前言
本文是《ShardingSphere5.x 分库分表原理与实战》系列的第五篇文章,我们一起梳理下ShardingSphere框架中的核心部分分片策略和分片算法,其内部针为我们提供了多种分片策略和分片算法,来应对不同的业务场景,本着拿来即用的原则。
这次将详细介绍如何在ShardingSphere-jdbc中实战 5 种分片策略和 12 种分片算法,自定义分片算法,比较它们的应用场景以及优劣。
全部 demo 案例 GitHub 地址:https://github.com/chengxy-nds/Springboot-Notebook/tree/master/shardingsphere101/shardingsphere-algorithms
分片策略
分片策略是分片键和分片算法的组合策略,真正用于实现数据分片操作的是分片键与相应的分片算法。在分片策略中,分片键确定了数据的拆分依据,分片算法则决定了如何对分片键值运算,将数据路由到哪个物理分片中。
由于分片算法的独立性,使得分片策略具有更大的灵活性和可扩展性。这意味着可以根据具体需求选择不同的分片算法,或者开发自定义的分片算法,以适应各种不同的分片场景。在分表和分库时使用分片策略和分片算法的方式是一致的。
注意:如果在某种分片策略中使用了不受支持的 SQL 操作符,比如 MYSQL 某些函数等,那么系统将无视分片策略,进行全库表路由操作。这个在使用时要慎重!
ShardingSphere对外提供了standard、complex、hint、inline、none5 种分片策略。不同的分片策略可以搭配使用不同的分片算法,这样可以灵活的应对复杂业务场景。
标准分片策略
标准分片策略(standard)适用于具有单一分片键的标准分片场景。该策略支持精确分片,即在 SQL 中包含=、in操作符,以及范围分片,包括BETWEEN AND、>、<、>=、<=等范围操作符。
该策略下有两个属性,分片字段shardingColumn和分片算法名shardingAlgorithmName。
spring: shardingsphere: rules: sharding: tables: t_order: # 逻辑表名称 # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${1..10} # 分库策略 databaseStrategy: # 分库策略 standard: # 用于单分片键的标准分片场景 shardingColumn: order_id # 分片列名称 shardingAlgorithmName: # 分片算法名称 tableStrategy: # 分表策略,同分库策略
复制代码
行表达式分片策略
行表达式分片策略(inline)适用于具有单一分片键的简单分片场景,支持 SQL 语句中=和in操作符。
它的配置相当简洁,该分片策略支持在配置属性algorithm-expression中书写Groovy表达式,用来定义对分片健的运算逻辑,无需单独定义分片算法了。
spring: shardingsphere: rules: sharding: tables: t_order: # 逻辑表名称 # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${1..10} # 分库策略 databaseStrategy: # 分库策略 inline: # 行表达式类型分片策略 algorithm-expression: db$->{order_id % 2} Groovy表达式 tableStrategy: # 分表策略,同分库策略
复制代码
复合分片策略
复合分片策略(complex)适用于多个分片键的复杂分片场景,属性shardingColumns中多个分片健以逗号分隔。支持 SQL 语句中有>、>=、<=、<、=、IN 和 BETWEEN AND 等操作符。
比如:我们希望通过user_id和order_id等多个字段共同运算得出数据路由到具体哪个分片中,就可以应用该策略。
spring: shardingsphere: rules: sharding: tables: t_order: # 逻辑表名称 # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${1..10} # 分库策略 databaseStrategy: # 分库策略 complex: # 用于多分片键的复合分片场景 shardingColumns: order_id,user_id # 分片列名称,多个列以逗号分隔 shardingAlgorithmName: # 分片算法名称 tableStrategy: # 分表策略,同分库策略
复制代码
Hint 分片策略
Hint 强制分片策略相比于其他几种分片策略稍有不同,该策略无需配置分片健,由外部指定分库和分表的信息,可以让 SQL 在指定的分库、分表中执行。
使用场景:
比如,我们希望用user_id做分片健进行路由订单数据,但是t_order表中也没user_id这个字段啊,这时可以通过Hint API手动指定分片库、表等信息,强制让数据插入指定的位置。
spring: shardingsphere: rules: sharding: tables: t_order: # 逻辑表名称 # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${1..10} # 分库策略 databaseStrategy: # 分库策略 hint: # Hint 分片策略 shardingAlgorithmName: # 分片算法名称 tableStrategy: # 分表策略,同分库策略
复制代码
不分片策略
