
Redis 数据结构
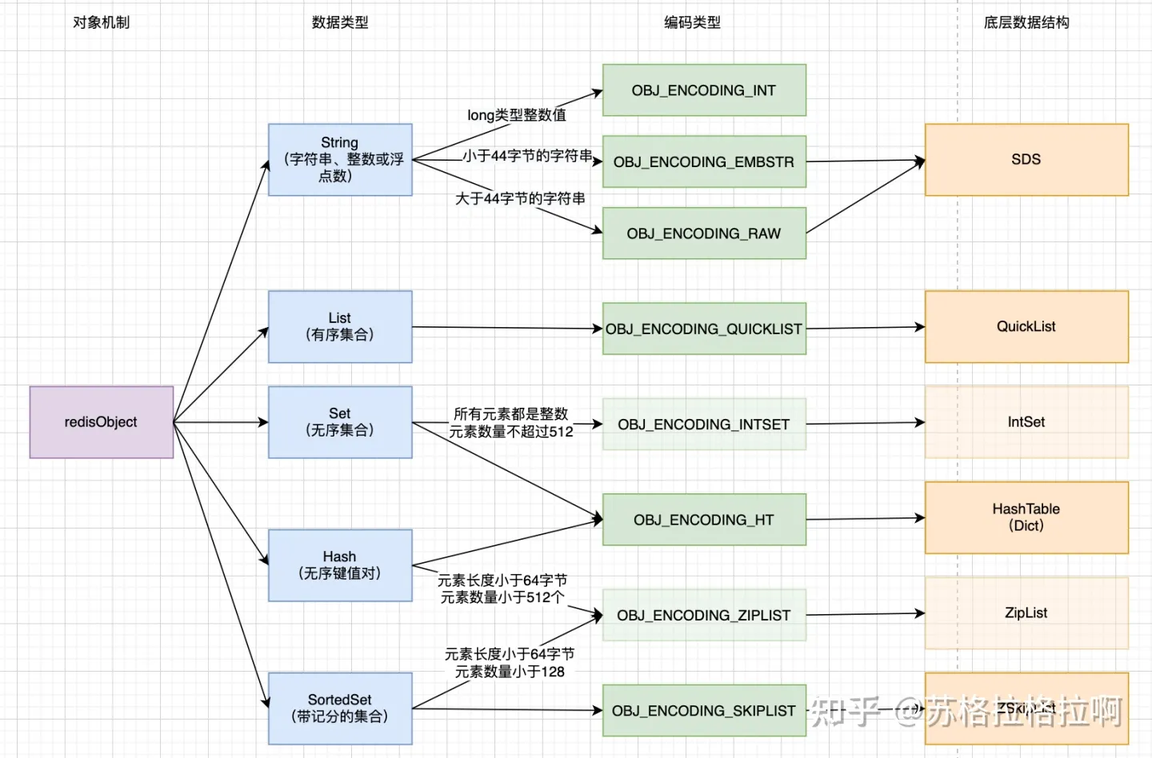
5 种基本数据类型

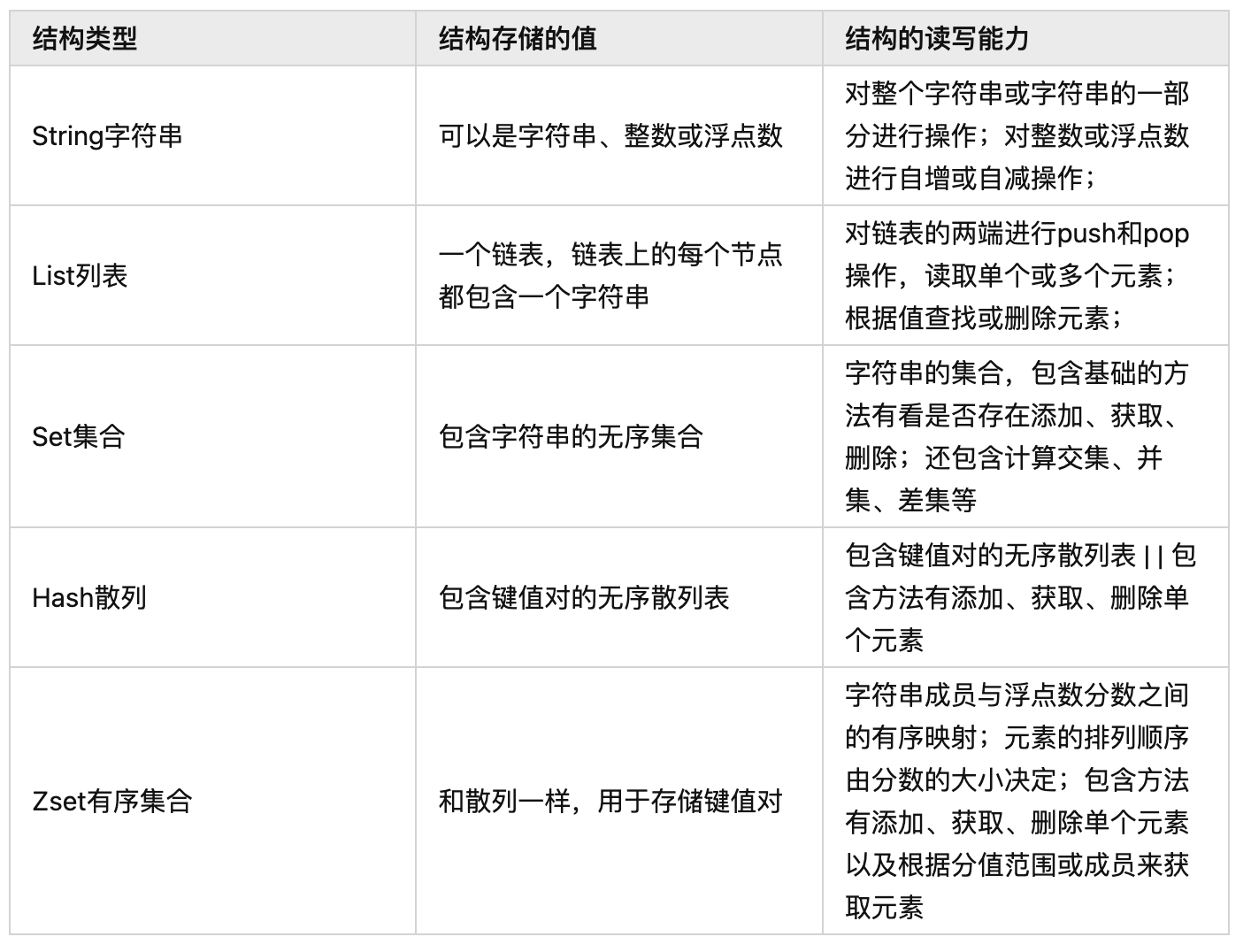
对象机制
Redis 的每种对象其实都由对象结构(redisObject) 与 对应编码的数据结构组合而成,为什么 Redis 要设计 redisObject 对象?
redis 数据为键值类型,不同类型的值所支持的操作不一样(如 LPUSH 和 LLEN 只能用于列表键),相同的操作(如 DEL)对不同的类型数据操作的实现不一样,所以 Redis 必须让每个键都带有类型信息, 使得程序可以检查键的类型, 并为它选择合适的处理方式。在具体的实现上,还需要根据数据类型的不同编码进行多态处理。
数据结构
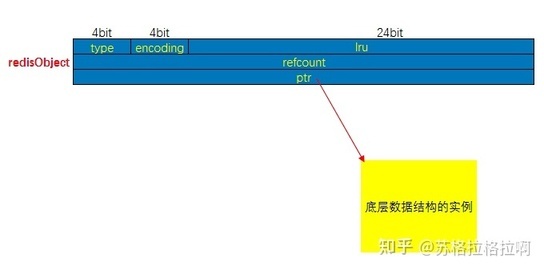
type 字段记录了对象所保存的值的类型
encoding 字段记录了对象所保存的值的编码
底层数据结构
sds
总体概览

头部数据结构
优点:
1.常数复杂度获取字符串长度
2.杜绝缓冲区溢出
C 使用 strcat 函数进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
3.减少修改字符串的内存分配次数
C 语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
而对于 SDS,由于 len 属性和 alloc 属性的存在,对于修改字符串 SDS 实现了空间预分配和惰性空间释放两种策略:
空间预分配 :对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
惰性空间释放 :对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用 alloc 属性将这些字节的数量记录下来,等待后续使用。
4.二进制安全
C 字符串以空字符作为字符串结束的标识,而对于一些包括空字符串的二进制文件,C 字符串无法正确存取;而 SDS 通过 API 处理 buf 里面的元素,以 len 而非空字符串判断是否结束。
5.兼容部分
C 字符串函数 SDS 一样遵从每个字符串都是以空字符串结尾的惯例,这样可以重用 C 语言库 <string.h> 中的一部分函数。
ziplist
整体结构

entry 结构
为什么 ZipList 省内存
普通的数组每个元素占用的内存是一样的且取决于最大的那个元素(很明显它是需要预留空间的);
ziplist 增加 encoding 字段,针对不同的 encoding 来细化存储大小,尽量让每个元素按照实际的内容大小存储。
这时候还需要解决的一个问题是遍历元素时如何定位下一个元素呢?在普通数组中每个元素定长,所以不需要考虑这个问题;但是 ziplist 中每个 data 占据的内存不一样,所以为了解决遍历,需要增加记录上一个元素的 length,所以增加了 prelen 字段。
ziplist 的缺点
ziplist 不预留内存空间, 并且在移除结点后, 也是立即缩容, 每次写操作都会进行内存分配操作.
