
何以应用启动加速
引子
过去,我们更多追求应用的运行性能,鲜少关注它的启动效率。
在追求业务连续性的当下,永不下线似乎已经成为在线服务的固定标签,相对于漫长的服役生涯,应用的启动阶段就像蹒跚学步时跌跌撞撞迈出的几米,在人生的万里路途中显得有些微不足道。
但是,从一个请求预期开始,到应用能够提供响应,中间的等待时间已经变得越来越不可忽略。一方面,软件框架随着业务复杂度的提升变得日益繁复,依赖增长也带来更高的加载开销,集群规模膨胀又进一步加剧滚动发布的整体时长;另一方面,分工集中和效率解放催生了 Serverless 这类让开发者更专注于业务逻辑的云计算模型,在成本与性能的权衡下,也对应用的启动速度提出了更高的要求。
冷启阶段加速
应用从完全关闭到运行状态的过程称为冷启动,大致可以分为准备、加载和运行三个阶段,如下图不同颜色所示。其中准备和加载阶段耗时,就是前面提到的不容忽视的等待开销,优化冷启影响可以从降低冷启概率和加快启动速度两方面着手。

启动预热
降低冷启概率最理想的情况是应用时刻处于运行状态,能够随时响应请求,但热调用一般也要求热实例,实际上是以空间换时间的做法,牺牲了一定的资源利用率。自然而然地,为了减少饱和式集群规模的资源浪费,我们希望找到一种方法,能够恰好维持承接请求流量的实例数量,这就是弹性伸缩的思路。
对冷启来说主要是预热,关键在于判断什么时候该提前创建实例,一般有几类触发点:一是根据负载水位触发,适用于持续有请求进入且对资源相对敏感的业务,但较难处理长期空闲的情况;再是根据预估请求触发,适用于有一定流量规律的业务,需要适度冗余,或使用更精确的时序预测算法;另外也可根据前置处理触发,例如在 HTTPS 握手或 ACL 认证时拉起实例,属于抢跑策略,还是受限于应用的启动速度。
镜像分发
加快启动速度在上面各个阶段各有不同做法,应用镜像获取的完整周期应该包含镜像构建到下载的过程,只不过我们常将代码变成制品的过程归到更早之前的集成阶段。
如果实在有提交代码片段就要快速运行的需求,除了并行构建技术外,还可以通过数据外挂的方式,在后面的应用数据传输和应用代码加载阶段进行加速。
所以,镜像的快速就绪就像一个典型的内容分发场景,那么压缩算法、内容切片和多级缓存等经典方案同样适用于减轻镜像的传输压力,以及实现快速分发和就近获取。
环境准备
