
百度网盘“第二大脑”产品探析,AI 技术让记忆更轻松

你是否遇到过因忘记一个重要的事情而错失良机,因工作总结时找不到素材而着急,因学习记不住知识点而苦恼?在我们的生活中,每一天都有大量的信息需要处理、记忆和唤醒。然而,受限于我们大脑的记忆机制,长期记忆只能在短期记忆不断强化的情况下才可以形成 ,这难免导致我们会忘记一些重要信息。假如我们的记忆可以快速固化,像文件一样存储、检索和回忆,这样就不用再为已获取的信息遗忘而苦恼,百度网盘“第二大脑”产品概念就是基于此来构建的。
在 9 月 5 日举办的 2023 百度云智大会上,百度集团执行副总裁、百度智能云事业群总裁沈抖表示,百度网盘“云一朵”智能助理面向大众全面开放使用,截至目前累积使用人数已经超过 600 万,“云一朵”就是百度网盘“第二大脑”的初级形态入口,用户可通过与其对话,实现基于私域数据的文件与视频的快速查找、知识点总结、文档翻译,甚至进行内容创作。百度智能云网盘产品部总经理吴天昊表示,百度网盘正经历从信息化到知识化的转变,走向 AI 时代的终极畅想:成为“第二大脑”。
百度网盘的“第二大脑”是一个什么样的产品呢?
首先它是个高效的存储体,能够方便地让用户把自己所搜集到各种渠道的信息存储到网盘中,为此网盘构建了多样的同步机制和工具,这些用户数据资产是“第二大脑”的知识源泉,具体存储方式如下:
手机自动备份(用户可以在【我的工具】【文件管理】类目下找到【手机备份】开启照片/通讯录/微信自动备份功能)
浏览器网盘插件直接转存
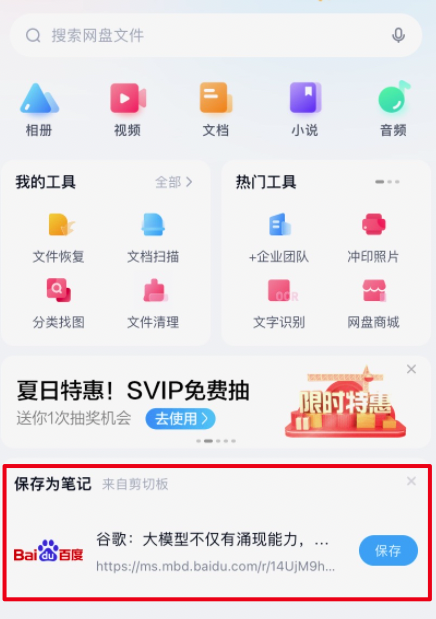
链接复制后打开网盘可以直接保存为笔记
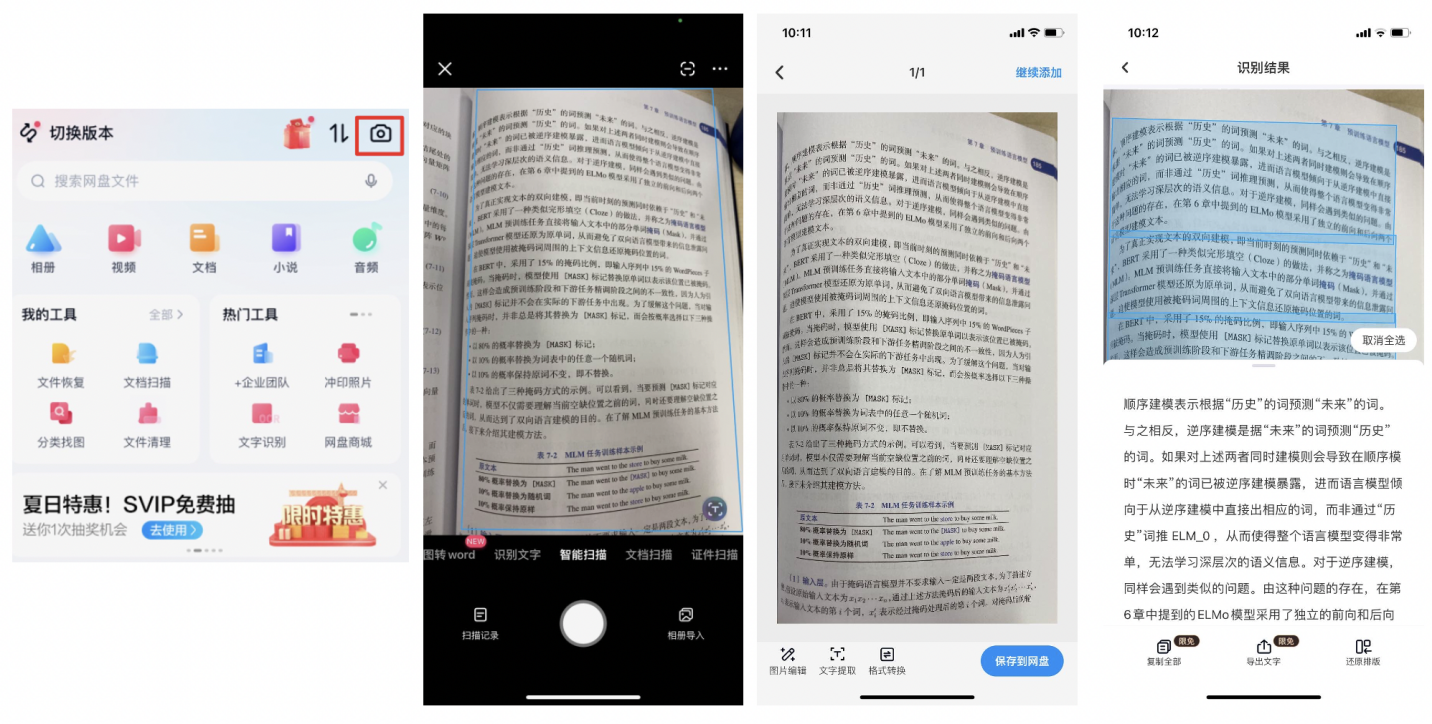
纸质文件通过扫描或拍照进行同步
其次它还是一个博学多才、无所不能的管家,无论是私人知识,还是网络公开资料,都可以信手拈来。它以完成用户指令为目标,不仅可以借助用户的“记忆”来回答问题,还可以借助大模型的能力将“记忆”之外的知识作为内容的补充,帮助用户完成既定任务。
最后它拥有一套便捷而自然的交互形态,是可以通过自然语言驱动的智能助手。

人类最自然的两种交互形态一种是手指划选,一种是自然语言,智能手机与触屏的结合带来了第一次交互的变革。而大语言模型的应用,必然会带来第二次交互的变革,所以“第二大脑”的交互形式也必然会是基于新一代交互技术构建的,用户通过自然语言的表述就可以让系统完成对应的任务。其初级形态入口就是当前已经面向大众全面开放的百度网盘“云一朵”智能助理。
“第二大脑”的相关技术有哪些?