结点如果扩容, 导致结点占用的内存增长, 并且超过 254 字节的话, 可能会导致链式反应: 其后一个结点的 entry.prevlen 需要从一字节扩容至五字节. 最坏情况下, 第一个结点的扩容, 会导致整个 ziplist 表中的后续所有结点的 entry.prevlen 字段扩容。
quicklist
在 Redis3.2 之前,linkedlist 和 ziplist 两种编码可以进选择切换;在 Redis3.2 之后,统一用 quicklist 来存储列表对象。
quicklist 存储了一个双向列表,每个列表的节点是一个 ziplist,所以实际上 quicklist 就是 linkedlist 和 ziplist 的结合。
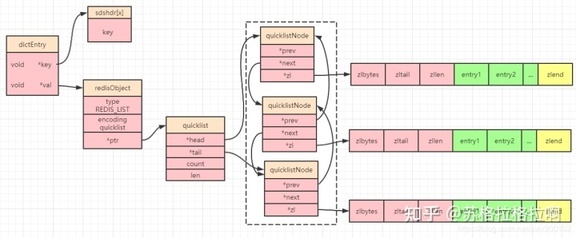
quicklist 同样采用了 linkedlist 的双端列表特性,然后 quicklist 中的每个节点又是一个 ziplist,所以 quicklist 就是综合平衡考虑了空间碎片和读写性能两个维度。使用 quicklist 需要注意以下 2 点:
如果 ziplist 中的 entry 个数过少,极端情况就是只有 1 个 entry,此时就相当于退化成了一个普通的 linkedlist。
如果 ziplist 中的 entry 过多,那么也会导致一次性需要申请的内存空间过大,而且因为 ziplist 本身的就是以时间换空间,所以会过多 entry 也会影响到列表对象的读写性能。
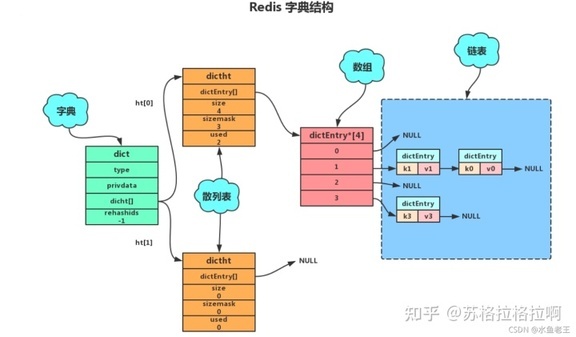
dict
由于 Redis 是单进程单线程模型,为了避免在 hash 扩容以及 rehash 的过程中阻塞服务, dict 结构中的 ht 定义成了一个数组,维护两个 dictht(hashtable) 。 rehashidx 则是在 rehash 过程中被用作 ht[0] 中的 bucket 的索引。 pauserehash 用来标识 rehash 是否暂停。
hash 冲突
链表法(头插)
扩容条件
扩容:当负载因子大于等于 1(没有在执行 BGSAVE 或 BGREWRITEAOF 命令);或当负载因子大于等于 5(在执行 BGSAVE 或 BGREWRITEAOF 命令)
缩容:元素数量与 bucket 数量之比小于一定值(10%),并且此时 bucket 的数量还大于 Redis 服务所允许的最小值(4)
扩容过程
1、为字符 ht[1]哈希表分配空间
扩展:ht[1]的大小为第一个大于等于 ht[0].used*2。
收缩:ht[1]的大小为第一个大于等于 ht[0].used/2 。
2、将所有的 ht[0]上的节点 rehash 到 ht[1]上,重新计算 hash 值和索引,然后放入指定的位置。
3、当 ht[0]全部迁移到了 ht[1]之后,释放 ht[0],将 ht[1]设置为 ht[0]表,并创建新的 ht[1],为下次 rehash 做准备。
渐进式 hash
在元素数量较少时,rehash 会非常快的进行;但是当元素数量达到几百、甚至几个亿时进行 rehash 将会是一个非常耗时的操作。庞大的计算量可能会导致服务器在一段时间内停止服务。