从大的范围来看,应用的运行时环境还包括底层资源,例如主机、磁盘、VPC 或 K8s 集群等等,但这更多是属于资源调度的阶段。一般来说,底层资源的弹性伸缩成本比起单纯的应用实例增减高出许多,如果也苛刻地要求从无到有实时构建,难度似乎不可同日而语,这个阶段的弹性效率更多体现在资源的分配绑定和回收解绑上面。
目前最常见是容器运行时环境,相比于传统 VM 动辄数十秒到数分钟的创建时间,容器的启动速度和运行时开销更小。对于常规业务来说,在不含镜像下载的情况下,能降到数秒的容器启动耗时已经近乎可以忽略,但对于要求即时反馈的 Serverless 平台,对函数实例沙盒环境的构建效率要更吹毛求疵一些。
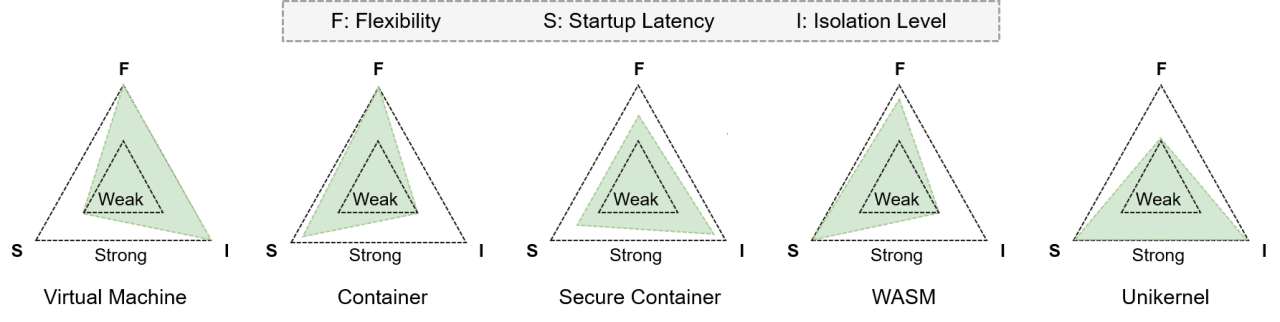
在优化速度方面,缓存总是放诸四海皆准的万金油,另外就是由重到轻的裁剪。对于传统容器,裁剪一些不必要的启动项,比方说使用轻量的基础镜像,在一定程度上能够提升启动效率。
安全容器是比较特殊的一项,作为在容器基础上增加安全隔离机制的技术,很适合 Serverless 平台下多租户高密度的安全部署需求,它的基本模式是增加分层拦截,通过多一层微虚拟机或独立内核实现强隔离和有限调用,正常来说这会带来性能损失,增大启动和运行开销。不过,根据主流安全容器项目的数据,如 Kata Containers 和 gVisor,通过在冷启动方面做的大量优化,已经达到毫秒级别的启动延迟。
数据传输
提升数据传输效率的最好方法是不要传输,其次是减少拷贝。借助网络进行跨节点数据、代码或者状态传输是一个较为耗时的操作,尤其是在 Serverless 平台大量实例并发创建的场景,远程容器初始化也进一步加剧这个问题。
RDMA(Remote Direct Memory Access,远程直接内存访问)技术通过允许用户态的应用程序直接读取和写入远程内存,无需 CPU 介入多次拷贝,从而实现快速远程内存读取和跨节点容器间的数据传输,由于涉及到硬件和软件的协同工作,因此在实施时需要对相关设备和协议有深入的了解,在建设成本和管理灵活性上要求较高。
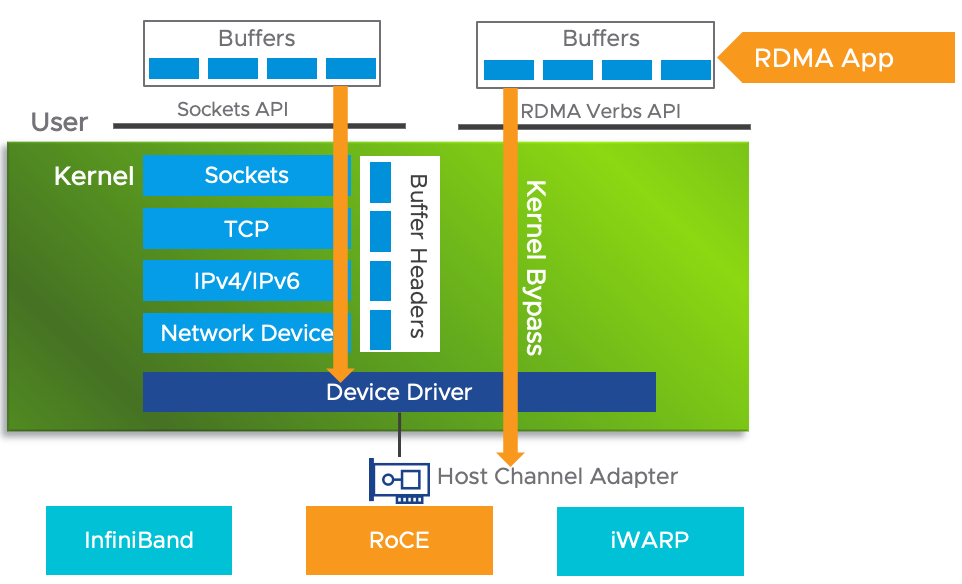
