
任务编排:CompletableFuture 从入门到精通
最近遇到了一个业务场景,涉及到多数据源之间的请求的流程编排,正好看到了一篇某团介绍 CompletableFuture 原理和使用的技术文章,主要还是涉及使用层面。网上很多文章涉及原理的部分讲的不是特别详细且比较抽象。因为涉及到多线程的工具必须要理解原理,不然一旦遇到问题排查起来就只能凭玄学,正好借此梳理一下 CompletableFuture 的工作原理
背景
我们把 Runnable 理解为最基本的线程任务,只具备在线程下执行一段逻辑的能力。为了获取执行的返回值,创造了 Callable 和与其配合使用的 Future。为了将任务之间进行逻辑编排,就诞生了 CompletableFuture。关于如何理解任务的逻辑编排,举一个简单的例子:
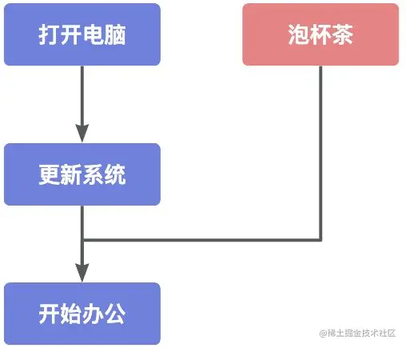
打开电脑-更新系统这两个操作是有先后顺序的,但是泡茶和这两个操作没有先后顺序,是可以并行的,而开始办公必须要等待其他操作结束之后才能进行,这就形成了任务编排的执行链。
在 IO 密集型系统中,类似的场景有很多。因为不同数据集的查询依赖主键不同,A 数据集的查询主键是 B 数据集的一个字段这种情况很常见,通常还需要并发查询多个数据集的数据,所以对于多线程的执行编排是有需求的。
一种解决办法是 CountDownLatch,让线程执行到某个地方后进行等待,直到依赖的任务执行结束。对于一些简单的执行链是可以满足的,但是当编排逻辑复杂起来,CountDownLatch 会导致代码难以维护和调试。所以诞生了 CompletableFuture 用来描述和维护任务之间的依赖关系以进行任务编排。在实际应用中,有以下两类场景是适合使用任务编排的:
多数据源请求的流程编排
非阻塞化网关等 NIO 场景
使用方式
创建与执行
同步方法
和 FutureTask 类似,CompletableFuture 也通过 get()方法获取执行结果。但是不同的是,CompletableFuture 本身可以不承载可执行的任务(相比 FutureTask 则必须承载一个可执行的任务 Callable),通过一个用于标记执行成功并设置返回值的函数,在使用上也更为灵活,如下:
执行结果:success
和 Future 类似,get()函数也是同步阻塞的,调用 get 函数后线程会阻塞直到调用 complete 方法标记任务已经执行成功。
除了手动触发任务的完成,也可以让创建对象的同时就标记任务完成:
执行结果:success
异步方法
相比于同步方法,异步执行更为常见。比如下面这个例子:
执行结果:do something by threadForkJoinPool.commonPool-worker-9success
