
袋鼠云产品功能更新报告 04 期丨 2023 年首次,产品升级“狂飙”

新的一年我们加紧了更新迭代的速度,增加了数据湖平台EasyLake和大数据基础平台EasyMR,超 40 项功能升级优化。我们将继续保持产品升级节奏,满足不同行业用户的更多需求,为用户带来极致的产品使用体验。
以下为袋鼠云产品功能更新报告第四期内容,更多探索,请继续阅读。
数据湖平台
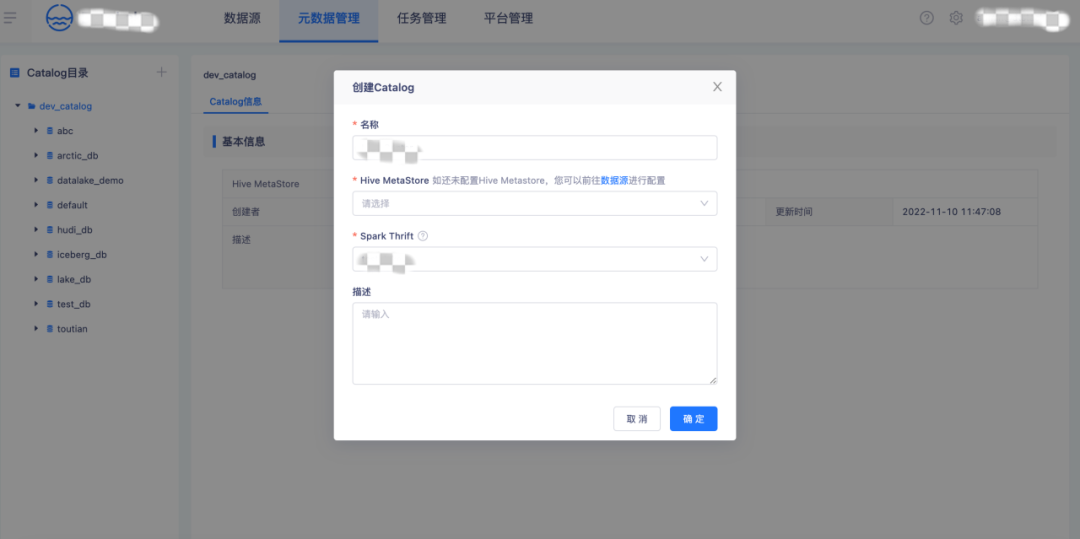
1.【元数据管理】Catalog 创建
在【元数据管理】页创建一个 Catalog,填写 Catalog 名称、Hive MetaStore、Spark Thrift。
一个 Calalog 只允许绑定一个 Hive MetaStore,Spark Thrift 用于 Iceberg 表创建、数据入湖转表任务,用户可以使用 Calalog 进行业务部门数据隔离。
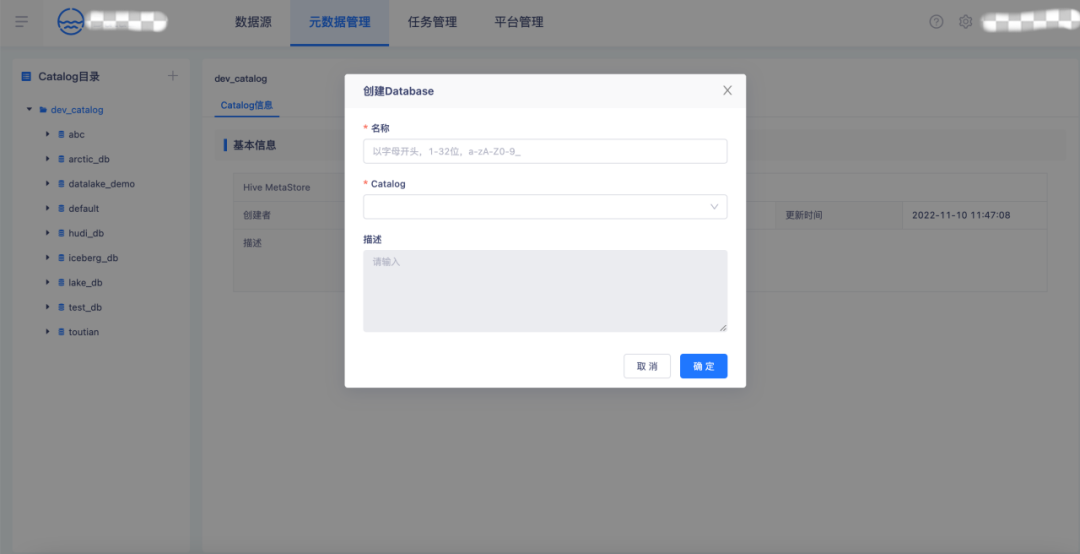
2.【元数据管理】Database 创建
在【元数据管理】页创建一个 Database,绑定 Calalog。
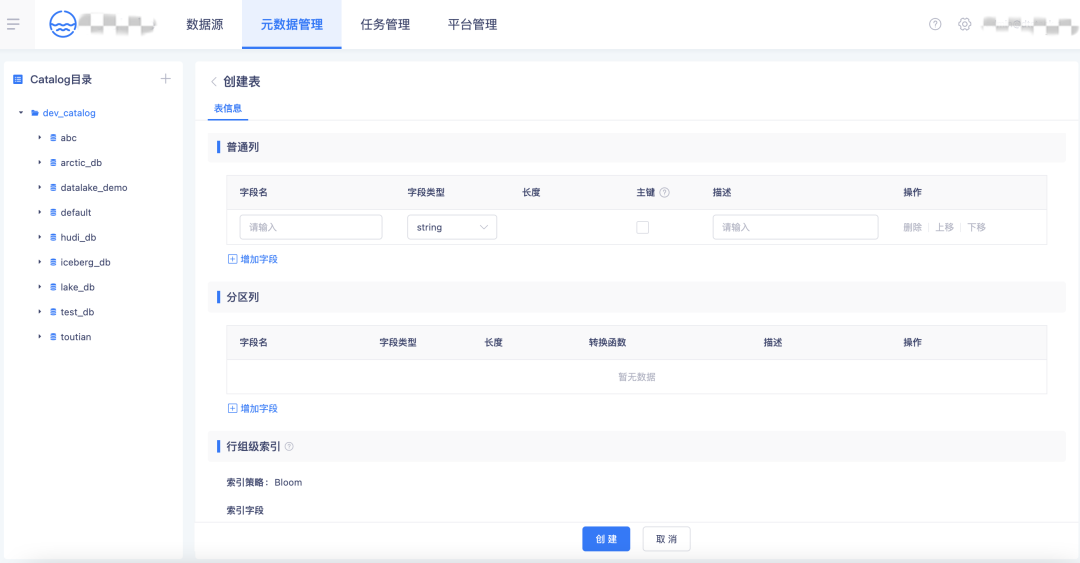
3.【元数据管理】Iceberg 表创建
• 在【元数据管理】页创建一个创建一张 Table:选择 Table 所在的 Catalog、Database,目前只支持 Iceberg 湖表创建;
• 设置表普通列,支持对普通列字段设置主键,可以用作湖表的唯一标识;
• 选择普通列字段作为分区字段,支持多种转换函数,timestamp 数据类型字段支持时间字段按照年、月、日和小时粒度划分区;
• 支持行组级索引设置,选择普通列作为索引字段,设置 Bloom 索引;
• 自定义高级参数设置。
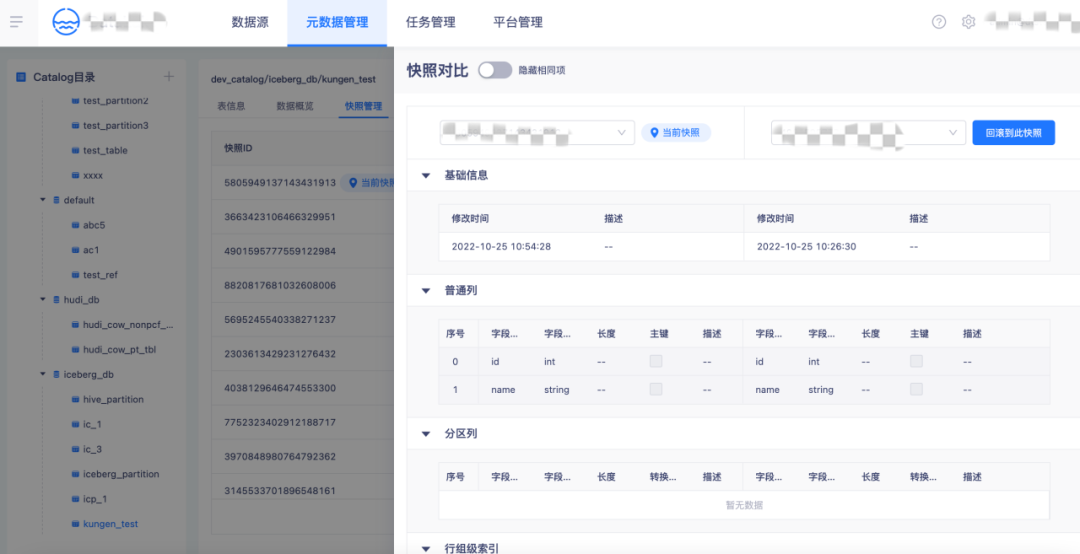
4.【元数据管理】Iceberg 表快照管理
支持快照历史管理,支持多版本间快照变更对比,支持湖表时间旅行,可一键回滚到指定数据版本。
5.【数据入湖】支持 Hive 转 Iceberg 表实现Hive表入湖
在【数据入湖】页创建一个入湖任务,选择 Parquet、ORC、Avro 格式 Hive 表进行转表入湖,一键生成湖表信息.