渐进式 rehash 的好处在于它采取分而治之的方式,将 rehash 键值对所需的计算工作均摊到对字典的每个添加、删除、查找和更新操作上,从而避免了集中式 rehash 而带来的庞大计算量。
步骤:
为 ht[1]分配空间,让字典同时持有 ht[0]和 ht[1]两个哈希表。
在字典中维持一个索引计数器变量 rehashidx,并将它的值设置为 0,表示 rehash 工作正式开始。
在 rehash 进行期间,每次对字典执行添加、删除、查找或者更新操作时,程序除 了执行指定的操作以外,还会顺带将 ht[0]哈希表在 rehashidx 索引上的所有键值对 rehash 到 ht[1],当 rehash 工作完成之后,程序将 rehashidx+1(表示下次将 rehash 下一个桶)。
随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被 rehash 至 ht[1],这时程序将 rehashidx 属性的值设为-1,表示 rehash 操作已完成。
intset
结构
encoding 表示编码方式,的取值有三个:INTSET_ENC_INT16, INTSET_ENC_INT32,INTSET_ENC_INT64
length 代表其中存储的整数的个数
contents 指向实际存储数值的连续内存区域, 就是一个数组;整数集合的每个元素都是 contents 数组的一个数组项(item),各个项在数组中按值得大小从小到大有序排序,且数组中不包含任何重复项。(虽然 intset 结构将 contents 属性声明为 int8_t 类型的数组,但实际上 contents 数组并不保存任何 int8_t 类型的值,contents 数组的真正类型取决于 encoding 属性的值)
整数集合升级
当在一个 int16 类型的整数集合中插入一个 int32 类型的值,整个集合的所有元素都会转换成 32 类型。 整个过程有三步:
根据新元素的类型(比如 int32),扩展整数集合底层数组的空间大小,并为新元素分配空间。
将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素放置到正确的位上, 而且在放置元素的过程中, 需要继续维持底层数组的有序性质不变。
最后改变 encoding 的值,length+1。
skiplist
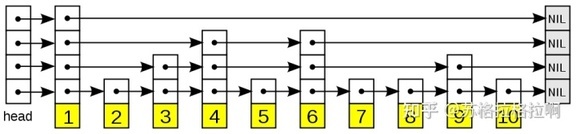
特性
由多层组成,最底层为第 1 层,次底层为第 2 层,以此类推。层数不会超过一个固定的最大值 Lmax。
每层都是一个有头节点的有序链表,第 1 层的链表包含跳表中的所有元素。
如果某个元素在第 k 层出现,那么在第 1~k-1 层也必定都会出现,但会按一定的概率 p 在第 k+1 层出现。
查找
从最顶层链表的头节点开始遍历(以升序跳表为例),如果当前节点的下一个节点包含的值比目标元素值小,则继续向右查找;如果下一个节点的值比目标值大,就转到当前层的下一层去查找。重复向右和向下的操作,直到找到与目标值相等的元素为止。
