
Java 项目中对使用递归的理解分享
一、什么是递归
1.1 基本概念
这里就有必要简单介绍一下关于递归的基本概念了。
在 Java 中,递归是指在方法的定义中调用自身的过程,递归是基于方法调用栈的原理实现的:当一个方法被调用时,会在调用栈中创建一个对应的栈帧,包含方法的参数、局部变量和返回地址等信息。在递归中,方法会在自身的定义中调用自身,这会导致多个相同方法的栈帧依次入栈。当满足终止条件时,递归开始回溯,栈帧依次出栈,方法得以执行完毕。
递归的关键是定义好递归的终止条件和递归调用的条件。如果没有适当的终止条件或递归调用的条件不满足,递归可能会陷入无限循环,导致栈内存溢出。
1.2 优缺点
优点:
简化问题:递归能够将复杂问题分解成更小规模的子问题,简化了问题的解决过程;
实现高效算法:递归在某些算法中能够实现高效的解决方法,如数据结构操作中遍历树节点等。
缺点:
栈溢出风险:递归可能导致方法调用栈过深,造成栈内存溢出;
性能损耗:递归调用需要创建多个栈帧,对系统资源有一定的消耗;
可读性不高:递归的使用需要谨慎,不合理地使用可能造成代码难以理解和调试。
1.3 与迭代的区别
迭代(Iteration)
迭代常见于 for 循环中:比如有一个集合 A,对 A 进行 foreach,在内部设置条件,符合条件后将集合中某个元素的值替换成别的值。
迭代示例简图
结果为:
迭代结果简图
递归(Recursion)
递归的例子会在下一小节详细给出。
二、实际案例
下面笔者以递归获取某个评论 id 下面所有的子级评论 id 为例子,向大家介绍这个递归的过程。
首先,这里给出一个简单的数据库评论表的 demo,id 是主键 id 也是评论唯一 id,parent_id 是该条评论的父评论 id,status 为 1 表示审核通过的状态。
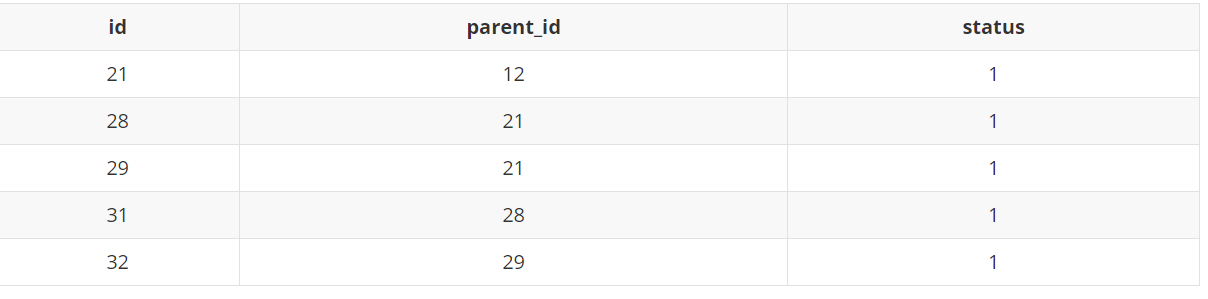
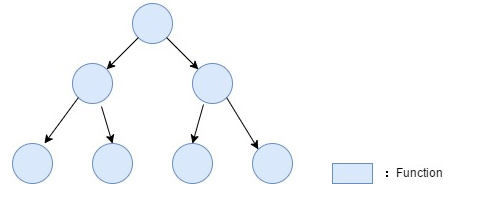
其中,我们可以简单发现:这里 21 为第一层,28 和 29 为第二层、31 和 32 为第三层,草图如下所示:
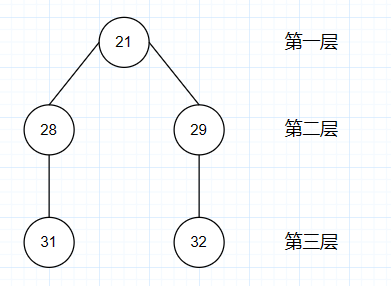
评论 id 简单层级示意图
那么,我们如何将 21、28、29、31、32 都放进一个集合里返回呢?下面的代码示例可以给你一个参考。
但是,在看代码之前,有个问题请你思考一下:
从 21 开始后,遍历的路线是 21-28-29?还是 21-28-31?还是 21-29-32?或者是 21-28-31-29-32?
下面是经过脱敏处理后的参看代码示例,注释都写得比较清楚了:
上面问题的答案是:递归后得到的 id 集合:[21,28,31,29,32],原因就是:迭代会从一棵树开始遍历到底,没有元素了再从头开始遍历,依次迭代,类似于深度优先遍历。
比如:21 下面有两个子 id:28 和 29,那么会先走 21-28-31 这棵树,到底了后接着按照 29-32 遍历。
三、改进方案
我根据自己的开发经验,可以从控制递归层数和改用 Stream 这两种办法来对递归进行改进。
3.1 控制递归层数
JVM 默认控制的递归最大深度限制在 1000 层,可以通过设置 JVM 参数来控制其深度,如:
或者在代码层面对递归的层数进行控制:
3.1 用 Stream 遍历
核心思路是:先数据库全量查询(10 万条以内),内存中使用 Stream 流操作、Lambda 表达式、Java 地址引用进行筛选。
适用于数据总量不多的情况,如:部门树,部门数量一般情况是比较固定的,一个组织或者公司最多也就几百上千个部门。
四、文章小结
笔者确实不推荐在项目中过度使用递归,但是合理使用的话也能成为解决特定问题的一个利器,至于怎么拿捏这个度,那就要看大家的具体情况了。
Java 项目中对使用递归的理解分享到这里就结束了,文章如有不足和错误,或者你有更好的解决思路,欢迎大家的指正和交流!
文章转载自:CodeBlogMan

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论