不分片策略比较好理解,设置了不分片策略,那么对逻辑表的所有操作将会执行全库表路由。
spring: shardingsphere: rules: sharding: tables: t_order: # 逻辑表名称 # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${1..10} # 分库策略 databaseStrategy: # 分库策略 none: # 不分片 tableStrategy: # 分表策略,同分库策略
复制代码
分片算法
ShardingSphere 内置了多种分片算法,按照类型可以划分为自动分片算法、标准分片算法、复合分片算法和 Hint 分片算法,能够满足我们绝大多数业务场景的需求。
此外,考虑到业务场景的复杂性,内置算法也提供了自定义分片算法的方式,我们可以通过编写 Java 代码来完成复杂的分片逻辑。下边逐个算法实践一下,看看每种算法的实际执行效果。
开始前,我要吐槽下官方文档,对于算法这种至关重要的内容,解释描述的过于潦草,对于新手入门不友好,学习成本偏高啊
准备工作
给逻辑表配置完算法后,先执行创建表的 SQL,这样就可以依据你的算法在 db 内快速生成分片表,所以不要总是问我要表结构了,哈哈哈。如果有不明白的小伙伴可以看我上一篇对于autoTable的介绍 分库分表如何管理不同实例中几万张分片表?。
自动分片算法
1、MOD
取模分片算法是内置的一种比较简单的算法,定义算法时类型MOD,表达式大致(分片健/数据库实例) % sharding-count,它只有一个 props 属性sharding-count代表分片表的数量。
这个 sharding-count 数量使用时有点小坑,比如db0和db1都有分片表t_order_1,那么实际上数量只能算一个。YML核心配置如下:
spring: shardingsphere: rules: sharding: # 自动分片表规则配置 auto-tables: t_order: actual-data-sources: db$->{0..1} sharding-strategy: standard: sharding-column: order_date sharding-algorithm-name: t_order_table_mod # 分片算法定义 sharding-algorithms: t_order_table_mod: type: MOD # 取模分片算法 props: # 指定分片数量 sharding-count: 6 tables: t_order: # 逻辑表名称 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: .... # 分表策略 table-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_table_mod
复制代码
2、HASH_MOD
哈希取模分片算法是内置取模分片算法的一个升级版本,定义算法时类型HASH_MOD,也只有一个props属性sharding-count代表分片的数量。表达式hash(分片健/数据库实例) % sharding-count。
YML核心配置如下:
spring: shardingsphere: rules: sharding: # 自动分片表规则配置 auto-tables: t_order: actual-data-sources: db$->{0..1} sharding-strategy: standard: sharding-column: order_date sharding-algorithm-name: t_order_table_hash_mod # 分片算法定义 sharding-algorithms: t_order_table_hash_mod: type: HASH_MOD # 哈希取模分片算法 props: # 指定分片数量 sharding-count: 6 tables: t_order: # 逻辑表名称 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: .... # 分表策略 table-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_table_hash_mod
复制代码
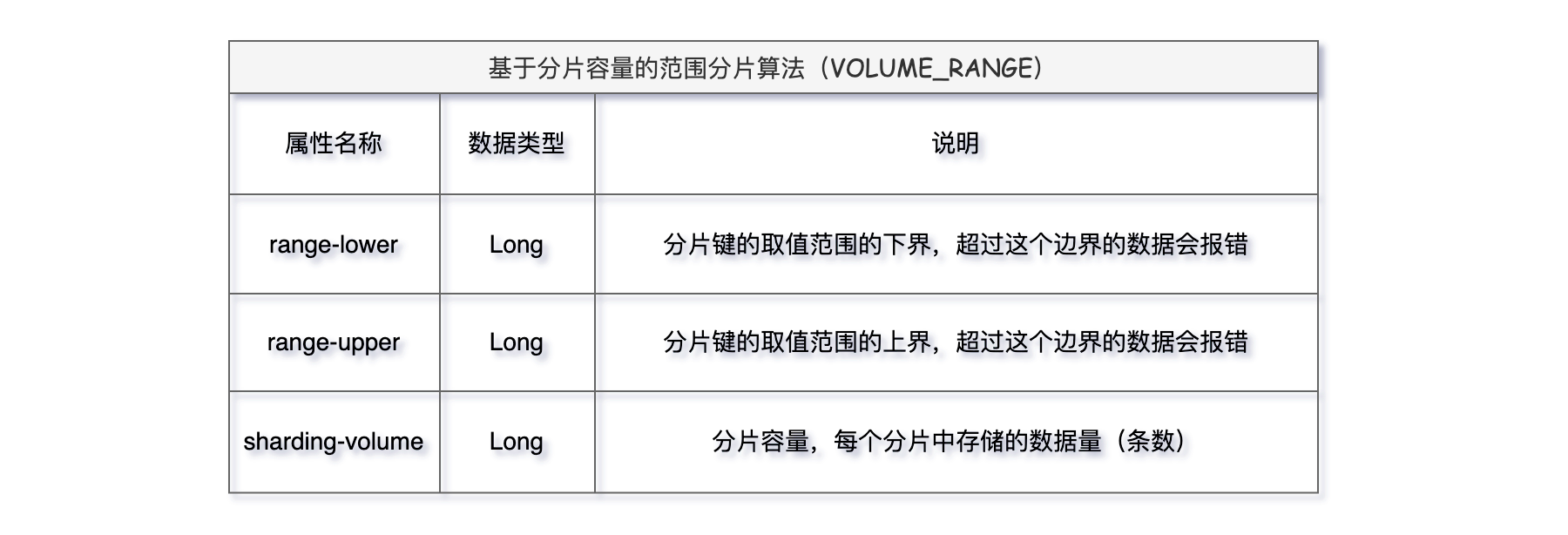
3、VOLUME_RANGE
基于分片容量的范围分片算法,依据数据容量来均匀分布到分片表中。
它适用于数据增长趋势相对均匀,按分片容量将数据均匀地分布到不同的分片表中,可以有效避免数据倾斜问题;由于数据已经被按照范围进行分片,支持频繁进行范围查询场景。
不仅如此,该算法支持动态的分片调整,可以根据实际业务数据的变化动态调整分片容量和范围,使得系统具备更好的扩展性和灵活性。
VOLUME_RANGE算法主要有三个属性:
看完是不是一脸懵逼,上界下界都是什么含义,我们实际使用一下就清晰了。为t_order逻辑表设置VOLUME_RANGE分片算法,range-lower下界数为 2,range-upper上界数为 20,分量容量sharding-volume 10。
yml核心配置如下:
# 分片算法定义spring: shardingsphere: rules: sharding: # 自动分片表规则配置 auto-tables: t_order: actual-data-sources: db$->{0..1} sharding-strategy: standard: sharding-column: order_date sharding-algorithm-name: t_order_table_volume_range sharding-algorithms: t_order_table_volume_range: type: VOLUME_RANGE props: range-lower: 2 # 范围下界,超过边界的数据会报错 range-upper: 20 # 范围上界,超过边界的数据会报错 sharding-volume: 10 # 分片容量 tables: t_order: # 逻辑表名称 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: .... # 分表策略 table-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_table_volume_range
复制代码
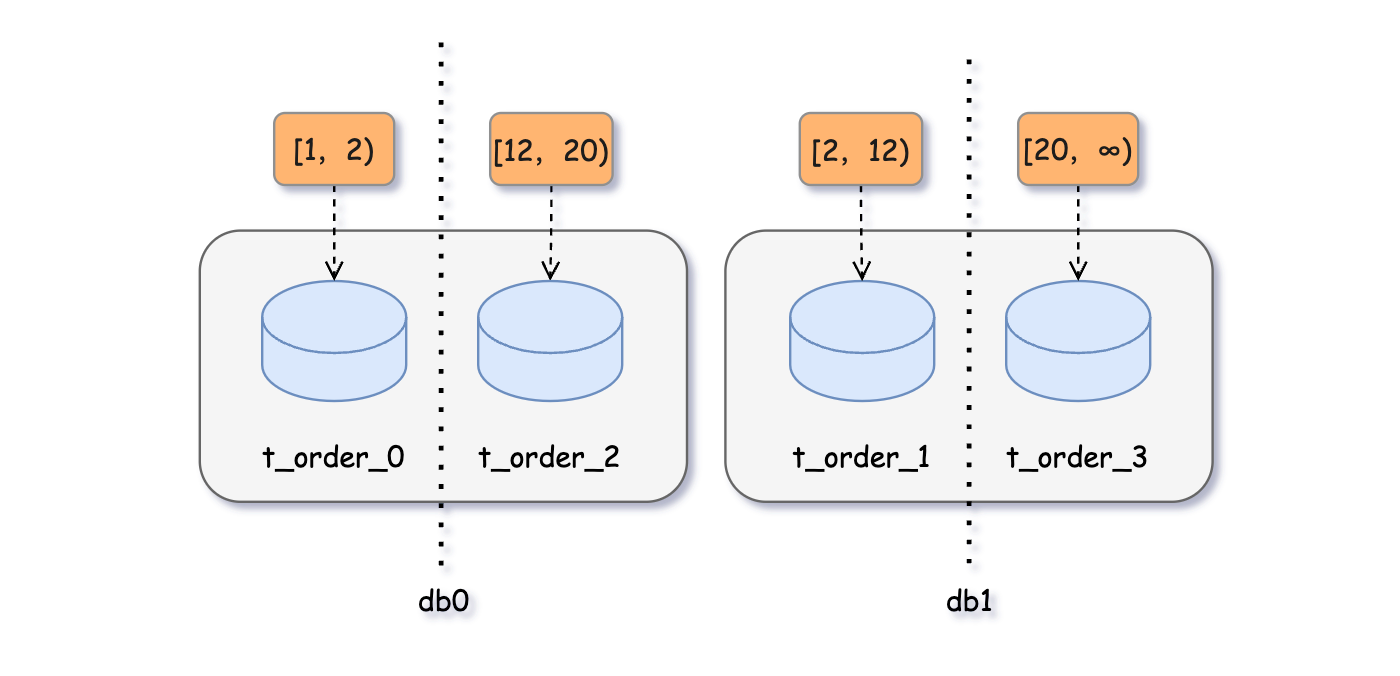
这个配置的意思就是说,分片健t_order_id的值在界值 [range-lower,range-upper) 范围内,每个分片表最大存储 10 条数据;低于下界的值 [ 1,2 ) 数据分布到 t_order_0,在界值范围内的数据 [ 2,20 ) 遵循每满足 10 条依次放入 t_order_1、t_order_2;超出上界的数据[ 20,∞ ) 即便前边的分片表里未满 10 条剩下的也全部放在 t_order_3。
那么它的数据分布应该如下:
[ 0,2 )数据分布到 t_order_0
[ 2,12 )数据分布到 t_order_1
[ 12,20 )数据分布到 t_order_2
[ 20,∞ )数据分布到 t_order_3
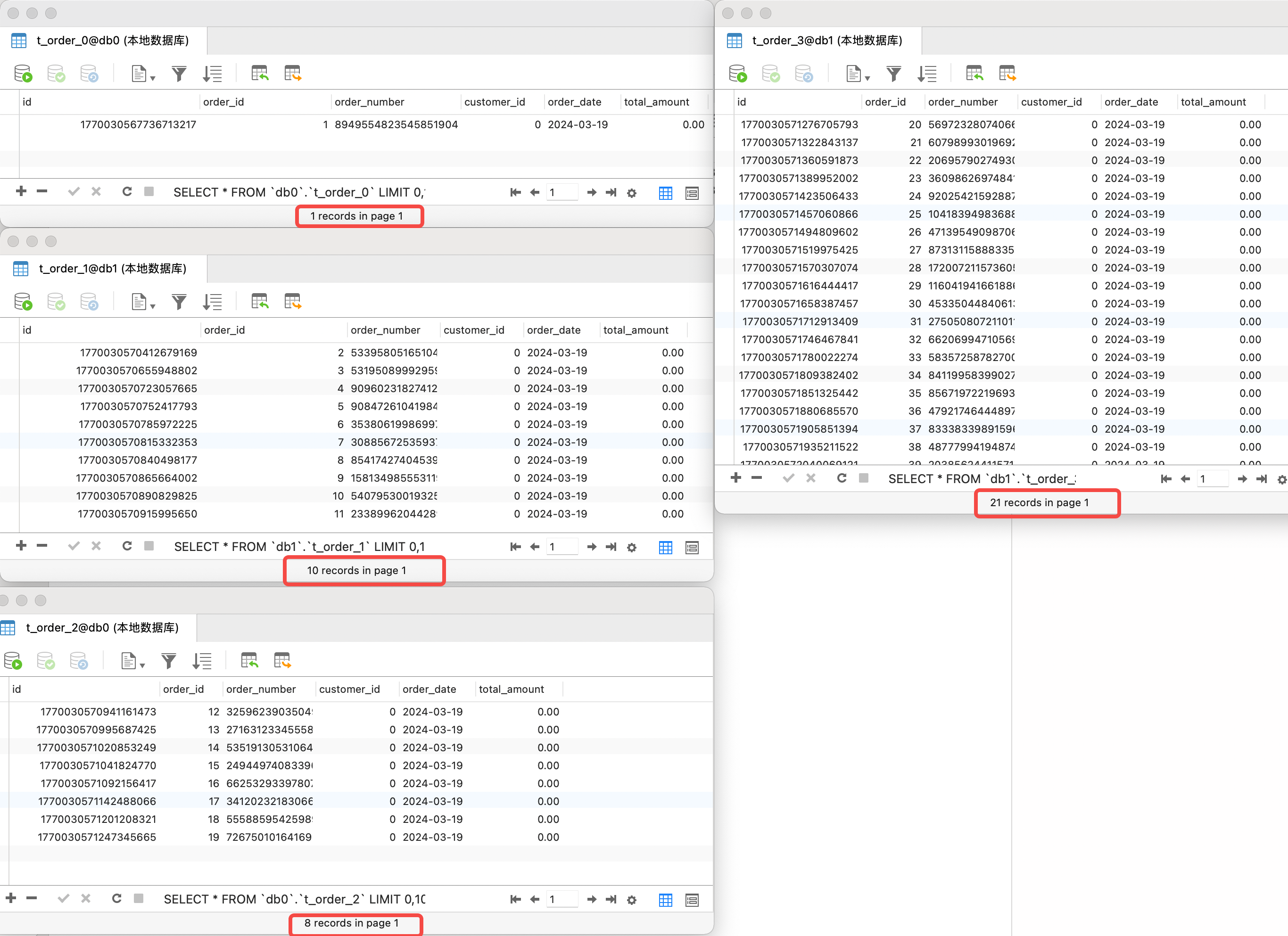
接着准备插入 40 条数据,其中分片健字段t_order_id值从 1~40,我们看到实际插入库的数据和上边配置的规则是一致的。超出range-lower、range-upper边界的部分数据,比如:t_order_2表未满 10 条也不再插入,全部放入了t_order_3分片表中。
4、BOUNDARY_RANGE
基于分片边界的范围分片算法,和分片容量算法不同,这个算法根据数据的取值范围进行分片,特别适合按数值范围频繁查询的场景。该算法只有一个属性sharding-ranges为分片健值的范围区间。
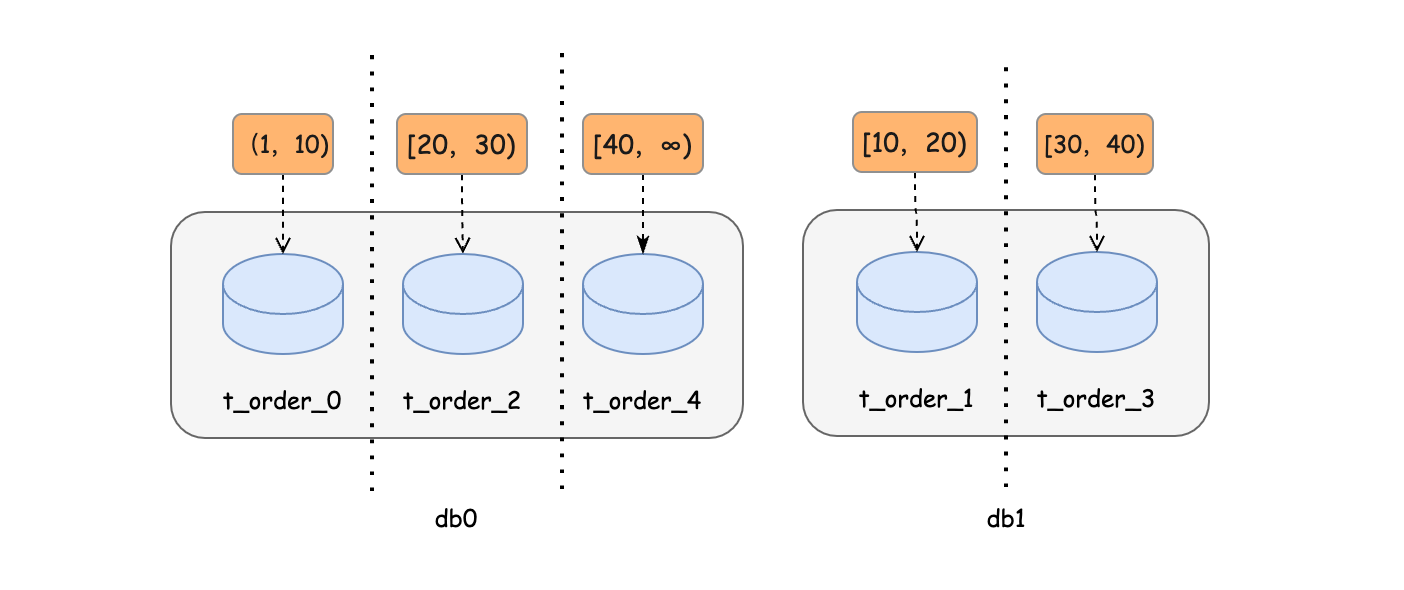
比如,我们配置sharding-ranges=10,20,30,40,它的范围默认是从 0 开始,范围区间前闭后开。配置算法以后执行建表语句,生成数据节点分布如:
db0- |_t_order_0 |_t_order_2 |_t_order_4db1- |_t_order_1 |_t_order_3
复制代码
那么它的数据分布应该如下:
[ 0,10 )数据分布到 t_order_0,
[ 10,20 )数据分布到 t_order_1,
[ 20,30 )数据分布到 t_order_2,
[ 30,40 )数据分布到 t_order_3,
[ 40,∞ )数据分布到 t_order_4。
BOUNDARY_RANGE算法的YML核心配置如下:
spring: shardingsphere: rules: sharding: # 自动分片表规则配置 auto-tables: t_order: actual-data-sources: db$->{0..1} sharding-strategy: standard: sharding-column: order_date sharding-algorithm-name: t_order_table_boundary_range sharding-algorithms: # 基于分片边界的范围分片算法 t_order_table_boundary_range: type: BOUNDARY_RANGE props: sharding-ranges: 10,20,30,40 # 分片的范围边界,多个范围边界以逗号分隔 tables: t_order: # 逻辑表名称 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: .... # 分表策略 table-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_table_boundary_range
复制代码
也插入 40 条数据,其中分片健字段t_order_id值从 1~40,和上边分析的数据分布结果大致相同。看到第一张分片表中 t_order_0 只有 9 条数据,这是因为咱们插入数据的分片健值是从 1 开始,但算法是从 0 开始计算。
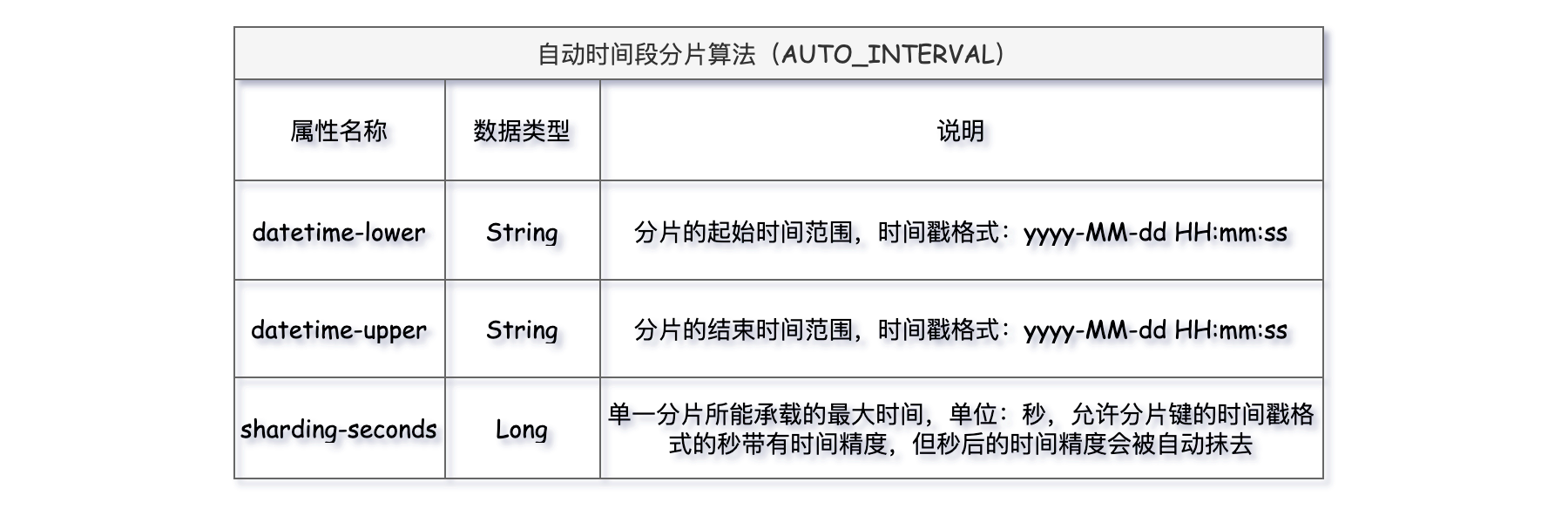
5、AUTO_INTERVAL
自动时间段分片算法,适用于以时间字段作为分片健的分片场景,和VOLUME_RANGE基于容量的分片算法用法有点类似,不同的是AUTO_INTERVAL依据时间段进行分片。主要有三个属性datetime-lower分片健值开始时间(下界)、datetime-upper分片健值结束时间(上界)、sharding-seconds单一分片表所能容纳的时间段。
这里分片健已经从t_order_id替换成了order_date。现在属性 datetime-lower 设为 2023-01-01 00:00:00,datetime-upper 设为 2025-01-01 00:00:00,sharding-seconds为 31536000 秒(一年)。策略配置上有些改动,将分库和分表的算法全替换成AUTO_INTERVAL。
