱敏为’张*’,我们还是可以很容易确定这里的脱敏前信息是‘张三’,从而导致张三用户的信息存在泄漏的风险。
针对这一问题,我们采用了“悲观主义”模式,任何常量等值判断都可能存在恶意套取的风险,都应当禁止,实例如下:
禁止使用常量恶意套取的场景总结如下:
1.脱敏字段的常量等值判断表达式、复合表达式、等价表达式
2.假设 name 字段是脱敏字段且当前会话满足策略触发条件,则语句有如下(且不限于)特征,存在恶意套取风险,禁止执行:
• name = '张三‘
• name = ‘张三’ OR name = ‘李四’
• name in (‘张三’, ‘李四’)
• CASE name WHEN ‘张三’ THEN true …
• CASE WHEN name in (‘张三’, ‘李四’) THEN …
• 高级包 dbms_output.put_line
3.语句执行会报错:ERROR: Redaction column “name” cannot be referenced in equivalence conditions with const value.
5. 数据脱敏实现原理
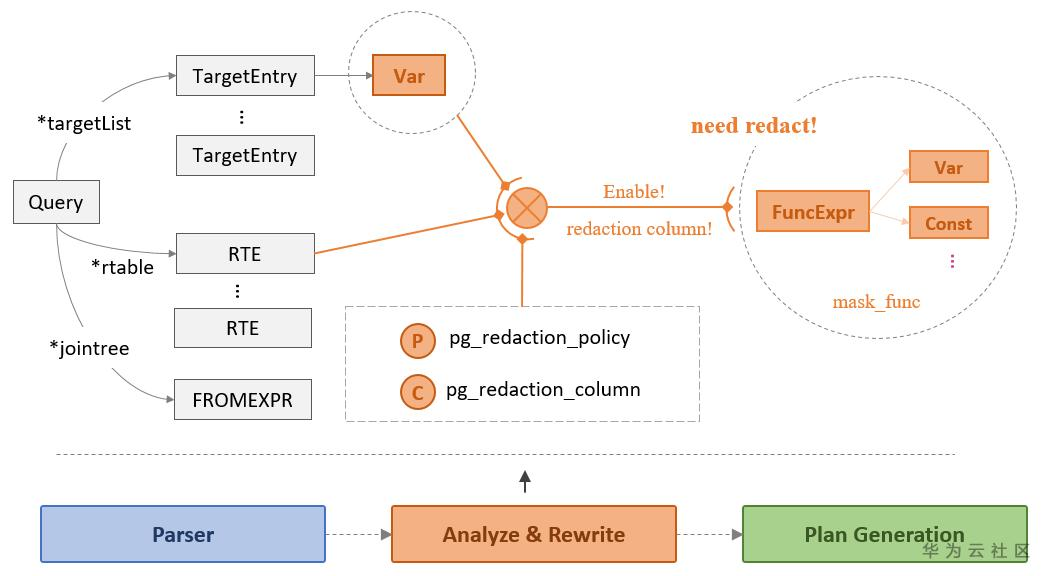
GaussDB (DWS)数据脱敏功能,基于 SQL 引擎既有的实现框架,在受限用户执行查询语句过程中,实现外部不感知的实时脱敏处理。关于其内部实现,如上图所示。我们将脱敏策略(Redaction Policy)视为表对象上绑定的规则,在优化器查询重写阶段,遍历 Query Tree 中 TargetList 的每个 TargetEntry,如若涉及基表的某个脱敏列,且当前脱敏规则生效(即满足脱敏策略的生效条件且 enable 开启状态),则断定此 TargetEntry 中涉及要脱敏的 Var 对象,此时,遍历脱敏列系统表 pg_redaction_column,查找到对应脱敏列绑定的脱敏函数,将其替换成对应的 FuncExpr 即可。经过上述对 Query Tree 的重写处理,优化器会自动生成新的执行计划,执行器遵照新的计划执行,查询结果将对敏感数据做脱敏处理。
带有数据脱敏的语句执行,相较于原始语句,增加了数据脱敏的逻辑处理,势必会给查询带来额外的开销。这部分开销,主要受表的数据规模、查询目标列涉及的脱敏列数、脱敏列采用的脱敏函数三方面因素影响。
针对简单查询语句,以 tpch 表 customer 为例,针对上述因素展开测试,如下图所示。