更具体地,RDMA 最初是在 InfiniBand 传输网络上实现的,IB 架构拥有极好的性能,但是其不仅要求在服务器上安装专门的 InfiniBand 网卡,还需要专门的交换机硬件,成本十分昂贵。业界广泛使用的还是经典的 Ethernet,为了复用现有的以太网,同时获得 InfiniBand 强大的性能,IBTA 组织推出了 RoCE(RDMA over Converged Ethernet)。RoCE 支持在以太网上承载 IB 协议,这样一来,仅需要在服务器上安装支持 RoCE 的网卡,而在交换机和路由器仍然使用标准的以太网基础设施
Java 启动加速
前面这么大费周章都是为了给应用搭台唱戏,但到现在应用还是没有粉墨登场。一个角儿登台表演,总是要先摆弄身段起势,然后才缓缓开腔念白。
JVM 初始化
我们来看 Java 应用的一场演出,首先起势,摆了虚拟机初始化(VM init)和应用初始化(App init)两套动作,再慢慢开口暖嗓,进入应用初活跃过程(App active warmup),然后渐入佳境,来到应用稳定运行期(App active steady),最后收尾(Shutdown)谢幕离场。
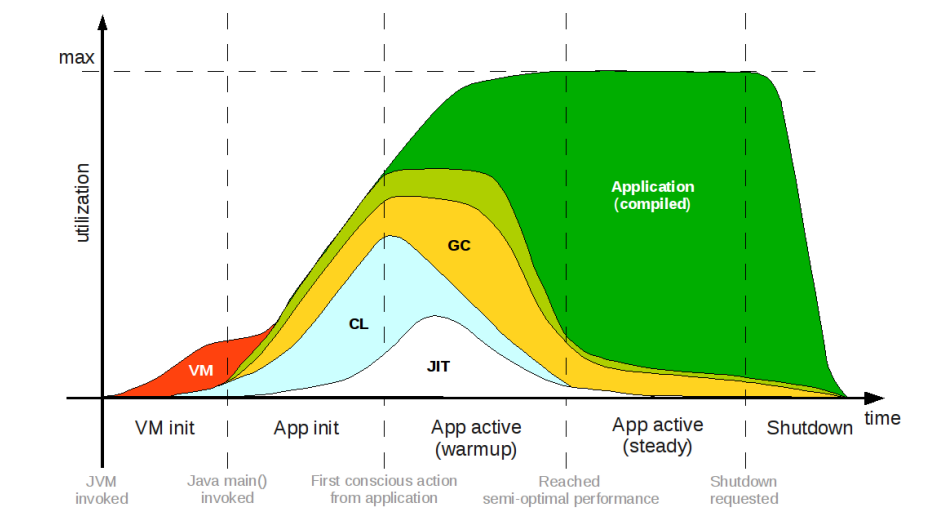
从图中明显可以看到,虚拟机启动(VM,图中红色)和类加载(CL,图中蓝色)是冷启动的主要耗时来源。
其中 JVM 的加载是 Java 应用不可回避的成本,除非更换成支持特定场景的轻量虚拟机实现,不过相对于复杂业务代码引入的后续初始化耗时,虚拟机的加载实际近乎不可感知,大家可以对比简单 Java 应用与成熟商业框架的运行体感,也许有所体会。
对于传统的 JVM 来说,升级更高版本的 JDK 或许包含某些性能优化的改进,另外调整启动参数也可能有所帮助,例如设置合理的堆大小,以减轻初始内存分配开销。
类加载优化
正如抛开剂量讨论毒性的谬误,不提类的数量只讲类加载耗时也是不合情理的。
从 J2EE 规范开始,EJB(Enterprise Java Beans)定义了企业级开发所需要的安全、IoC、AOP、事务、并发等能力,设计极度复杂,随着互联网的兴起,EJB 逐渐被更加轻量和免费的 Spring 框架取代,Spring 成了 Java 企业开发的事实标准。
但 Spring 毕竟还是个企业级应用框架,受 J2EE 影响深远,充斥着大量的可配置和初始化逻辑,以及复杂的设计模式来支撑这种灵活性,随之而来的成本是,一个简单的 spring-boot-web 的 HelloWorld 应用,启动依赖的 class 文件数量可能超过 7000 个。
