
GPT 大语言模型引爆强化学习与语言生成模型的热潮、带你了解 RLHF。

GPT 大语言模型引爆强化学习与语言生成模型的热潮、带你了解 RLHF。

随着 ChatGPT 的爆火,强化学习(Reinforcement Learning)和语言生成模型(Language Model)的结合开始变得越来越受人关注。
有关 ChatGPT 的视频讲解可以参考这里。
该项目的详细介绍可以参考这里。

在这个项目中,我们将通过开源项目 trl 搭建一个通过强化学习算法(PPO)来更新语言模型(GPT-2)的几个示例,包括:
基于中文情感识别模型的正向评论生成机器人(No Human Reward)
基于人工打分的正向评论生成机器人(With Human Reward)
基于排序序列(Rank List)训练一个奖励模型(Reward Model)
排序序列(Rank List)标注平台
1. 基于中文情感识别模型的正向评论生成机器人(No Human Reward)
考虑现在我们有一个现成的语言模型(示例中选用中文的 GPT2),通过一小段 prompt,模型能够继续生成一段文字,例如:
我们现在希望语言模型能够学会生成「正向情感」的好评,而当前的 GPT 模型是不具备「情绪识别」能力的,如上面两个生成结果都不符合正面情绪。
为此,我们期望通过「强化学习」的方法来进化现有 GPT 模型,使其能够学会尽可能的生成「正面情感」的评论。
在强化学习中,当模型生成一个结果时,我们需要告知模型这个结果的得分(reward)是多少,即我们为模型的每一个生成结果打分,例如:
如果依靠人工为每一个输出打分,这将是一个非常漫长的过程(在另一个示例中我们将实现该功能)。
因此,我们引入另一个「情绪识别模型」来模拟人工给出的分数。