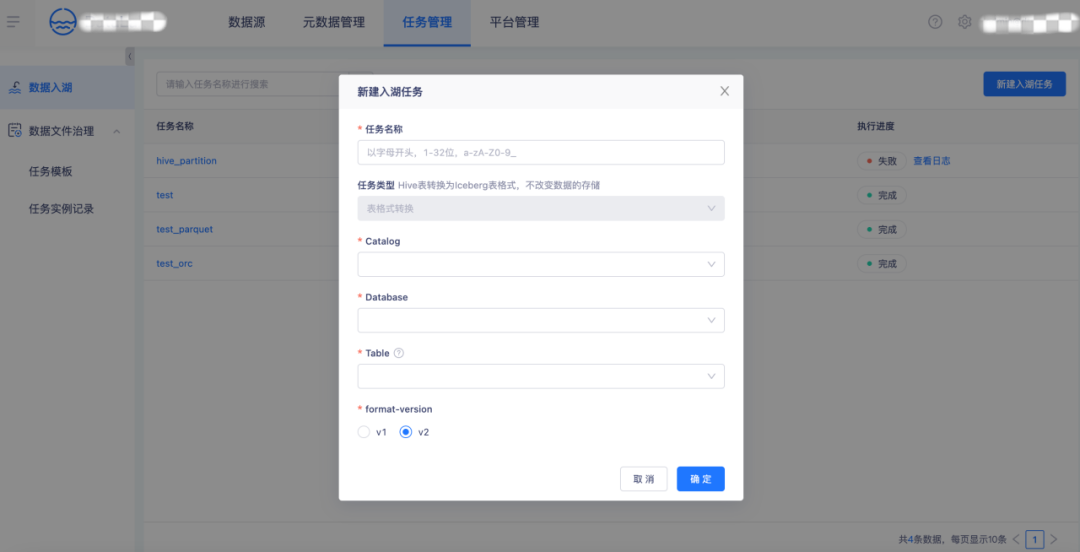
6.支持小文件合并、孤儿文件清理、过期快照清理
在【数据文件治理】-【任务模板】页新建任务模板,支持小文件合并、快照清理、孤儿文件清理等数据文件治理任务,支持立即支持、预约治理、周期治理多种数据治理方式。
大数据基础平台
1.【全局】使用主机名作为机器唯一标识
• EM平台产品上变更为以主机名 Hostname 作为唯一标识对主机进行管理;
• 主机间通信默认为 IP 通信,可在【平台管理】-【通信配置】页进行通信方式切换。
2.功能优化
• 告警:新建告警通道出现异常时 dtalert 和 grafana 告警通道不一致
• 告警:dtalert 挂载目录与上传 jar 包目录不一致
• 告警:添加自定义告警通道保存后编辑上传 jar 包不显示
• Hadoop 安全:EM 开启 Hadoop 安全,服务未重启,直接显示开启成功
• 备份优化:EM备份管理查询优化
• redis 角色获取:redis 运行正常,但是角色获取信息有误,导致部署其他服务无法正确获取 redis 角色状态
离线开发平台
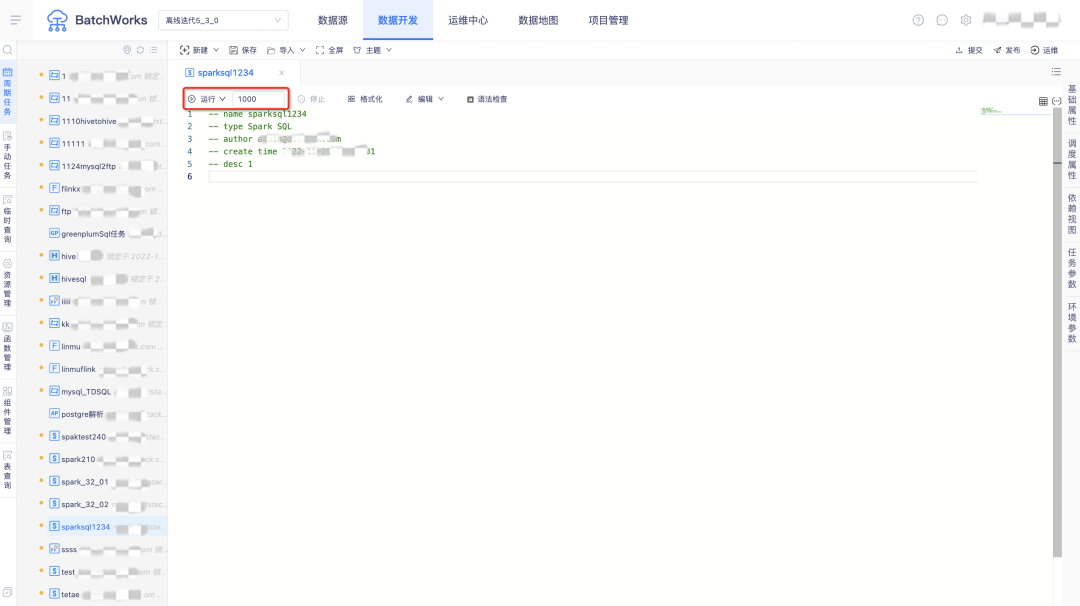
1.数据开发 IDE 中可限制数据查询条数
用户痛点:数据开发页面的临时运行没有限制数据结果查询条数,极端情况下有把系统磁盘打满的风险。
新增功能说明:所有SQL类型任务,运行按钮右侧新增了数据查询条数输入框,默认查询条数为 1000 条,上限最大值为 1000000 条(最高上限为配置项,可在后台配置)。
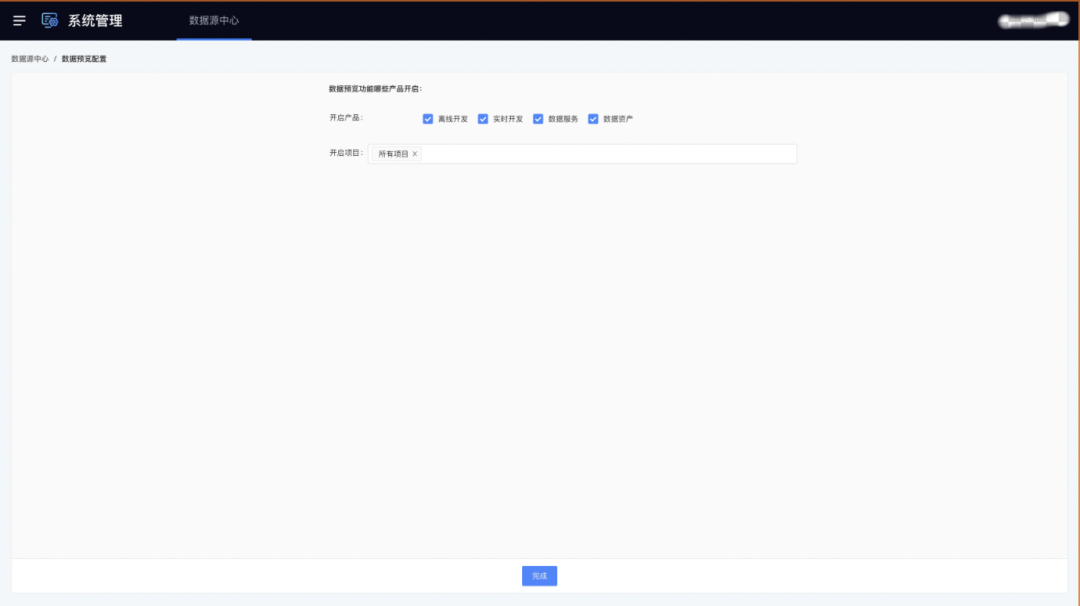
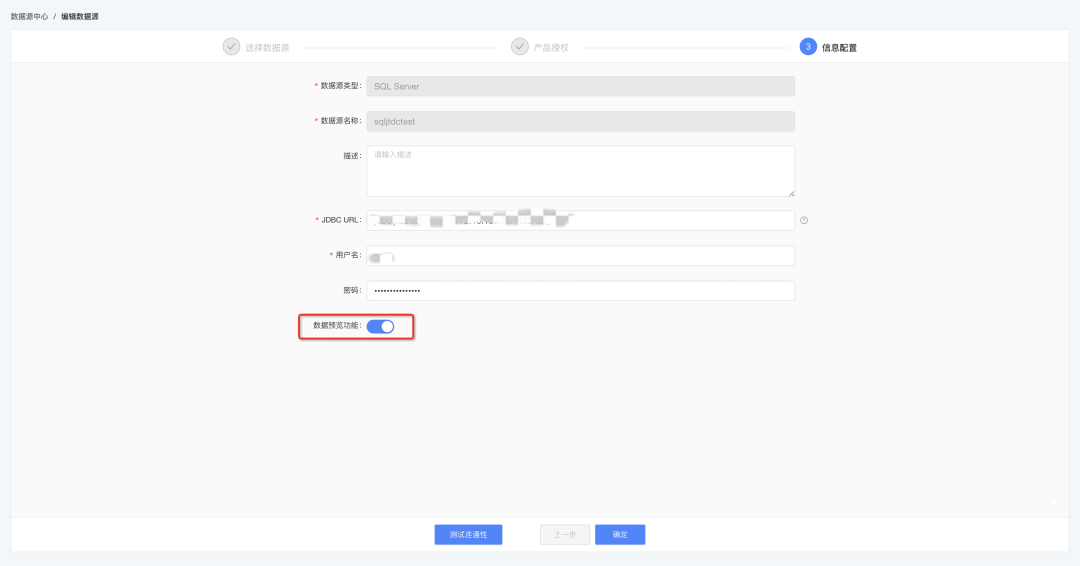
2.数据预览全局管控功能对接
数据源中心新增数据预览全局管控开关:
• 可进行子产品和项目的数据预览全局管控
• 可进行单个数据源的数据预览管控
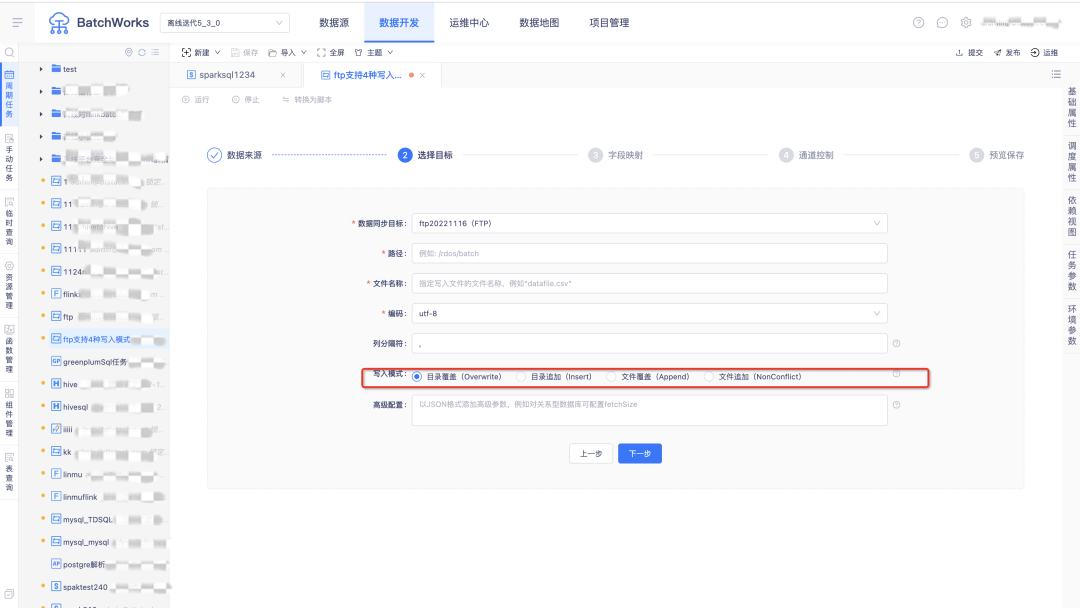
3.FTP 作为目标数据源支持 4 种写入模式
• append:按文件名称覆盖写入;
• overwrite:先清空目录下的文件然后写入;
• nonconflict:按文件名称查找,存在同名文件则报错,不存在同名文件则可正常写入;
• insert:文件追加写入,存在同名时通过添加后缀的方式修改新文件的文件名称;
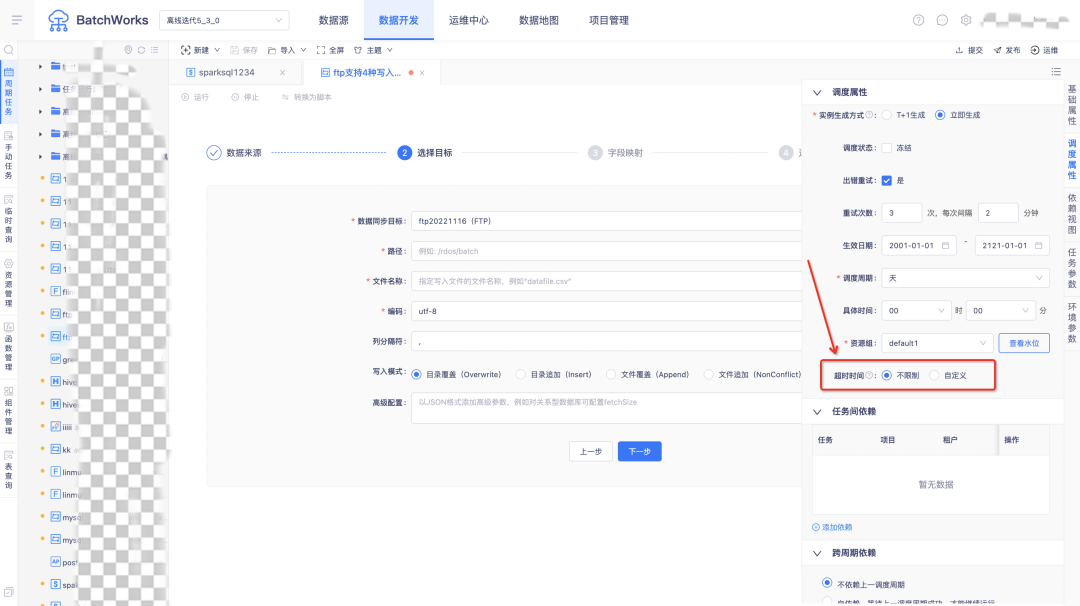
