
go 高并发之路——本地缓存
一、使用场景
试想一个场景,有一个配置服务系统,里面存储着各种各样的配置,比如直播间的直播信息、点赞、签到、红包、带货等等。这些配置信息有两个特点:
1、并发量可能会特别特别大,试想一下,一个几十万人的直播间,可能在直播开始前几秒钟,用户就瞬间涌入进来了,那么这时候我们的系统就得加载这些配置信息。此时请求量就如同洪峰一般,一下子就冲击进入我们的系统。
2、这些配置通常都是只需要读取,在 B 端(管理后台)设置好的,一般直播开始后,修改的频率很低。
那么面对上述的业务场景,假设我们的目标是扛住 3wQPS,你们会选用什么技术架构和方案呢?
1、直接查数据库,例如 MySQL、Doris 之类的关系型数据库。很明显这肯定扛不住,一般关系型数据库能让扛个几千就基本上到头了。
2、使用单机版 Redis。理论上是可以的,腾讯云(下图)和一些 Redis 官方的数据,都说理论上高配置版本的单机 Redis 能抗住 10W+的 QPS。可是理论毕竟是理论,实际上工作中,我使用 Redis 做过许多压测,都表明单机 Redis 上了两万多之后就性能会出现瓶颈,压测就压不上去。(当然,或许是我司的 Redis 还没升到顶配?)

3、使用集群版 Redis,当然是可以解决这个问题,就是成本有点点高咯,公司不差钱完全可以使用这个方案。
4、本地缓存,就是本文的重点,完美地解决这个问题。所谓本地缓存就是将这些所需要获取的数据存储在服务器的内存中。服务器读取本地缓存的速度理论上来说没有上限,看服务器物理机的配置。但其下限就远比 MySQL 和单机 Redis 之类的高好几倍了,一台 2 核 4G 的 Linux 服务器,估计也至少 10W+QPS 起步。我曾经在本地的 Windows 系统做过压测(四核八线程,16G),就达到过 100W+的 QPS。换到同等配置的 Linux 系统上,那就更不用说了。
二、技术方案
既然选用了本地缓存这个策略,那么我们怎么设计这个本地缓存的技术方案呢?
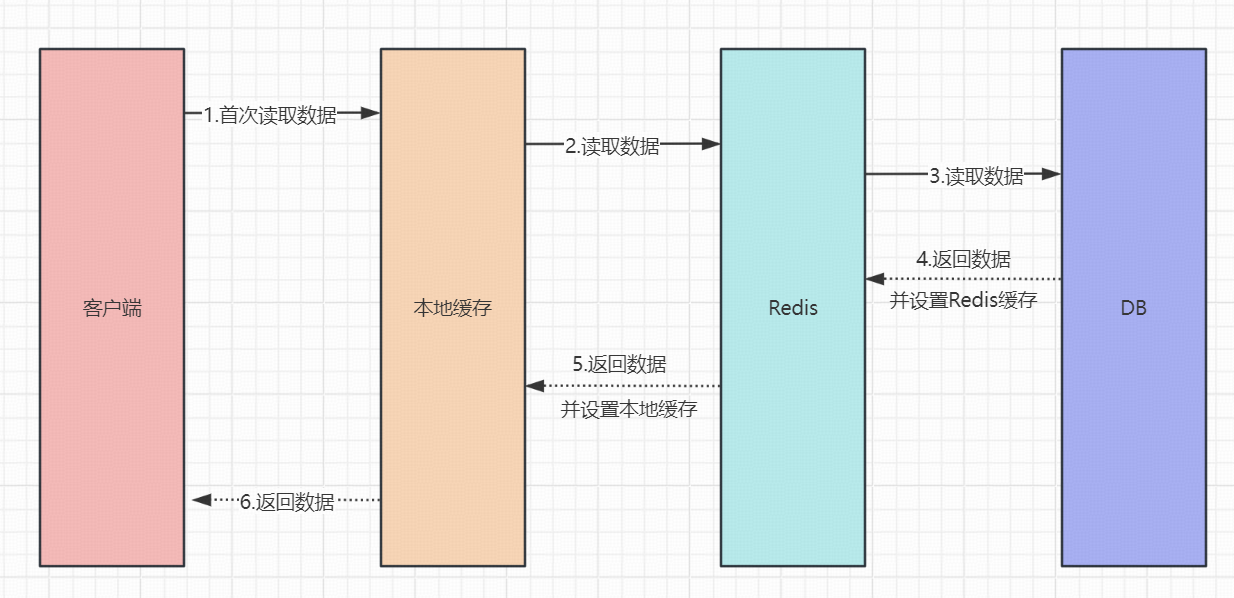
1、如上图所示,我们客户端获取数据首先会读取本地缓存,如果本地缓存没有数据就会读取 Redis 数据,如果 Redis 没有就会读取 DB 数据。
2、需要注意的是,本地缓存和 DB 之间一般还会加入 Redis 这一层缓存。这是因为本地缓存设置好后就无法再更新了(除非重启服务器),而 Redis 缓存我们是可以在 DB 有更改后,随时更新。这个也很好理解,因为 Redis 是有单独的 Redis 服务器,而本地缓存就只能在那台机器上更新和设置,但实际项目中,设置本地缓存的 DB 数据源的机器和使用本地缓存的机器大概率都不在同一个系统中。所以我们本地缓存的时间都设置得很短,大部分都是秒级的,一般不会超过 1 分钟,比如 1 秒、2 秒... 。而 Redis 这个缓存时长明显可以设置长一些,比如半小时、1 小时...。
三、如何更新本地缓存
上面讲了,本地缓存最不好的地方就是更新问题,因为很可能设置本地缓存的 DB 数据源的系统和使用本地缓存的系统不是同一个,无法在 DB 数据更新的时候就同步更新本地缓存。但是实际使用的时候很可能就需要这种场景,就是在更新数据源的时候去更新本地缓存。举个例子:
我们设置配置 A 的 DB 数据源的系统是一个 API 系统,但现在有一个脚本系统,需要根据某个配置 A,去处理 C 端的一些行为数据,判断是否满足该配置 A,然后进行对应的业务处理。好了,现在 C 端的行为数据量是非常庞大的,可以说是海量数据,平均每秒钟有五十万的数据通过 kafka 推送过来。此时我们就必须得用本地缓存存储配置 A 的信息了,才能抗的住这个流量洪峰。但是这是一个脚本系统啊,我们更新配置 A 的 DB 信息是在对应的 API 系统中的。那怎么办呢?
有几个方法:
1、在脚本系统中维护一个脚本,每隔一段时间就去读取 MySQL 的数据,然后更新到本地缓存。但这个得综合评估下时间和 MySQL 的性能,因为要一直扫表。
2、拉取 MySQL 的 binlog 日志,每当数据有变更时,kafka 推送数据到下游。脚本监听 kafka 数据,当收到 kafka 数据是就更新配置 A 的本地缓存。但这个也得注意,因为脚本系统一般会同时起很多个服务,所以得注意有多少个服务就得设置多少个消费者组,因为要保证脚本系统的每个服务都消费到 kafka 对应的 DB 更新数据,进而更新各自机器上的本地缓存。
3、使用 Redis 的发布订阅功能,上游 api 有更新配置信息时就去发布信息,每个脚本服务都去订阅该信息,一有消息就去更新自己机器上的本地缓存。但这也有个弊端,Redis 的发布订阅功能是没有确认机制的,所以可能某个脚本服务没收到信息导致没更新本地缓存,然后就出现 bug 了。demo 如下:
(1)发布者:
(2)订阅者:
4、跟方法 1 类似,只是可以把修改的配置 A 信息推送到 Redis 中,然后脚本去扫描 Redis 信息,有则更新本地缓存。其实就是延迟队列。但这个就得上游的配置 A 增删改都要写入这个 Redis,有时候增删改的口子太多,其实实施起来也比较困难。
如上所述,基本上更新本地缓存没有一个很合适、很高效的方法,只能选取其中一个比较符合自己业务场景的方法。
四、本地缓存常用类库
go 如何使用本地缓存呢?
1、可以自己实现一个本地缓存,一般可以使用 LRU(最近最少使用)算法。下面是自己实现的一个本地缓存的 demo。
该代码中使用 LRU 算法,通过将最新的缓存移动到链表头部(最近使用)来实现这个算法。但也有一些问题,CleanUp 方法需要手动调用去清理过期缓存,并没有定期自动清理的机制。这就意味着使用者可能需要频繁调用 CleanUp,否则过期项可能会在缓存中停留较长时间。代码中也加了锁,可能还会存在并发访问时的数据一致性和性能问题等等。
所以,这种自己实现的 demo 不建议放在生产环境中使用,可能会存在一些小问题。比如,之前我部门写的一个本地缓存类库,就存在一个大 bug:本地缓存的内存空间不能释放,导致内存一直蹭蹭地往上涨。隔好几天内存就飙到 90%,然后我们临时处理方法是:隔好几天就去重启一次脚本...
2、所以呢,我们还是建议去使用开源的类库,至少有许多前辈帮我们踩过坑了,这里推荐几个 star 数比较高的:
(1)go-cache:一个简单的内存缓存库,支持过期和自动清理,适合简单的缓存 key-value 需求。(本人项目中使用比较多,方便简单,推荐)
(2)bigcache:高性能的内存缓存库,适用于大量数据的缓存,其设计旨在减少垃圾回收的压力。
(3)groupcache:Google 开发的一个缓存库,支持分布式缓存和单机缓存。适用于需要高并发和高可用性的场景。
以上,就是个人使用本地缓存的一些经验了。不得不说,这玩意用着是真香,物美价廉,能扛能打。唯一美中不足的就是本地缓存不太好实时去更新,当然这个上面也给出了几个解决方案。
文章转载自:snail_lie

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论