
记一次请求头导致的 requests 乱码问题 && 源码分析
引言
好好的代码,添加了请求头,也正确的解码了响应,跑的好好的突然就乱码了,换了几种方式解码都不成功,研究了好久,才发现问题。
问题复现
先来看这样一段代码:
上面的代码在正常情况下访问是没有问题的,当然了,地址我使用百度来替代。
但是跑着跑着,有的时候会遇到下面的乱码问题,开始不能稳定复现,后来发现可以稳定复现了,猜测可能是服务端改了什么东西。

问题分析
起初我以为是编码方式变了,换了好几种编码方式都无法成功解码。
使用抓包工具抓包发现,抓包工具可以正常显示响应数据,说明服务端返回的数据是正确的。后来打印了一下响应头,和使用浏览器访问其他网站对比了一下,发现了一个异常的地方。

从上面的图中可以看到,content-type 请求头的编码是 utf-8 没有问题,但是前面的 content-encoding 却是 br。这个 br 是啥呢,查了一下,它的全称叫做:Brotli。
Brotli 是谷歌开发的一种全新的压缩算法,它的压缩率相比于 gzip 来说要高得多,也就是说服务端在告诉我们,响应数据使用了 br 算法来压缩,那肯定就要用 br 算法来解压缩。
想到了这里,我们再看一下请求头,'Accept-Encoding': 'gzip, deflate, br, zstd',在发送请求头的时候,我们指定了四种算法,这里是给服务端用来协商压缩算法的,服务端可以选取自己支持的算法来进行压缩,目的是减少服务器流量占用。