鱼和熊掌不可兼得,就像 Serverless 提供给业务的便利性,食物不会主动跑到你的桌上,一次美好的就餐体验是以前台忙碌的侍者和后厨轰鸣的炉火为代价的。
查找加速
说类加载慢,与它的过程繁多有相当关系。一个类的生命周期一般包括加载、验证、准备、解析、初始化、使用和卸载七个阶段,在使用前就有五件事情要做,这还不包括加载前的寻找定位过程。
Jar 文件本质上是包含一组 class 文件且在 META-INF 目录下存放元信息的 Zip 压缩包。当需要加载类时,类加载器通常是按扫描的方式寻找指定类的,首先顺序遍历 classpath 下的 Jar 包集合,其次再抽取单个类文件,直到匹配目标为止。
这类无序查找问题一般可以通过索引的方式进行优化,在 JDK1.3 版本引入了 JarIndex 技术,通过在 META-INF 目录下生成 INDEX.LIST 文件,在加载根 Jar 文件时能据此构造一个哈希表,减少后续扫描遍历的开销。虽然在加载大量类的情况下有潜在的性能优势,但这项有些古老的技术基本已经失去了可行性,一方面缺少有保障的索引文件生成方式,另一方面只有 URLClassloader 支持,需要自定义类加载器,尤其是现代应用框架大多都有自定义的 Jar 包结构和类加载器的情况下,这些问题显得更加严峻。
数据复用
很多时候效率是灵活性的牺牲品,过往 Java 提供的动态特性,是它从众多编程语言中杀出血路的重要武器,同时也是现在性能优化的掣肘。颠覆重来显得过犹不及,一个基本方向是把不变的东西沉淀下来,减少无谓的重复。
通常情况下,同一个类多次解析的生成结果是不变的,AppCDS(Application Class Data Sharing)通过共享类的元数据来减少 JVM 的启动时间和内存消耗。如下图所示的 Java 对象内存 layout,Klass*指向了描述对象类型的数据结构 InstanceKlass,这个数据结构是通过运行时解析 class 文件获得的,首先将它导出到 Shared Archive 文件中,下次运行时可以使用内存映射文件的方式快速读取,省略解析的过程。
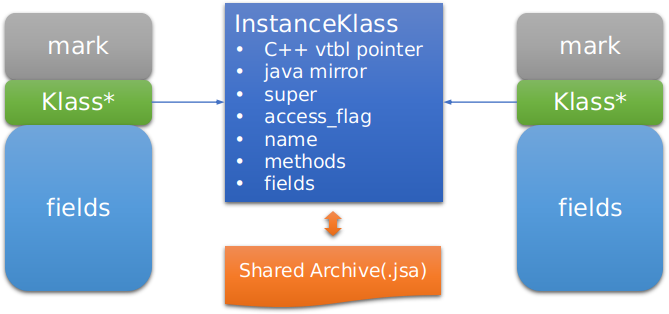
