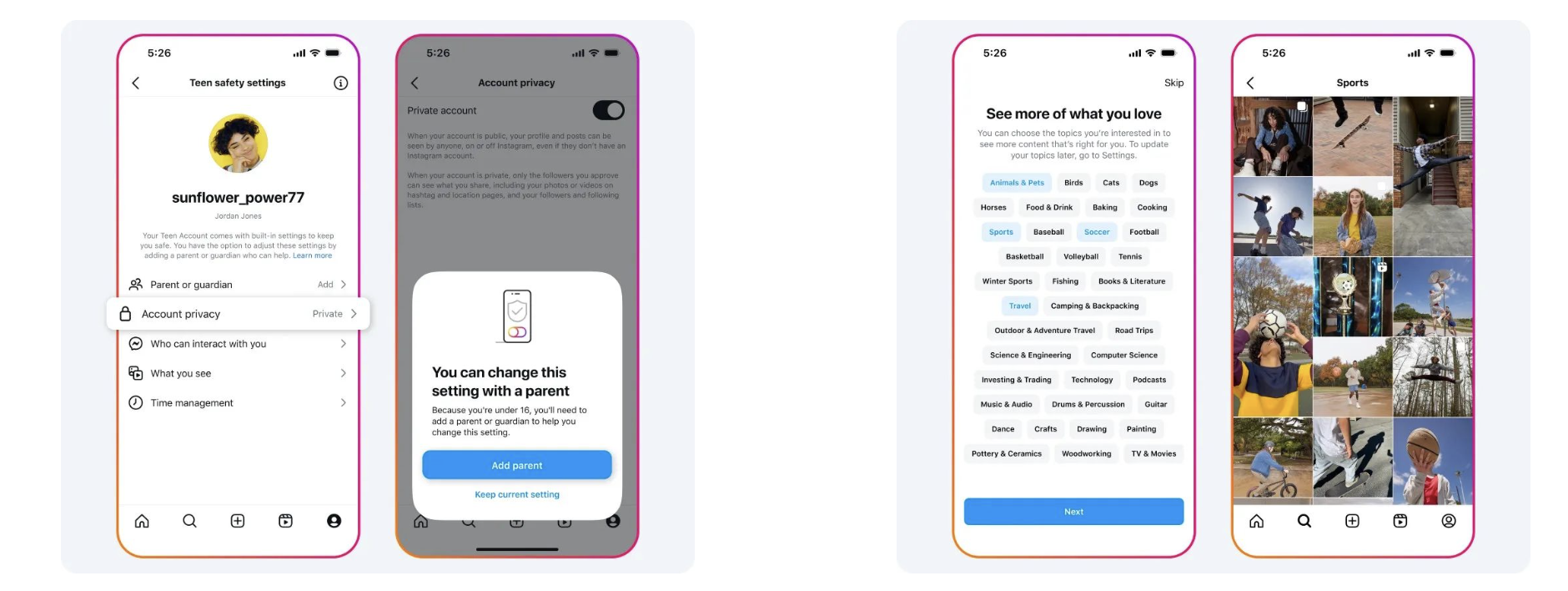
在持续多年的监管和诉讼压力下,作为社交网站的巨头,Instagram 落实了“最严格的青少年用户保护法”。
Instagram 上所有未满 18 岁的用户都将被归为“青少年用户”,默认把账号设置为私密状态,自动实施多项防护措施,很多体验功能也会受限。私密账号有效隔离了普通用户与青少年用户之间的直接联系,青少年用户也只能看到他们关注用户的“标签”(Tag) 和“提及”(Mention),甚至在上网 60 分钟后就会收到使用时长已满的提醒。此外,平台还引入了家长监督机制 (Parental Supervision),对于 16 岁以下的用户来说,家长可以查看孩子的关注列表、私信记录、浏览内容等行动,甚至有权批准或拒绝孩子调整防护措施的要求,从而实现对孩子网络活动的全面监管。
Instagram 的青少年用户保护机制,将首先推送给美国、英国、澳大利亚、加拿大市场,随后在欧盟地区上线,2025 年逐步在全球市场推广。
一、现状:社交媒体深陷内容合规性的困局
社交媒体上发布的内容需符合法律法规、社会公德和平台规则,这是维护网络健康生态的基石,但现实情况不容乐观。一方面,虚假信息、恶意攻击、色情暴力等内容屡禁不止,严重侵害了用户的合法权益,破坏了网络环境的和谐稳定。另一方面,平台在内容审核上往往面临技术难题、人力不足的双重挑战,难以做到全面、及时、准确地监管。美国十多个州的司法部曾联合起诉 Meta,指控其为了利益无视青少年用户的身心健康。于是,很多社交媒体平台采用了内容分级、账号限制等手段,例如 Instagram 发布的“青少年用户保护功能”,meta 也为未成年用户安装了“数字围栏”。
