
谷歌用 Bard 打响了 Chat GPT 的第一枪,百度版 Chat GPT 何时出炉?


百度 | Bard | Chat GPT
谷歌 | RLHF| ERNIE Bot
随着深度学习、高性能计算、数据分析、数据挖掘、LLM、PPO、NLP 等技术的快速发展,Chat GPT 得到快速发展。Chat GPT 是 OpenAI 开发的大型预训练语言模型,GPT-3 模型的一个变体,经过训练可以在对话中生成类似人类的文本响应。
为了占据 ChatGPT 市场的有利地位,百度谷歌等巨头公司也在运筹帷幄,不断发展。
作为国内液冷服务器知名厂商,蓝海大脑 Chat GPT 深度学习一体机实现了软硬协同的深度优化,在分布式存储加速、智能网络加速等关键性技术上取得重要突破,提供更加出色的云系统性能。采用 NVMe 专属定制的加速引擎,发挥 NVMe 极致性能,全栈的数据传输通道实现分布式存储副本数据传输零损耗。同时,升级智能网络引擎,通过更多类型网卡进行虚拟化调度,释放 CPU 性能,可以使计算资源节约最多达 90%,网络转发速率提高数倍,进一步提升平台性能深受广大 Chat GPT 工作者的喜爱。

深度学习一体机
ChatGPT 的训练过程
在整体技术路线上,Chat GPT 引入了“手动标注数据+强化学习”(RLHF,从人的反馈进行强化学习)来不断 Fine-tune 预训练语言模型。主要目的是让 LLM 模型学会理解人类命令的含义(比如写一篇短文生成问题、知识回答问题、头脑风暴问题等不同类型的命令),让 LLM 学会判断对于给定的提示输入指令(用户的问题)什么样的回答是优质的(富含信息、内容丰富、对用户有帮助、无害、不包含歧视信息等多种标准)。
在“人工标注数据+强化学习”的框架下,具体来说,Chat GPT 的训练过程分为以下三个阶段:
一、第一阶段:监督调优模型
就 GPT 3.5 本身而言,虽然功能强大,但很难理解不同类型人类的不同指令所体现的不同意图,也很难判断生成的内容是否是高质量的结果。为了让 GPT 3.5 初步理解指令中包含的意图,将随机选择一批测试用户提交的 prompt(即指令或问题),由专业标注人员对指定指令提供高质量的答案,然后专业人员标注数据对 GPT 3.5 模型进行微调。通过这个过程,可以假设 GPT 3.5 最初具有理解人类命令中包含的意图并根据这些意图提供相对高质量答案的能力。
第一阶段的首要任务是通过收集数据以训练监督的策略模型。
数据采集:选择提示列表,要求标注者写出预期结果。Chat GPT 使用两种不同的 prompt 来源:一些是直接使用注释者或研究人员生成的,另一些是从 OpenAI 的 API 请求(即来自 GPT-3 用户)获得的。尽管整个过程缓慢且昂贵,但最终结果是一个相对较小的高质量数据集(大概有 12-15k 个数据点),可用于调整预训练语言模型。
模型选择:Chat GPT 开发人员从 GPT-3.5 套件中选择预训练模型,而不是对原始 GPT-3 模型进行微调。使用的基础模型是最新版本的 text-davinci-003(用程序代码调优的 GPT-3 模型)。
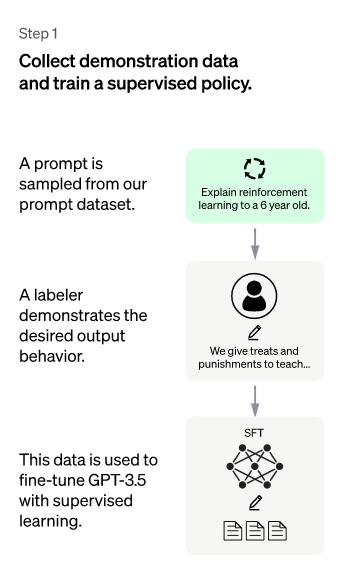
二、第二阶段:训练回报模型
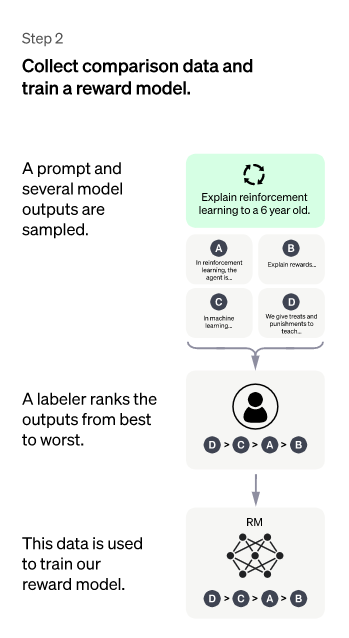