4.运行超时中断
任务支持设置超时时间,运行时间超过此时间时后台会自动杀死。
5.数据同步通道控制页面支持配置高级参数
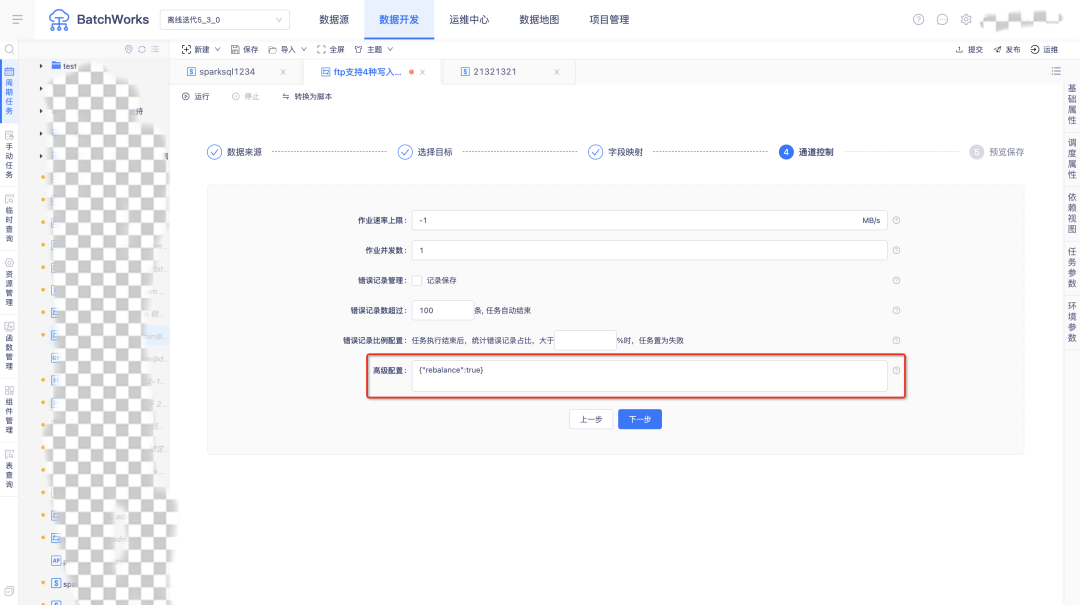
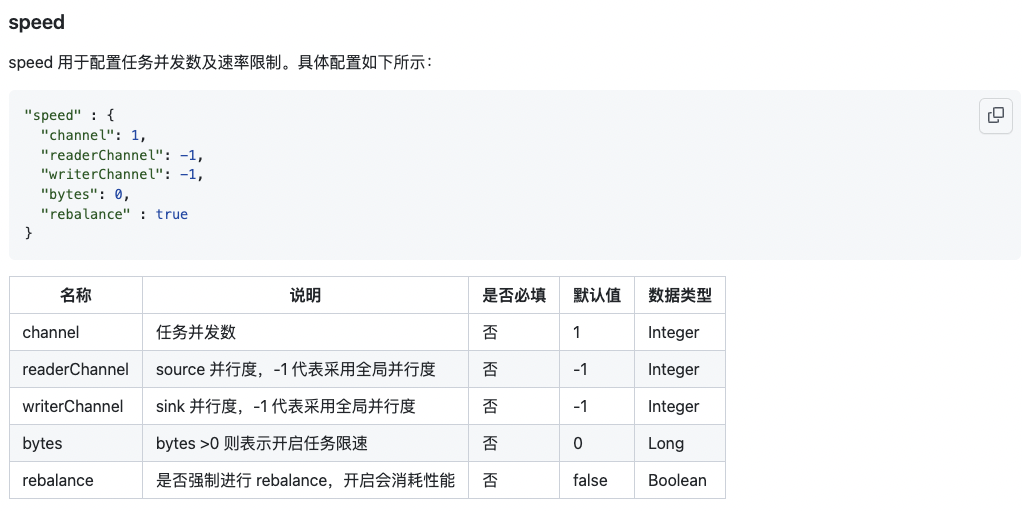
6.其他新增功能项
• Inceptor 表接入数据地图:Inceptor 已数据地图中支持元数据查询、数据脱敏、血缘展示等功能;
• 支持 Flink Batch 任务类型;
• HBase REST API 支持数据同步读取;
• Sybase 支持数据同步读取。
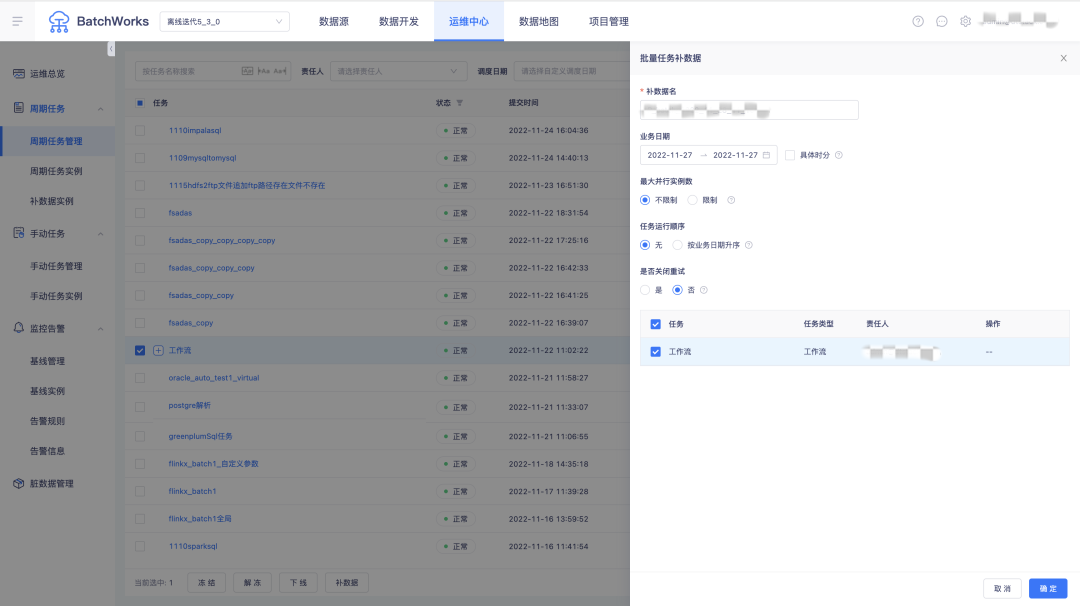
7.补数据优化
• 补数据支持三种补数据模式:单任务补数据、在任务管理列表按筛选条件筛选批量任务补数据、按任务上下游关系选择多个任务补数据;
• 多个在同一依赖树但彼此之间存在断层/不直接依赖的任务,所生成的补数据实例仍将按原依赖顺序执行;
• 支持选择是否关闭重试;
• 补数据支持选择未来时间。
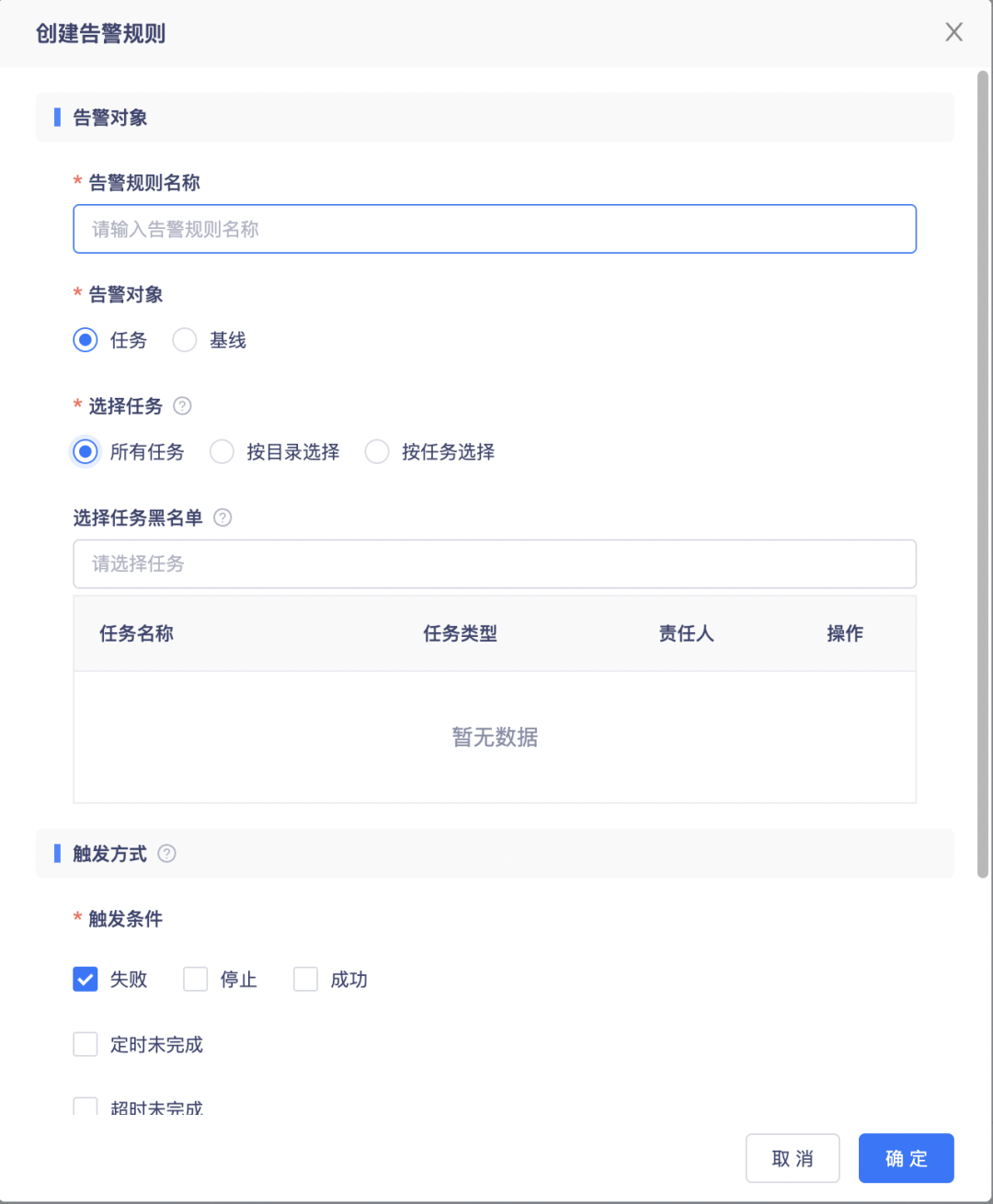
8.告警规则任务选择方式优化
支持按项目全选任务或按任务管理目录全选目录下任务。
9.整库同步功能优化
• 整库同步支持选择:Oracle MySQL DB2 Hive TiDB PostgreSQL ADB Doris Hana 作为整库同步目标端;
• 高级设置能查看历史配置,针对同一数据源和 schema,能记录高级设置的规则内容。
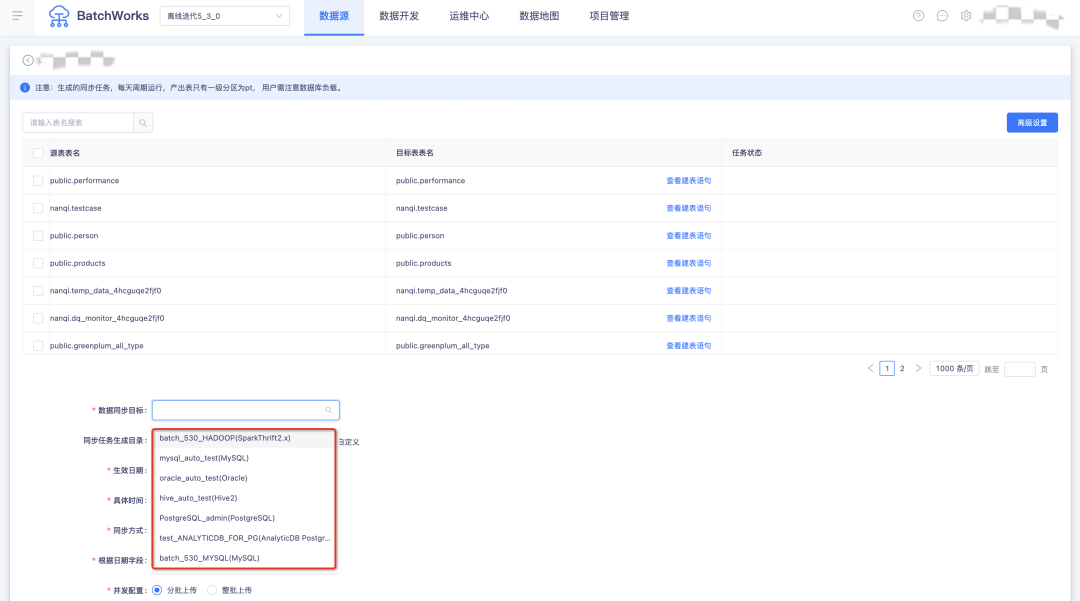
10.Greenplum 任务调整
• Greemplum SQL 和 Inceptor SQL 临时运行复杂 SQL 和包含多段 SQL 时运行逻辑从同步运行修改为异步运行;
• 表查询中可查看Greenplum元数据信息;
• 支持语法提示。
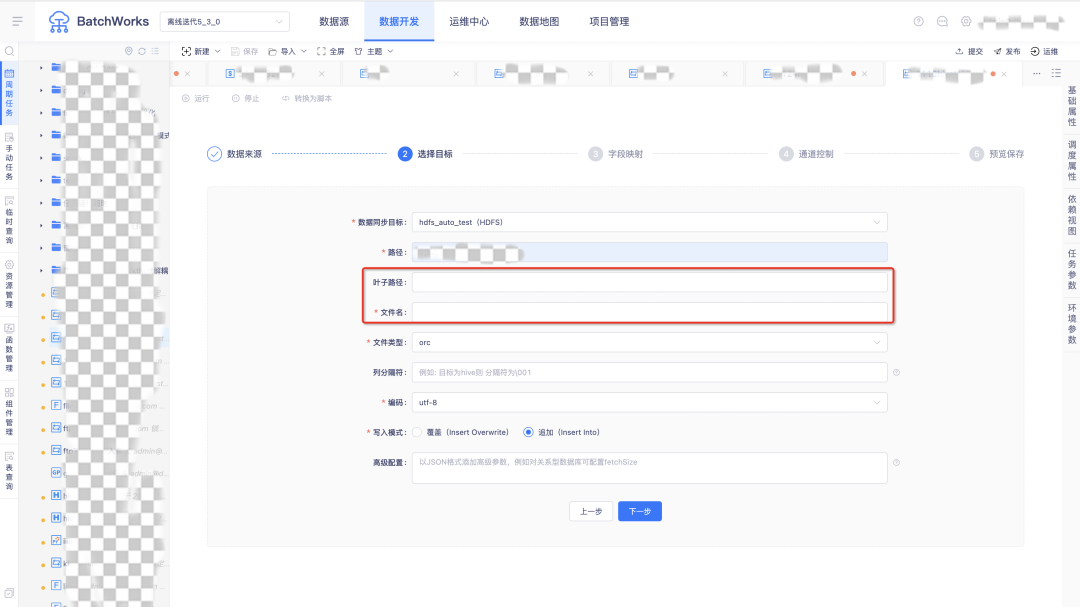
11.数据同步至 HDFS 时支持指定文件名称
用户痛点:历史写 HDFS 时,指定文件名实际是指定的叶子目录名称,实际无法指定文件名称。
体验优化说明:在高级配置中新增了参数 strictMode,当参数值为“true”时,开启严格模式,当参数值为”false“时,开启宽松模式。严格模式下,指定叶子路径下的文件名,仅允许存在一个文件名,多并行度、断点续传将不生效。
12.创建项目只允许以英文字母开头