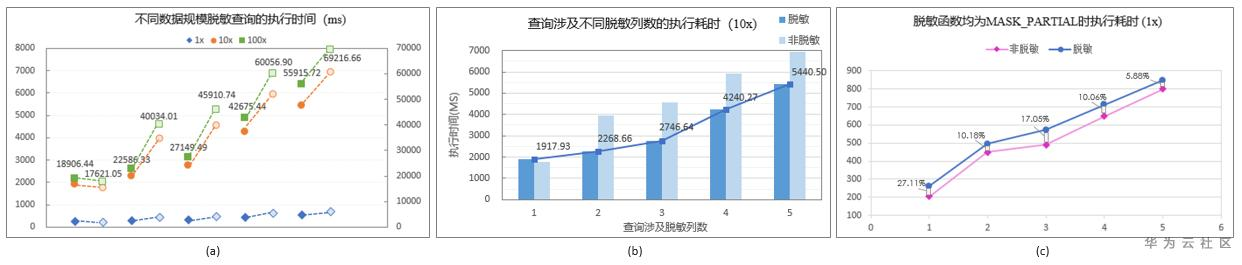
图(a)、(b)中基表 customer 根据字段类型和特征,既有采用 MASK_FULL 脱敏函数的,也有采用 MASK_PARTIAL 脱敏函数的。MASK_FULL 对于任何长度和类型的原始数据,均只脱敏成固定值,所以,输出结果相较于原始数据,差异很大。图(a)显示不同数据规模下,脱敏和非脱敏场景简单查询语句的执行耗时。实心图标为非脱敏场景,空心图标为被限制用户,即脱敏场景。可见,数据规模越大,带有脱敏的查询耗时与原始语句差异越大。图(b)显示 10x 数据规模下查询涉及脱敏列数不同对于语句执行性能的影响。涉及 1 列脱敏列时,带有脱敏的查询比原始语句慢,追溯发现,此列采用的是 MASK_PARTIAL 部分脱敏函数,查询结果只是改变了结果的格式,结果内容的长度并未变化,符合“带有脱敏的语句执行会有相应的性能劣化”的理论猜想。随着查询涉及脱敏列数的增加,我们发现一个奇怪的现象,脱敏场景反倒比原始语句执行更快。进一步追溯多列场景下脱敏列关联的脱敏函数,发现,正是因为存在使用 MASK_FULL 全脱敏函数的脱敏列,导致输出结果集部分相比原始数据节省很多时间开销,从而多列查询下带有数据脱敏的简单查询反倒提速不少。
为了佐证上述猜测,我们调整脱敏函数,所有脱敏列均采用 MASK_PARTIAL 对原始数据做部分脱敏,从而能够在脱敏结果上保留原始数据的外部可读性。于是,如图©所示,当脱敏列均关联部分脱敏函数时,带有数据脱敏的语句比原始语句劣化 10%左右,理论上讲,这种劣化是在可接受范围的。上述测试仅针对简单的查询语句,当语句复杂到带有聚集函数或复杂表达式运算时,可能这种性能劣化会更明显。
6. 总结
GaussDB (DWS)产品数据脱敏功能,是数据库产品内化和夯实数据安全能力的重要技术突破,主要涵盖以下三个方面:
一套简单、易用的数据脱敏策略语法;
一系列可覆盖常见隐私数据脱敏效果的、灵活配置的内置脱敏函数;
一个完备、便捷的脱敏策略应用方案,使得原始语句在执行过程中可以实时、透明、高效地实现脱敏。
总而言之,此数据脱敏功能可以充分满足客户业务场景的数据脱敏诉求,支持常见隐私数据的脱敏效果,实现敏感数据的可靠保护。
文章转载自:华为云开发者联盟

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论