这个阶段的主要目标是通过手动标注训练数据来训练回报模型。具体是随机抽取用户提交的请求 prompt(大部分与第一阶段相同),使用第一阶段 Enhancement 的冷启动模型。对于每个 prompt,冷启动模型都会生成 K 个不同的答案,所以模型会生成数据<prompt, answer1>, <prompt, answer2>....<prompt, answerX>。之后,标注者根据各种标准(上述的相关性、富含信息性、有害信息等诸多标准)对 X 个结果进行排序,并指定 X 个结果的排名顺序,这就是这个阶段人工标注的数据。
接下来,使用这个排名结果数据来训练回报模型。使用的训练方式实际上是常用的 pair-wise learning to rank。对于 X 排序结果,两两组合起来形成一个训练数据对,ChatGPT 使用 pair-wise loss 来训练 Reward Model。RM 模型将 <prompt, answer> 作为输入,并提供奖励分数来评估答案的质量。对于一对训练数据,假设 answer1 排在 answer2 之前,那么 Loss 函数驱动 RM 模型比其他得分更高。
总结一下:在这个阶段,首先冷启动后的监控策略模型对每个 prompt 生成 X 个结果,并根据结果的质量从高到低排序,并作为训练数据,通过 pair-wise learning to rank 模式来训练回报模型。对于学好的 RM 模型来说,输入 <prompt, answer>,并输出结果质量分数。分数越高,答案的质量就越高。其工作原理是:
选择 prompt 列表,SFT 模型为每个命令生成多个输出(4 到 9 之间的任何值);
标注者从最好到最差对输出进行排名。结果是一个新标记的数据集,其大小大约是用于 SFT 模型的确切数据集的 10 倍;
此新数据用于训练 RM 模型。该模型将 SFT 模型的输出作为输入,并按优先顺序对它们进行排序。
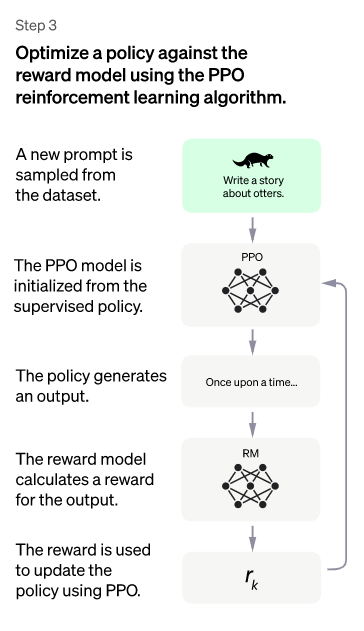
三、第三阶段:使用 PPO 模型微调 SFT 模型
本阶段不需要人工标注数据,而是利用上一阶段学习的 RM 模型,根据 RM 打分结果更新预训练模型参数。具体来说,首先从用户提交的 prompt 中随机选择一批新的指令(指的是不同于第一阶段和第二阶段的新提示),PPO 模型参数由冷启动模型初始化。然后对于随机选取的 prompt,使用 PPO 模型生成答案,使用前一阶段训练好的 RM 模型,提供一个评价答案质量的奖励分数,即 RM 对所有答案给出的整体 reward。有了单词序列的最终回报,每个词可以看作一个时间步长,reward 从后向前依次传递,由此产生的策略梯度可以更新 PPO 模型的参数。这是一个标准化的强化学习过程,目标是生成符合 RM 标准的高质量答案。
如果我们不断重复第二和第三阶段,很明显每次迭代都会让 LLM 模型变得越来越强大。因为在第二阶段,RM 模型的能力通过人工标注数据得到增强,而在第三阶段,增强的 RM 模型更准确地评估新 prompt 生成的答案,并使用强化学习来鼓励 LLM 模型学习新的高质量内容 ,这类似于使用伪标签来扩展高质量的训练数据,从而进一步增强 LLM 模型。显然,第二阶段和第三阶段相辅相成,这就是为什么连续迭代的效果会越来越大。
不过小编认为,在第三阶段实施强化学习策略并不一定是 Chat GPT 模型如此出色的主要原因。假设第三阶段不使用强化学习,而是采用如下方法:与第二阶段类似,对于一个新的 prompt,冷启动模型可能会生成 X 个答案,由 RM 模型打分。我们选择得分最高的答案组成新的训练数据<prompt, answer>,进入 fine-tune LLM 模型。假设换成这种模式,相信效果可能会比强化学习更好。虽然没那么精致,但效果不一定差很多。不管第三阶段采用哪种技术模型,本质上很可能是利用第二阶段学会的 RM,从 LLM 模型中扩展出高质量的训练数据。