因部分引擎只能创建/读取以英文字母开头的 schema(例如 Trino),所以创建项目时项目标识限制为只允许以英文字母开头。
13.发布按钮点击逻辑优化
修改前:只有已提交的任务发布按钮才可点击。
修改后:所有状态的任务发布按钮均可点击。
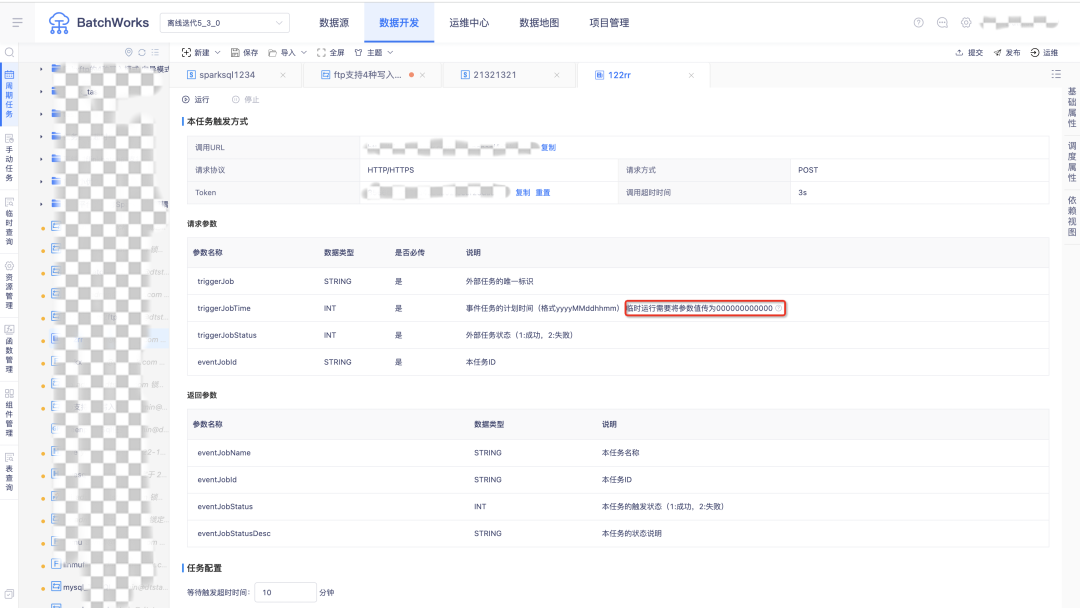
14.事件任务文案调整
临时运行需要将参数值传为 000000000000。
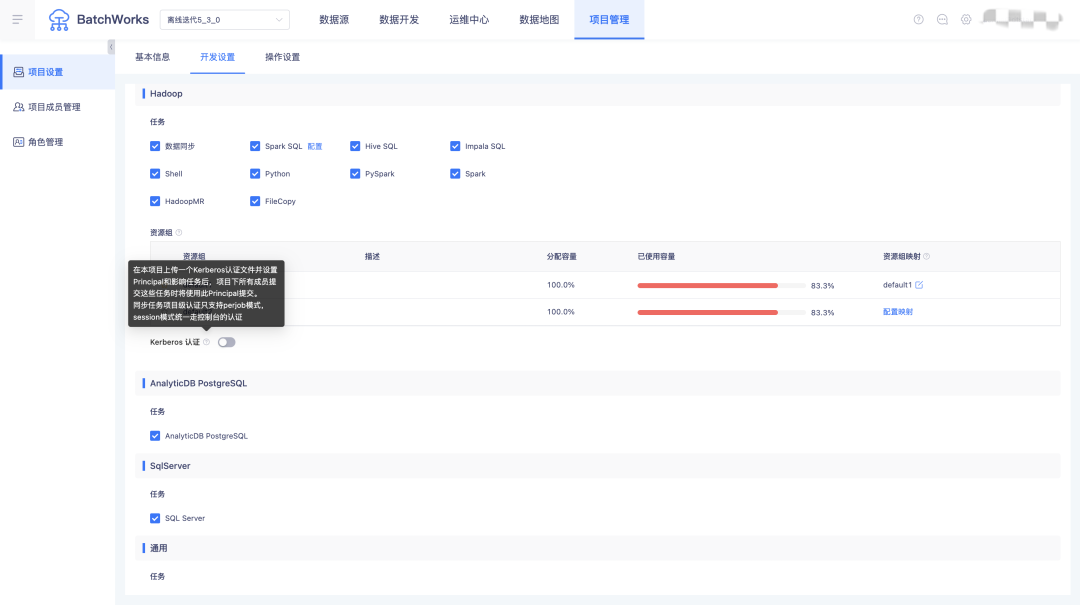
15.项目级 kerberos 新增提示
16.数据同步可选表范围优化
用户痛点:meta schema 对应的数据源和连接用户都是控制台的,如果不限制项目里的这个数据源只能选择项目对接的这一个 schema,相当于每个项目都可以通过数据同步绕过数据权限管控把集群下所有别的项目的 schema 的表直接同步到当前项目中用,这是一个非常大的权限漏洞。
体验优化说明:
• 过滤脏数据表;
• 针对所有 meta schema 所对应的数据源固定可选 schema 的范围仅当前项目对接的 schema;
• 如果需要在当前项目同步任务里要用到其他 schema,可以把其他项目的 meta schema 通过租户管理员授权引入当前项目里用。
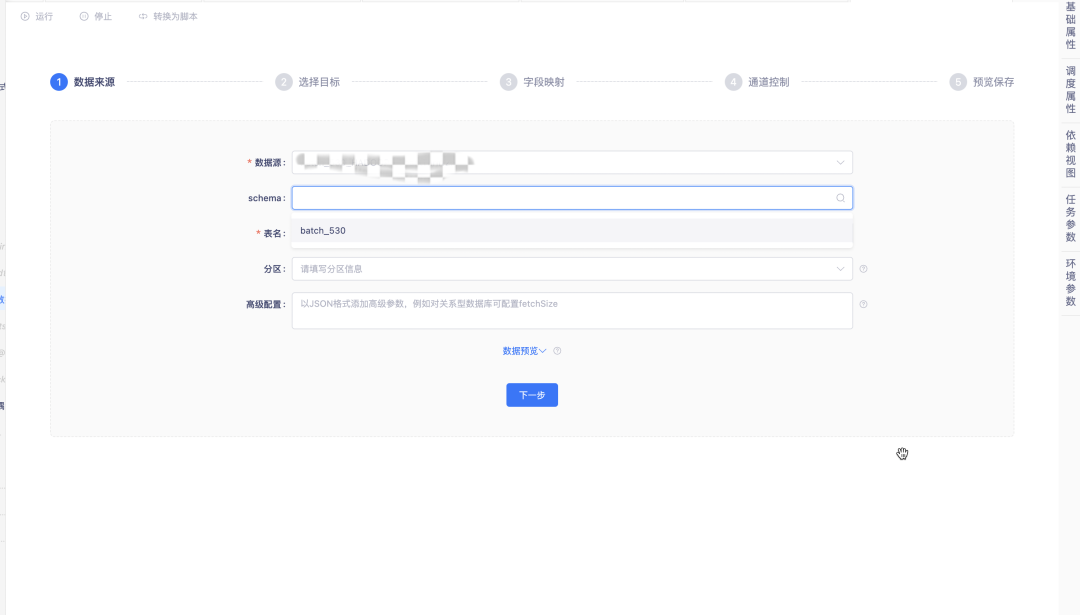
17.数据同步实例运行指标展示优化
数据同步任务实例的运行日志优化了同步性能展示方式。
18.其他体验优化项
• 安全审计操作对象“脚本”修改为“临时查询”;
• for 循环内网络开销调用优化。
实时开发平台
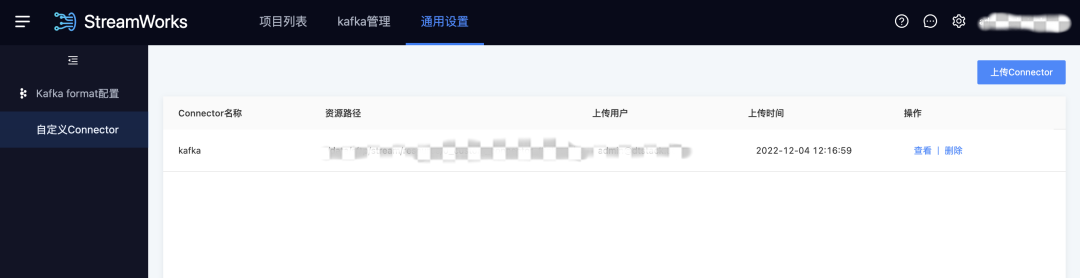
1.自定义 Connector
用户痛点:随着实时产品客户的增长,各种各样的数据源插件需求不断,我们希望有开发能力的客户,可以不用等产品迭代,自行开发插件去使用产品,使产品能力越来越开放灵活。
新增功能说明:对于 ChunJun 尚未支持的数据源,支持上传【用户自行开发/第三方】的插件包(需符合 Flink Connector 的开发要求,平台不校验插件的可用性),然后在脚本模式的任务开发中使用。
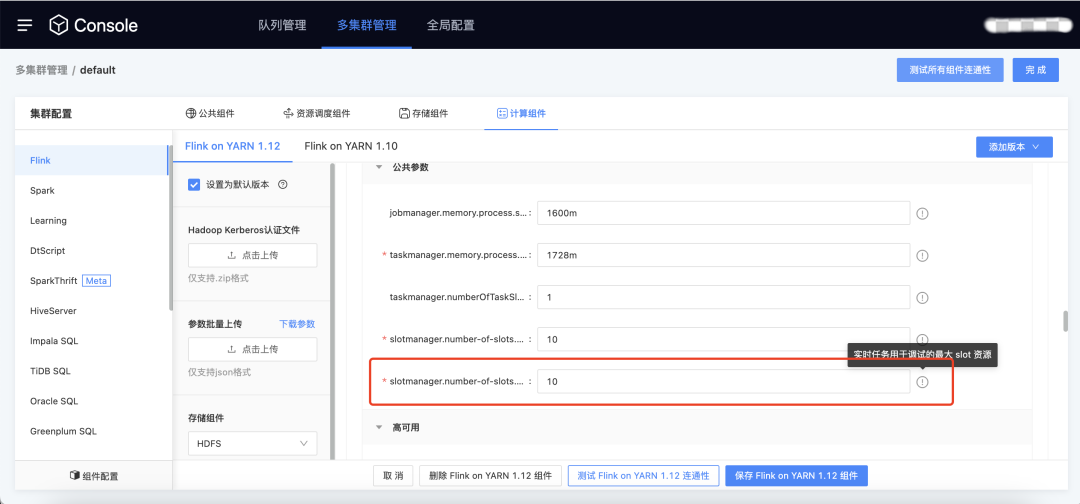
2.Session 模式
用户痛点:之前实时任务的调试功能,和普通任务一样走的 per job 模式。虽然该模式可以保障任务运行的稳定性,但是整个的提交-申请资源-运行,后端处理流程较长,不符合调试的功能场景(调试不需要持续的稳定性,但是需要快速的出结果)。