「情绪识别模型」我们选用 transformers 中内置的 sentiment-analysis pipeline 来实现。
该模型基于网络评论数据集训练,能够对句子进行「正向、负向」的情绪判别,如下所示:
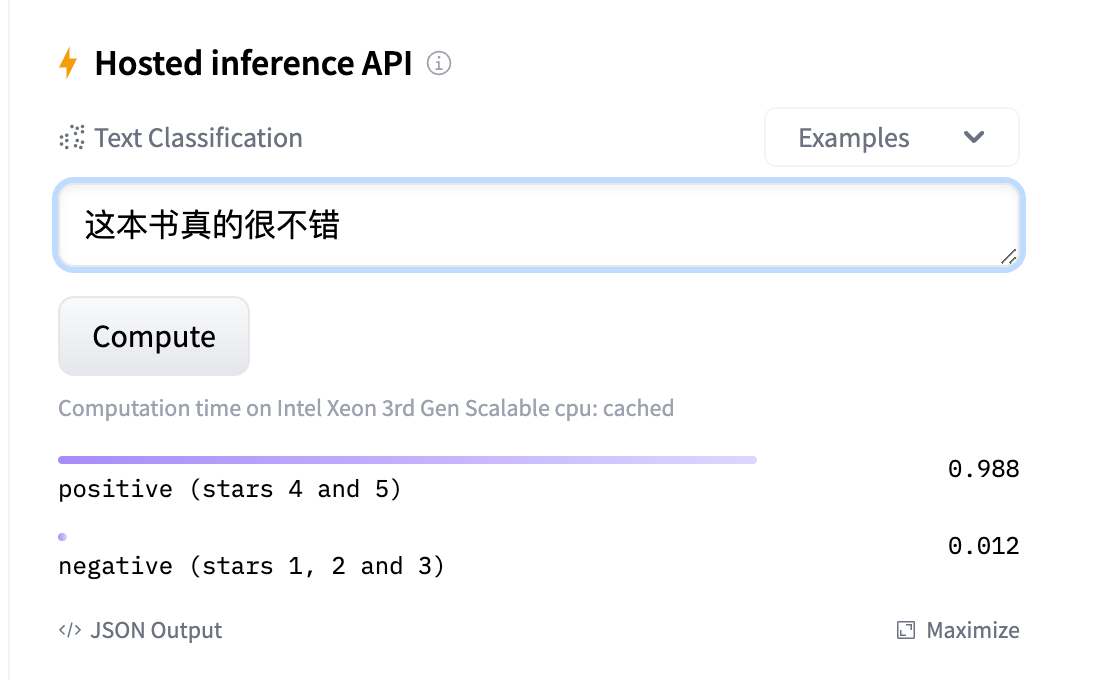
我们利用该「情感识别模型」的判别结果(0.0~1.0)作为 GPT 生成模型的 reward,以指导 GPT 模型通过强化学习(PPO)算法进行迭代更新。
1.1 训练流程
整个 PPO + GPT2 的训练流程如下所示:
随机选择一个
prompt,如:"这部电影很"GPT 模型根据
prompt生成答案,如:"这部电影很 好 看 哦 ~ "将 GPT 的生成答案喂给「情绪识别」模型,并得到评分(reward),如:0.9
利用评分(reward)对 GPT 模型进行优化。
重复该循环,直到训练结束为止。
1.2 开始训练
本项目基于 pytorch + transformers 实现,运行前请安装相关依赖包:
运行训练脚本:
正常启动训练后,终端会打印如下数据:
其中 mean-reward 代表该 epoch 下模型的平均得分(来自「情绪识别模型」的反馈),Random Sample 代表该模型在当前 epoch 生成的句子样例。
在 logs/PPO-Sentiment-Zh.png 下会保存模型训练过程中的各个指标变化(包括 reward 变化曲线):
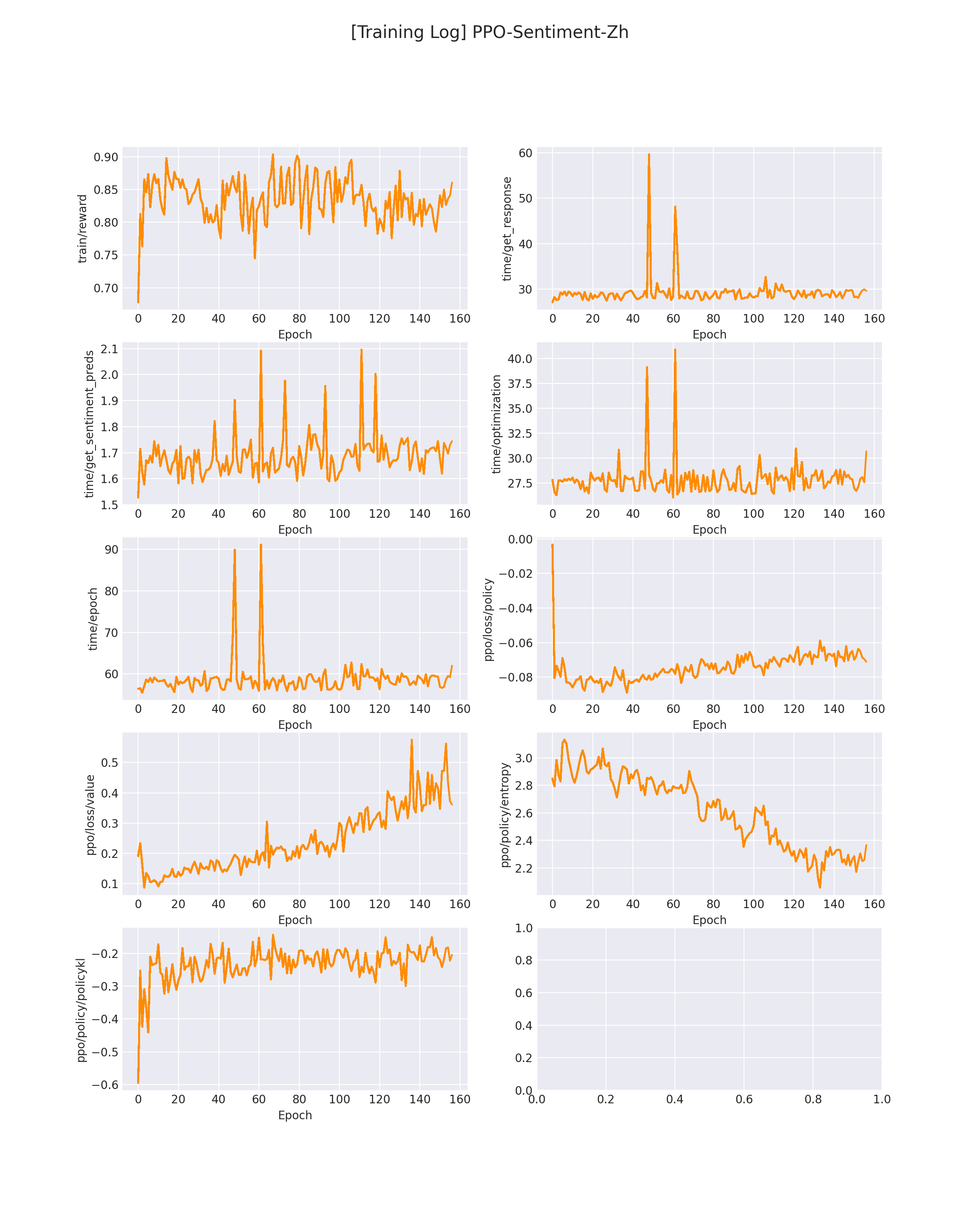
在模型刚开始训练的时候,GPT 会生成一些比较随机的答案,此时的平均 reward 也不会很高,会生成一些「负面」情绪的评论(如下所示):

