
数据库变革:HashData 云数仓实现事务级实时性

8 月 16-18 日,第十四届中国数据库技术大会(DTCC 2023)在北京召开。酷克数据资深解决方案架构师陈义贤在“数据库内核•技术创新”专场发表题为“分布式数仓的 TP 能力探索—HashData UnionStore”的演讲,介绍 HashData 以 Log is database 的思路在分布式数据仓库提升 TP 性能改造中的技术方案及未来发展规划。
演讲精彩观点:
01、在数据业务化的背景下,企业对数仓实时性能力提出越来越高的要求,OLAP 和 OLTP 会发生进一步的融合。
02、存算分离架构将成为未来数据架构的基本要求,云原生架构的核心理念是将存算分离,使用对象存储来保存一份全域数据,所有计算集群均为无状态,按需申请使用,也可以兼容各种不同计算引擎,满足各类不同业务的需求。
03、存算解耦后,使用不同引擎分开处理数据成为可能:Log is database 的理念可以大幅优化数仓的 OLTP 能力,通过将数据随机写入的操作剥离,以日志数据为中介载体,减少了复杂的锁定和同步操作,大幅提升了并发能力,同时减少随机访问带来的成本。
以下为本次演讲文字实录(节选):
近些年,随着企业 IT 建设从信息化演进到数字化,企业对数据应用的需求也经历三个阶段:
在 1.0 阶段,以数据统计查询为主,在此基础上构建相应的系统,服务于部门级的应用。
在 2.0 阶段,企业通过数仓整合远端应用数据,再进一步的进行加工,实现商业智能,为企业决策层提供支撑。
随着大数据技术的发展,企业数据应用已经进入 3.0 阶段。在这一阶段,数据应用越来越丰富,能够更好地服务于企业全体员工。
上述的三个阶段仍是处于信息化阶段,数据只是在业务系统运营产生的副产品。而随着企业数据衍生的价值越来越大,企业在进行系统设计之前,就需要考虑如何更好地管理数据资产。
在这样的的背景下,应用系统成为了物理世界和数字世界的映射的媒介。同时,伴随着 AI 技术的成熟,未来企业数据应用会越来越智能化和自动化,能够自动优化企业的运营策略和业务流程,达成敏捷业务的能力。
随着数据业务化的发展,对数据平台的时效性、准确性和一致性提出了更高的要求,OLTP 和 OLAP 将会进一步地融合。
传统 MPP 分布式数仓提升 OLTP 能力的尝试
目前,MPP 数仓提升 OLTP 能力主要分为两个技术路线:第一种是在 TP 应用场景,由 2PC 转为直接派发,减少 prepare 阶段的实例等待,从而提升单条数据增删改的性能。这种方式的缺点是随着数据分析负载的增加,会额外加大系统开销,造成比较大的延迟。
另一种方式是针对单条记录增删改的数据使用行存表,提升并发性能。
传统分布式 MPP 架构数据库,会将任务并行的分布到多个服务器和节点上,并在完成计算后,将结果返回并汇总,从而完成对海量数据的分析处理。随着业务的增长,企业需要增加服务器去提升整个集群的数据处理的能力。
由于传统分布式 MPP 架构计算存储紧耦合,当单一集群达到一定的规模时(一般为 200),即使再追加新的计算节点,集群总体性能都会受制于旧的节点,不但不会上升,反而出现下降。