YML核心配置如下:
spring: shardingsphere: rules: sharding: # 自动分片表规则配置 auto-tables: t_order: actual-data-sources: db$->{0..1} sharding-strategy: standard: sharding-column: order_date sharding-algorithm-name: t_order_table_auto_interval # 分片算法定义 sharding-algorithms: # 自动时间段分片算法 t_order_table_auto_interval: type: AUTO_INTERVAL props: datetime-lower: '2023-01-01 00:00:00' # 分片的起始时间范围,时间戳格式:yyyy-MM-dd HH:mm:ss datetime-upper: '2025-01-01 00:00:00' # 分片的结束时间范围,时间戳格式:yyyy-MM-dd HH:mm:ss sharding-seconds: 31536000 # 单一分片所能承载的最大时间,单位:秒,允许分片键的时间戳格式的秒带有时间精度,但秒后的时间精度会被自动抹去 tables: # 逻辑表名称 t_order: # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: standard: sharding-column: order_date sharding-algorithm-name: t_order_table_auto_interval # 分表策略# table-strategy:# standard:# sharding-column: order_date# sharding-algorithm-name: t_order_table_auto_interval
复制代码
只要你理解了上边 VOLUME_RANGE 算法的数据分布规则,那么这个算法也很容易明白,分片健值在界值范围内 [datetime-lower,datetime-upper) 遵循每满足 sharding-seconds 时间段的数据放入对应分片表,超出界值的数据上下顺延到其他分片中。
它的数据分布应该如下:
[ 2023-01-01 00:00:00,2024-01-01 00:00:00 )数据分布到 t_order_0,
[ 2024-01-01 00:00:00,2025-01-01 00:00:00 )数据分布到 t_order_1,
[ 2025-01-01 00:00:00,2026-01-01 00:00:00 )数据分布到 t_order_2。
[ 2026-01-01 00:00:00,∞ )数据分布到 t_order_3。
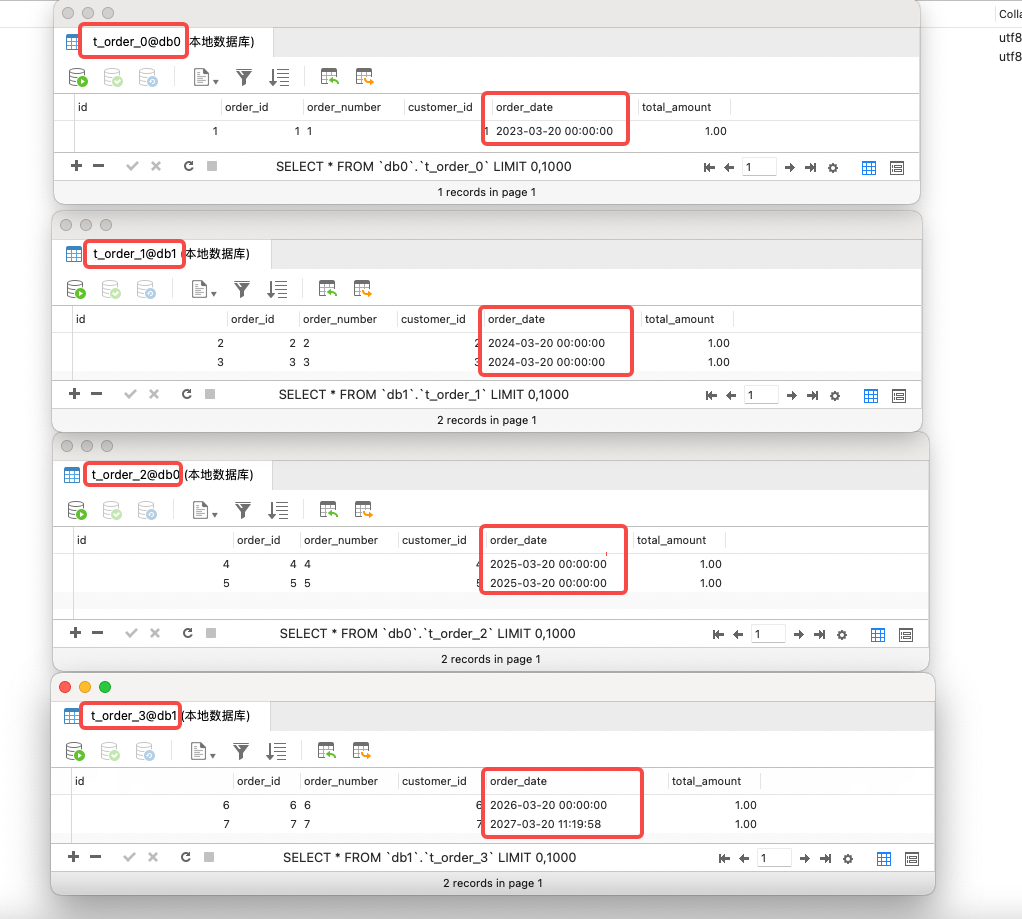
为了方便测试,手动执行插入不同日期的数据,按照上边配置的规则应该t_order_0会有一条 23 年的数据,t_order_1 中有两条 24 年的数据,t_order_2 中有两条 25 年的数据,t_order_3 中有两条 26、27 年的数据。
// 放入 t_order_0 分片表INSERT INTO `t_order` VALUES (1, '2023-03-20 00:00:00', 1, '1', 1, 1.00);// 放入 t_order_1 分片表INSERT INTO `t_order` VALUES (2, '2024-03-20 00:00:00', 2, '2', 2,1.00);INSERT INTO `t_order` VALUES (3, '2024-03-20 00:00:00', 3, '3', 3, 1.00);// 放入 t_order_2 分片表INSERT INTO `t_order` VALUES (4,'2025-03-20 00:00:00',4, '4', 4, 1.00);INSERT INTO `t_order` VALUES (5,'2025-03-20 00:00:00',5, '5', 5, 1.00);// 放入 t_order_3 分片表INSERT INTO `t_order` VALUES (6,'2026-03-20 00:00:00',6, '6', 6, 1.00);INSERT INTO `t_order` VALUES (7,'2027-03-20 11:19:58',7, '7', 7, 1.00);
复制代码
查看实际的数据分布情况和预想的结果完全一致,至此内置算法全部使用大成。
标准分片算法
6、INLINE
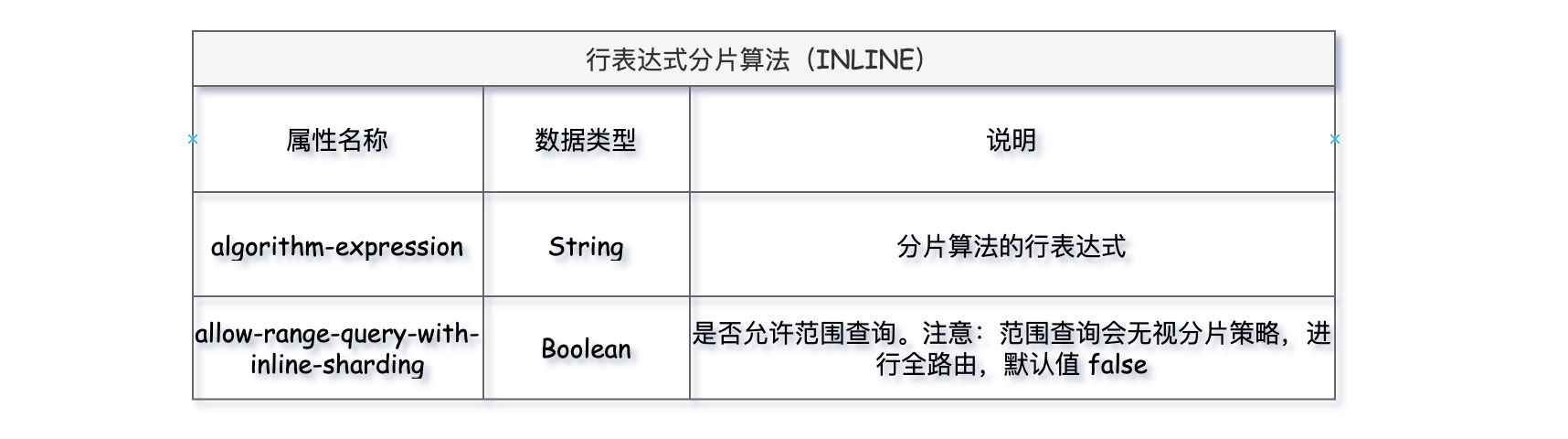
行表达式分片算法,适用于比较简单的分片场景,利用Groovy表达式在算法属性内,直接书写分片逻辑,省却了配置和代码开发,只支持 SQL 语句中的 = 和 IN 的分片操作,只支持单分片键。
该算法有两属性:
algorithm-expression:编写Groovy的表达式,比如: t_order_$->{t_order_id % 3} 表示根据分片健 t_order_id 取模获得 3 张 t_order 分片表 t_order_0 到 t_order_2。
allow-range-query-with-inline-sharding:由于该算法只支持含有 = 和 IN 操作符的 SQL,一旦 SQL 使用了范围查询 >、< 等操作会报错。要想执行范围查询成功,该属性开启为true即可,一旦开启范围查询会无视分片策略,进行全库表路由查询,这个要慎重开启!