supplyAsync 方法接收一个 Supplier 对象,逻辑函数交给线程池中的线程异步执行

默认会使用 ForkJoinPool 的公共线程池来执行代码(不推荐),当然也可以指定线程池,如下:
执行结果:do something by threadpool-1-thread-1success
如果不需要执行结果,也可以用 runAsync 方法:
执行结果:do something by threadForkJoinPool.commonPool-worker-9
多任务编排
多任务编排是 CompletableFuture 的核心,这里列举不同的场景来进行说明
一元依赖
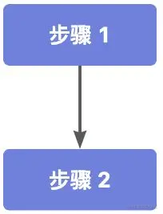
步骤 2 需要依赖步骤 1 执行完毕才能执行,类似主线程的顺序执行,可以通过以下方式实现:
执行结果:执行【步骤 1】上一步操作结果为:【步骤 1 的执行结果】步骤 2 的执行结果:【步骤 2 的执行结果】
通过 thenApply 方法,接收上一个 CompletableFuture 对象的返回值,其中隐含的逻辑是,该处逻辑只有等上一个 CompletableFuture 对象执行完后才会执行。
二元依赖
相比于一元依赖的顺序执行链,二元依赖更为常见,比如下面这个场景:
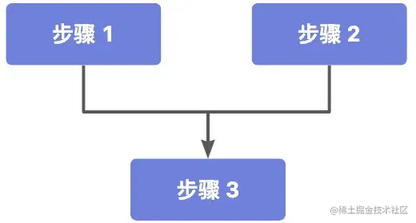
步骤 1 和 2 是并行的,而步骤 3 需要等步骤 1 和 2 执行完之后才能执行,通过 CompletableFuture 是这么实现的:
执行结果:执行【步骤 1】执行【步骤 2】前两步操作结果分别为:【步骤 1 的执行结果】【步骤 2 的执行结果】步骤 3 的执行结果:【步骤 3 的执行结果】
通过 thenCombine 方法,等待 step1 和 step2 都执行完毕后,获取其返回结果并执行一段新的逻辑
多元依赖
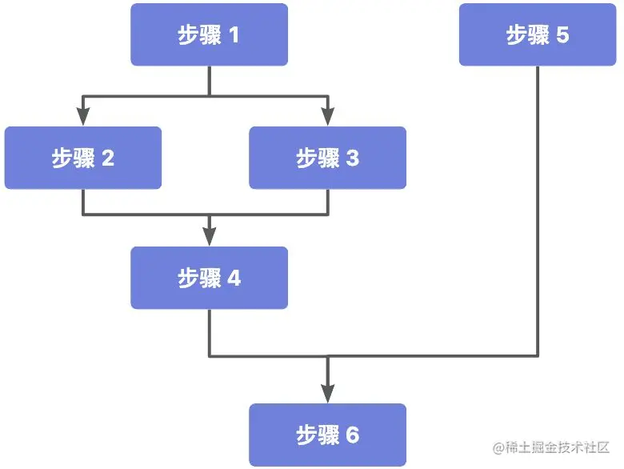
当然还可能有下面这种场景,步骤 M 需要依赖 1-N 的 N 个前置节点:
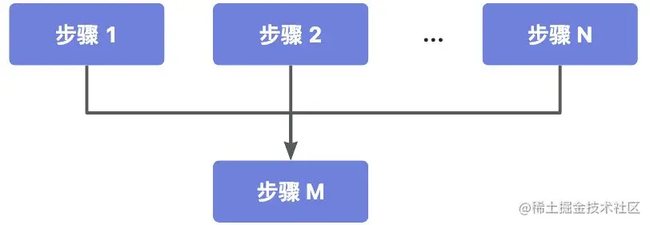
这种情况会更为复杂,实现方式如下:
执行结果:执行【步骤 1】执行【步骤 2】执行【步骤 3】步骤 M 的结果:【步骤 1 的执行结果】【步骤 2 的执行结果】【步骤 3 的执行结果】
通过 allOf 函数声明当参数中的所有任务执行完毕后,才会执行下一步操作,但是要注意,allOf 本身只是定义节点,真正阻塞的位置是 thenApply 函数。
和之前的方式不同,由于采用了不定变量,所以要通过 CompletableFuture#join 来获取每个任务的返回值。