问题解决
分析到这里我们应该明白了,其实主要原因就是我们提供了多种压缩算法,但是其中有我们不支持的算法,服务端正好选择了我们不支持的算法,导致程序接收到的响应无法解码。
那原因清楚了,解决问题就很简单了,删除我们不支持的 br 算法即可。删掉 br 请求头后,问题解决,响应可以正常解码。
源码分析
那 requests 为什么不支持 br 算法呢,既然可以支持 gzip,那我理解 br 算法应该也是可以支持的,我们到源码里面看一看。
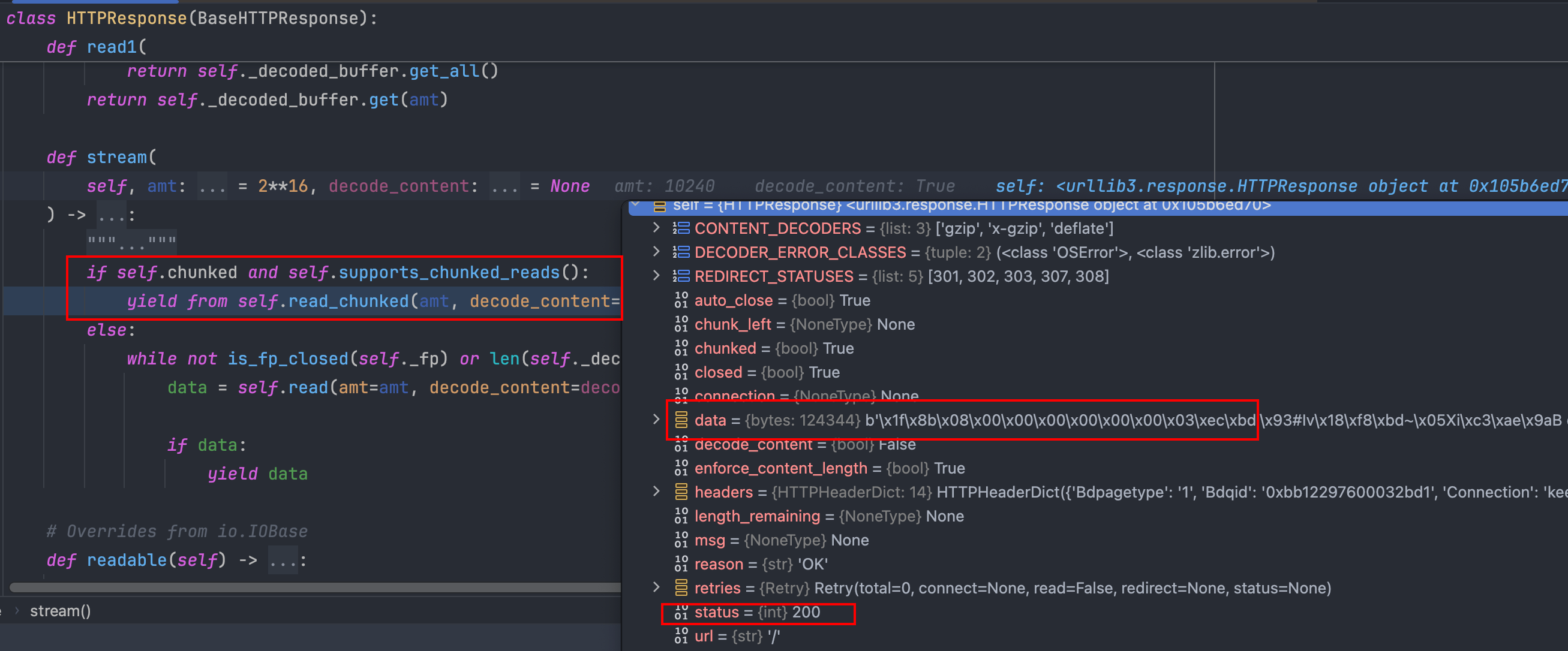