YML核心配置如下:
spring: shardingsphere: # 具体规则配置 rules: sharding: # 分片算法定义 sharding-algorithms: # 标准分片算法 # 行表达式分片算法 t_order_table_inline: type: INLINE props: algorithm-expression: t_order_$->{order_id % 3} # 分片算法的行表达式 allow-range-query-with-inline-sharding: false # 是否允许范围查询。注意:范围查询会无视分片策略,进行全路由,默认 false tables: # 逻辑表名称 t_order: # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_database_algorithms # 分表策略 table-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_table_inline
复制代码
7、INTERVAL
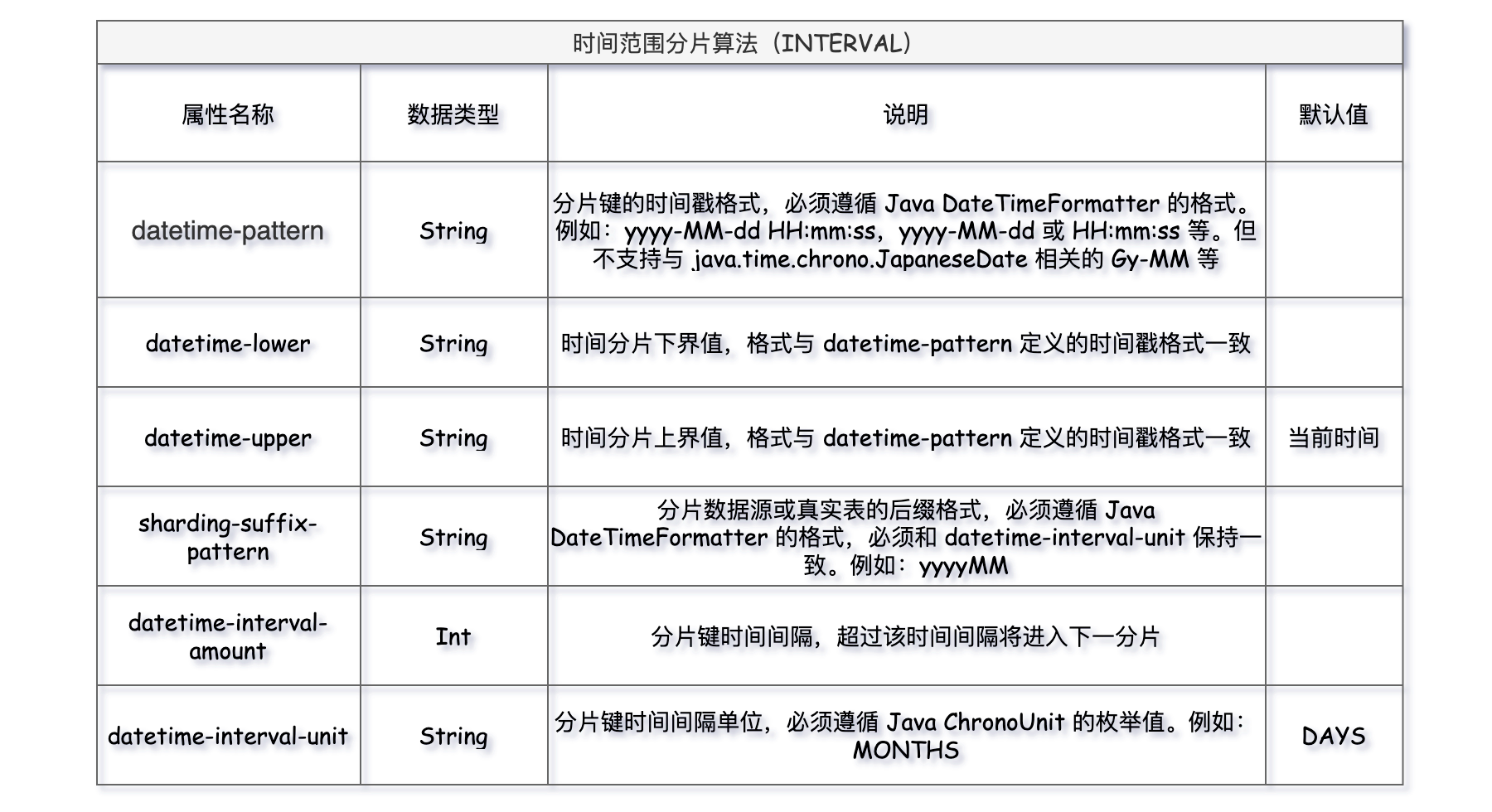
时间范围分片算法,针对于时间字段(字符串类型)作为分片健的范围分片算法,适用于按照天、月、年这种固定区间的数据分片。上边使用其它时间分片算法时,用的都是t_order_n后缀编号格式的分片表。但业务上往往需要的可能是按月、年t_order_yyyyMM的这种分片表格式。
时间范围分片算法(INTERVAL),可以轻松实现这种场景,它的属性比较多,逐个解释下:
datetime-pattern:分片健值的时间格式,必须是 Java DateTimeFormatter 类支持的转换类型
datetime-lower:分片健值的下界,超过会报错,格式必须与datetime-pattern一致
datetime-upper:分片健值的上界,超过会报错,格式必须与datetime-pattern一致
sharding-suffix-pattern:分片表后缀名格式,yyyyMM、yyyyMMdd 等格式,分片表格式的定义要结合datetime-interval-unit的单位,比如:t_order_yyyyMM格式表示分片表存的月的数据,t_order_yyyy格式表示分片表存的年的数据;
datetime-interval-unit:分片间隔单位,超过该时间间隔将进入下一分片。它遵循 Java ChronoUnit 枚举,比如:MONTHS、DAYS等;
datetime-interval-amount:分片间隔数,和datetime-interval-unit是紧密配合使用;
接下来实现个按月存储数据的场景,用t_order_202401~t_order_202406 6 张分片表存储前半年的数据,每张分片表存储一个月的数据。interval_value字段作为分片健,时间字符串类型,允许的分片值时间范围 2024-01-01 00:00:00~2024-06-30 23:59:59 不在范围内插入报错。
spring: shardingsphere: rules: sharding: # 分片算法定义 sharding-algorithms: t_order_database_mod: type: MOD props: sharding-count: 2 # 指定分片数量 t_order_table_interval: type: INTERVAL props: datetime-pattern: "yyyy-MM-dd HH:mm:ss" # 分片字段格式 datetime-lower: "2024-01-01 00:00:00" # 范围下限 datetime-upper: "2024-06-30 23:59:59" # 范围上限 sharding-suffix-pattern: "yyyyMM" # 分片名后缀,可以是MM,yyyyMMdd等。 datetime-interval-amount: 1 # 分片间隔,这里指一个月 datetime-interval-unit: "MONTHS" # 分片间隔单位 tables: # 逻辑表名称 t_order: # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${202401..202406} # 分库策略 database-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_database_mod # 分表策略 table-strategy: standard: sharding-column: interval_value sharding-algorithm-name: t_order_table_interval keyGenerateStrategy: column: id keyGeneratorName: t_order_snowflake
复制代码
配置完成后插入测试数据 1 月~7 月,正常情况下前 6 个月的数据会正常插入,超过界值的 7 月数据应该会报错。
// 放入 t_order_202401 分片表INSERT INTO `t_order` VALUES (1, 1, '1', 1, 1.00, '2024-01-01 00:00:00', 1);// 放入 t_order_202402 分片表INSERT INTO `t_order` VALUES (2, 2, '2', 2, 1.00, '2024-02-01 00:00:00', 1);// 放入 t_order_202403 分片表INSERT INTO `t_order` VALUES (3, 3, '3', 3, 1.00, '2024-03-01 00:00:00', 1);// 放入 t_order_202404 分片表INSERT INTO `t_order` VALUES (4, 4, '4', 4, 1.00, '2024-04-01 00:00:00', 1);// 放入 t_order_202405 分片表INSERT INTO `t_order` VALUES (5, 5, '5', 5, 1.00, '2024-05-01 00:00:00', 1);// 放入 t_order_202406 分片表INSERT INTO `t_order` VALUES (6, 6, '6', 6, 1.00, '2024-06-01 00:00:00', 1); // 插入会报错INSERT INTO `t_order` VALUES (7, 7, '7', 7, 1.00, '2024-07-01 00:00:00', 1);