随着训练,GPT 会慢慢学会偏向「正面」的情绪评论(如下所示):

2. 基于人工打分的评论生成机器人(With Human Reward)
在第一个示例中,模型的 reward 来自于另一个模型。
在该示例中,我们将制作一个平台来支持人工进行打分。
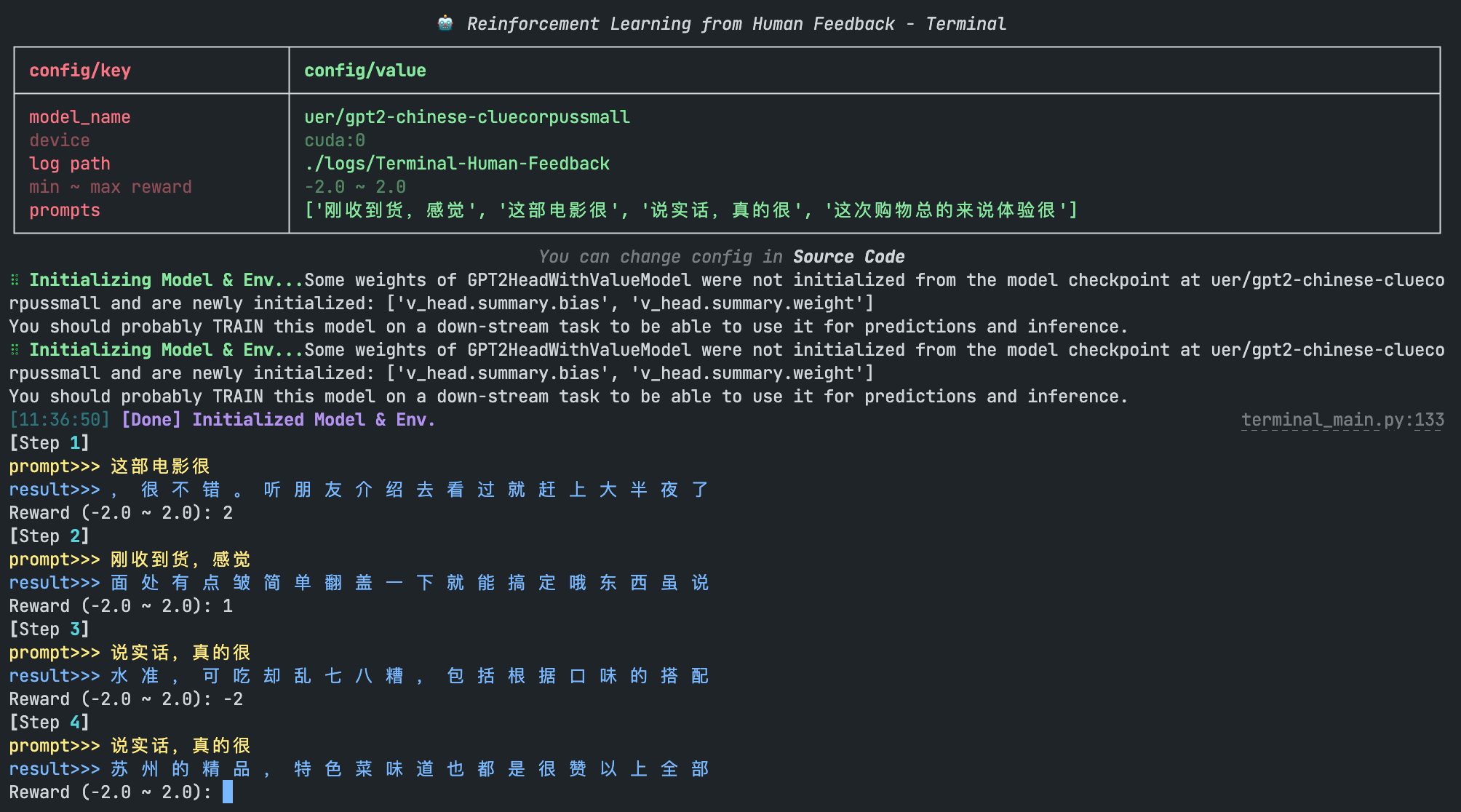
我们启动标注平台:
随后我们可以在终端看到模型的生成结果,通过人工输入 reward 以迭代模型:
3. 基于人工排序训练 Reward Model
通过排序序列训练打分模型。
训练数据集在 data/reward_datasets/sentiment_analysis,每一行是一个排序序列(用\t 符号隔开)。
排在越前面的越偏「正向情绪」,排在越后面越「负向情绪」。
开启训练脚本:
成功开始训练后,终端会打印以下信息:
在 logs/reward_model/sentiment_analysis/ERNIE Reward Model.png 会存放训练曲线图:

完成训练后,我们运行预测脚本,可以看到训练后的模型的打分效果:
我们输入两句评论句子:
可以看到「正向评论」得到了 10.6 分,而「负向评论」得到了 -9.26 分。
<br>
4. 人工排序(RankList)标注平台
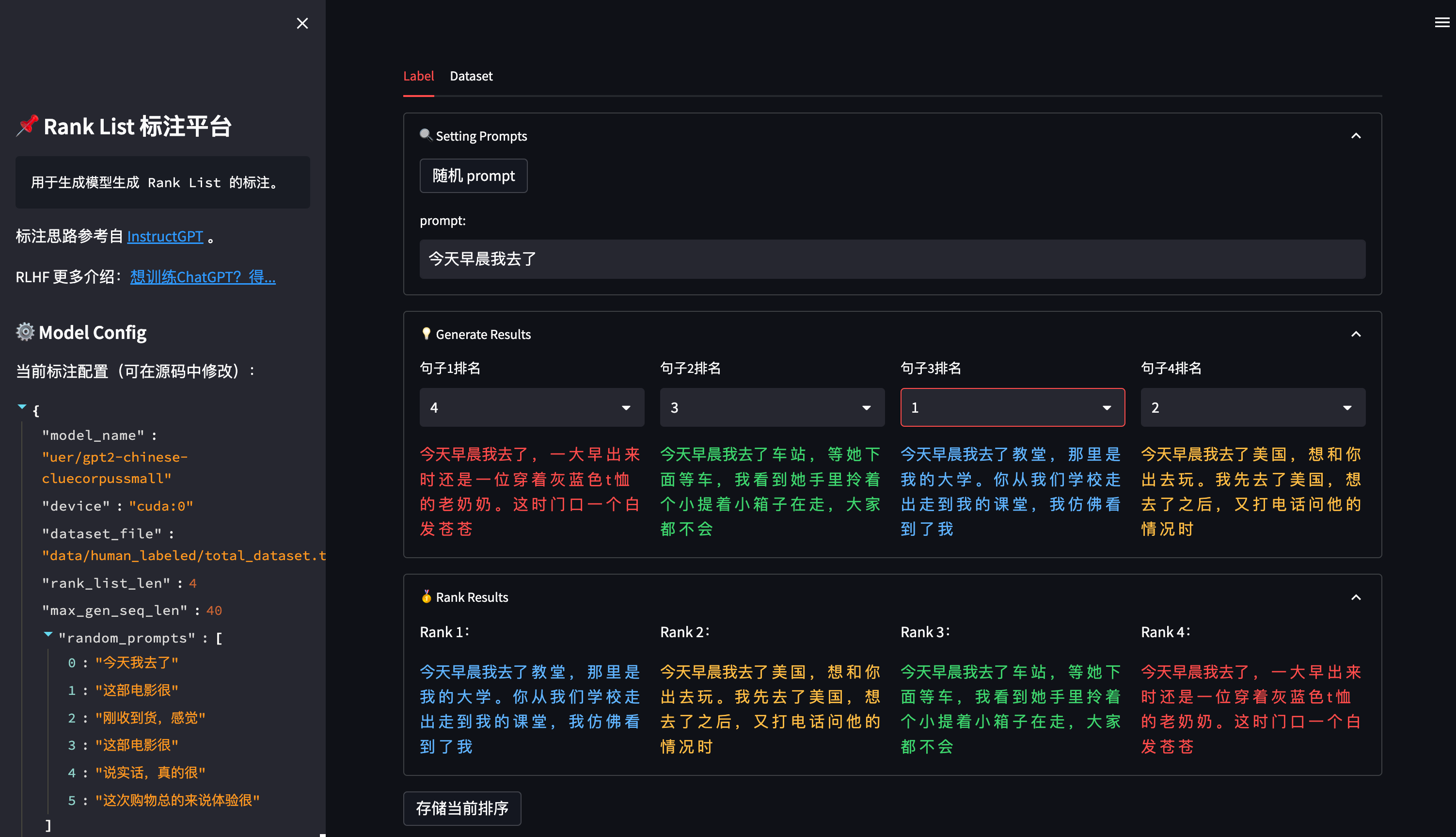
对于第三步 Reward Model 训练,若想自定义的排序数据集,可以使用该项目中提供的标注工具:
平台使用 streamlit 搭建,因此使用前需要先安装三方包:
随后,运行以下命令开启标注平台:
在浏览器中访问 ip + 端口(默认 8904, 可在 sh start_ranklist_labler.sh 中修改端口号)即可打开标注平台。
点击 随机 prompt 按钮可以从 prompt 池 中随机选择一个 prompt(prompt 池可以在 ranklist_labeler.py 中修改 MODEL_CONFIG['random_prompts'])。
通过对模型生成的 4 个答案进行排序,得到从高分到低分的排序序列,点击底部的 存储当前排序 按钮将当前排序存入本地数据集中。
数据集将存储在 data/human_labeled/total_dataset.tsv 中(可在 ranklist_labeler.py 中修改 MODEL_CONFIG['dataset_file'] 参数),每一行是一个 rank_list,用 \t 分割:
也可以点击标注页面上方的 Dataset 按钮,可以查看当前已存储的数据集:
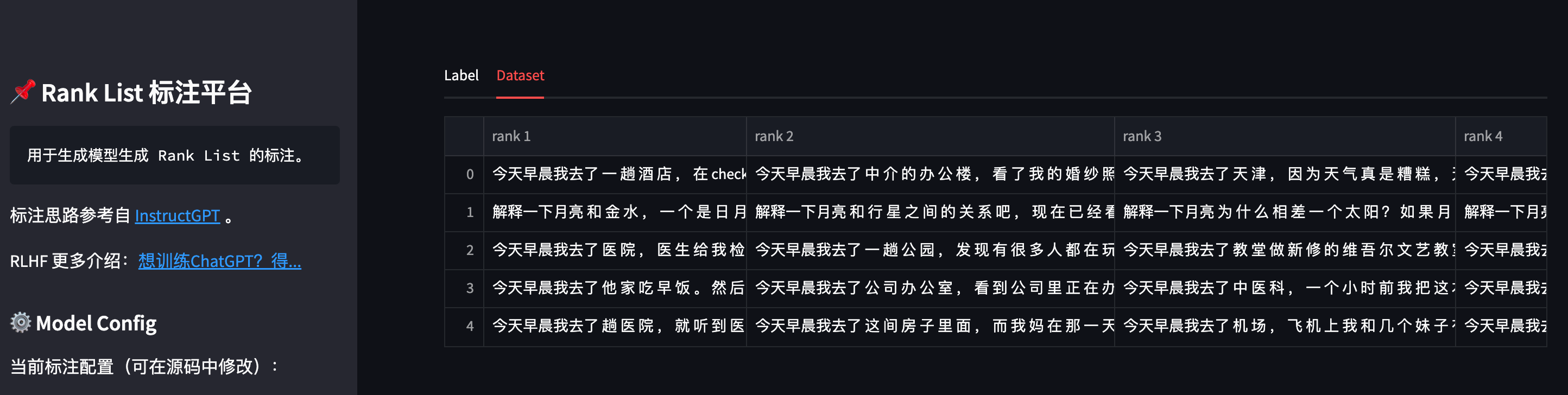
数据标注完成后,即可参照第三步训练一个自定义的 Reward Model。
参考链接:
https://mp.weixin.qq.com/s/1v4Uuc1YAZ9MRr1UWMH9xw
https://zhuanlan.zhihu.com/p/595579042
https://zhuanlan.zhihu.com/p/606328992
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。


版权声明: 本文为 InfoQ 作者【汀丶人工智能】的原创文章。
原文链接:【http://xie.infoq.cn/article/34ea1e50692f99bb7bb22167e】。
本文遵守【CC-BY 4.0】协议,转载请保留原文出处及本版权声明。

本博客将不定期更新关于NLP等领域相关知识 2022-01-06 加入
本博客将不定期更新关于机器学习、强化学习、数据挖掘以及NLP等领域相关知识,以及分享自己学习到的知识技能,感谢大家关注!









评论