跟踪代码,我们发现在获取响应时,会进入上图中的方法,这个时候的 data 变量还是未解压缩的数据,说明解压缩操作应该在 read_chunked 里面,继续步入看看。
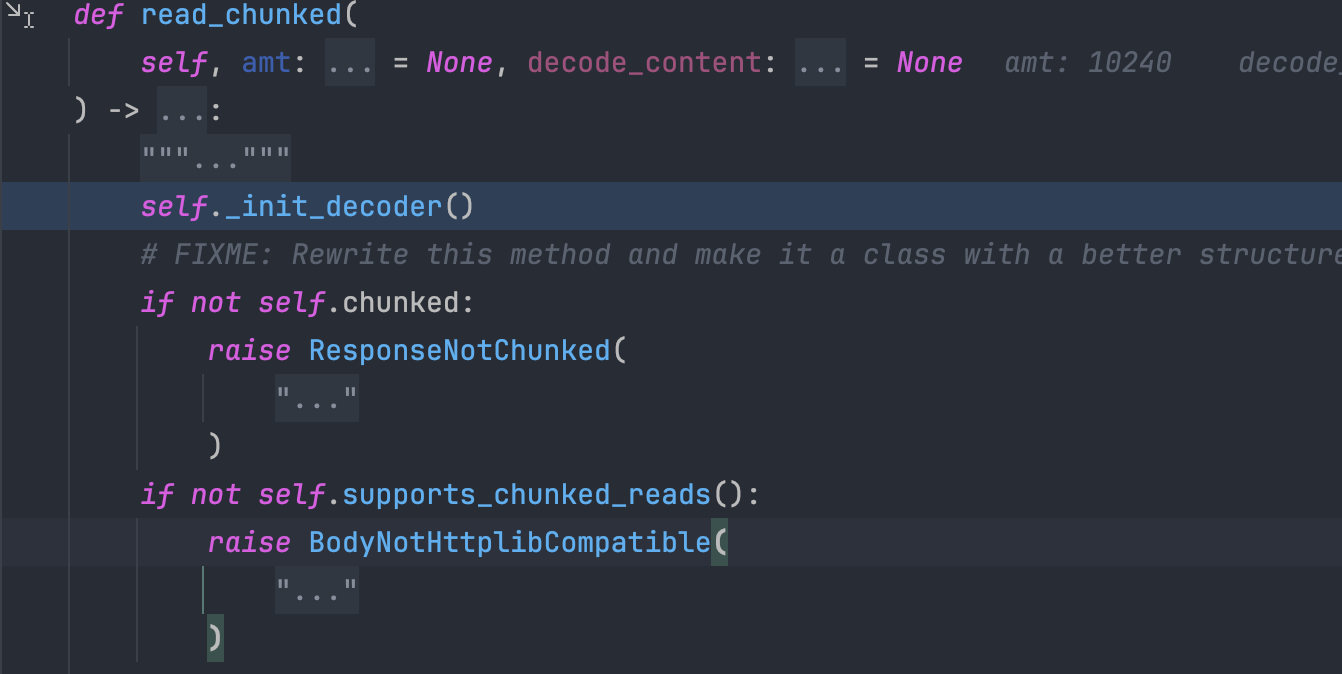
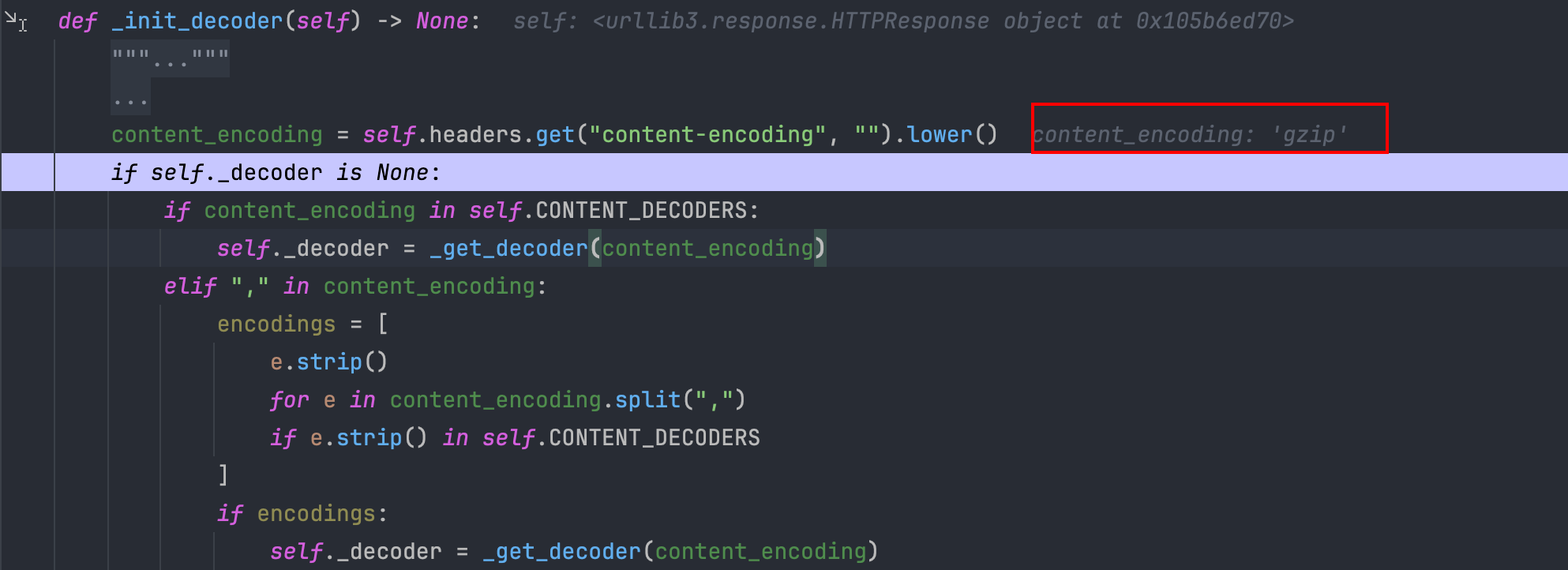
发现有一个 init_decoder 方法,看上去是一个解码器的初始化方法,进入看看,首先获取请求头中的 content-encoding 字段,可以看到目前获取的是 gzip,如果获取到了,则初始化对应的解码器,继续往下看。
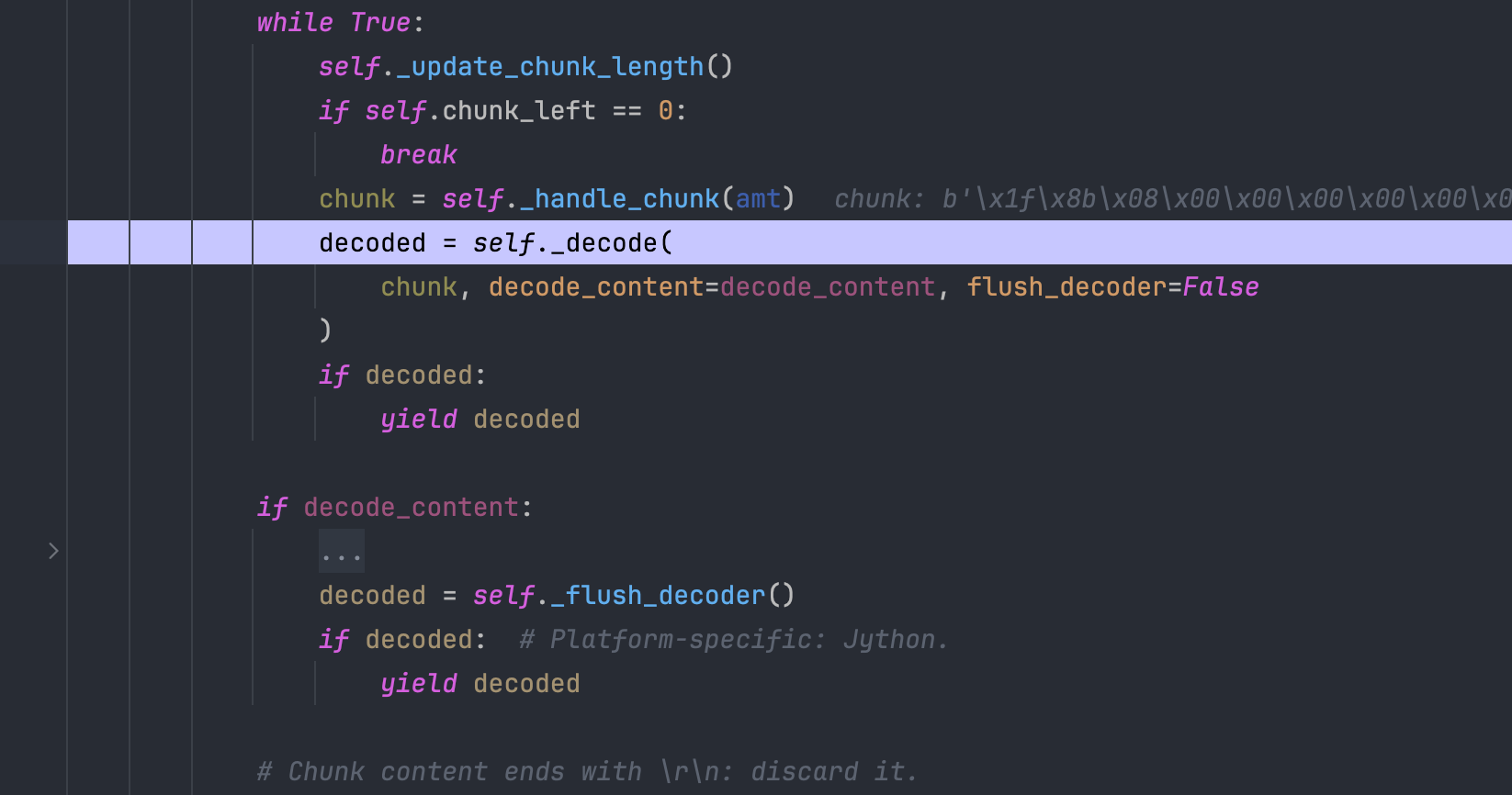