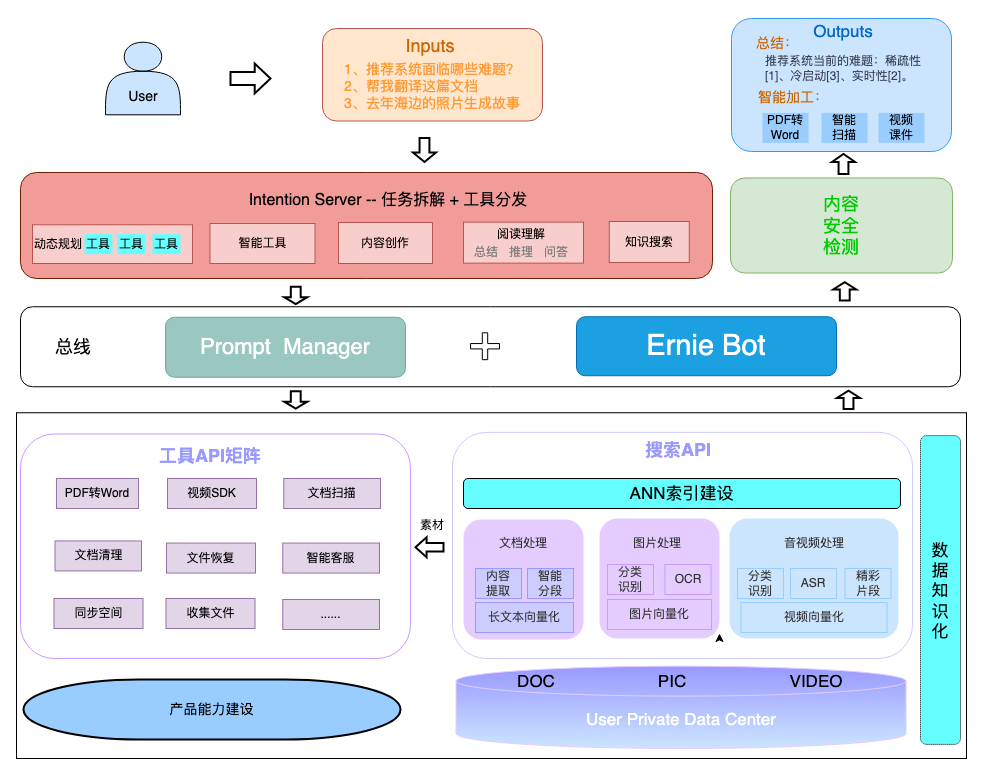
从上面“第二大脑”的产品描述我们可以看到,网盘“第二大脑”的核心目的就是帮助用户更好地使用网盘,以及获取存储在网盘里的知识。和一般的大语言模型不同的是,它更加突出用户的“私域”属性,通过“云一朵”这个数字形象,满足用户公域知识、私域知识、插件调用、智能客服、情感陪伴等多个维度需求,技术拆解上分为内容知识化、用户意图理解、任务拆解和规划、知识获取 4 个主要部分,下面我们分别探究下各模块的相关技术。
云一朵是如何做意图识别的?
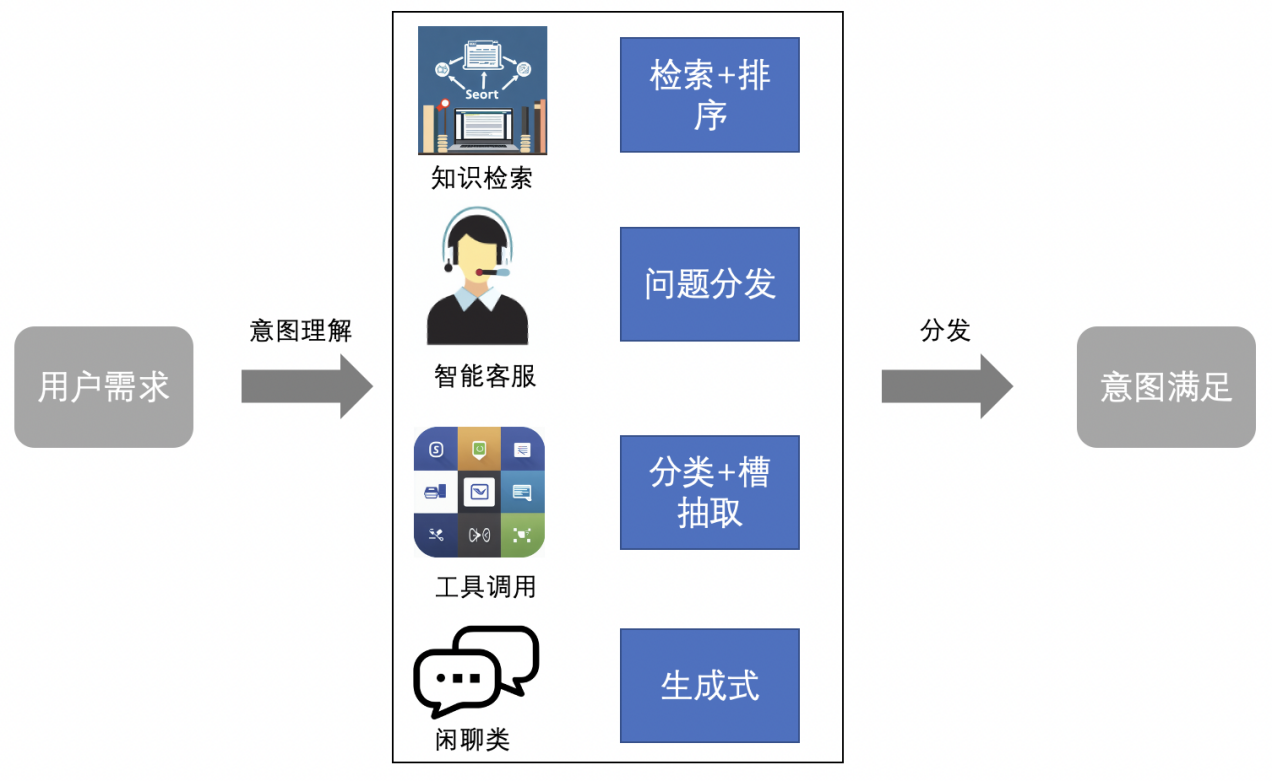
用户进入云一朵后,输入“帮我翻译下这篇论文”,我们是如何做呢?
首先通过模型判定这是一次工具调用,然后通过工具匹配知道是翻译意图,翻译对象是当前这篇论文,然后触发翻译任务,就完成了一次用户需求处理。
以上需求传统 NLP 也可以完成,而结合大模型(LLM)能力,我们可以完成更复杂的工具编排,要大模型稳定产出,首先要解决大模型的“幻觉”问题,最有效的方法就是在特定场景可以通过少量的训练数据对大模型进行微调(SFT),可以让大模型功能更为稳定和专一(通过大量的实践,发现网盘场景下所需的合适模型大小),而最后效果的好坏很大程度是训练数据集的质量决定的。