新增功能说明:调试任务以session模式运行,提高调试效率,用户需要先在控制台为实时 debug 分配 slot 资源。
3.表管理
用户痛点:之前每个实时任务的开发,都需要临时映射 Flink 表,开发效率较低;之前提供的 Hive catalog 表管理,需要用户维护 Hive Metastore,对原 Hive 有一定的入侵。
新增功能说明:提供数栈MySQL作为 Flink 元数据的存储介质;提供向导和脚本两种模式维护 Catalog-database-table;支持在 IDE 开发页面直接创建、引用 Flink 库表(需要已 Catalog.DB.table 的方式引用)。
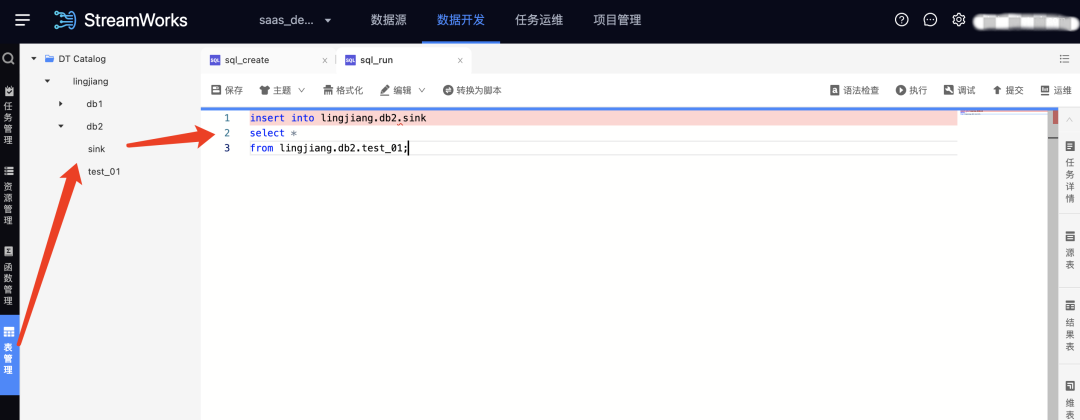
4.数据源新增/优化
• 新增 GreatDB 作为 FlinkSQL 的维表、结果表;
• 新增 HBase2.x 作为 FlinkSQL 的结果表;
• 新增 Phoenix5.x 作为 FlinkSQL 的结果表;
• 优化Oracle数据源,新增序列管理、clob/blob 长文本数据类型支持。
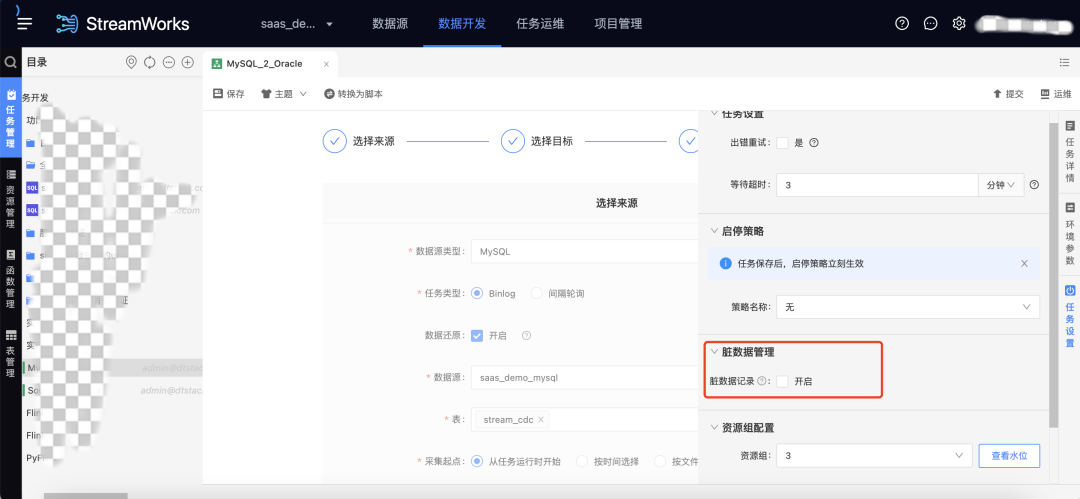
5.脏数据管理
用户痛点:原脏数据管理仅支持 FlinkSQL 任务。
新增功能说明:实时采集也支持脏数据管理。
6.功能优化
• 任务运维:新增列表过滤器,支持按状态、任务类型、责任人等过滤查询;
• 数据开发:优化任务操作相关按钮的排版;IDE 输入支持自动联想;实时采集脚本模式支持注释。
数据资产平台
1.数据源
• 新增数据源支持:
Greenplum、DB2、PostgreSQL(V5.3.0)
Hive3.x(Apache)、Hive3.x(CDP)、TDSQL、StarRocks(V5.3.1)
• Meta 数据源自动授权支持:
Hive3.x(Apache)、Hive3.x(CDP)(V5.3.0)
TiDB(V5.3.1)
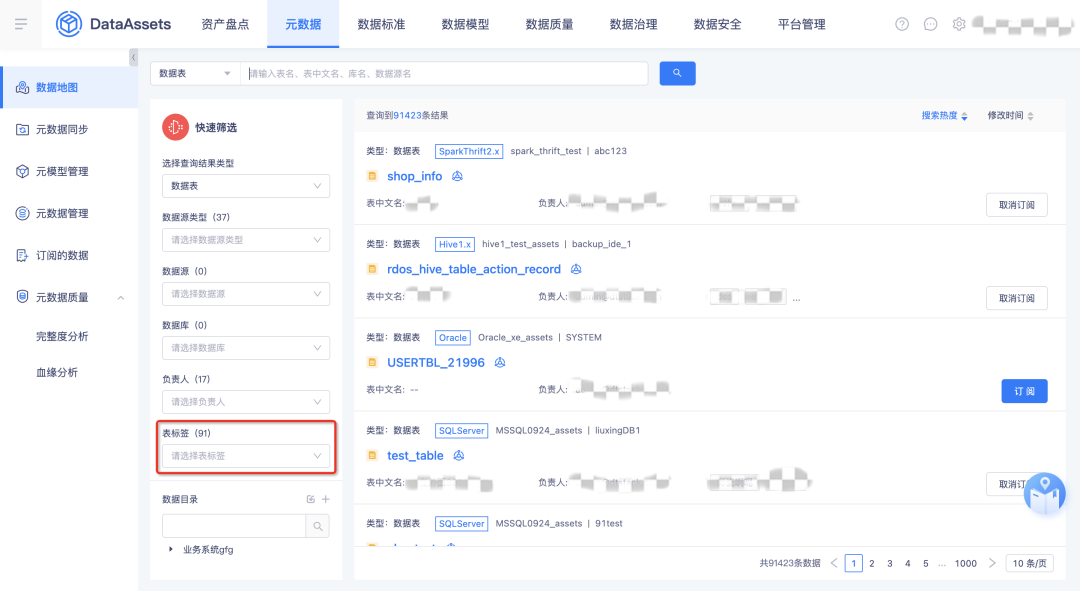
2.数据地图
• 新增指标:指标进数据地图,作为资产平台的一类资产;
• kafka 元数据优化:Kafka 隐藏表结构,新增分区查询 tab;
• 标签筛选优化:标签采集到的任务,之前没有根据实体进行区分,会出现标签名称相同的情况,新增功能为标签添加「所属实体」属性并在快速筛选栏增加实体筛选;