在实际的社交媒体使用过程中,未成年人总试图用各种途径绕开“青少年保护机制”,如使用家人的身份信息进行账号注册等。从传播过程中拦截违规、骚扰、不当信息固然重要,同样,从根源处用内容审核的方式掐断不宜传播的信息的苗头,更是普遍、高效的一种解决方案。
二、国内的内容审核工具测评
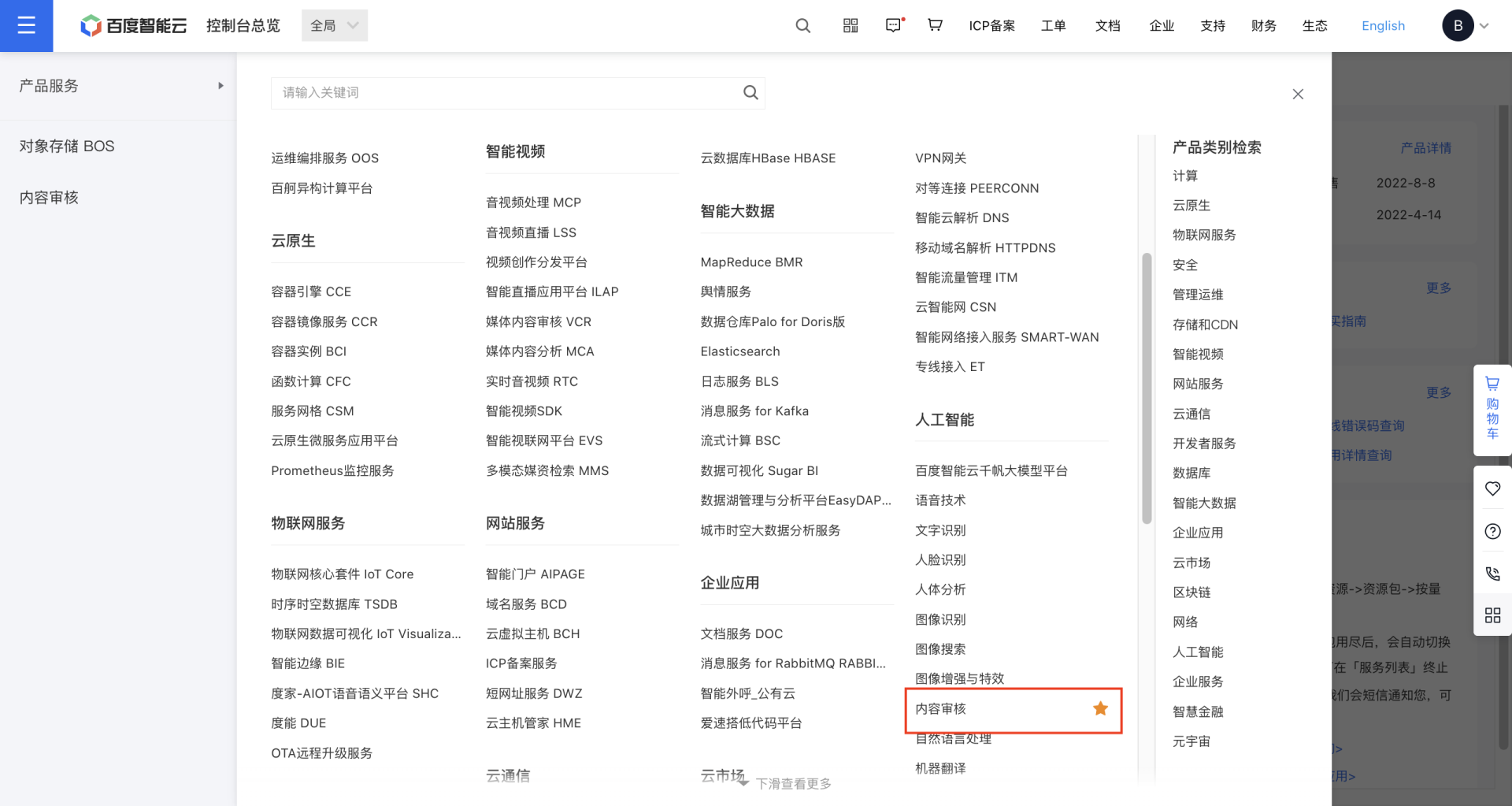
据官网介绍,百度内容审核平台是一款针对多媒体内容进行智能审核的服务平台。支持对图像、文本、音频、视频、直播等内容进行安全审核,具有精准的审核模型、丰富的审核维度、灵活的规则配置等特点。通过可视化界面选择审核维度、个性化调整松紧度,实现自动检测涉黄、辱骂、违禁、广告等内容,降低业务违规风险。
主要包括以下几种功能:
图像审核:采用前沿的图像识别、图像检索等算法结合海量的违规图像数据进行训练建模,具备超过 80 个细分审核维度,全方位过滤敏感图像内容,包括违禁、色情、广告、旗帜标志识别等通用审核能力,以及百度独具特色的审核能力:恶心图识别,图像清晰度识别,图像美观度,公众人物,直播场景,头像审核等。
文本审核:基于百度领先的 NLP 技术,结合海量的关键词库,准确识别各种敏感文本及其变体违规内容。提供严格/宽松场景选择:能够区分敏感内容正负向,涉黄及辱骂的轻重度,以精准适配不同业务场景。
音频审核:语音、语义、声纹多重审核保障。领先的 ASR(语音识别)引擎,将音频中的语音转写为文本,利用文本审核模型识别违规内容,并结合音频特征识别技术,准确识别低俗声音(呻吟、娇喘、ASMR)等违规内容。 支持短音频同步审核、音频文件异步审核、音频流审核等多种方案,高效协助企业审核语音聊天、电台,或录音、有声读物、直播等场景产生的音频数据。