复制代码
看到实际的入库的效果和预期的一致,一月的数据存到t_order_202401,二月的数据存到t_order_202402~,在插入 7 月数据的时候报错了。
COSID 类型算法
ShardingSphere 提供了三种基于散列散列算法的CosId(它是一款性能极高分布式 ID 生成器)分片算法,这个算法的核心思想是通过散列算法对 CosId 生成的分布式 ID 和分片键值进行处理,以确定数据应该存放在哪个具体的数据节点上。
使用散列算法的优势,可以将数据按照一定规则映射到不同的数据节点上,能够确保数据的均匀分布,避免某些节点负载过重或者数据倾斜的情况。
三个算法与其他分片算法主要区别在于底层的实现,在配置上使用上基本没太多区别。
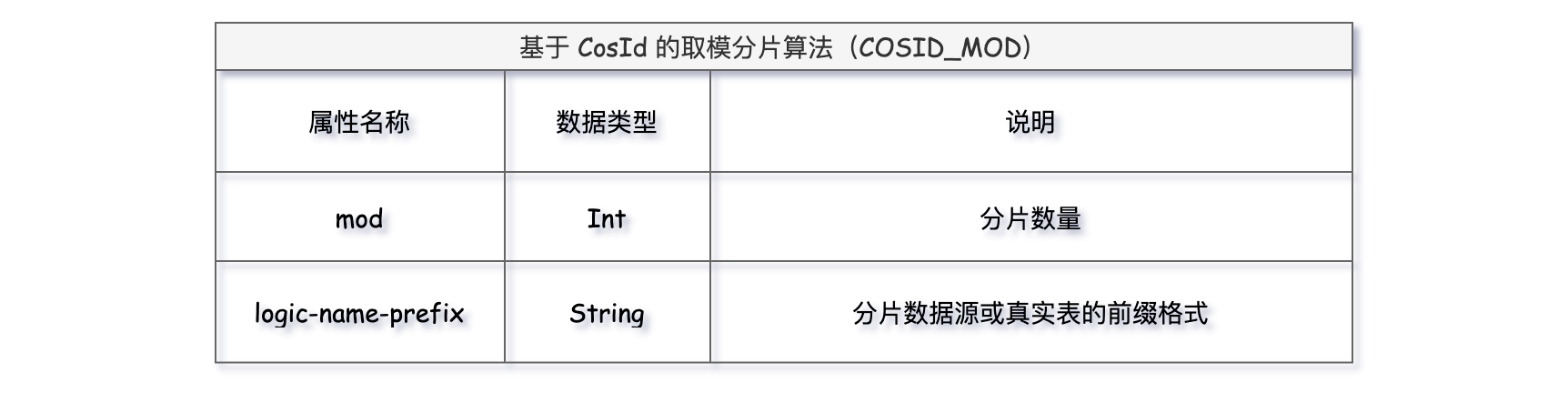
8、COSID_MOD
基于 CosId 的取模分片算法和普通的 MOD 算法使用上略有不同,mod为分片数量,logic-name-prefix分片数据源或真实表的前缀格式。
yml核心配置如下:
spring: shardingsphere: rules: sharding: # 分片算法定义 sharding-algorithms: t_order_database_mod: type: MOD props: sharding-count: 2 # 指定分片数量 # 8、基于 CosId 的取模分片算法 t_order_table_cosid_mod: type: COSID_MOD props: mod: 3 # 分片数量 logic-name-prefix: t_order_ # 分片数据源或真实表的前缀格式 tables: # 逻辑表名称 t_order: # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_database_mod # 分表策略 table-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_table_cosid_mod keyGenerateStrategy: column: id keyGeneratorName: t_order_snowflake
复制代码
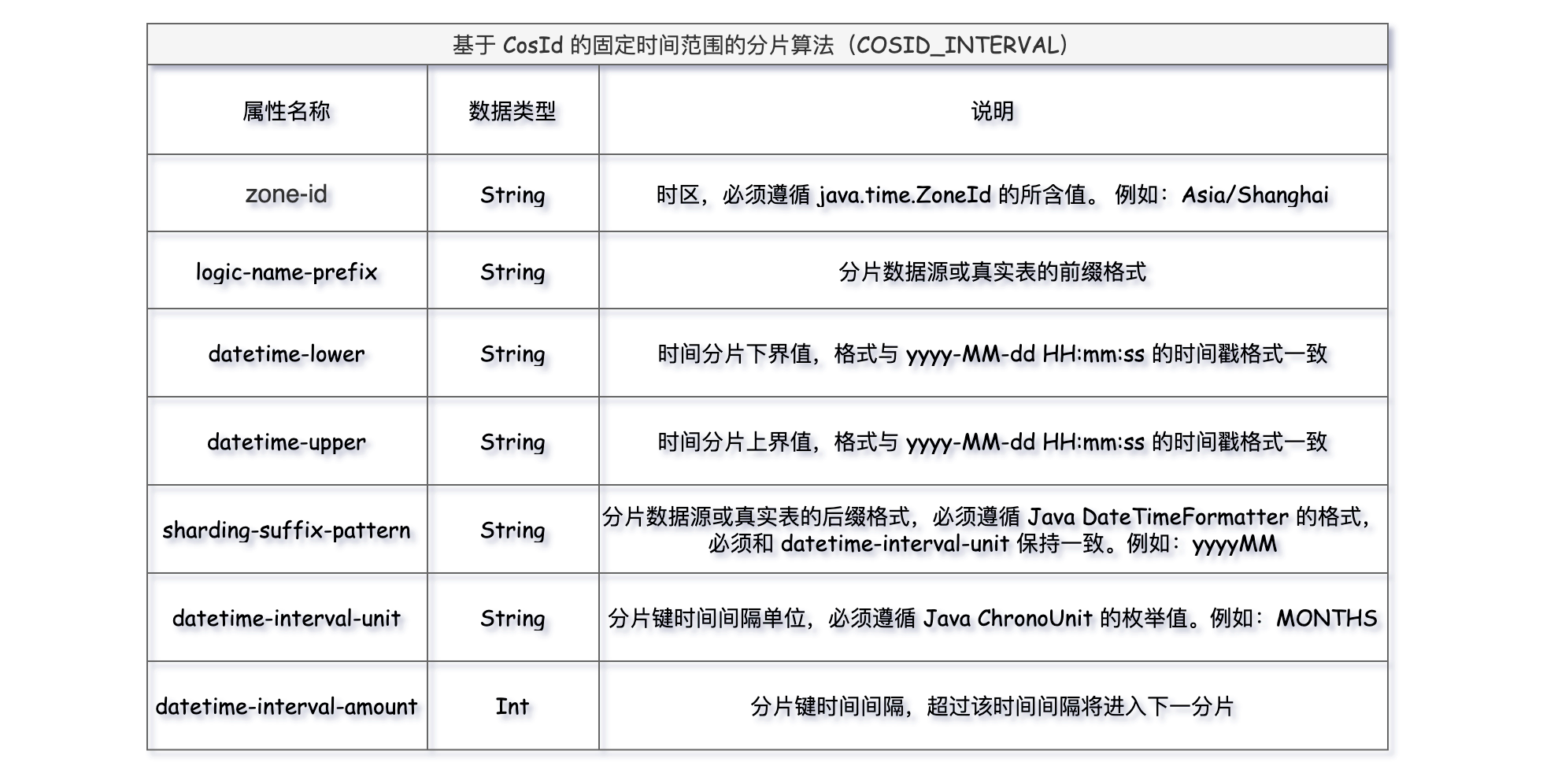
9、COSID_INTERVAL
基于 CosId 的固定时间范围的分片算法,和INTERVAL算法的用法很相似,不同点在于增加了zone-id时区属性,logic-name-prefix分片数据源或真实表的前缀格式,上下界datetime-lower、datetime-upper范围的时间格式是固定的yyyy-MM-dd HH:mm:ss。
yml核心配置如下:
spring: shardingsphere: rules: sharding: # 分片算法定义 sharding-algorithms: t_order_database_mod: type: MOD props: sharding-count: 2 # 指定分片数量 # 基于 CosId 的固定时间范围的分片算法 t_order_table_cosid_interval: type: COSID_INTERVAL props: zone-id: "Asia/Shanghai" # 时区,必须遵循 java.time.ZoneId 的所含值。 例如:Asia/Shanghai logic-name-prefix: t_order_ # 分片数据源或真实表的前缀格式 sharding-suffix-pattern: "yyyyMM" # 分片数据源或真实表的后缀格式,必须遵循 Java DateTimeFormatter 的格式,必须和 datetime-interval-unit 保持一致。例如:yyyyMM datetime-lower: "2024-01-01 00:00:00" # 时间分片下界值,格式与 yyyy-MM-dd HH:mm:ss 的时间戳格式一致 datetime-upper: "2024-12-31 00:00:00" # 时间分片上界值,格式与 yyyy-MM-dd HH:mm:ss 的时间戳格式一致 datetime-interval-unit: "MONTHS" # 分片键时间间隔单位,必须遵循 Java ChronoUnit 的枚举值。例如:MONTHS datetime-interval-amount: 1 # 分片键时间间隔,超过该时间间隔将进入下一分片 tables: # 逻辑表名称 t_order: # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${202401..202412} # 分库策略 database-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_database_mod # 分表策略 table-strategy: standard: sharding-column: interval_value sharding-algorithm-name: t_order_table_cosid_interval keyGenerateStrategy: column: id keyGeneratorName: t_order_snowflake