• 表标签优化:表维度进入时,显示「表标签」,其他维度显示「标签」;各个维度打的标签相互隔离,从不同维度进入时,不再能看到全部标签。
3.API 血缘
实现了表到 API、API 到 API 的血缘链路打通。
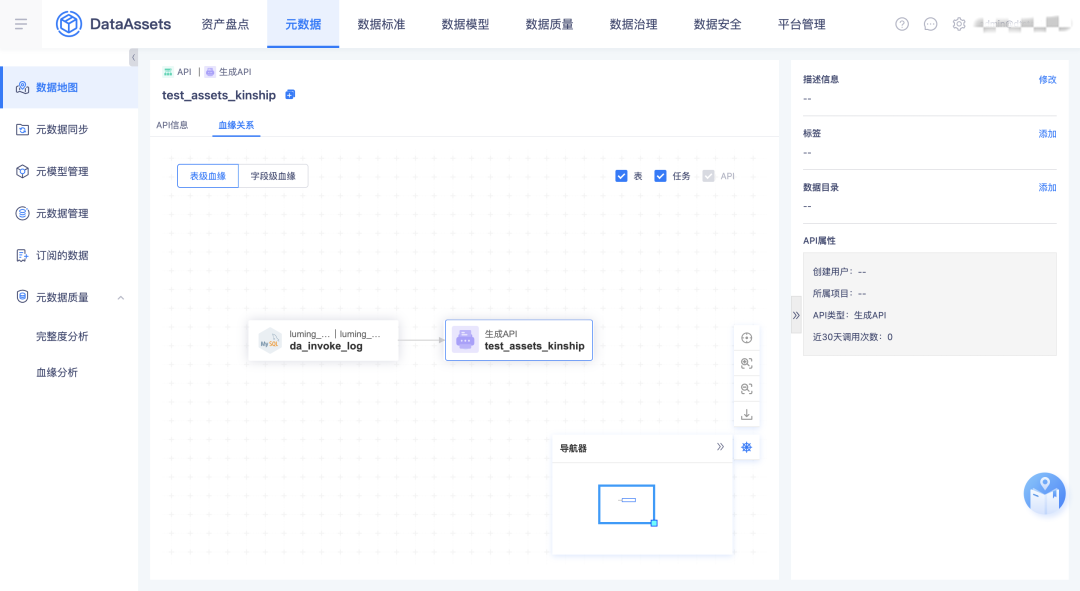
4.指标/标签血缘
本期把指标标签内部的血缘关系先拿到资产进行展示,下一期会实现表到指标、表到标签的血缘关系。
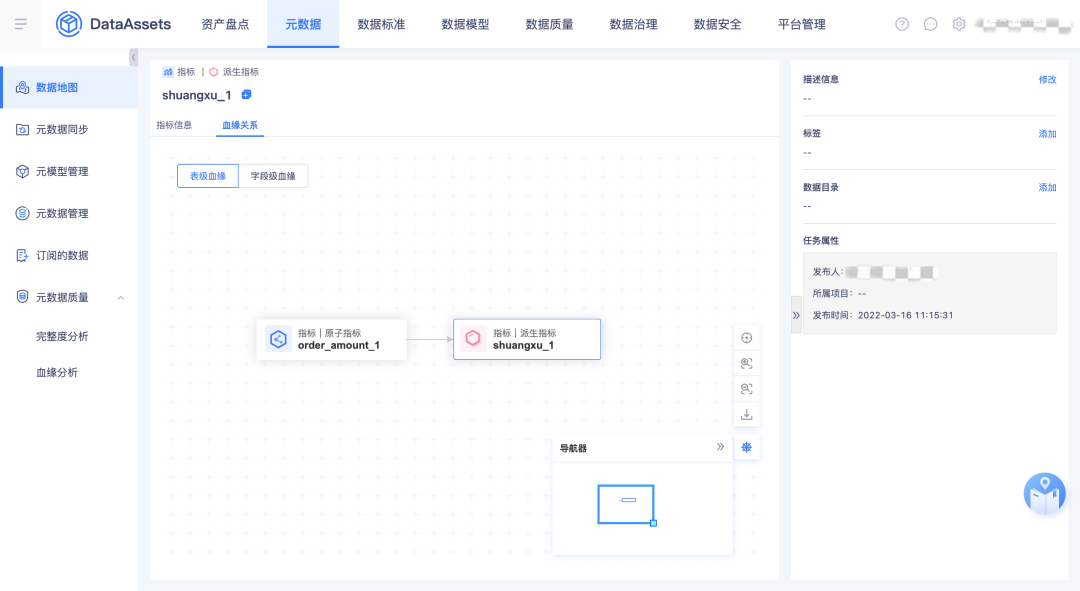
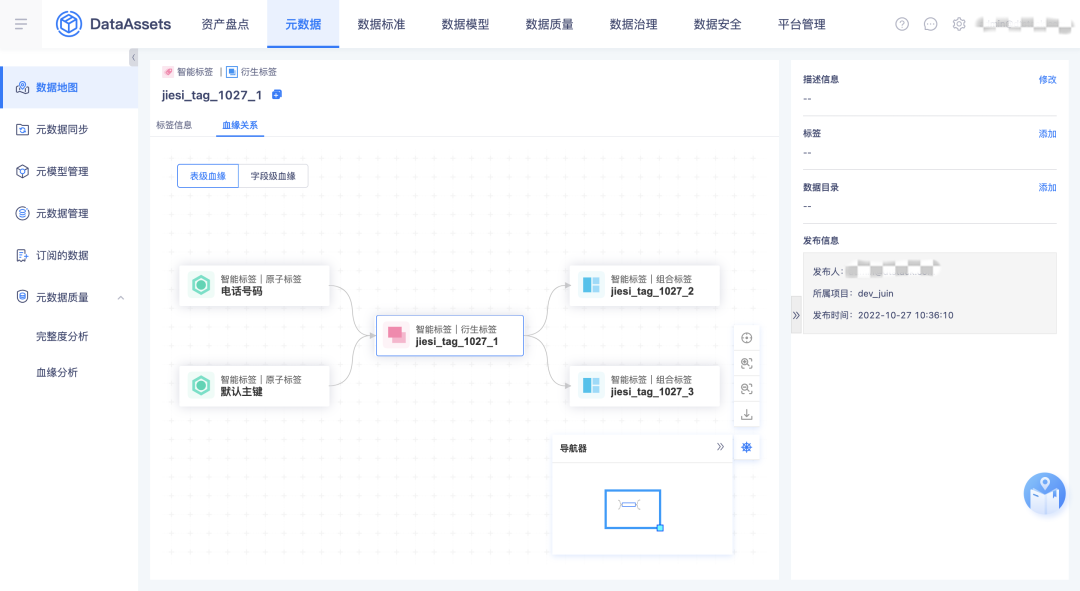
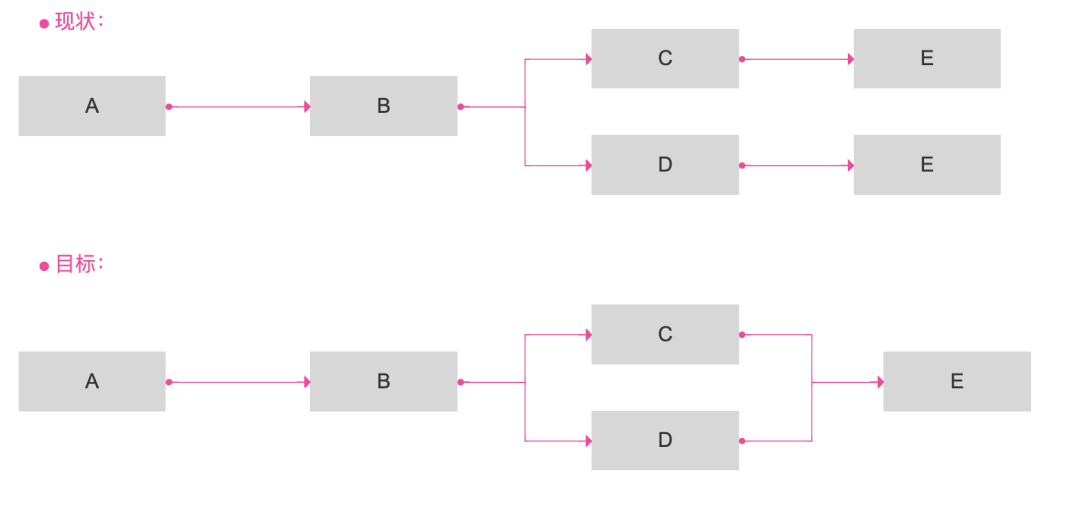
5.血缘优化
• 血缘解析新增 truncate 关键词:当表发生 trancate 数据清空时,表与表之间、表与任务之间的血缘关系需要删除;
• 排除自身到自身的血缘以及重复展示的血缘;
• 解决线段与表相互覆盖问题:直角的血缘流向线段改为弯曲的灰色线;支持拖动;高亮当前覆盖或点击的表的流入和流出。
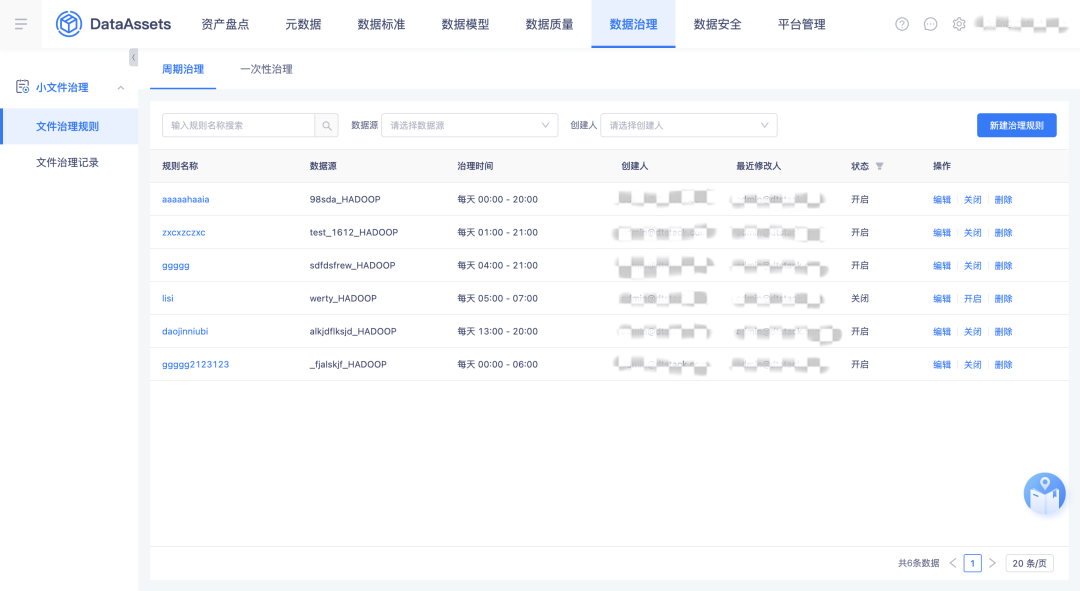
6.数据文件治理
将离线侧的数据文件治理迁移到资产侧的数据治理模块并进行优化和兼容,治理规则包括周期治理和一次性治理。
7.数据文件治理优化调整
• 周期治理「选择项目」改为「选择数据源」,治理范围为可选的meta数据源,下拉框排序按照时间进行倒序;
• 一次性治理「选择项目」改为「选择数据源」,治理范围为可选的 meta 数据源下的 Hive 表;
• 小文件治理的时间如果超过 3 小时则治理失败,超时的时间条件改为可配置项,可由配置文件支持,默认为 3 小时;
• 占用存储的统计目标由一个分区/表改为一个文件。
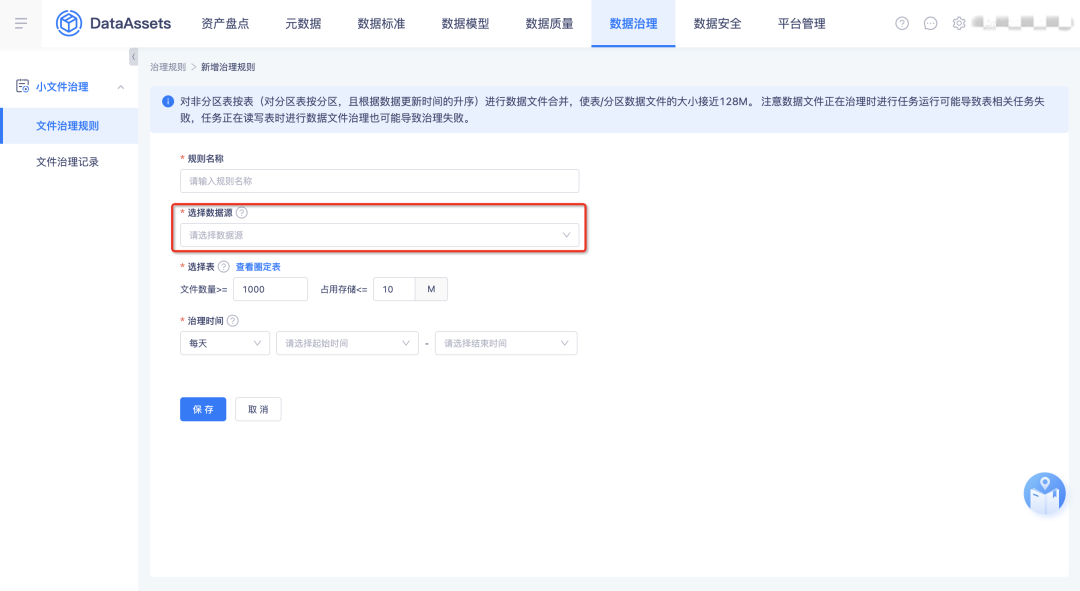
8.元数据同步取消初始化流程
用户痛点:V5.2 合并改造,元数据同步与数据源管理功能拆分之前,原有逻辑是在引入数据源后会先进行初始化,初始化完成后会一次性拿到所有库表名称,进行元数据同步时再去查拿到的库表信息,这将占据较多的资源和存储,并导致存在较多无用数据,如资产盘点加载数据慢等问题。
体验优化说明:取消数据源引入之后的初始化流程,在元数据同步时实时查询数据源内库表信息。
9.元数据中心耦合关系优化
• 增量 SQL 优化:目前元数据中心的定位基础元数据中心,可以支持单独部署,但是现在增量 SQL 无法支持;