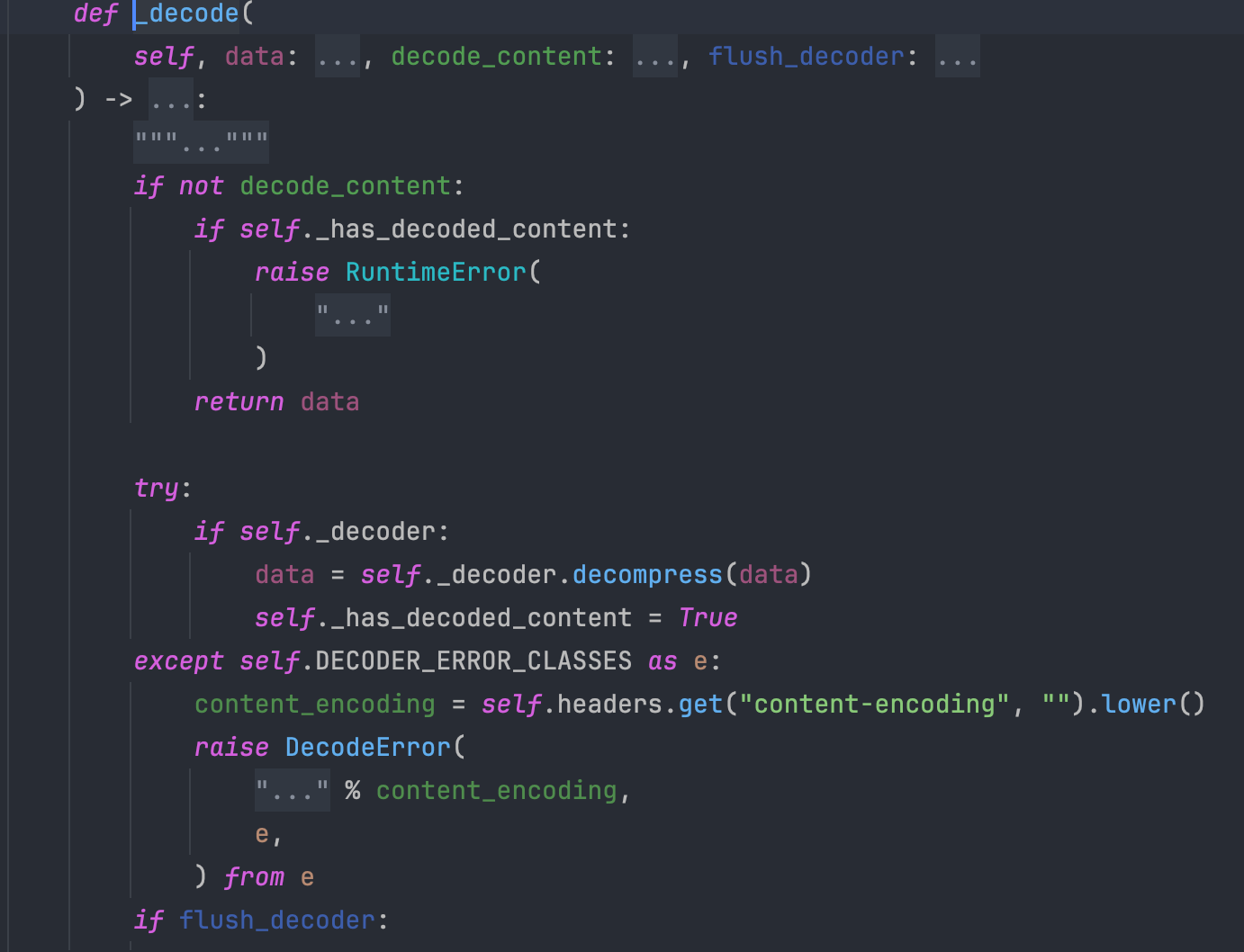
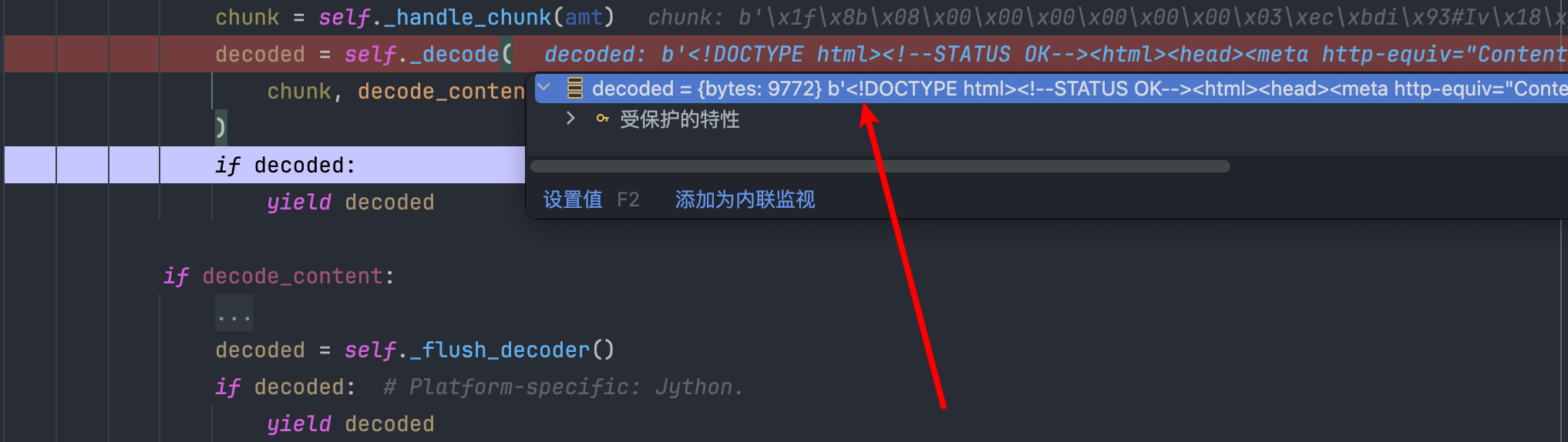
继续往下就到了解码的地方,在一个循环中调用刚才初始化好的解码器开始解压缩工作,并返回解压缩后的数据,可以看到 decoded 变量存储的数据已经被解压了,已经变成了我们可以看懂的明文。
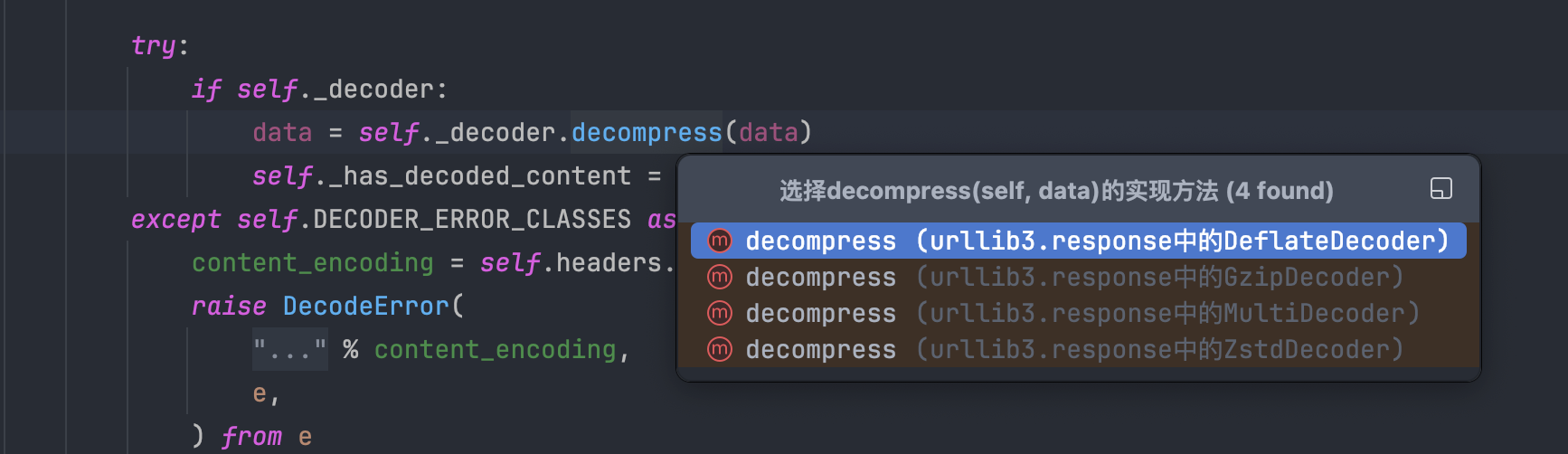
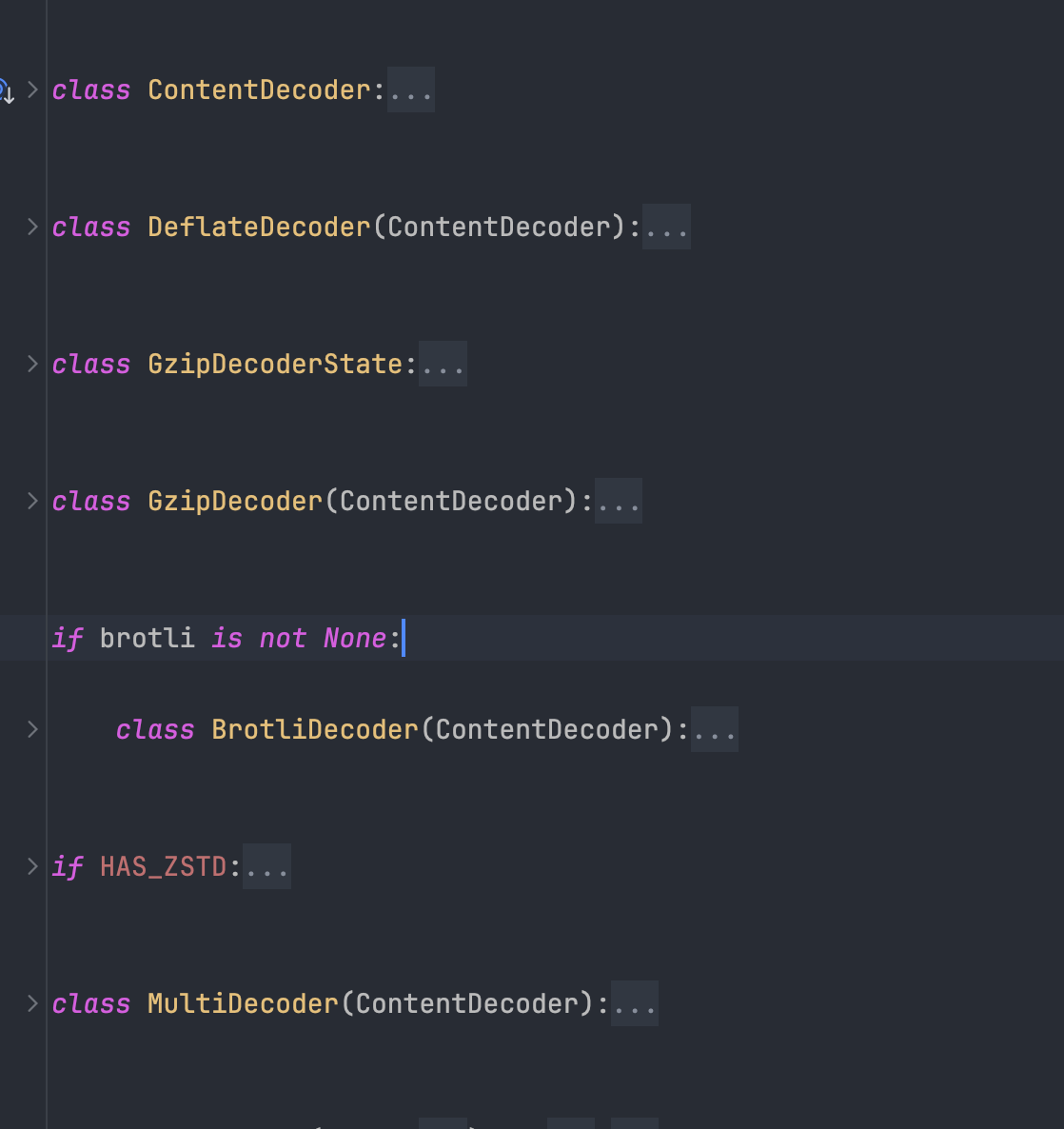
查看解码器对应的实现,发现一共有四个实现,仔细查看对应的实现,发现其实有五个,而且底层实现是支持 br 算法的,只不过是通过 brotli 变量进行控制的,看下这个变量是怎么来的。