除了 allOf 之外,如果我们需要任意一个任务完成后就执行下一步操作,可以使用 anyOf 方法,如下:
执行结果:步骤 M 的结果:【步骤 1 的执行结果】
与 allOf 不同,anyOf 的返回值即为第一个执行完毕的任务
工作原理
概念
在讲原理之前,先来了解一下 CompletableFuture 的定义。在实现上,CompletableFuture 继承了 Future 和 CompletionStage
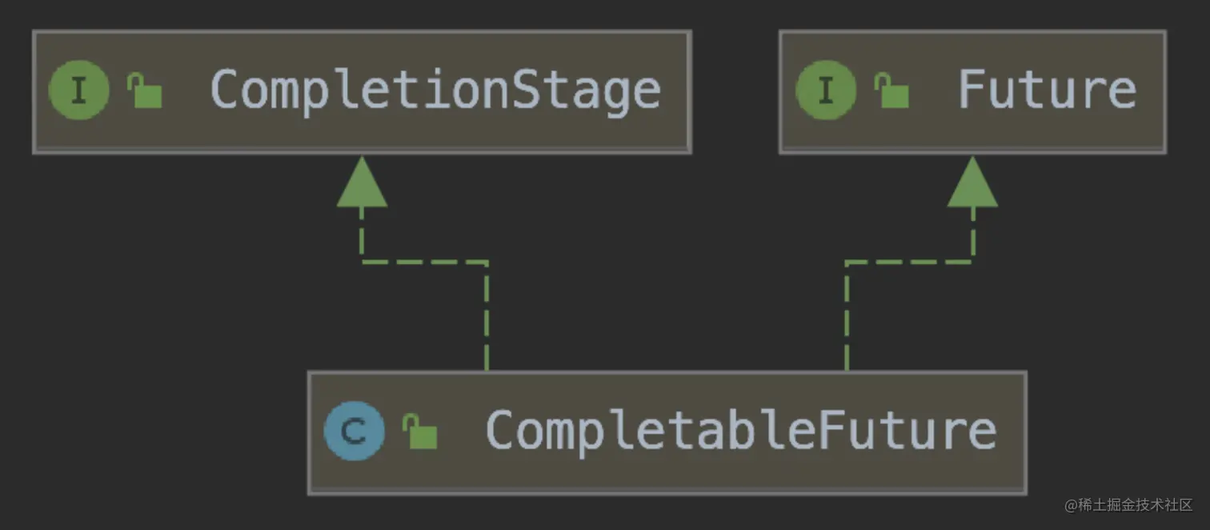
Future 毋庸置疑,CompletableFuture 最基本的能力就是获取异步计算的结果。CompletionStage 则是声明了编排节点的能力,每一个 CompletionStage 都声明了流程树上的一个节点(见下图):
CompletionStage 声明的接口 thenXXX,包括 thenApply、thenCompose 等,定义了节点之间的连接方式(实际情况更为复杂,具体原理参考下节函数分析),通过这种方式,最终定义出一颗流程树,进而实现了多线程的任务编排。CompletionStage 的方法返回值通常是另一个 CompletionStage,进而构成了链式调用。
结构分析
CompletableFuture 里包含两个变量,result 和 stack
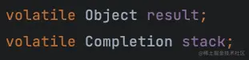
result 很好理解,就是当前节点的执行结果。stack 就比较复杂,是一个无锁并发栈,声明了当前节点执行完毕后要触发的节点列表,接下来我们详细讲一下
CompletableFuture 中的栈设计
Completion 是一个无锁并发栈,声明了当前节点执行完毕后要触发的节点列表。在结构上是一个链式节点,其中只包含了一个指向下一个节点的 next 对象

我们可以看到 Completion 有繁多的实现类,表示不同的依赖方式。
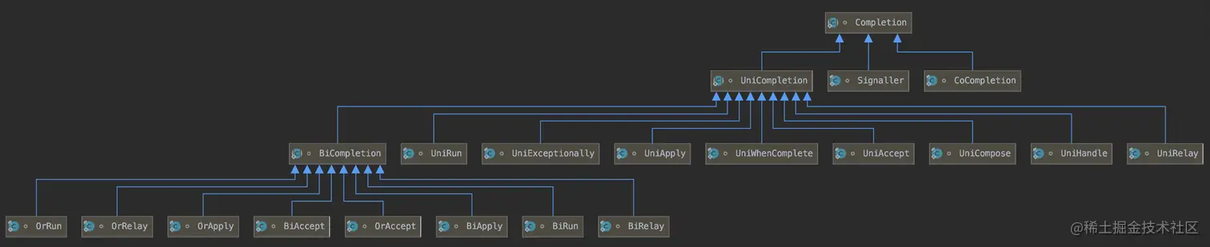
我们知道,在 CompletableFuture 中的流程编排是通过 thenApply、thenAccept、thenCombine 等方式来实现的:
thenApply:接收上一步的处理结果,进行下一步消费,并返回结果
thenAccept:和 thenApply 类似,不过无结果返回
thenCombine:同时接收两个流程节点,等其都执行完毕后一起处理结果
每个函数实际分别对应了一种 Completion 实现类,以刚才的三种函数为例,分别对应了 UniApply、UniAccept、UniCombine 三个对象。所以 Completion 可以认为是流程编排逻辑的抽象对象,可以理解为流程节点,或者任务节点。