插入
当按照上述查找流程找到新元素的插入位置之后,首先将其插入第 1 层。
至于是否要插入第 2,3,4...层,就需要用随机数等方法来确定(如抛硬币)。
数据结构
redis 对象与底层结构对应关系
string
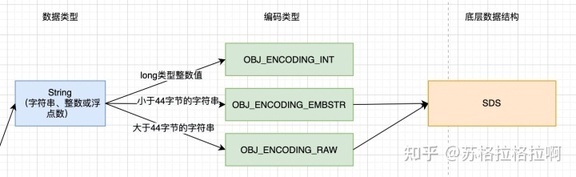
int 编码 :保存的是可以用 long 类型表示的整数值。
embstr 编码 :保存长度小于 44 字节的字符串(redis3.2 版本之前是 39 字节,之后是 44 字节)。
raw 编码 :保存长度大于 44 字节的字符串(redis3.2 版本之前是 39 字节,之后是 44 字节)。
内存模型
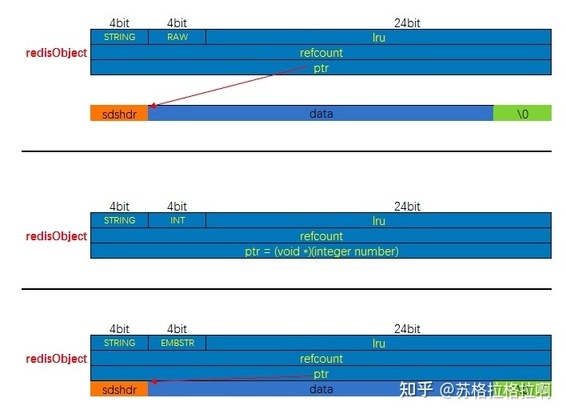
raw 和 embstr 的区别
embstr 的使用只分配一次内存空间(因此 redisObject 和 sds 是连续的),而 raw 需要分配两次内存空间(分别为 redisObject 和 sds 分配空间)。
因此与 raw 相比,embstr 的好处在于创建时少分配一次空间,删除时少释放一次空间,以及对象的所有数据连在一起,寻找方便。
而 embstr 的坏处也很明显,如果字符串的长度增加需要重新分配内存时,整个 redisObject 和 sds 都需要重新分配空间,因此 redis 中的 embstr 实现为只读。
list

(前面已经提到)
在 Redis3.2 之前,linkedlist 和 ziplist 两种编码可以进选择切换;在 Redis3.2 之后,统一用 quicklist 来存储列表对象。
quicklist 存储了一个双向列表,每个列表的节点是一个 ziplist,所以实际上 quicklist 就是 linkedlist 和 ziplist 的结合。
set
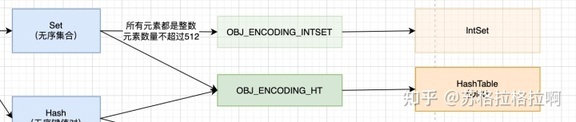
当集合同时满足以下两个条件时,使用 intset 编码:
1、集合对象中所有元素都是整数
2、集合对象所有元素数量不超过 512
内存模型
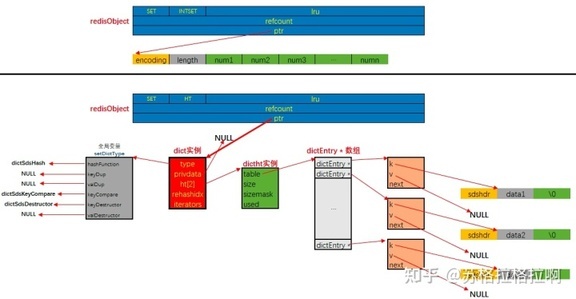
hash

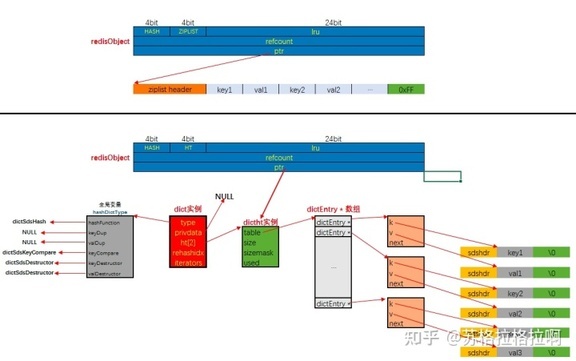
当同时满足下面两个条件时,使用 ziplist(压缩列表)编码:
1、列表保存元素个数小于 512 个
2、每个元素长度小于 64 字节
内存模型
sortedset
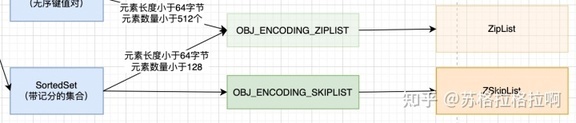
当有序集合对象同时满足以下两个条件时,对象使用 ziplist 编码:
1、保存的元素数量小于 128;
2、保存的所有元素长度都小于 64 字节。
版权声明: 本文为 InfoQ 作者【苏格拉格拉】的原创文章。
原文链接:【http://xie.infoq.cn/article/485be86a540e4de583b1d49a8】。文章转载请联系作者。

还未添加个人签名 2018-08-22 加入
还未添加个人简介








评论