
网络性能问题排查思路

网络性能问题排查思路
网络问题往往是性能排查中最复杂的一个问题,因为网络问题往往涉及的链路比较长,排查起来不仅仅是看本地机器的指标就可以了。本文将展示一个比较系统的排查网络问题的思路。
我们往往都是通过类似 prometheus,grafana 搭建的监控平台对机器的各项指标进行监控,其中就包括网络性能,当发现指标异常后,你就需要定位到具体的进程了,定位到进程还没完,你还需要定位到进程中是哪段代码引发的这个问题。整个过程你可以看到是一个大范围到小范围逐步定位的过程,大致分为 3 个步骤:
1,系统层面发现问题
2,定位到具体异常进程
3,定位到进程中引发异常的代码段
你就像侦探一样,一层层抽丝剥茧,排查过程十分有趣。
接下来,我们来挨个看看,具体每个步骤,我们应该如何做?
从系统层面发现网络问题
衡量网络性能,往往我们会根据几个重要的指标,来挨个看看。
首先是 网卡流入流出的流量 ,衡量流量大小也是有几种单位方式,MBS 代表每秒多少个 MB 字节,Mbps 代表每秒多少个 M 比特位,他们的换算关系是 MBS = Mbps / 8。
接着一个指标是 每秒收发包的数量 英文是 pps,一个完整的网络请求是其实是分成很多个网络包进行发送的,在描述网卡性能时,一般都是将 流入流出流量大小和 pps 大小结合起来阐述。
然后是另一个指标 丢包数 当产生丢包行为时,可能会因为 tcp 的重传机制,让丢了的包重新发送到对端,但是重传必然会导致网络延迟的增大,当丢包数急剧上升时,我们也认为这是网络的一个异常表现。
丢包数或者丢包率指标我认为 是 pps 和流入流出的流量 功能 不太一样的指标类型,pps 和流入流出的流量我把它们称作流量类型的网络指标,通过它们,能够知道网络流量的大小,而丢包数 是则是形容网络传输的好坏。
好了,说完了几个指标,再谈谈如何用上系统工具来实际的观察下这些指标值,不然与纸上谈兵又有何异。
可以使用 sar 命令 每 1 秒统计一次网络接口的发包数以及进出流量,连续显示 5 次。
IFACE:网络接口名称。
rxpck/s、txpck/s:每秒收或发的数据包数量。
rxkB/s、txkB/s:每秒收或发的字节数,以 kB/s 为单位。