此模块也成为整个交互的核心,不同于创作场景对大模型生成能力的依赖,对复杂任务的编排更多是用到大模型的推理能力,思维链(COT)、思维图(GOT)等技术,在此处大放异彩,通过训练后我就可以完成如下的复杂任务。
用户给定的任务是“帮我生成一个去年海边游玩的故事”,基于大语言模型就可以编排为:
1)搜索去年海边的照片——调用图片搜索 API,对应参数:时间-2022 年/事物-海边
2)生成照片故事——调用故事生成 API,对应参数:X 张照片 ID
通过两次工具的调用,就可以完成用户设定的任务。
云一朵是如何做知识存储的?
网盘中既有文档,也有图片和视频,存在大量的未整理的非结构化数据,这些数据既然是“第二大脑”的知识源泉,第一步就是需要如何把这些信息知识化,并进行有效存储。产品需要支持通过自然语言驱动网盘数据,跨模态的语义向量化表征就成为一种必然的选择,基于此我们搭建了一套内容解析和向量数据库存储系统,以文档类型为例:
1)精准的文档内容识别和合理的段落切分是内容向量化的基础,网盘文档在线预览经过多年的技术积累,已经可以很好的做到文字信息提取和段落切分
2)向量数据存储表结构如下:
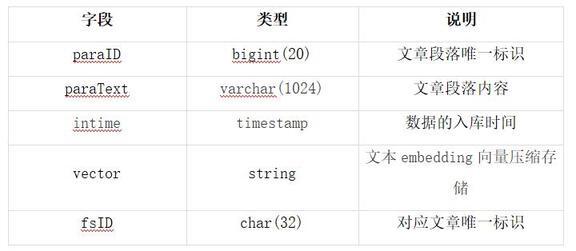
文档内容结构化再知识化,最后向量化后,变成了机器可以理解的知识,通过网盘自研的端云一体化底座技术进行存储。
云一朵是如何“回忆”的?