以 UniCompletion 为例,结构如下:
先来看 claim 函数,这个比较容易解释,该函数用于判断任务是否可被执行。通过 compareAndSetForkJoinTaskTag 函数的 CAS 操作保证只有一个线程执行成功,主要作用就是在多线程情况下确保任务的正确执行。
接下来就是重头戏,源任务与依赖任务,这两个概念是 CompletableFuture 的核心,贯穿了所有逻辑的执行,只有理解了这两个概念,才能对执行原理有比较透彻的理解
源任务与依赖任务
源任务和依赖任务在 UniCompletion 中分别为 src 和 dep 属性,举个具体的例子,比如下面这段代码:
调用 a.thenApply(Function fn)时,可以认为是生成了一个 UniApply 的流程节点(具体怎么生成的下文会提到),其中源任务就是 a,而依赖任务则是 thenApply 的返回值。
换个简单的说法,在上面的代码中,我们有 a、b 两个任务,b 任务的完成需要依赖于 a 任务的完成,所以 a 会生成一个流程节点(UniApply 对象),其中包含了 b 想要执行完成的全部资源(a 的执行结果等),这时 a 任务就叫做源任务(因为 a 任务中有任务资源)。而 b 任务需要依赖 a 任务来完成,所以 b 任务叫做依赖任务。
源任务的完成会触发依赖任务的执行,这个就是任务编排的基本原理
函数分析
在本节中,CompletableFuture 由于名字太长,会以 cf 来代指。
由于 thenAccept、thenCombine 函数等逻辑比较类似,我们以最基础的 thenApply 函数为例进行分析。
核心函数
我们先不要直接从 thenApply、complete 等函数入手,我们先来看这几个核心函数,不明白做什么的不要紧,先理解这几个函数的原理就好。
uniApply
CompletableFuture 的逻辑在于“只有当 X 条件满足时,再执行 Y 逻辑”,uniApply 函数就是负责这样的逻辑判断,首先看源码:
整个方法可以分为三段(已在代码中标出),我们分开来说。
第一段,判断所给的任务节点是否已经执行完毕,如果已经执行完毕则进入下一步
第二段,如果有关联的流程节点,则通过 claim 函数判断当前任务是否可被执行,如果可执行则进入下一步(确保多线程情况下任务的正确执行)
第三段,执行传入的函数并把值设置到当前对象中。
整个逻辑是这样的,首先我们传入了一个 cf 对象、一个函数,和一个流程节点。只有当传入的 cf 对象执行完成(result 不为空),再执行给定的函数,并把执行结果设置到当前对象中。如果不考虑特殊情况,uniApply 方法用一句话解释就是:如果给定的任务已经执行完毕,就执行传入的函数并把执行结果设置到当前对象中
tryFire