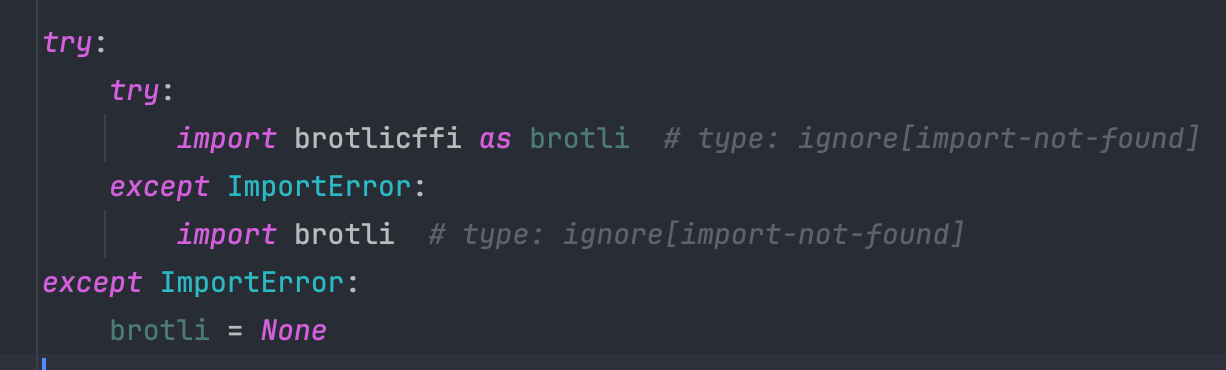
看到这里,一切真相大白了,原来是尝试导入了 brotli 库,如果发现导入错误,则认定是没有安装对应的算法库,就无法进行解压缩工作了,只能原样返回响应数据。
新解决方案
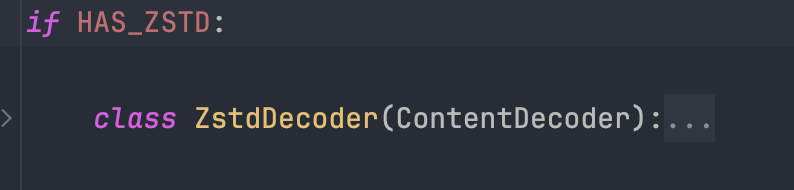
看到这里,大家应该都知道了,其实解决这个问题更加简单的方式是直接安装对应的 brotli 库,在可以正常导入 brotli 库后,解压缩工作也就能正常进行了。