复制代码
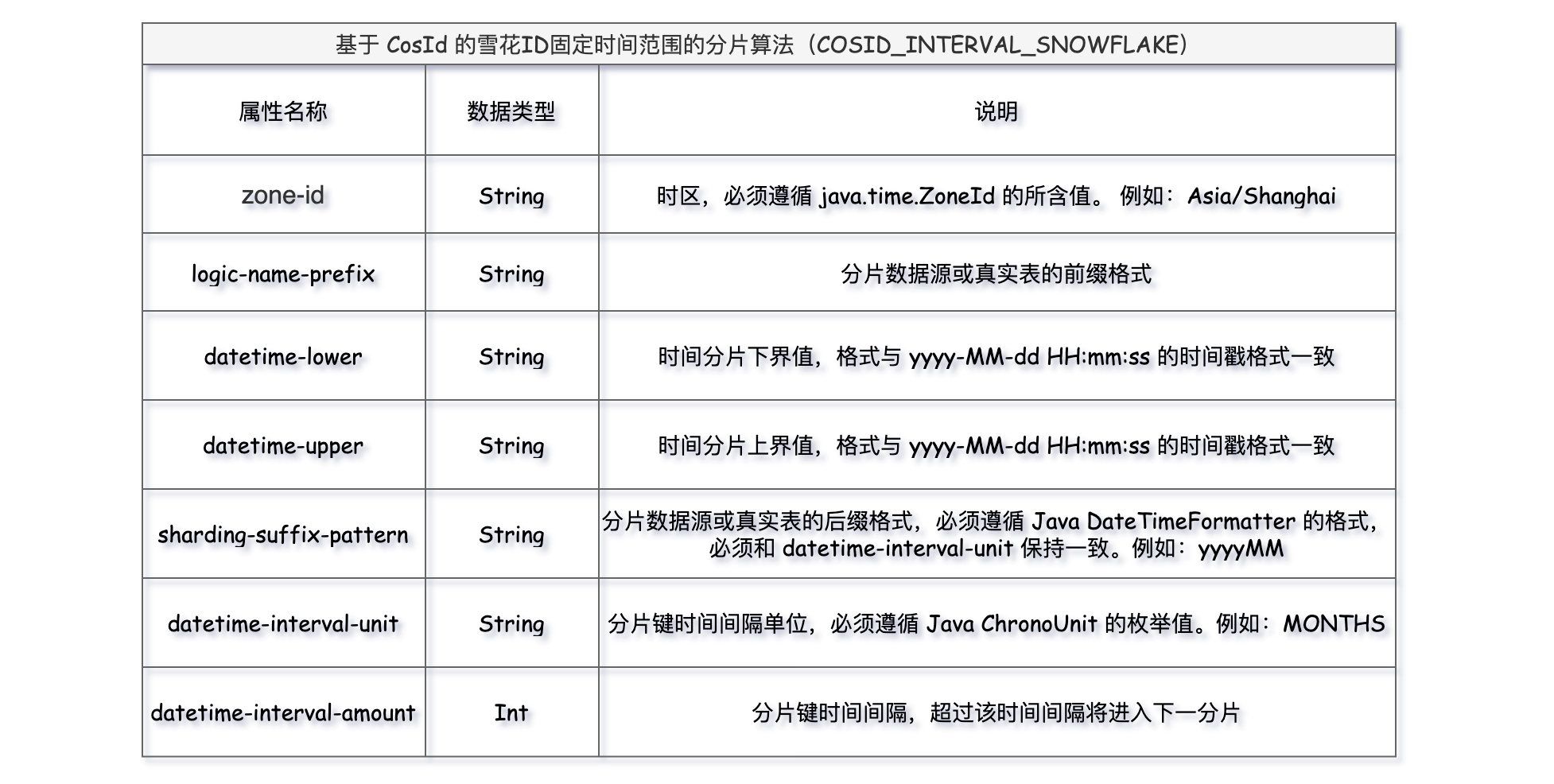
10、COSID_INTERVAL_SNOWFLAKE
基于 CosId 的雪花 ID 固定时间范围的分片算法,和上边的COSID_INTERVAL算法不同之处在于,底层用于散列的 COSID 的生成方式是基于雪花算法(Snowflake),内部结合了时间戳、节点标识符和序列号等,这样有助于数据分布更均匀些。
使用除了 type 类型不同COSID_INTERVAL_SNOWFLAKE外,其他属性用法和COSID_INTERVAL完全一致。yml核心配置如下:
spring: shardingsphere: rules: sharding: # 分片算法定义 sharding-algorithms: t_order_database_mod: type: MOD props: sharding-count: 2 # 指定分片数量 # 基于 CosId 的固定时间范围的分片算法 t_order_table_cosid_interval_snowflake: type: COSID_INTERVAL_SNOWFLAKE props: zone-id: "Asia/Shanghai" # 时区,必须遵循 java.time.ZoneId 的所含值。 例如:Asia/Shanghai logic-name-prefix: t_order_ # 分片数据源或真实表的前缀格式 sharding-suffix-pattern: "yyyyMM" # 分片数据源或真实表的后缀格式,必须遵循 Java DateTimeFormatter 的格式,必须和 datetime-interval-unit 保持一致。例如:yyyyMM datetime-lower: "2024-01-01 00:00:00" # 时间分片下界值,格式与 yyyy-MM-dd HH:mm:ss 的时间戳格式一致 datetime-upper: "2024-12-31 00:00:00" # 时间分片上界值,格式与 yyyy-MM-dd HH:mm:ss 的时间戳格式一致 datetime-interval-unit: "MONTHS" # 分片键时间间隔单位,必须遵循 Java ChronoUnit 的枚举值。例如:MONTHS datetime-interval-amount: 1 # 分片键时间间隔,超过该时间间隔将进入下一分片 tables: # 逻辑表名称 t_order: # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${202401..202412} # 分库策略 database-strategy: standard: sharding-column: order_id sharding-algorithm-name: t_order_database_mod # 分表策略 table-strategy: standard: sharding-column: interval_value sharding-algorithm-name: t_order_table_cosid_interval_snowflake keyGenerateStrategy: column: id keyGeneratorName: t_order_snowflake
复制代码
复合分片算法
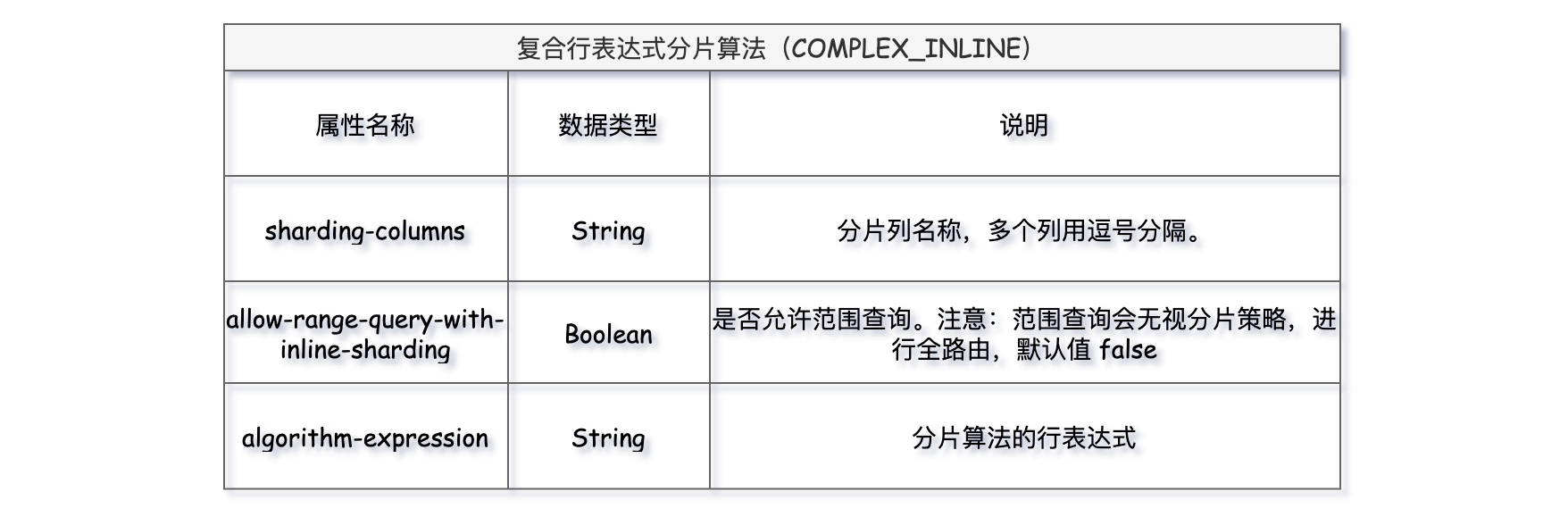
11、COMPLEX_INLINE
复合行表达式分片算法,适用于多分片健的简单分片场景,和行表达式分片算法使用的方式基本一样。多了一个属性sharding-columns分片列名称,多个列用逗号分隔。特别注意:使用多分片键复合算法,一定要基于复合分片策略进行设置。
我们对现有的分库分表算法进行了改进,将分片策略修改为complex,sharding-columns单个分片键升级为多个分片键逗号分隔。例如,将分库表达式从db$->{order_id % 2}调整为db$->{(order_id + user_id) % 2},就实现了多个分片键的应用。
yml核心的配置如下:
spring: shardingsphere: # 具体规则配置 rules: sharding: # 分片算法定义 sharding-algorithms: t_order_database_complex_inline_algorithms: type: COMPLEX_INLINE props: sharding-columns: order_id, user_id # 分片列名称,多个列用逗号分隔。 algorithm-expression: db$->{(order_id + user_id) % 2} # 分片算法的行表达式 allow-range-query-with-inline-sharding: false # 是否允许范围查询。注意:范围查询会无视分片策略,进行全路由,默认 false # 11、复合行表达式分片算法 t_order_table_complex_inline: type: COMPLEX_INLINE props: sharding-columns: order_id, user_id # 分片列名称,多个列用逗号分隔。 algorithm-expression: t_order_$->{ (order_id + user_id) % 3 } # 分片算法的行表达式 allow-range-query-with-inline-sharding: false # 是否允许范围查询。注意:范围查询会无视分片策略,进行全路由,默认 false tables: # 逻辑表名称 t_order: # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: complex: shardingColumns: order_id, user_id sharding-algorithm-name: t_order_database_complex_inline_algorithms # 分表策略 table-strategy: complex: shardingColumns: order_id, user_id sharding-algorithm-name: t_order_table_complex_inline keyGenerateStrategy: column: id keyGeneratorName: t_order_snowflake