uniApply 函数仅仅是一个有条件的函数执行器,真正想要达到任务编排还需要其他函数的参与,我们先来看 tryFire 方法:
tryFire 根据关联关系的不同有多种实现,实际执行流程相差不大,这里以常用的 UniApply 的实现来举例。
首先这个方法接收了一个 mode 参数,有以下几种取值:
-1:传播模式,或者叫嵌套模式。表示任务实际已经执行完毕,只是在传递状态
0:同步模式。任务由当前线程调用处理
1:异步模式。任务需要提交到指定线程池处理
根据 mode 的不同,实际 tryFire 执行的流程也会发生很大区别。不过归根到底,tryFire 方法的本质是调用了 uniApply 执行一次任务,如果执行成功,则会清空 dep、src 等自身属性(清空之后 isLive 方法会返回 false,表示任务已经执行完毕),同时通过 postFire 方法执行该任务下的其他依赖任务,实现任务的传播执行。
postFire 方法由于和 tryFire 方法关联比较密切,这里放在一起说明:
这里简单概括一下执行原理,如果是嵌套模式,则清理栈内无效任务,并返回对象本身(可以认为什么都没做);否则通过 postComplete 方法执行栈内依赖此任务的其他任务项。
postComplete
当一个 CompletionStage 执行完成之后,会触发依赖它的其他 CompletionStage 的执行,这些 Stage 的执行又会触发新一批的 Stage 执行,这就是任务的顺序编排。
如果说 uniApply 是基础功能,是负责线程安全且遵守依赖顺序地执行一个函数,那么 postComplete 就是核心逻辑,负责当一个任务执行完毕后触发依赖该任务的其他任务项,先来看源码:
在源码上标记了三个位置,分别代表三层结构:
第一层 while 循环,只要当前对象栈中还有流程节点,那么就循环执行内部逻辑。
第二层,由于 continue 的存在,和第一层结合起来看就是一个批量压栈的操作,将所有需要触发的依赖树按顺序压入当前对象栈中。
第三层,通过 tryFire 按顺序触发栈中所有的依赖任务。上节我们可以看到 tryFire 函数内根据 mode 的不同会触发不同的逻辑,这里 mode 指定为 NESTED 就是为了避免循环调用 postComplete
执行函数
几个核心函数介绍完了,接下来我们回到最外层,来看看任务是如何执行的,首先我们以 thenApply 为例分析核心执行函数。
supplyAsync(实际调用为 asyncSupplyStage)
该方法用于提交一个任务到线程池中执行,并将该任务打包为一个 CompletableFuture 节点
其中 AsyncSupply 实现了 Runnable 接口,所以理解为一种特殊的任务即可。这种任务在执行完成后会调用 completeValue 将函数执行的结果设置当前对象中。