rxcmp/s、txcmp/s:每秒收或发的压缩过的数据包数量。
rxmcst/s:每秒收到的多播数据包。
sar 不能看到 丢包数的指标信息 ,因为丢包问题涉及的链路较长,我将放在此文的后面专门阐述。但是起码 sar 能够看 pps 以及进出流量了。不过这个只是从系统层面宏观的看网络情况,当你发现系统层面流量异常后,如何定位到是哪个进程导致流量异常的呢?
从进程角度看网络情况
接下来,我们从进程的进程来看网络情况。观察的内容还是和系统层面差不多,不外乎就是进出流量,发送数据包等等。我将介绍两种工具,对比起系统层面看网络情况,它们能从更低的维度看网络情况。
首先是 iftop 工具,它能找出是哪个 ip 消耗流量最多。
=> 和<= 代表网络包的流向,每一行右边有 3 列变化的值,分别是在 2s 内,10s 内,40s 内的平均每秒流量的大小,而在 iftop 输出的最下面,则是系统整体的网络流量情况了。但是这样只能看 ip,如果定位到进程呢?iftop 可以根据目的地址和源地址聚合流量,当进入 iftop 输出界面时,按 s 就是按源地址聚合流量,按 d 则是按目的地址聚合流量。 默认 iftop 输出界面时不显示端口的,但如果要按端口维度对流量进行区分,需要在 iftop 输出界面,按 S 或者 D,S 和 D 分别代表按源地址的端口对流量进行划分,D 代表按目的地址端口对流量进行划分。
当在 iftop 界面 分别按 S 和 d 后,将会得到主机上按端口维度进行区分的流量情况。如下所示:
这样便能看到主机上是哪个端口占用的流程最高了,有了端口就能很好的定位到进程了。
关于 iftop 一些高级用法可以通道 man iftop 去查看,这里就不再展开了
对比起 iftop 而言,有个更简单帮助我们查看进程上网络情况的工具,叫做 nethogs。
查看进程占用带宽情况 ,命令如下:
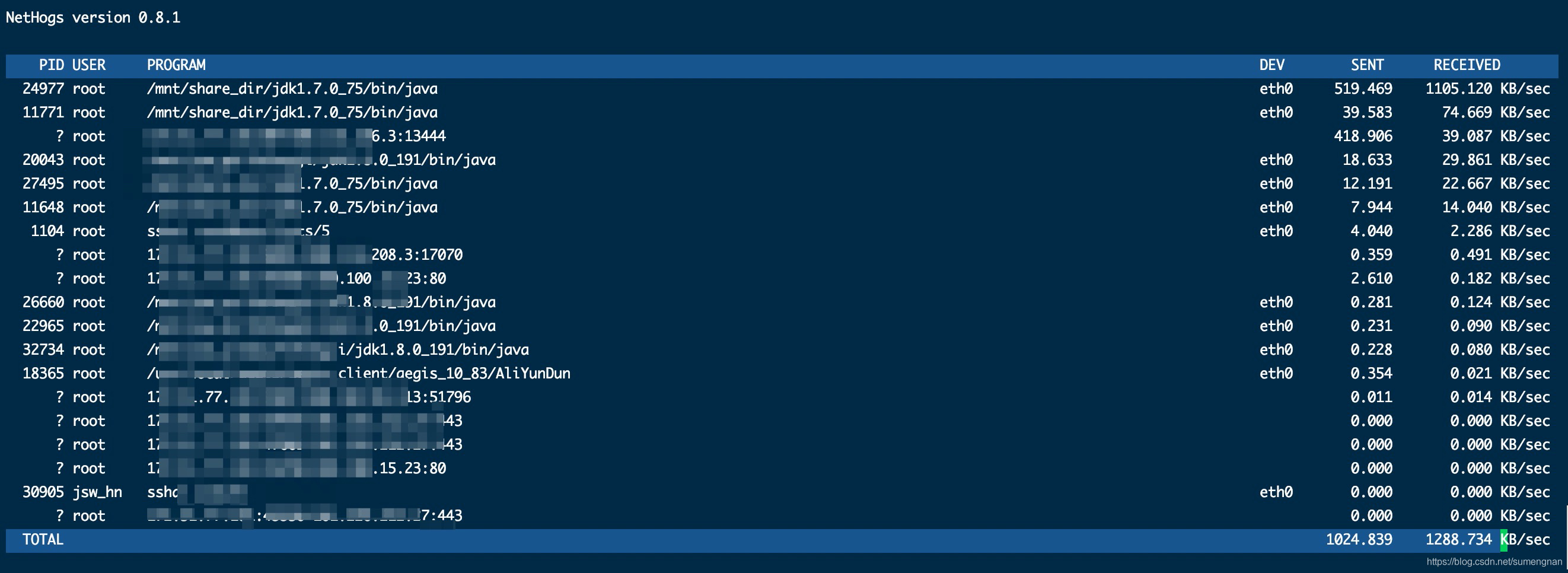
查看 nethogs 的输出,每一行最后则是进程瞬时每秒的发送与接收的流量。通过 nethogs,我们可以直接定位到是哪个进程有流量异常产生。
如何定位到具体代码
通过 iftop 和 nethogs 命令,我们可以定位是哪个进程产生的流量异常了,但是如何定位到具体的代码呢?