视频审核:基于图像、文本、音频等基础审核能力,结合海量的违规视频数据库, 从图像、OCR 文本、音频等多种维度全方位过滤敏感视频内容。支持短视频同步审核、长视频异步审核、视频流审核等多种方案,高效协助企业审核短视频、长视频、直播等场景。
直播审核:对实时直播流进行同步审核,自动解析直播流链接,对视频流进行抽帧审核,对音频流按照 VAD 方式进行语音识别及审核,可实时检测直播过程中违规内容。
智能机审平台:可视化、灵活调配、实时监控。数据统计和分析板块化,展示业务风险趋势,支持多维度数据导出,便于业务分析;零代码、可视化界面操作,无需自建平台,快速接入使用,帮助企业减少开发维护成本;可根据业务场景,灵活选择审核维度、细分标签、以及对应的审核松紧度。
人机审核平台:面向拥有人工审核团队的服务商或企业内部审核团队的审核员操作平台。审核员可在平台上高效地审核图像、文本、短视频、篇章等各类媒体内容,同时借助人机协同审核流程和易用的操作页面,进一步提升审核效率,降低企业运营成本。
三、内容审核 SaaS 平台的实操步骤
“百度智能云·一念”的内容审核平台,拥有行业内唯一具备的大模型审核能力,覆盖涉黄、违禁、广告、恶心不适等丰富的审核维度,支持自定义黑白库和个性化审核策略配置,可以为业务健康发展保驾护航。
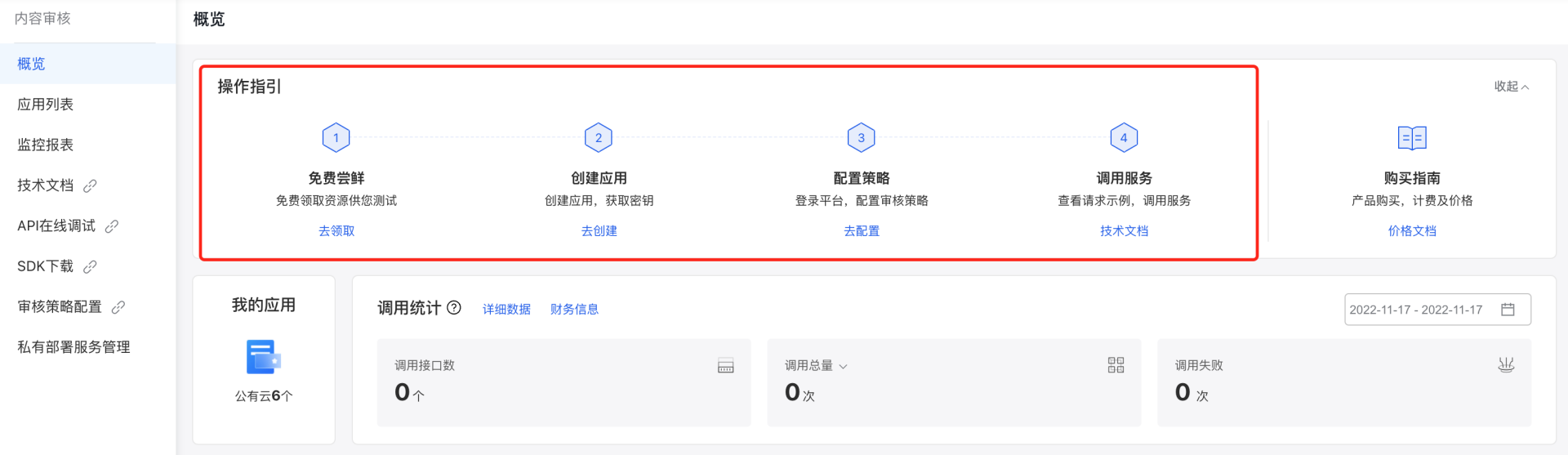
Step1:账号登录及资源领取调用
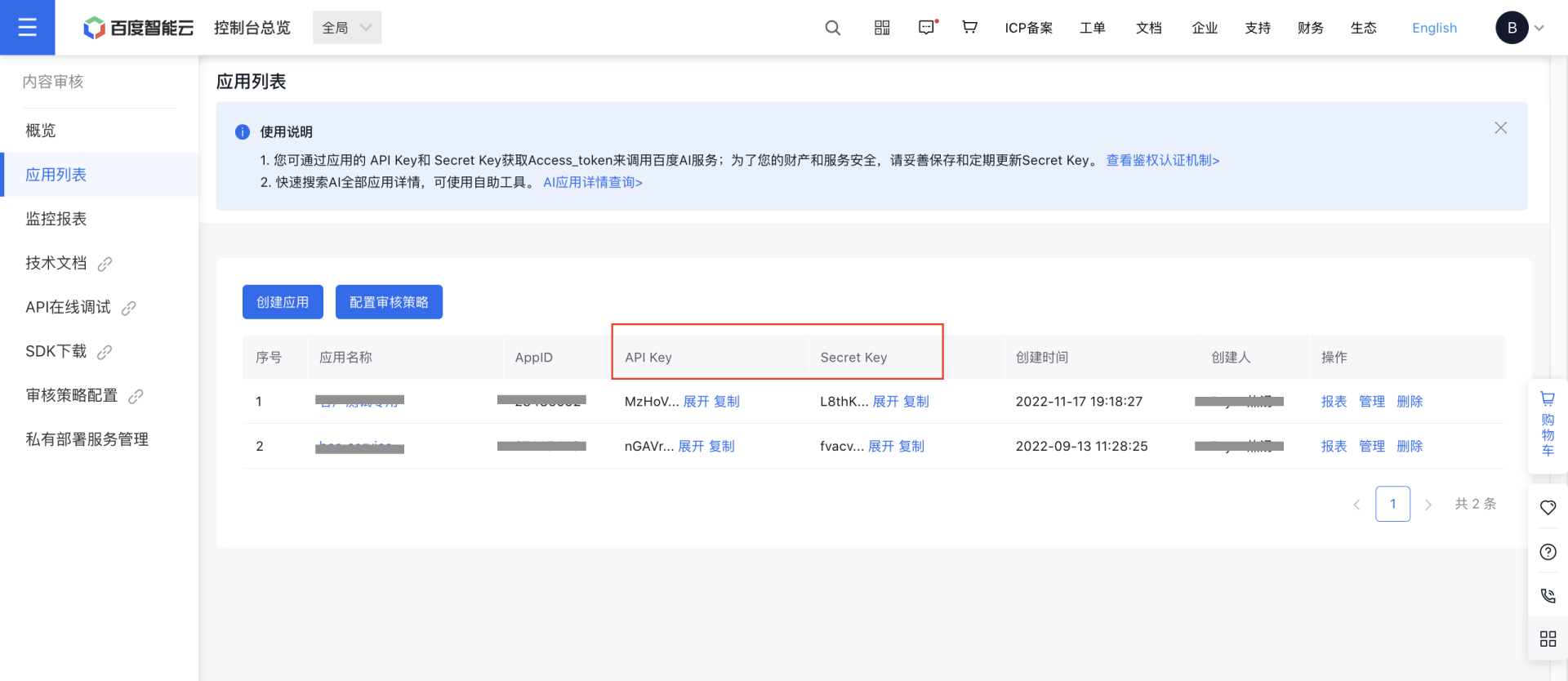
百度智能云的内容审核能力,首先需注册账号https://cloud.baidu.com/solution/censoring。
然后根据操作指引,分别领取免费资源、创建应用、配置策略和调用服务。
Step2:在线验证
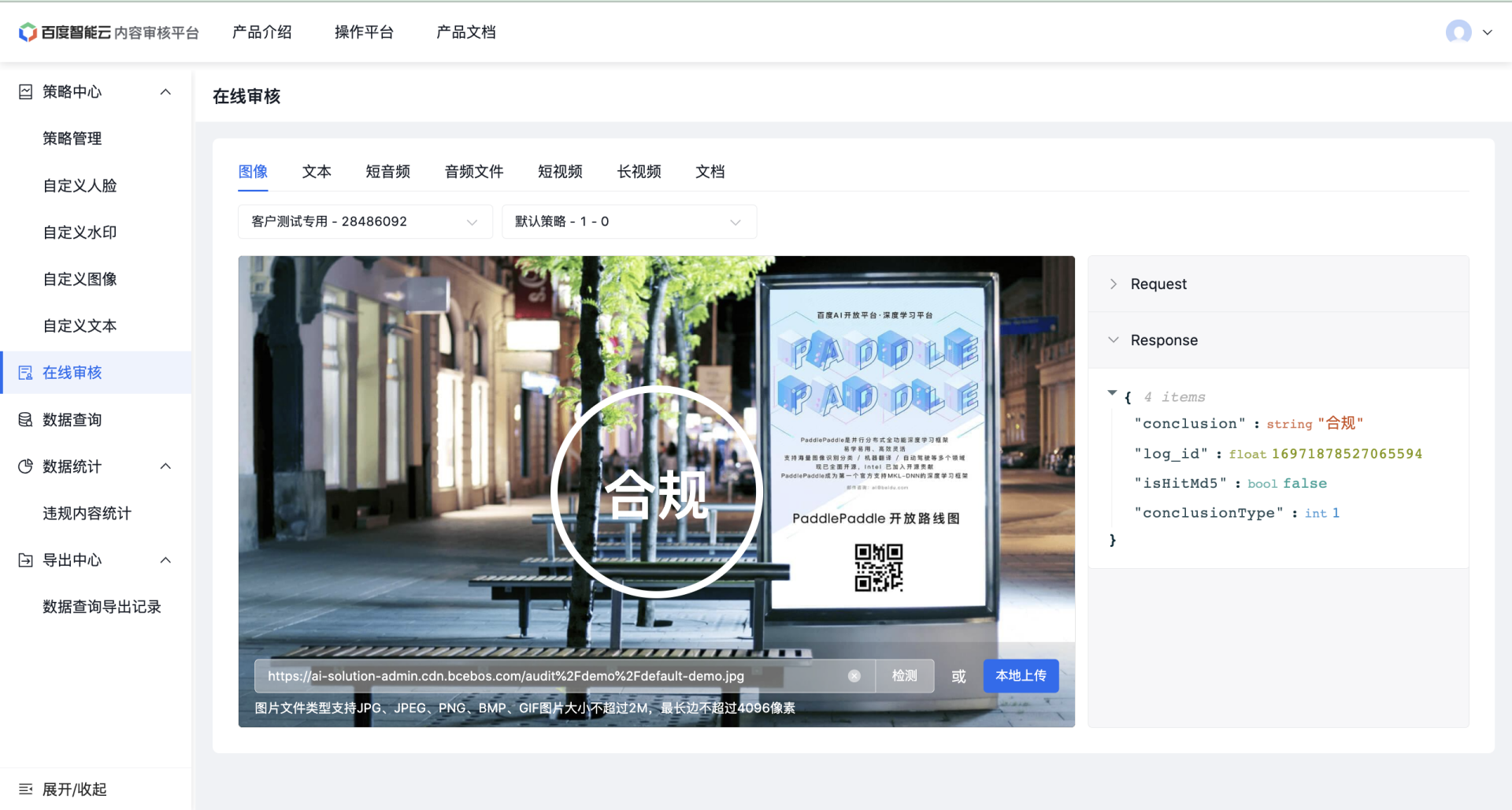