由于 Java 的类对象实际是由类和加载器共同决定的,对于系统类可以方便地通过类标识进行快速匹配,但业务自定义类无法简单辨别类加载器的身份,因此仍需要通过自定义类加载器扫描 Jar 包,通过标识和校验和配对后才能返回 InstanceKlass。
静态编译
静态编译是另外一种优化 Java 应用启动效率的方法,通常提前生成可执行文件,允许 Java 应用程序在没有 JVM 的情况下直接执行,从而提高启动速度。
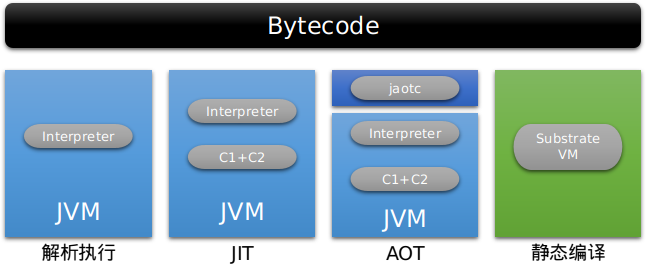
Java 编译模式的发展有它必然的一面,最初依靠解释器无需编译实时执行,不过性能太差,就引入了 JIT(Just In Time)实时编译技术,能将高频函数编译成性能更好的机器码,但编译器开销过高(见前图白色部分),又再引入 AOT(Ahead Of Time)编译,提前编译部分代码,不过 AOT 缺乏应用的运行时环境,无法做到像 JIT 那样收集运行时数据对代码做重复优化,可能对运行速度起反作用。
目前做得比较好的是 Graal VM,静态编译框架和运行时由 Substrate VM 子项目负责,兼容 OpenJDK 运行时实现,提供了原生镜像程序运行时的异常处理、同步调度、线程管理、内存管理等功能,可将 Java 程序静态编译为可执行文件或共享库文件 Native Image。
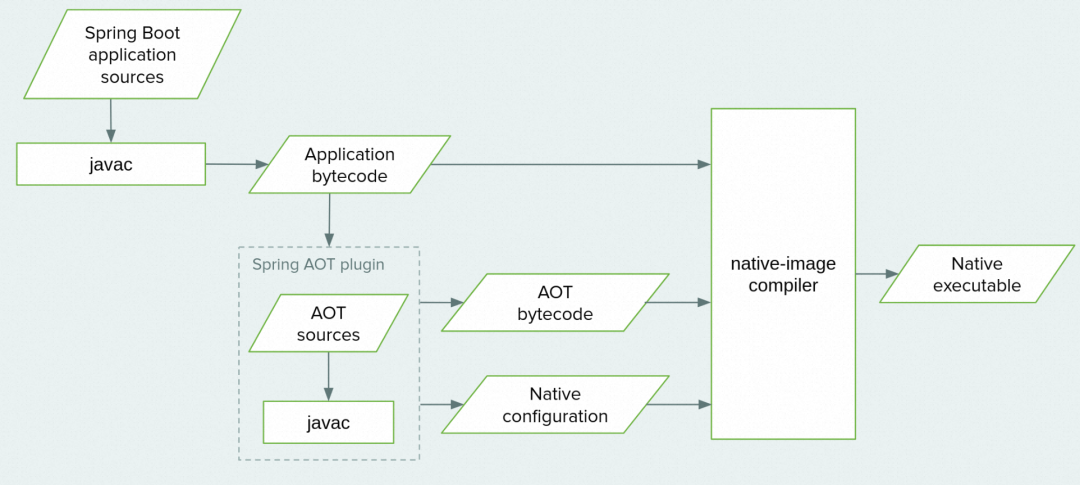
由于静态分析的局限性,静态编译无法覆盖 Java 中的反射、动态代理、JNI 调用等动态特性,这也造成了很多 Java 框架因为大量使用上述特性,难以直接基于 Substrate VM 完成对自身所有代码的静态分析,需要通过额外的外部配置来解决静态分析本身的不足。
例如 Spring 社区因此开发了 AOT Engine 来帮助解决 Spring 项目基于 Substrate VM 完成静态编译的问题。
版权声明: 本文为 InfoQ 作者【陈一之】的原创文章。
原文链接:【http://xie.infoq.cn/article/464cd8cc1af5108ec3ff90709】。文章转载请联系作者。

靡不有初,鲜克有终 2017-10-19 加入
让时间流逝












评论