复制代码
Hint 分片算法
12、HINT_INLINE
Hint 行表达式分片算法(强制路由分片算法),允许我们指定数据分布的分片库和分表的位置。这个算法只有一个属性algorithm-expression,直接利用Groovy表达式在其中书写分片逻辑。
如果想要向db0.t_order_1分片表中插入一条数据,但我的 Insert SQL 中并没有分片健呀,执意执行插入操作可能就会导致全库表路由,插入的数据就会重复,显然是不能接受的。Hint 算法可以很好的解决此场景。
HINT_INLINE 算法一定要在 HINT 分片策略内使用,否则会报错。
核心的配置如下:其中两个表达式db$->{Integer.valueOf(value) % 2}和t_order_$->{Integer.valueOf(value) % 3}中的value值分别是我们通过 Hint API 传入的分库值和分表值。
spring: shardingsphere: rules: sharding: # 分片算法定义 sharding-algorithms: # Hint 行表达式分片算法 t_order_database_hint_inline: type: HINT_INLINE props: algorithm-expression: db$->{Integer.valueOf(value) % 2} # 分片算法的行表达式,默认值${value} t_order_table_hint_inline: type: HINT_INLINE props: algorithm-expression: t_order_$->{Integer.valueOf(value) % 3} # 分片算法的行表达式,默认值${value} tables: # 逻辑表名称 t_order: # 数据节点:数据库.分片表 actual-data-nodes: db$->{0..1}.t_order_${0..2} # 分库策略 database-strategy: hint: sharding-algorithm-name: t_order_database_hint_inline # 分表策略 table-strategy: hint: sharding-algorithm-name: t_order_table_hint_inline keyGenerateStrategy: column: id keyGeneratorName: t_order_snowflake
复制代码
配置完分片算法,如何将value值传递进来?通过HintManager设置逻辑表的分库addDatabaseShardingValue、分表addTableShardingValue,强制数据分布到指定位置。
@DisplayName("测试 hint_inline 分片算法插入数据")@Testpublic void insertHintInlineTableTest() { HintManager hintManager = HintManager.getInstance(); hintManager.clearShardingValues(); // 设置逻辑表 t_order 的分库值 hintManager.addDatabaseShardingValue("t_order", 0); // 设置逻辑表 t_order 的分表值 hintManager.addTableShardingValue("t_order", 1); // 1%3 = 1 所以放入 db0.t_order_1 分片表 jdbcTemplate.execute("INSERT INTO `t_order`(`id`,`order_date`,`order_id`, `order_number`, `customer_id`, `total_amount`, `interval_value`, `user_id`) VALUES (1, '2024-03-20 00:00:00', 1, '1', 1, 1.00, '2024-01-01 00:00:00', 1);"); hintManager.close();}
复制代码
ShardingSphere 通过使用ThreadLocal管理强制路由配置,可以通过编程的方式向HintManager中添加分片值,该分片值仅在当前线程内生效。
HintManager.getInstance() 获取 HintManager 实例;
HintManager.addDatabaseShardingValue,HintManager.addTableShardingValue 方法设置分片键值;
执行 SQL 语句完成路由和执行;
最后调用 HintManager.close 清理 ThreadLocal 中的内容。
按我们设定的数据节点位置,插入一条测试数据,看到确实存在了db0.t_order_1中,完美!
总结
本文中我们讲解了ShardingSphere-jdbc所支持的 12 种分片算法,每种算法都具有独特的特点。在实际应用中,需要结合具体的业务场景来灵活选择和应用适合的分片算法。
文章转载自:程序员小富
原文链接:https://www.cnblogs.com/chengxy-nds/p/18097298
体验地址:http://www.jnpfsoft.com/?from=001















评论