创建应用与配置策略完成后,即可进行在线验证。
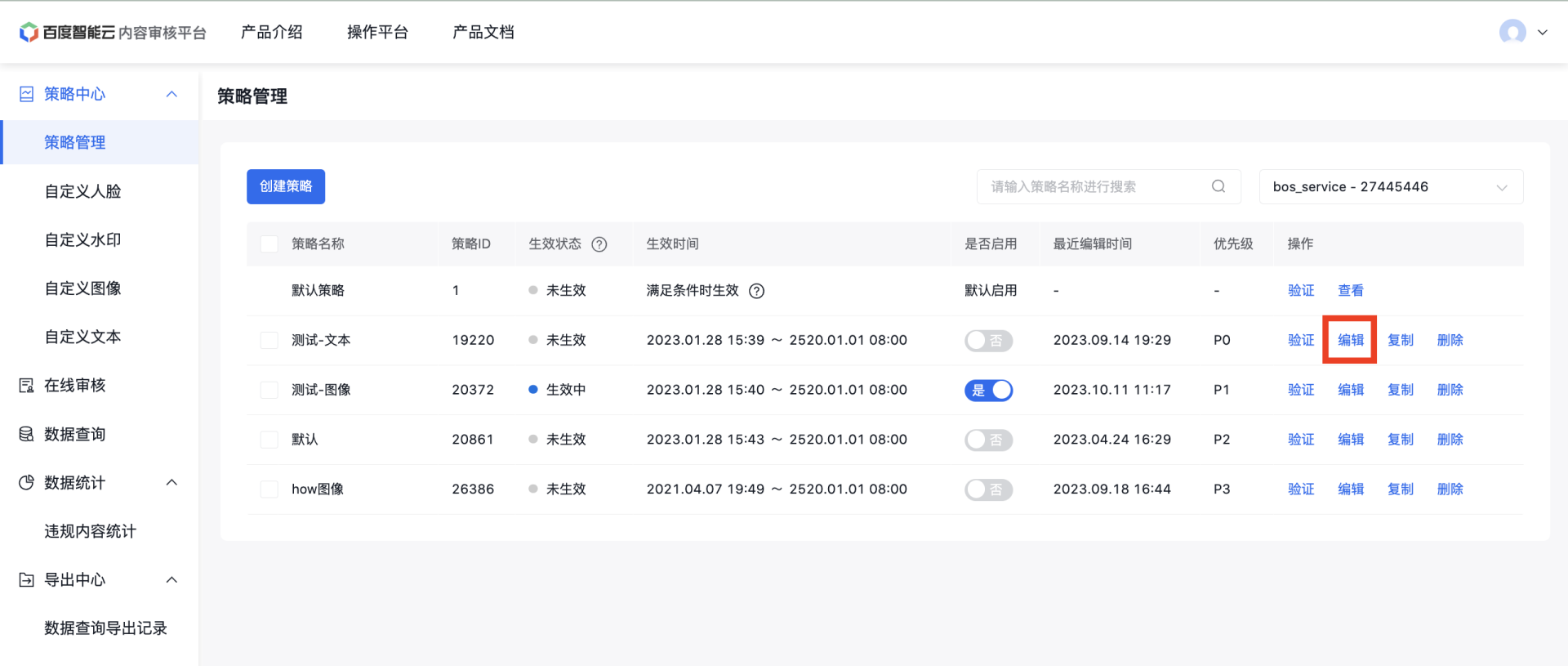
策略管理页面:
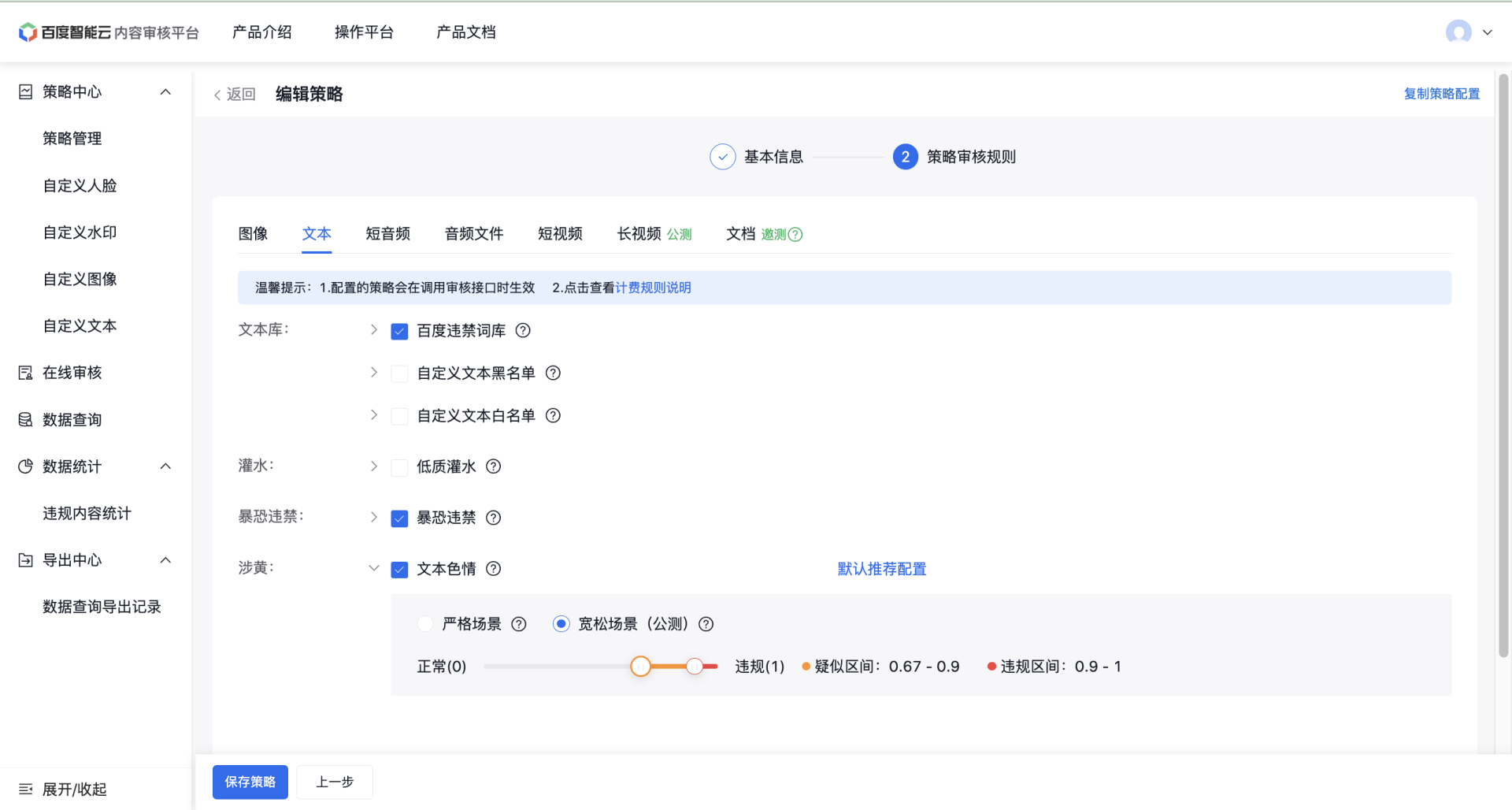
策略配置页面:
在线审核/验证页面:
Step3: 编写示例程序
根据第一步创建应用时生成的 API KEY 以及 Secret KEY,就可以写一个能调用百度 AI 内容审核能力的示例代码。
准备开发环境
用 python 来快速搭建一个原型
Windows 快速测试包
Windows 平台的用户如果对 python 安装感到困难,可以下载一键测试包,下载地址:Windows 测试包。
解压 zip 文件后,双击 run.bat 即可测试。
编写代码
新建一个 main.py
粘贴以下内容,不要忘记替换 API_KEY 以及 SECRET_KEY:
# coding=utf-8
import sysimport jsonimport base64
# 保证兼容python2以及python3IS_PY3 = sys.version_info.major == 3if IS_PY3: from urllib.request import urlopen from urllib.request import Request from urllib.error import URLError from urllib.parse import urlencode from urllib.parse import quote_pluselse: import urllib2 from urllib import quote_plus from