• 产品权限优化:某个客户有资产权限,在指标侧调用元数据中心的数据模型没问题,但是客户如果没有资产权限,调用元数据中心的数据模型就会提示没有权限。
10.数据源插件优化
• 同步全部库表参数,实际库表发生变化,不传参数,数据源插件实时去查库表名称;
• binlog 关闭后重新开启:脚本已停止,没有被重新唤起,再次开启时需要自动唤起。
11.功能优化
• 脏数据:管理默认存储实效为 90 天,全局提示对应修改,脏数据管理范围针对当前项目;
• 词根匹配准确率提高:界面上增加的词根、标准需要加入分词器,解决了字段中文名按照分词去匹配,出现某些情况下无法匹配的问题。
客户数据洞察平台
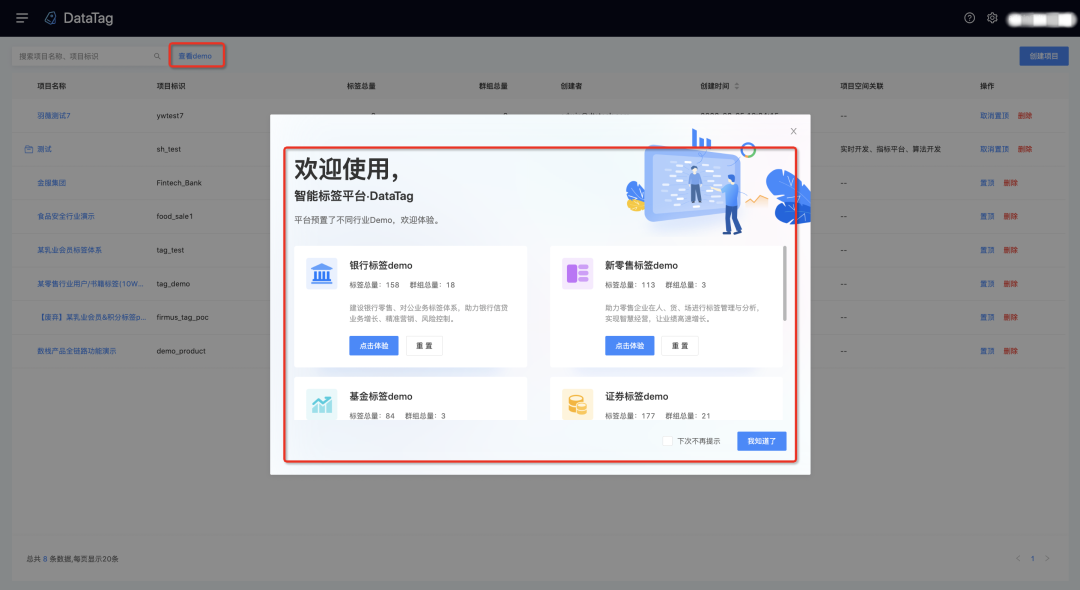
1.证券、银行、保险标签体系 demo 集成
进入标签平台,通过弹窗进行 demo 体验,也可通过平台首页上方查看 demo 按钮进入平台体验 demo。
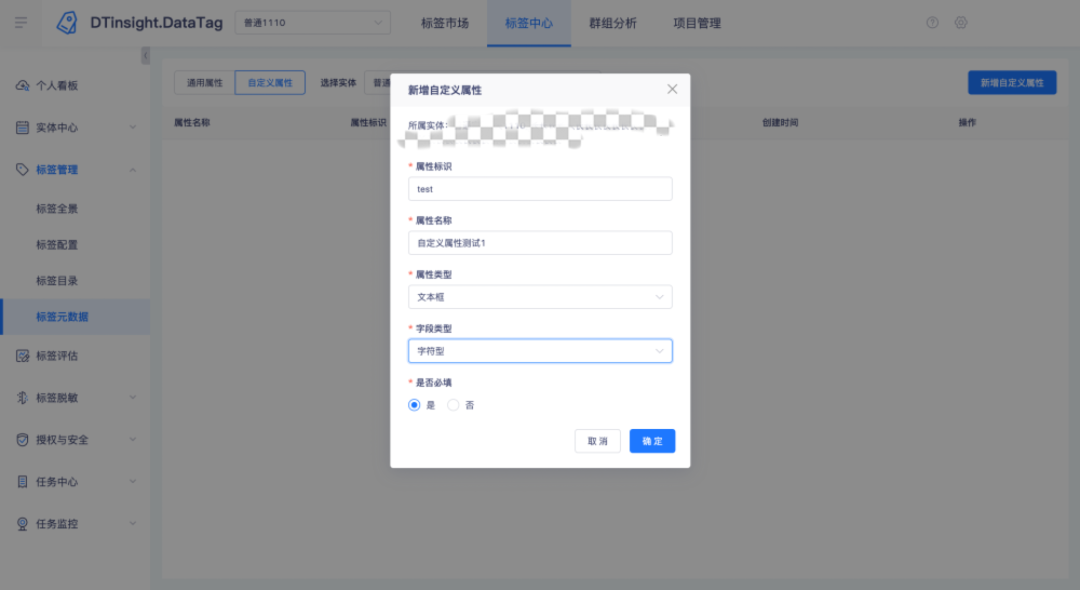
2.【标签管理】支持配置自定义属性
用户痛点:目前标签创建时的信息是固定的,除了一些通用的属性,不同行业客户对标签的元数据信息各有不同,如银行客户有定义标签金融安全等级的需求,但这个属性不适配基金、零售客户,所以要通过标签自定义属性来实现。
新增功能说明:
• 在「标签元数据」页面设置自定义属性,并可在列表页查看通用属性和自定义属性的元数据信息;
• 通用属性中增加标签责任人、业务口径、技术口径字段;
• 自定义的属性用于后续创建标签时进行属性设置。
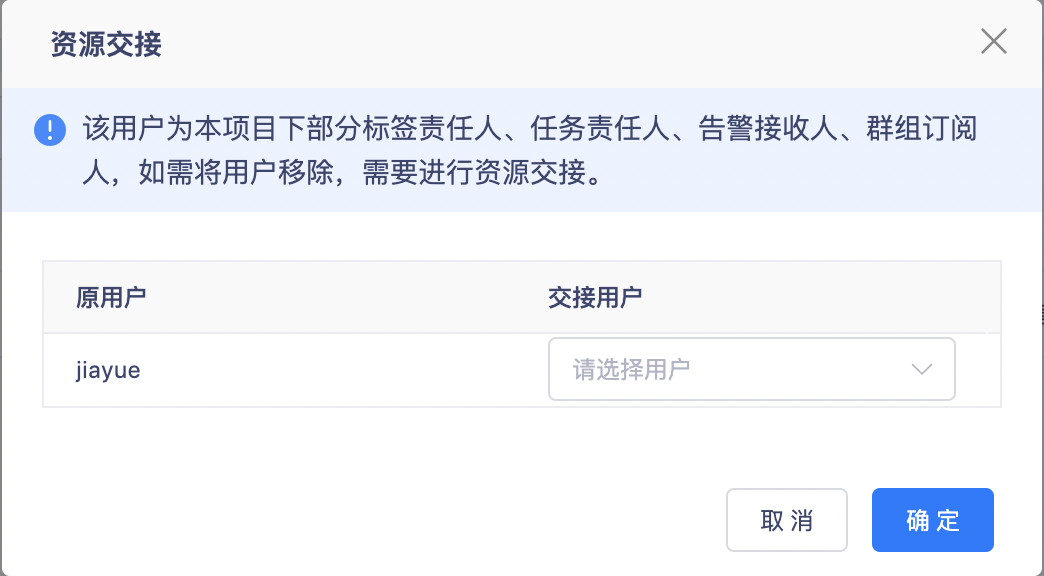
3.【项目管理】移除标签责任人等时指定交接人
【项目管理】移除标签责任人、任务责任人、告警接收人、群组订阅人时指定交接人。
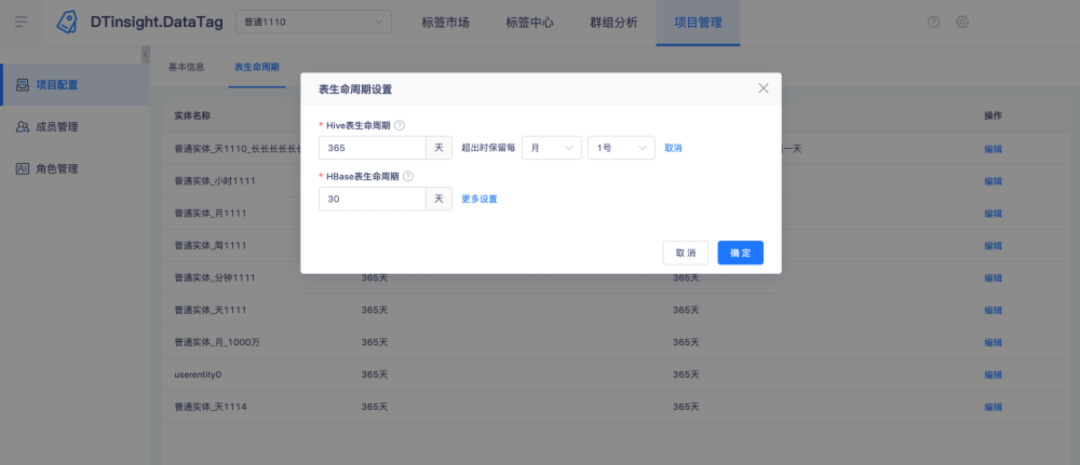
4.【项目管理】Hive 表和 HBase 表支持自定义生命周期
• 支持对标签大宽表进行生命周期设置,超期数据可全部删除,也可保留每个周期的特定时间的数据;
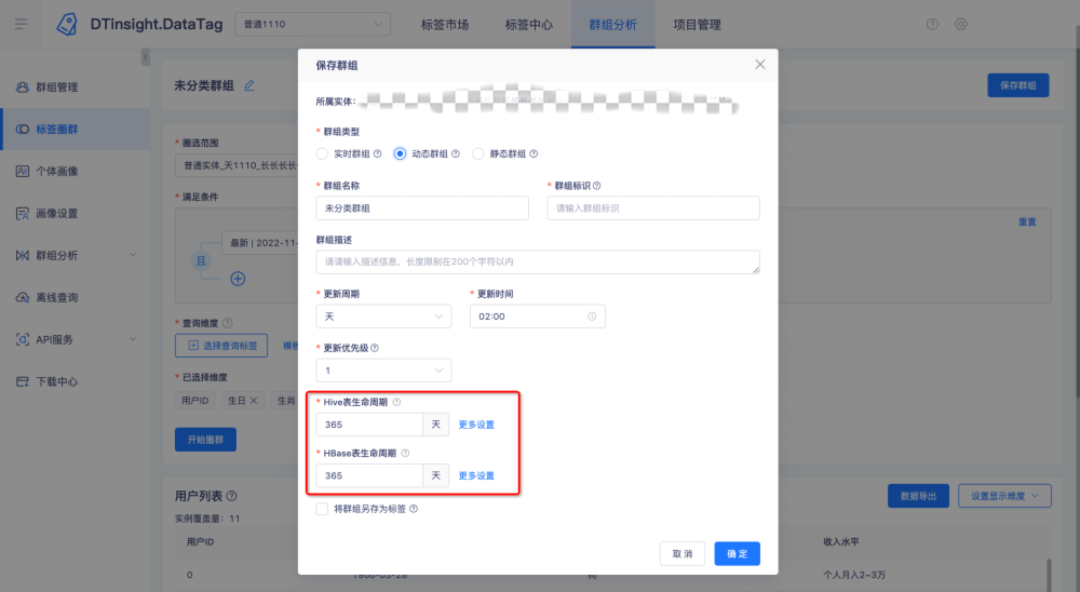
• 保存的标签群组可设置生命周期,超期数据可全部删除,也可保留每个周期的特定时间的数据;
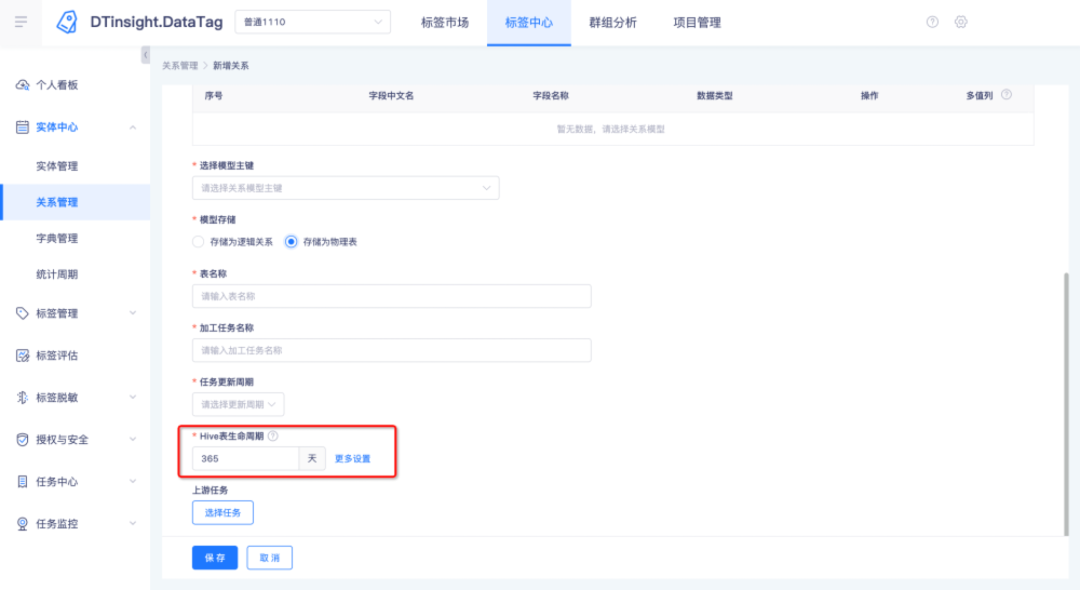
• 存储为物理表的管理科设置生命周期,超期数据可全部删除,也可保留每个周期的特定时间的数据。
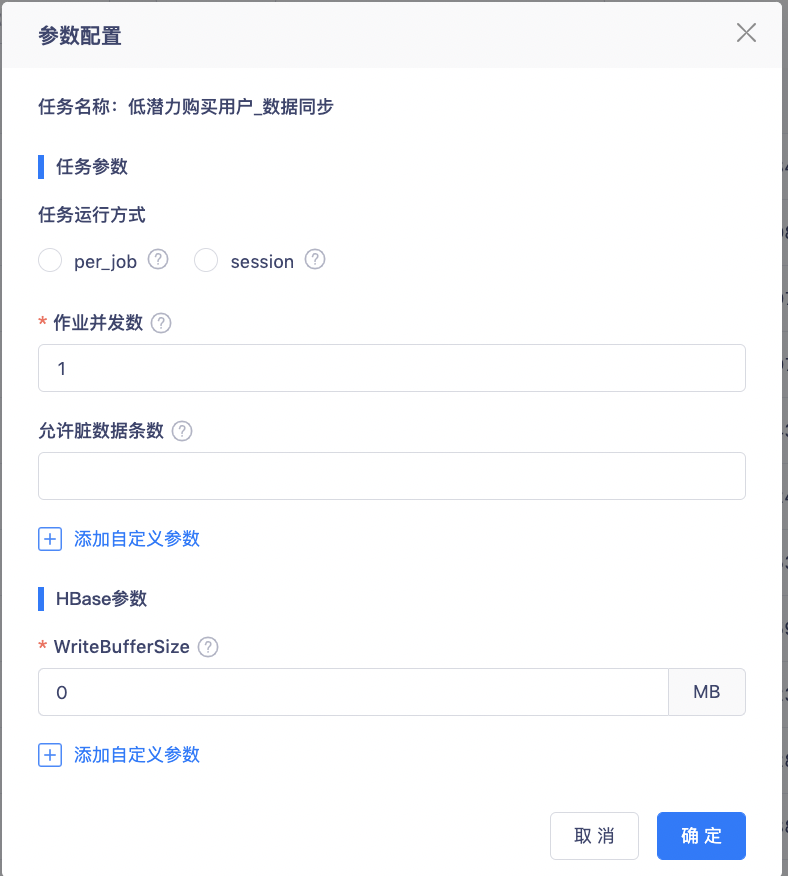