如果怕后续再遇到类似的问题,我们也可以提前安装 zstandard 库,下次如果服务端选择了 zstd 算法的话,我们不用更改任何代码就可以自动兼容了。

安装 brotli 库后,重新发起请求,发现这次选择了 br 算法并且可以正常解码数据,完工。
总结
本次问题其实是由服务端改动引起的,通过源码分析,我们知道了原来底层库已经支持了br 算法以及 zstd 算法,只不过我们没有安装对应的解码库,所以才无法解码的。后面只要将对应的库都安装上,就可以畅通无阻了,因为浏览器也就支持这四种算法,短时间内应该就不会再出现类似的问题了。
不推荐删除 br 算法支持,因为更高的压缩率就意味着更少的流量,在使用流量计费的代理 IP 时,还是可以降低不少费用的。而且万一服务端通过支持的算法来识别爬虫呢?哈哈哈,不敢想不敢想。
本文章首发于个人博客 LLLibra146's blog
本文作者:LLLibra146
更多文章请关注公众号 (LLLibra146):

版权声明:本博客所有文章除特别声明外,均采用 © BY-NC-ND 许可协议。非商用转载请注明出处!严禁商业转载!
版权声明: 本文为 InfoQ 作者【LLLibra146】的原创文章。
原文链接:【http://xie.infoq.cn/article/4db0531c6cd2698ea23f07f0a】。未经作者许可,禁止转载。

还未添加个人签名 2018-09-17 加入
还未添加个人简介












评论