以上是 Chat GPT 训练过程。这是一个改进的 instruct GPT。改进主要是标注数据收集方法上的一些差异。其他方面,包括模型结构和训练过程,基本遵循 instruct GPT。估计这种 Reinforcement Learning from Human Feedback 技术会很快扩散到其他内容创作方向,比如一个很容易想到的方向,类似“A machine translation model based on Reinforcement Learning from Human Feedback”等。不过个人认为在 NLP 的内容生成的特定领域采用这项技术并不是很重要,因为 Chat GPT 本身可以处理很多不同类型的任务,基本上涵盖了 NLP 产生的很多子领域。因此,对于 NLP 的某些细分领域,单独使用这项技术的价值并不大,其可行性可以认为是经过 Chat GPT 验证的。如果将该技术应用到其他模式的创作中,比如图像、音频、视频等,这或许是一个值得探索的方向。可能很快就会看到类似“A XXX diffusion model based on Reinforcement Learning from Human Feedback”之类的内容。
Chat GPT 的不足之处
尽管 Chat GPT 好评如潮且商家采用率不断提高,但仍然存在许多缺点。
一、回答缺少连贯性
因为 Chat GPT 只能基于上文且记忆力差,倾向于忘记一些重要的信息。研究人员正在开发一种 AI,可以在预测文本中的下一个字母时查看短期和长期特征。这种策略称为卷积。使用卷积的神经网络可以跟踪足够长的信息以保持主题。
二、有时会存在偏见
因为 Chat GPT 训练数据集是文本,反映了人类的世界观,这不可避免地包含了人类的偏见。如果企业使用 Chat GPT 撰写电子邮件、文章、论文等无需人工审核,则法律和声誉风险会很大。例如,带有种族偏见的文章可能会产生重大后果。
Facebook 的 AI 负责人 Jerome Pesenti 使用 Kumar 的 GPT-3 生成的推文来展示输出如何根据需要使用“犹太人、黑人、女性或大屠杀”等词,其输出可能会变得多么危险。Kumar 认为这些推文是精心挑选的,Pesenti 同意,但回应说“产生种族主义和性别歧视的输出不应该那么容易,尤其是在中立的情况下。”
另外,对 GPT-3 文章的评价也有失偏颇。人类写作文本的风格会因文化和性别而有很大差异。如果 GPT-3 在没有校对的情况下对论文进行评分,GPT-3 论文评分者可能会给学生更高的评分,因为他们的写作风格在训练数据中更为普遍。
三、对事实理解能力较弱
Chat GPT 不能从事实的角度区分是非。例如,Chat GPT 可能会写一个关于独角兽的有趣故事,但 Chat GPT 可能不了解独角兽到底是什么。
四、错误信息/虚假新闻
Chat GPT 可能会创作逼真的新闻或评论文章,这些文章可能会被坏人利用来生成虚假信息,例如虚假故事、虚假通讯或冒充社交媒体帖子,以及带有偏见或辱骂性的语言。或垃圾邮件、网络钓鱼、欺诈性学术论文写作、煽动极端主义和社会工程借口。Chat GPT 很容易成为强大宣传机器的引擎。
五、不适合高风险类别
OpenAI 声明该系统不应该用于“高风险类别”,例如医疗保健。在 Nabra 的博客文章中,作者证实 Chat GPT 可以提供有问题的医疗建议,例如“自杀是个好主意”。Chat GPT 不应在高风险情况下使用,因为尽管有时它给出的结果可能是正确的,但有时会给出错误的答案。在这个领域,正确处理事情是生死攸关的问题。