5.数据同步功能优化
• Rowkey 预分区功能优化:hbase 表默认设置预分区,且分区数量 = 30,去除作业并发数对分区计算产生的影响;
• 作业并发数优化:作业并发数输入限制调整为 1-100,满足业务更多的数据同步效率需要;
• 支持设置允许的脏数据条数:当产生的脏数据条数超过设置的阈值时,作业停止同步、置为失败;设置为 0 或空时,表示不允许有脏数据出现。
6.【标签 API】支持不指定业务日期查询标签结果
用户痛点:标签 API 查询数据的过程中,可能存在因数据同步任务尚未完成导致 API 无法查询到指定的最新业务日期数据的情况,此时会造成业务阻塞,为不影响业务正常运行,需要对 Hbase 数据做降级备份处理。
体验优化说明:hbase 中将备份存储一份同步成功的最新业务日期的最近一次同步成功数据。
API 传参时,业务日期调整为非必填项:
(1)指定业务日期,系统将返回对应业务日期的数据;
(2)未指定业务日期,系统将返回备份数据。
7.功能优化
SQL 优化:数字开头的 schema 读取问题优化;
标签目录:标签可以挂在父目录和子目录下;
API 调用:增加 pageNo 字段。
指标管理分析平台
1.【指标管理】支持生命周期设置
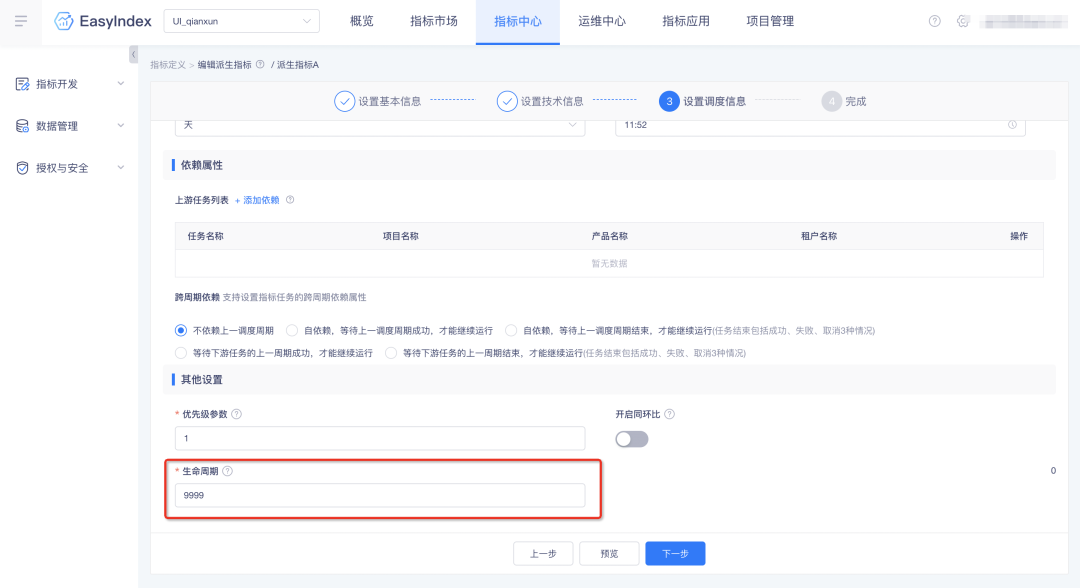
指标hive表支持生命周期设置;
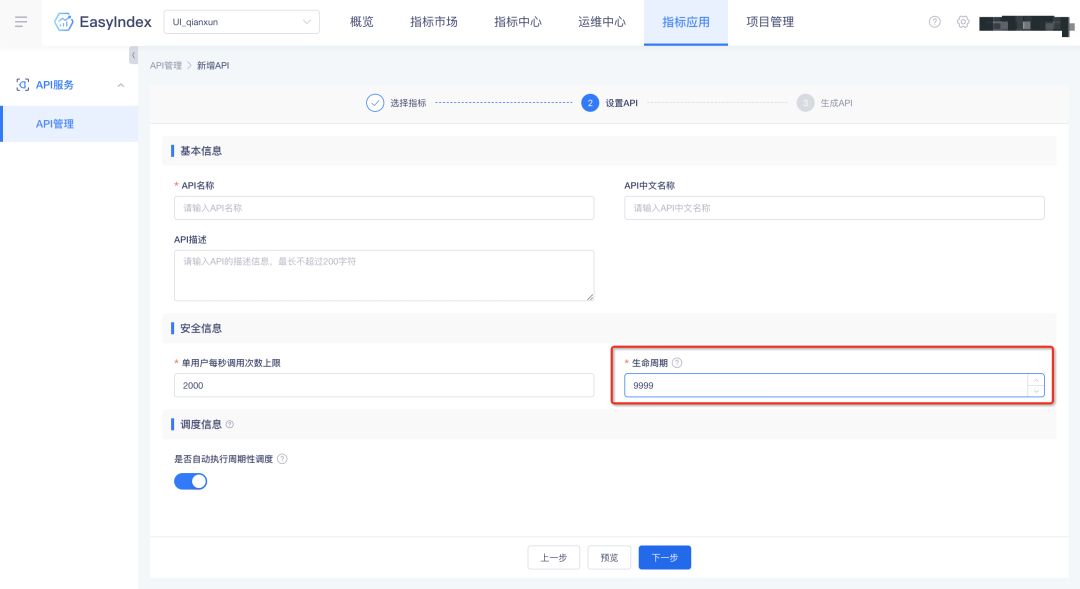
指标 API 支持生命周期设置。
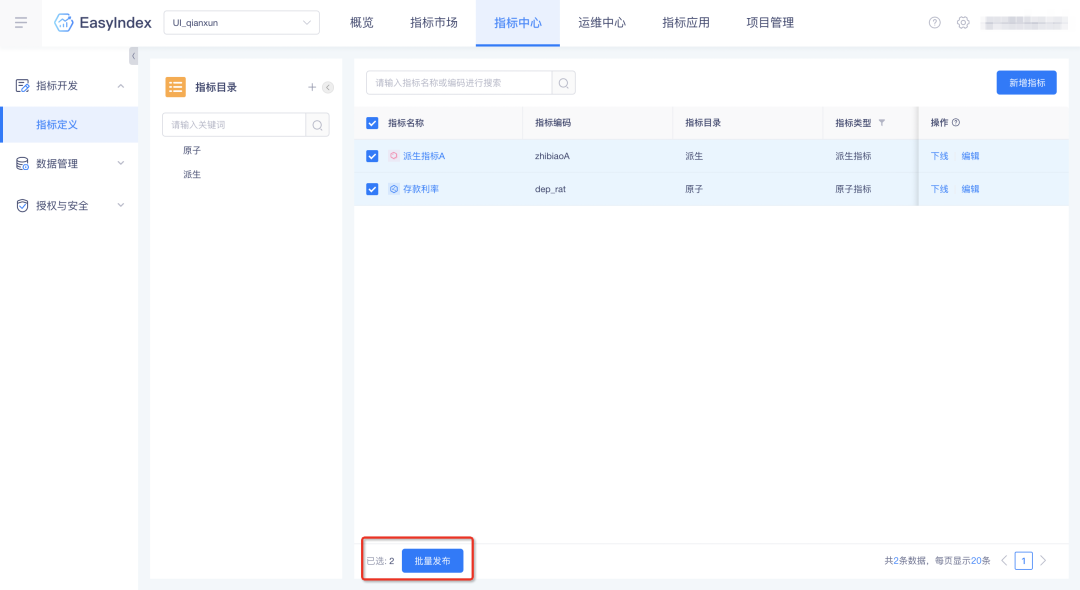
2.【指标管理】支持批量发布
支持批量发布未发布、已下线状态的非自定义SQL指标,发布成功后,可在指标市场中查询到此指标。
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szinfoq
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术 qun」,交流最新开源技术信息,qun 号码:30537511,项目地址:https://github.com/DTStack
版权声明: 本文为 InfoQ 作者【袋鼠云数栈DTinsight】的原创文章。
原文链接:【http://xie.infoq.cn/article/4c02744f4698a282a1724541b】。文章转载请联系作者。

还未添加个人签名 2021-05-06 加入
还未添加个人简介










评论