urllib2 import urlopen from urllib2 import Request from urllib2 import URLError from urllib import urlencode
# 防止https证书校验不正确import sslssl._create_default_https_context = ssl._create_unverified_context
API_KEY = 'eQnGqPdFTTctqkjHvdUEzmrC'
SECRET_KEY = 'HDBuwWT4pfSBGyLkTEAYhwoQkoDGrWU2'
IMAGE_CENSOR = "https://aip.baidubce.com/rest/2.0/solution/v1/img_censor/v2/user_defined"
TEXT_CENSOR = "https://aip.baidubce.com/rest/2.0/solution/v1/text_censor/v2/user_defined";
""" TOKEN start """TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
""" 获取token"""def fetch_token(): params = {'grant_type': 'client_credentials', 'client_id': API_KEY, 'client_secret': SECRET_KEY} post_data = urlencode(params) if (IS_PY3): post_data = post_data.encode('utf-8') req = Request(TOKEN_URL, post_data) try: f = urlopen(req, timeout=5) result_str = f.read() except URLError as err: print(err) if (IS_PY3): result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()): if not 'brain_all_scope' in result['scope'].split(' '): print ('please ensure has check the ability') exit() return result['access_token'] else: print ('please overwrite the correct API_KEY and SECRET_KEY') exit()
""" 读取文件"""def read_file(image_path): f = None try: f = open(image_path, 'rb') return f.read() except: print('read image file fail') return None finally: if f: f.close()
""" 调用远程服务"""def request(url, data): req = Request(url, data.encode('utf-8')) has_error = False try: f = urlopen(req) result_str = f.read() if (IS_PY3): result_str = result_str.decode() return result_str except URLError as err: print(err)