从云一朵的整体框架我们可以看出,当用户提出问题,云一朵系统基于上面知识化的内容存储进行问题检索,在检索召回结果的基础上借助大模型的能力,根据提问总结后返回给用户。
1)语义检索系统

针对用户查询 query,使用与文本内容向量化相对的模型进行向量化,请求对应的 ANN 服务进行内容匹配,考虑到性能和召回率,选取 top100 的段落进行相关性过滤,并排序后,取排序最高的 3 个段落+上用户问题作为大模型 prompt 输入,问题总结后呈现给用户。
注:百度飞桨平台提供了一套整体组建,想体验的同学可以参考下面的文章自己 DIY 一套简单的语义检索系统:动手搭建一套端到端文本语义检索系统 - 飞桨 AI Studio
2)与大语言模型的结合
问题总结能力是大语言模型的基础能力之一,与传统抽取式阅读理解不同,大语言模型通过生成式,能够从候选的段落中总结问题对应的答案,整体保持了语言的流畅和内容的完整性。
大模型的基本推理大致如下:

至此,用户通过模糊地表达需求,网盘第二大脑则基于大模型技术进行了信息搜索和整合,用用户容易理解的方式返回。
对个人和企业有哪些影响?
以上是网盘第二大脑的技术介绍,目前网盘电脑端、移动端均已开启了云一朵相关功能,不仅仅是帮你回忆存在网盘的知识,还可以帮助你阅读文档、理解视频,用自然语言搜索文件,更好地使用网盘工具等等,这些都值得大家去探索,欢迎大家体验,开启自己的记忆之旅。
当然,我们也承认这项技术还处于初期,整体复杂度之高超出原有的设想。比如 openai 的 chatgpt 也只是实现了公域知识范畴,一旦涉及工具(插件),他会让你选择,把复杂度交给了用户;微软 bing+gpt 的融合也只是一个搜索的插件,并能融入公域知识。网盘要做的这项工作,需要在用户如何使用网盘、获取盘内“记忆”中自由切换,还不能阻断公域知识引入,同时还要理解各种格式的文档、视频、音频等。这里我们只是把阶段性的探索工作呈现出来,并努力给大家提供更好的 AI 原生软件体验。
我们有幸生活在这样一个时代,知识爆炸、新生事物层出不穷,作为智能时代来临的见证者,自身和企业能力都面临较大挑战,都需要随着时代的进步不断提升,生存策略应该是避免用自己的短处去与 AI 的长处硬碰硬,相反,我们应该利用 AI 的优势来提升自己的长处。网盘结合 AI 打造“第二大脑”,帮助用户实现过目不忘和出口成章,拓宽了个人能力的边界,它的背后是人类不断通过创造工具来增强自我的进化过程。 同时,人不是 AI,人有语言与知识,也有体验与感知,这是属于我们更大的世界。
就像《哈利波特》电影中的“有求必应屋”,它充满了人们所需的一切,海伦娜形容它:“如果你还需要问,就永远不会明白;如果你明白,你只需要开口问。”
在有问必答的 AI 时代,智者将会如鱼得水,而愚者则可能会陷入困境。我们永远不能让 AI 代替我们思考,但是我们可以让它帮我们思考得更有成效。AI 之于社会的意义是让人更高效率“读万卷书”,有更多时间去“行万里路”。这也是百度网盘本身作为一个工具产品对每一位用户的意义,是网盘产研团队持续在进行思考和探索的方向。
人生最终的价值在于觉醒和思考的能力,而不只在于生存——亚里士多德。

还未添加个人签名 2021-05-31 加入
还未添加个人简介









评论