由于我比较熟悉 golang,这里介绍下用 go 开发的程序,可以怎么找出流量异常的代码,golang 自带有分析网络延迟的工具 go trace 可以查看网络调度延迟。 如果是 go 开发的程序 发生流量异常,相信通过 go trace 的 grapgh 能找到 网络延迟最高的一部分代码,定位到问题。关于 go trace 的原理以及使用,我在golang pprof 监控系列(1) —— go trace 统计原理与使用的详细的介绍。
有了上述的排查思路,相信在面对流量异常的情况,我们能很快的找到具体是哪段代码引发的异常了。接下来我们来谈谈如何排查丢包问题。
如何查找丢包问题
tcp ip 模型已经成为事实标准,网络包会经过 tcp,ip 模型的几个层次,发送和接收的每一个步骤都有可能产生丢包。排查的过程则是检查每一个步骤是否有丢包行为产生。
首先来看下应用层丢包如何排查。
应用层
内核在监听套接字的时候,在三次握手时,会创建两个队列,在服务器收到 syn 包时,会创建半连接队列,并将这条握手未完成的连接 放到里面,然后回复 ack,syn 包给客户端,当客户端回复 ack 时,内核会将这条连接放到全连接队列里,调用 accept 就是将连接从全连接队列里取出。
如果半连接队列或者全连接队列满了,则可能发生丢包行为。
半连接队列
半连接队列大小由内核参数 tcp_max_syn_backlog 定义。
另外,上述行为受到内核参数 tcp_syncookies 的影响,若启用 syncookie 机制,当半连接队列溢出时,并不会直接丢弃 SYN 包,而是回复带有 syncookie 的 SYN+ACK 包,设计的目的是防范 SYN Flood 造成正常请求服务不可用。
如何确认是半连接导致的丢包呢,我们可以通过下面的命令。
dmesg 可以查看内核的输出日志,如果半连接有丢包产生,那么 dmesg 会看到对应的输出。
半连接队列的连接数量也可以通过 netstat 命令统计 SYN_RECV 状态的连接得知。因为在 3 次握手时,收到 syn 包的连接的状态是 SYN_RECV 状态,而整个状态的持续时间是很短的,如果用 netstat 发现 SYN_RECV 状态的连接非常多,则说明半连接队列可能满了。
接着我们来看下分析全连接队列相关的命令。
全连接队列
ss 命令可以查看全连接队列大小
Recv-Q:当前全连接队列的大小,也就是当前已完成三次握手并等待服务端 accept() 的 TCP 连接;Send-Q:当前全连接最大队列长度,上面的输出结果说明监听 8088 端口的 TCP 服务,最大全连接长度为 128;listen 的全连接大小可以在 listen 系统调用的时候指定 go 源码里读取的是 /proc/sys/net/core/somaxconn 里的值。
Recv-Q:已收到但未被应用进程读取的字节数;Send-Q:已发送但未收到确认的字节数;
当全连接队列满了后,默认内核会将包丢弃,但是也可以指定其他策略。
0 :如果全连接队列满了,那么 server 扔掉 client 发过来的 ack ;1 :如果全连接队列满了,server 发送一个 reset 包给 client,表示废掉这个握手过程和这个连接;
通过查看应用层的全连接队列的相关指标,相信你能够定位 那些由于应用进程处理包缓慢导致的丢包场景了,因为应用进程处理包缓慢,持续小于 网卡的接包速度的话,将导致全连接队列很快就满了,导致丢包。
接着我们来看下传输层,网络层的丢包场景。
传输层,网络层
之所以把这两者放到一起进行讲解,因为很多工具的分析都横跨了这两个层次。
防火墙导致的丢包
先来看下其中的防火墙导致丢包的情况,除了防火墙本身配置 DROP 规则导致丢包外,与防火墙有关的还有连接跟踪表 nf_conntrack,Linux 为每个经过内核网络栈的数据包,生成一个新的连接记录项,当服务器处理的连接过多时,连接跟踪表被打满,服务器会丢弃新建连接的数据包。
以下命令可以查看 nf_conntrack 表最大连接数
tcp 丢包以及原因计数
用 nstat 命令 查看网络协议层丢包情况以及丢包原因,命令如下。
其实 netstat -s 命令也可以看 tcp 层的丢包情况,不过我还是强烈建议将 它换为 nstat 命令因为 nstat 效率更高,并且统计的内容命名也更符合 rfc 文档规范。
nstat 除了列出丢包的情况,还有其他统计信息,具体每个指标的含义可以参考 这个文档
此外,网络层 mtu 的设置有时可能导致丢包的产生,如果发送的 mtu 包的大小超过网卡规定的大小,并且网卡不允许分片,那么则会产生丢包。
接着就是链路层丢包的场景了。
链路层
链路层是物理网卡丢包的场景了,统计链路层丢包的数据可以用 netstat 得到。netstat 可以统计网卡环形缓冲区溢出(RX-OVR,TX-OVR),以及网卡发生错误(RX-ERR,TX-ERR)的次数。
版权声明: 本文为 InfoQ 作者【蓝胖子的编程梦】的原创文章。
原文链接:【http://xie.infoq.cn/article/34ede3dd88624ab8317ea4365】。文章转载请联系作者。

还未添加个人签名 2020-09-17 加入
还未添加个人简介









评论