if __name__ == '__main__':
# 获取access token token = fetch_token()
# 拼接图像审核url image_url = IMAGE_CENSOR + "?access_token=" + token
# 拼接文本审核url text_url = TEXT_CENSOR + "?access_token=" + token
file_content = read_file('./image_normal.jpg') result = request(image_url, urlencode({'image': base64.b64encode(file_content)})) print("----- 正常图调用结果 -----") print(result)
file_content = read_file('./image_advertise.jpeg') result = request(image_url, urlencode({'image': base64.b64encode(file_content)})) print("----- 广告图调用结果 -----") print(result)
text = "我们要热爱祖国热爱党" result = request(text_url, urlencode({'text': text})) print("----- 正常文本调用结果 -----") print(result)
text = "我要爆粗口啦:百度AI真他妈好用" result = request(text_url, urlencode({'text': text})) print("----- 粗俗文本调用结果 -----") print(result)
复制代码
运行代码
在命令行中运行python main.py
结果
若代码正确运行,命令行界面上会显示出运行结果:
----- 正常图调用结果 -----{"conclusion":"合规","log_id":15589290206915234,"conclusionType":1}----- 广告图调用结果 -----{"conclusion":"不合规","log_id":15589290221307686,"data":[{"msg":"存在水印码内容","probability":0.86516607,"type":5}],"conclusionType":2}----- 正常文本调用结果 -----{"conclusion":"合规","log_id":15589290234750607,"conclusionType":1}----- 粗俗文本调用结果 -----{"conclusion":"疑似","log_id":15589290237990632,"data":[{"msg":"疑似存在文本色情不合规","conclusion":"疑似","hits":[{"probability":0.802,"datasetName":"百度默认文本反作弊库","words":[]}],"subType":2,"conclusionType":3,"type":12}],"conclusionType":3}
复制代码
结果中返回了内容审核服务对于图片以及文本的审核结果,包括了概率以及不合规的类型。















评论