所以整体逻辑为,首先创建一个 cf 对象,并立即将任务添加到线程池执行,在执行完毕后会将任务执行的结果保存到所创建的 cf 对象中。
complete
该方法直接调用 completeValue 方法设置值,设置完值之后调用 postComplete 方法来依次执行后续任务。当调用该方法时,会实现任务的依赖扩散执行
thenApply(实际调用为 uniApplyStage)
结合上节分析的核心函数,我们很容易可以分析该函数的流程:执行 function 函数,如果条件不满足则执行失败,会生成一个流程节点并压入栈,同时再通过 tryFire 再尝试执行一次,如果条件依然不满足,那么只能等待所依赖的任务执行完成后通过 postComplete 触发执行。
get
方法核心在于 waitingGet,内部使用了 ForkJoinPool.managedBlock 来阻塞线程直到执行完毕
流程分析
在函数分析中,我们实际已经说明了任务依赖执行的基本原理,这里为了更为详细地说明,我们以一个简单的例子来分析。
首先我们抛开一切复杂的因素,以最基本的同步串行代码来讲,我们现在有这样一个对象:
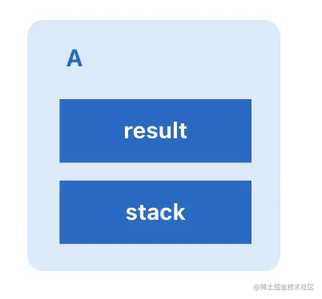
然后我们这时候给其加上了任务编排,增加了一个 thenApply 依赖。
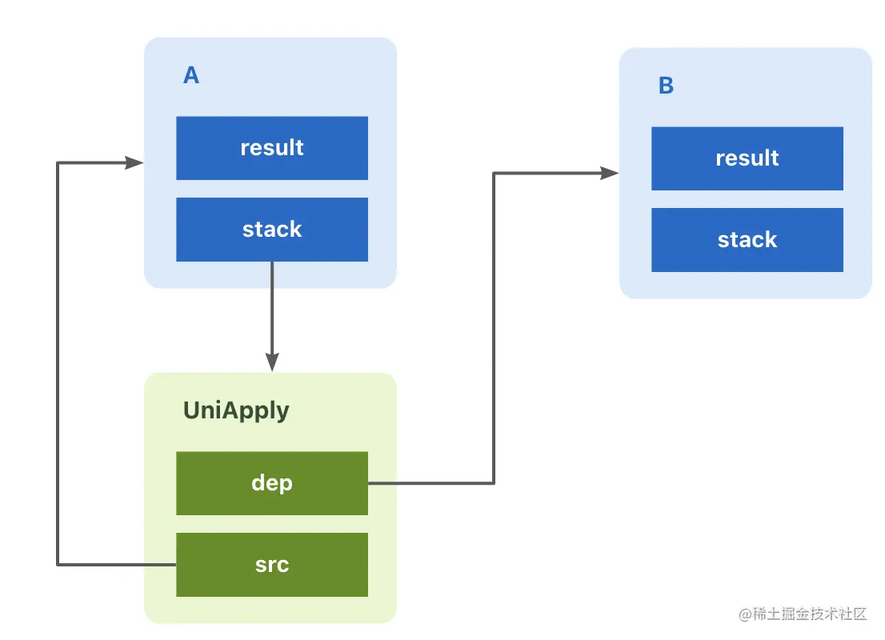
于是我们就有了这样一个结构,A 的 stack 中压入了一个 Completion 节点,该节点的源任务指向 A 本身,而依赖任务指向了 B,表示 B 任务依赖 A 任务的执行。
接下来我们再加一条依赖:
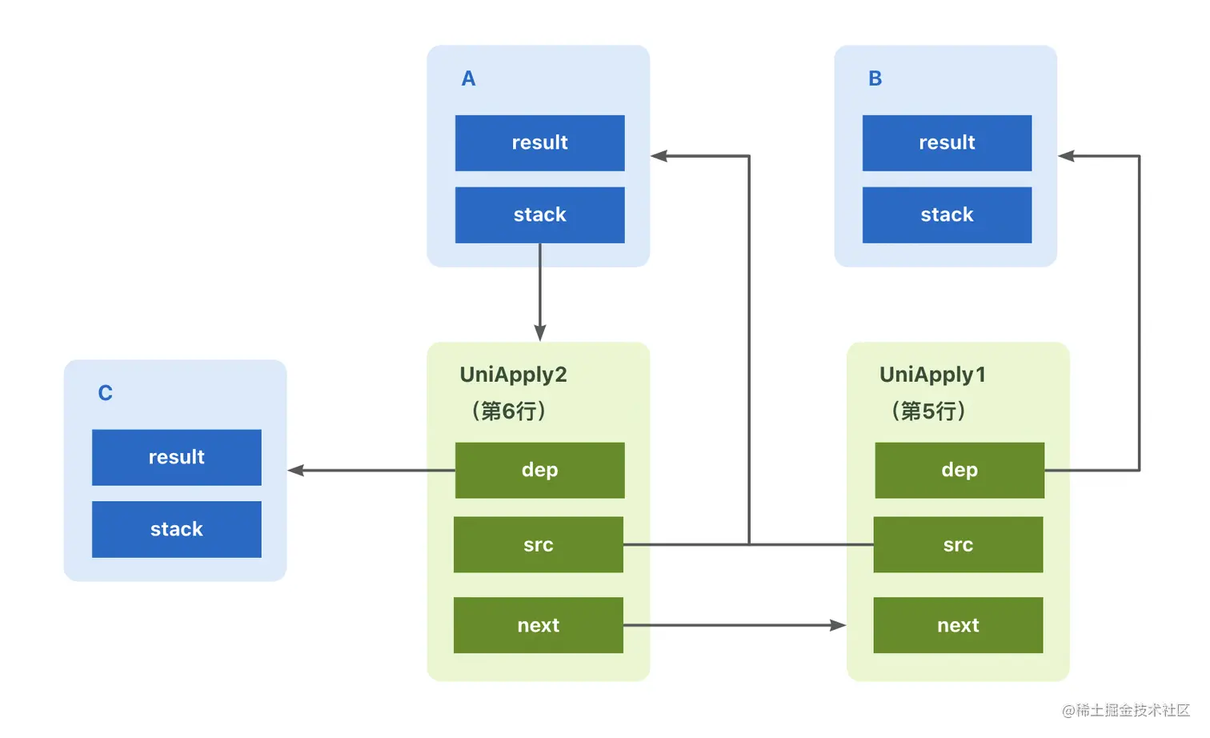
我们会发现两个特点:
和栈的性质一样,越晚添加的编排逻辑越早被执行
基于同一个对象衍生出来的流程节点的源任务是一致的
以此类推,thenXXX 的其他逻辑也是类似的原理,当 a 调用 complete 函数时(无论是同步还是异步),都会依次触发 A 任务的 stack 下挂接的其他依赖任务。而只要 a 没有调用 complete 函数,那么 thenApply 中挂接的依赖任务无论如何都无法执行(因为 a 对象的 result 属性为空)
注意事项
避免主任务和子任务向同一个线程池中申请线程,由于存在依赖关系,当通过 join 来获取子任务的值时,一旦子任务由于线程队列已满进入阻塞队列,那么将会形成死锁。
作者:Kripath_Rion
链接:https://juejin.cn/post/7212466685450207290
来源:稀土掘金

还未添加个人签名 2021-07-28 加入
公众号:该用户快成仙了









评论