存算分离架构将成为未来数据架构的基本要求
“存算分离”技术的出现,很好地解决了传统 MPP 架构数据库的“痛点”。云原生架构的核心理念就是存算分离,使用对象存储来保存一份全域数据,所有计算集群均为无状态,按需申请使用,也可以兼容各种不同计算引擎,满足各类不同业务的需求。
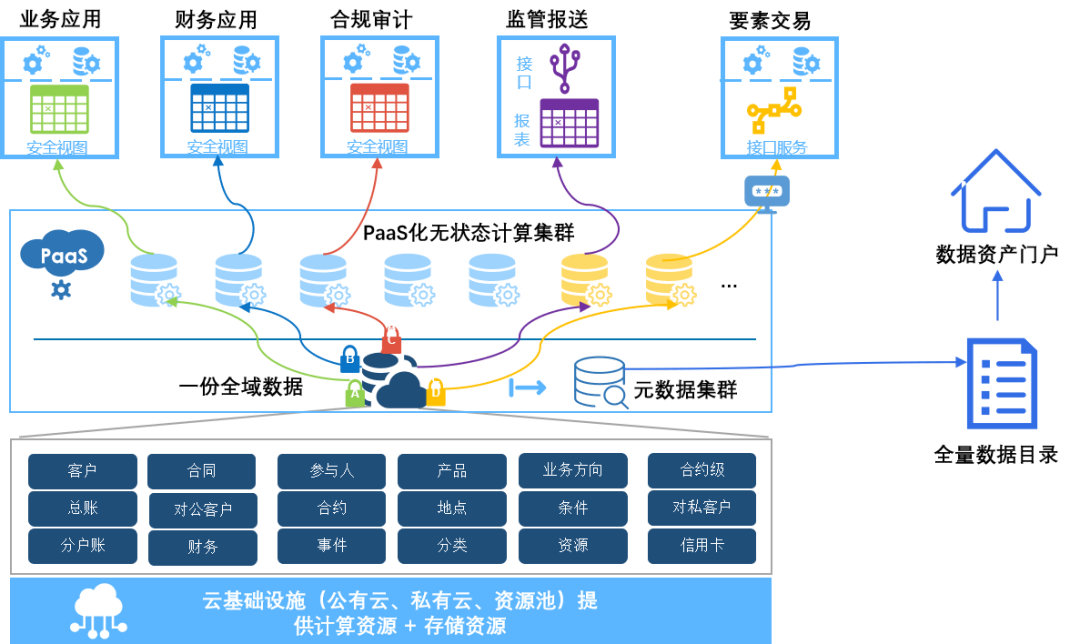
图 1:HashData 在某国有大行存算分离落地方案示意图
以 HashData 云数仓为例,多个集群共享统一的元数据、统一的数据存储,由统一的元数据集群提供与数据资产目录的动态连接。当底层数据发生变化的时候,数据资产目录可以同步进行更新,为企业数据资产运营、数据治理以及数据安全管理提供了相应的支撑能力。
同时,得益于存算分离的架构,HashData 通过一致性哈希来避免数据重新逻辑分组,通过共享存储避免数据重新物理分布,可以实现集群的秒级自动扩缩容。
HashData UnionStore 技术创新
存算解耦后,使用不同引擎分开处理数据成为可能:“Log is database”(日志即数据库)是一种基于日志的数据库架构思想,它可以提升 OLTP 系统的性能。
Log is database 通过将数据随机写入的操作剥离,计算集群只将 WAL 日志提交至 HashData UnionStore 集群,由 UnionStore 集群处理日志数据,并重放生成新的页数据,这样减少了复杂的锁定和同步操作,可以大幅提升并发能力,同时也减少随机访问。
Log is database 提升数仓 TP 性能体现在以下几个方面:
减少磁盘随机访问:传统的数据库系统需要将数据写入磁盘的数据文件中,这可能导致频繁的磁盘随机访问,对性能造成负面影响。而日志数据库将所有的数据更改操作都追加到日志中,这样可以将磁盘写入操作转变为连续的顺序写入操作,大大减少了磁盘的随机访问,提高了性能。
异步提交:传统的数据库系统在每个事务提交时都需要将数据写入磁盘,这会引入较高的延迟。而日志数据库采用异步提交的方式,即先将数据更改操作写入日志,然后异步地将日志中的操作批量写入磁盘。这种方式可以减少磁盘写入的次数和延迟,进一步提升性能。
并发控制优化:日志数据库可以利用日志记录事务操作的特性来进行并发控制的优化。多个事务可以并发地写入日志,而不需要进行复杂的锁定和同步操作。这种并发控制的优化可以提高系统的并发性能和吞吐量。
批处理优化:日志数据库通常将多个操作合并成批处理操作进行处理。通过批处理操作,可以减少磁盘写入的次数,进一步提高性能。例如,将多个更新操作合并成一个批处理操作,可以减少每个操作的开销和磁盘访问次数。
重放优化:日志数据库可以通过重放日志来恢复和重建数据库状态。在系统启动时,可以通过重放日志中的操作,按照顺序将数据更改应用到数据库中,从而快速恢复数据库的一致状态,而无需执行大量的随机访问和数据恢复操作。

图 2:HashData UnionStore 架构图
在内核层面,HashData 对 UnionStore 集群进行了以下优化:
Wal Service:在数据库中,WAL 是一种持久性存储技术,它可以确保数据库在重启或崩溃时不会丢失数据。在 WAL 机制下,数据库在写入数据之前,会首先写入一份日志记录,用于记录写入的数据信息。为了保证日志持久化之后的可靠性,日志通常会保存三副本。由 leader 节点负责接收计算集群请求,本地持久化同时将日志发送到 follower 节点,当所有节点都完成日志持久化之后,leader 节点才会返回给计算集群。
Safekeeper 为每一个租户启动了 Wal Writer 线程,负责进行日志持久化以及状态监控、选举。Safekeeper leader 会为每个 follower 启动一个 Wal Syncer 线程,专门负责同步日志以及发送心跳。
Page Service:主要负责从 Wal Service(safekeeper leader)获取已经持久化日志并进行解析,通过重放日志去修改 page 数据;此外还会对计算集群提供更新后的 Page 读取服务。
Page 存储形式:引入了快照机制,Page Service 将当前日志作为 page 的 delta log,通过 base page+delta log 方式来构建对应 page 的多版本。
Time Travel:HashData 通过 UnionStore 对底层数据存储的快照化设计,结合重做日志,赋予数据仓库“时间旅行”的能力。比如使用 LSN 700 读取 Page1,则 Page Service 会先获取 base page,然后根据 LSN 700 确定 delta log 范围,然后将日志按顺序 apply 到 base page v2,生成对应 page 版本返回。
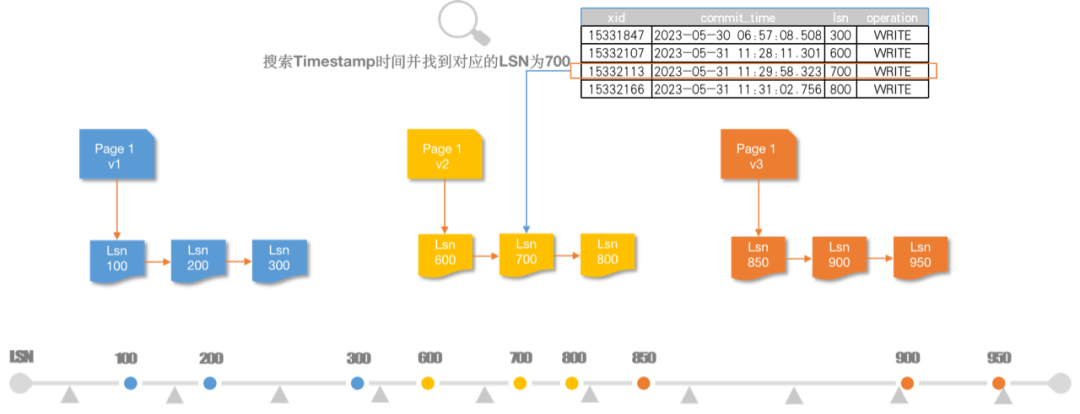
图 3:Time Travel 示例图
Time Travel 可广泛应用于以下场景,为数据库的操作管理提供极大的便利:
恢复数据库对象:通过追溯 Page 版本和 LSN,可以将数据恢复到任意时间点。误删除的表,Shcema 和库,可以直接将数据恢复到误操作之前时间点。
查询历史数据:可以查询任意时间点的数据,简单快速。获取数据在某个时间段的变更历史、增量统计用于决策分析;例如通过 CDC 数据入库,可以在不制作拉链表的情况下,直接选择统计数据的时间点。
历史数据克隆:创建任意时间点数据的拷贝,辅助数据模型训练。基于某个时间点训练结果创建多份数据拷贝,使用不同参数进行训练,对比训练结果。
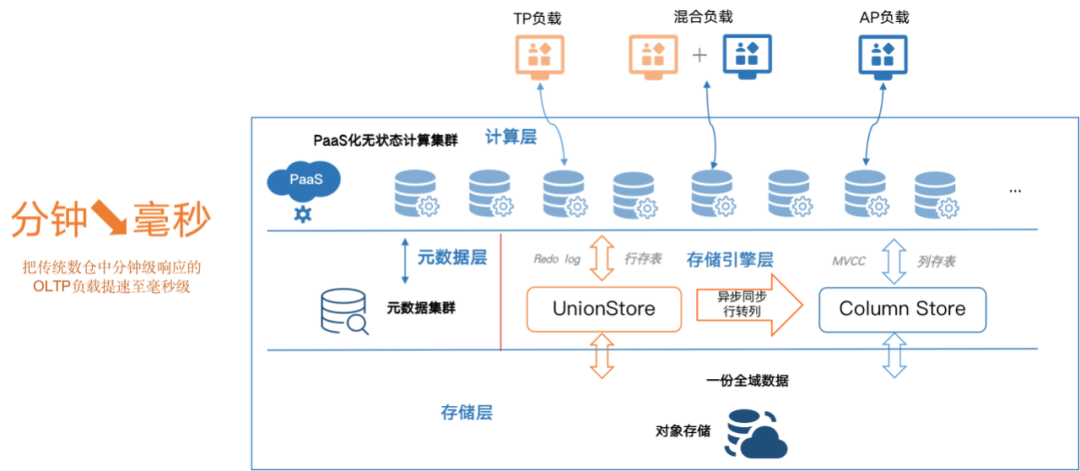
图 4:HashData 云原生统一架构 HTAP 数据平台
通过以上技术创新和优化,HashData 将可以支持数据跑批、流式计算、混合负载、数据增删改高效转化等应用场景,达成准实时数仓的能力,更好地助力企业构建 onedata 体系。
版权声明: 本文为 InfoQ 作者【HashData】的原创文章。
原文链接:【http://xie.infoq.cn/article/4228b06ae71fb71d9d3256667】。文章转载请联系作者。

还未添加个人签名 2021-03-10 加入
云原生企业级数据仓库









评论