六、有时产生无用信息
因为 Chat GPT 无法知道哪些输出是正确的,哪些是错误的,并且无法阻止自己向世界传播不适当的内容。使用此类系统生成的内容越多,互联网上产生的内容污染就越多。在互联网上寻找真正有价值的信息变得越来越困难。由于语言模型发出未经检查的话语,可能正在降低互联网内容的质量,使人们更难获得有价值的知识。
谷歌、百度应对 OpenAI 所采取的措施
近日,Chat GPT 聊天机器人风靡全球,轰动一时。这些 AI 产品是众多大厂竞相竞争的对象。2 月 7 日消息,据外媒报道,当地时间周一,谷歌公布了 Chat GPT 的竞争对手 Bard,一款人工智能聊天机器人工具。此外,百度计划在今年 3 月推出类似于 Chat GPT OpenAI 的 AI 聊天机器人服务。
一、谷歌推出 AI 聊天机器人工具 Bard
谷歌 CEO 桑达尔·皮查伊(Sundar Pichai)在一篇博文中宣布了该项目,将该工具描述为一种由 LaMDA(谷歌开发的大型语言模型)支持的“实验性对话式人工智能服务”,将回答用户问题并参与对话。
他还指出,Bard 能够从网络中提取最新信息以提供新鲜、高质量的回复,这意味着 Bard 可能能够以 Chat GPT 难以做到的方式回答有关近期事件的问题。
Pichai 表示,该软件最初将开始面向可信任的测试人员开放,然后在未来几周内更广泛地向公众提供。目前尚不清楚 Bard 将具有哪些功能,但聊天机器人似乎将像美国人工智能研究公司 OpenAI 拥有的 Chat GPT 一样免费使用。
据悉,Chat GPT 由 OpenAI 于 2022 年 11 月 30 日推出,Chat GPT 可以根据用户需求快速创作文章、故事、歌词、散文、笑话,甚至代码,并回答各种问题。Chat GPT 一经发布就在互联网上掀起一股风暴,并受到包括作家、程序员、营销人员在内的用户以及其他公司的青睐。对于 Chat GPT 的走红,Pichai 在公司内部发布了“红色警报”,表示将在 2023 年围绕 Chat GPT 全面适配谷歌在 AI 方面的工作。上周,皮查伊表示,谷歌将在未来几周或几个月内推出自己的 AI 语言建模工具,类似于 Chat GPT。

二、百度 Chat GPT 产品官宣确认:文心一言 3 月完成内测
值得注意的是,据外媒报道百度计划在今年 3 月推出类似于 Chat GPT OpenAI 的人工智能聊天机器人服务。初始版本将嵌入其搜索服务中。目前,百度已确认该项目名称为文心一言,英文名称为 ERNIE Bot。内部测试于 3 月结束,并向公众开放。此时,文心一言正在做上线前的冲刺。
去年 9 月,百度 CEO 李彦宏判断人工智能的发展“在技术层面和商业应用层面都出现了方向性转变”。据猜测百度那时候就开始做文心一言。按照谷歌和微软的节奏,文心一言可能提前开启内测。
百度拥有 Chat GPT 相关技术,在四层人工智能架构上(包括底层芯片、深度学习框架、大模型、顶级搜索应用)进行了全栈布局。文心一言位于模型层。百度深耕人工智能领域数十年,拥有产业级知识增强文心大模型 ERNIE,具有跨模态、跨语言的深度语义理解和生成能力。
业内人士分析,尤其是在自然语言处理领域,国内绝对没有一家公司能接近百度目前的水平。有专家提出 Chat GPT 是人工智能的一个里程碑,更是分水岭,意味着 AI 技术的发展已经到了一个临界点,企业需要尽快落地。

还未添加个人签名 2021-11-25 加入
深度学习GPU液冷服务器,大数据一体机,图数据库一体机









评论