
分享 6 个 SQL 小技巧
简介
经常有小哥发出疑问,SQL 还能这么写?我经常笑着回应,SQL 确实可以这么写。其实 SQL 学起来简单,用起来也简单,但它还是能写出很多变化,这些变化读懂它不难,但要自己 Get 到这些变化,可能需要想一会或在网上找一会。
各种 join
关于 join 的介绍,比较流行的就是这张图了,如下:
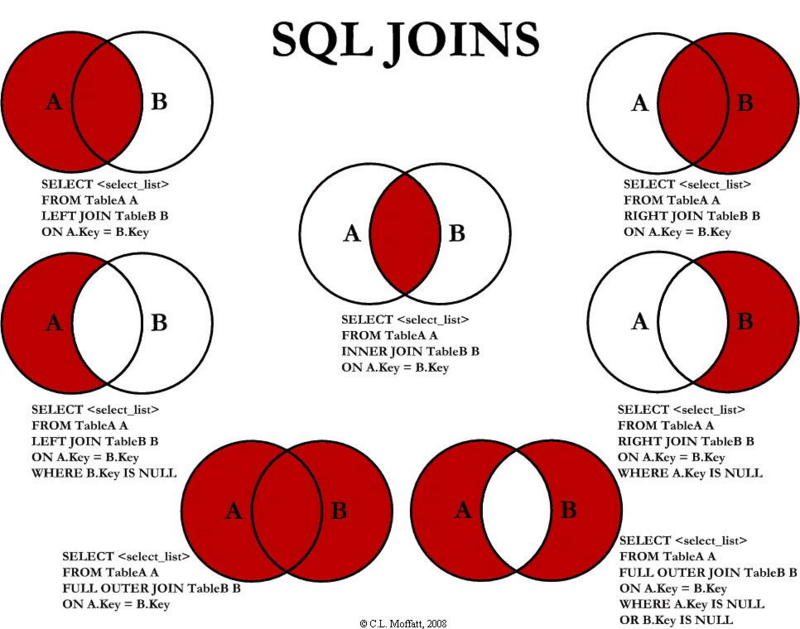
简单的解释如下:
join:内联接,也可写成 inner join,取两表关联字段相交的那部分数据。
left join:左外联接,也可写成 left outer join,取左表数据,若关联不到右表,右表为空。
right join:右外联接,也可写成 right outer join,取右表数据,若关联不到左表,左表为空。
full join:全联接,也可写成 full outer join,取左表和右表中所有数据。
但注意上图,里面还有几个Key is null的情况,它可以将两表相交的那部分数据排除掉!也正是因为这个特性,一种很常见的 SQL 技巧是,用left join可替换not exists、not in等相关子查询,如下:
也比较好理解,只有当左表的数据在右表中不存在时,B.Key is null才成立。
查询各类别最大的那条数据
比如在学籍管理系统中,有一类很常见的需求,查询每学科分数最高的那条数据,有如下几种写法:
比较好理解,考分最高其实就是过滤出分数等于最大分数的记录。
在不能使用子查询的场景下,也可转换成 join,如下:
这和前面用 left join 改写 not exists 类似,通过s1.id is null过滤出 left join 关联条件不满足时的数据,什么情况 left join 关联条件不满足呢,当 s 表记录是分数最大的那条记录时,s1.score > s.score条件自然就不成立了,所以它过滤出来的数据,就是学科中分数最大的那条记录。
一直以来,我看到 SQL 的 join 的条件大都是 a.field=b.field 这种形式,导致我以为 join 只能写等值条件,实际上,join 条件和 where 中一样,支持>、<、like、in甚至是 exists 子查询等条件,大家也一定不要忽视了这一点。
上面场景还有一种写法,就是使用 group by 先把各学科最大分算出来,然后再关联出相应数据,如下:
查询各类别 top n 数据
比如在学籍管理系统中,查询每学科分数前 5 的记录,类似这种需求也很常见,比较简单明了的写法如下:
很显然,第 5 名只有 4 个学生比它分数高,第 4 名只有 3 个学生比它分数高,依此类推。
LATERAL join
MySQL8 为 join 提供了一个新的语法 LATERAL,使得被关联表 B 在联接前可以先根据关联表 A 的字段过滤一下,然后再进行关联。
这个新的语法,可以非常简单的解决上面top n的场景,如下:
如上,每个学科查询出它的前 5 名记录,然后再关联起来。
统计多个数量
使用count(*)可以统计数量,但有些场景想统计多个数量,如统计 1 天内单量、1 周内单量、1 月内单量。
用count(*)的话,需要扫描 3 次表,如下:
其实扫描一次表也可以实现,用 sum 来代替 count 即可,如下:
IF 是 mysql 的逻辑判断函数,当其第一个参数为 true 时,返回第二个参数值,即 1,否则返回第三个参数值 0,然后再使用 sum 加起来,就是各条件为 true 的数量了。
数据对比
有时,我们需要对比两个表的数据是否一致,最简单的方法,就是在两边查询出结果集,然后逐行逐字段对比。
但是这样对比的效率比较低下,因为它要两个表的数据全都查出来,其实我们不一定非要都查出来,只要计算出一个 hash 值,然后对比 hash 值即可,如下:
先使用 CONCAT 将要对比的列连接起来,然后使用 CRC32 或 MD5 计算 hash 值,最后使用聚合函数 BIT_XOR 将多行 hash 值异或合并为一个 hash 值。
这个查询最终只会返回 1 条 hash 值,查询数据量大大减少了,数据对比效率就上去了。
总结
SQL 看起来简单,其实有很多细节与技巧,如果你也有其它技巧,欢迎留言分享讨论😃
作者:打码日记

还未添加个人签名 2023-06-19 加入
还未添加个人简介









评论