
Java 进阶:HashMap 底层原理(通俗易懂篇)
1.底层结构
Java 7 及之前版本
在 Java 7 及之前的版本中,HashMap 的底层数据结构主要是数组加链表。具体实现如下:
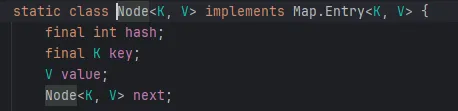
1、数组:HashMap 的核心是一个 Entry 数组(Entry<K,V>[] table),这个数组的大小总是 2 的幂。每个数组元素是一个单一的 Entry 节点,或者是一个链表的头节点。

2、链表:当两个或更多的键经过哈希运算后映射到数组的同一个索引上时,就会形成链表。Entry 节点包含了键值对以及指向下一个 Entry 的引用,以此来解决哈希冲突。
Java 8 及之后版本
从 Java 8 开始,HashMap 的底层结构除了数组加链表之外,还引入了红黑树,以优化在链表过长时的查找性能。结构变为数组加链表加红黑树:
1、数组:同样是一个 Entry 数组(Java 8 中称为 Node),大小仍然是 2 的幂,用于快速定位。
2、链表:在哈希冲突时,键值对仍会以链表形式链接在一起。但与 Java 7 不同的是,Java 8 对链表的处理增加了转换为红黑树的条件。
3、红黑树:当一个桶中的链表长度超过 8 且 HashMap 的容量大于 64 时(不大于 64 会先对数组进行扩容resize()),链表会被转换成红黑树。这种转换提高了在大量哈希冲突情况下的查找效率,因为红黑树的查找时间复杂度为 O(log n),相较于链表的 O(n)有显著提升。
2.数据插入
在 JDK1.7 的时候,采用的是头插法
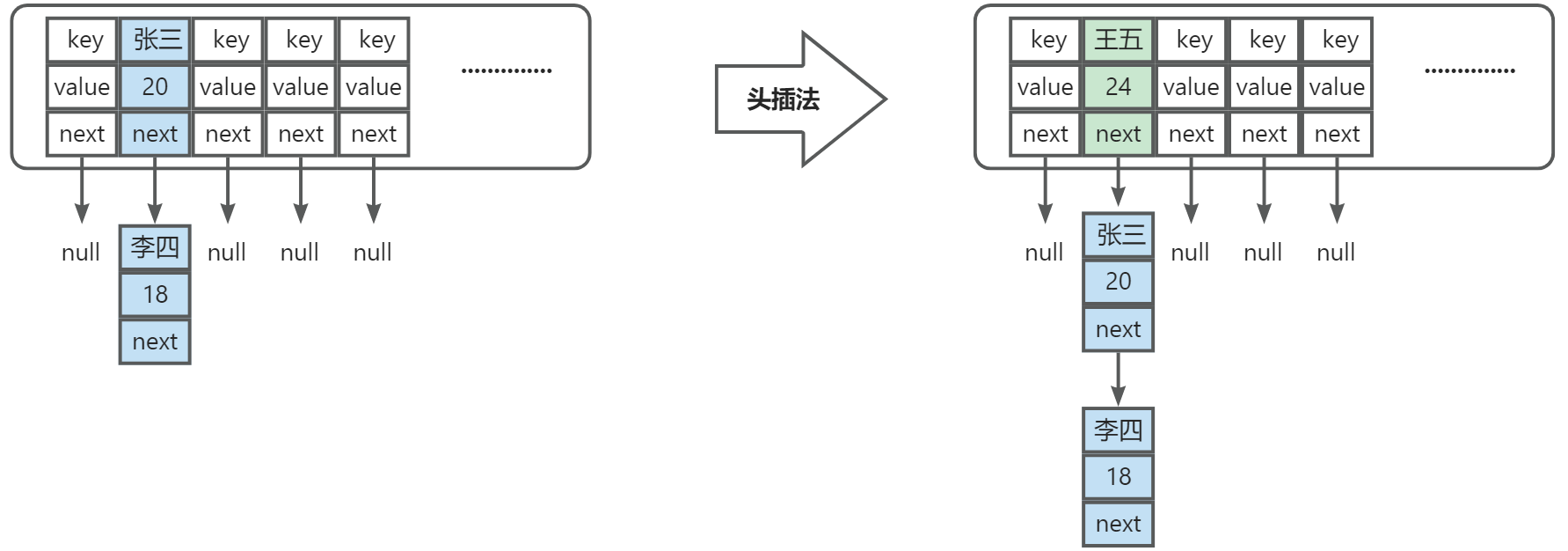
在 JDK1.8 改成了尾插法,这是因为头插法在多线程环境下扩容时可能会产生循环链表问题
线程不安全
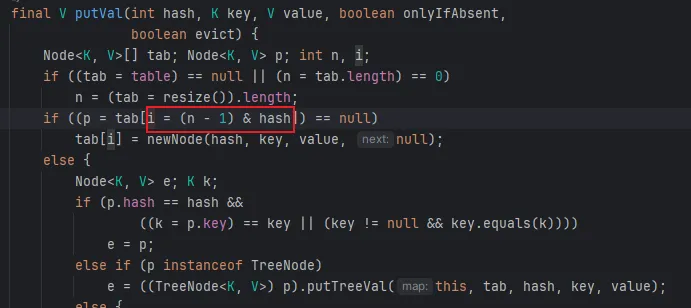
无论是 JDK1.7 还是 1.8 都是线程不安全的,下图是 1.8 中的 put 方法
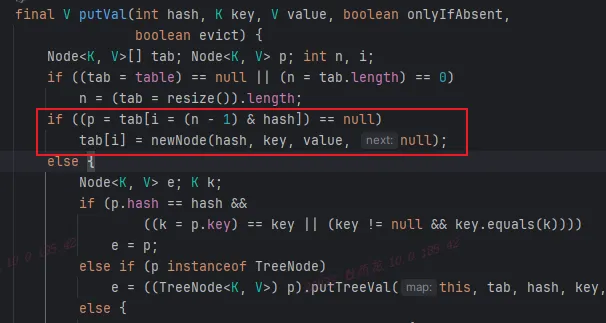
tab 是就是 HashMap 的数组 table,第一个 if 判断时做了赋值。框起来的部分表示如果没有 hash 冲突就直接在数组上插入元素,但是如果两个线程 hash 一样且都进入到了这个 if 下,线程 1 先执行的插入数据,线程 2 会覆盖 1 插入的数据。
那么什么是循环链表问题呢?这就不得不介绍一下 HashMap 的扩容机制了。
3.扩容机制
首先讲几个 HashMap 的属性
table:数组,存放链表或红黑树的头节点
Node:节点,属性有 hash、key、value、next(下一个节点)
size:元素个数,即节点 node 个数,非数组长度
Capacity:当前数组长度
loadFactor:加载因子,默认为 0.75f,简称 loadFactor
threshold:扩容门槛,值为 capacity*loadFactor,size 达到这个门槛就扩容
当 size 大于 threshold 时,就会进行扩容resize()。
扩容分为两步
1、创建一个新的数组,长度为原数组的两倍
2、遍历所有 Node 节点,重新计算 index 值(Java8 首先会重新计算 hash 值),放到新数组里,存在 hash 冲突的就放到链表或红黑树
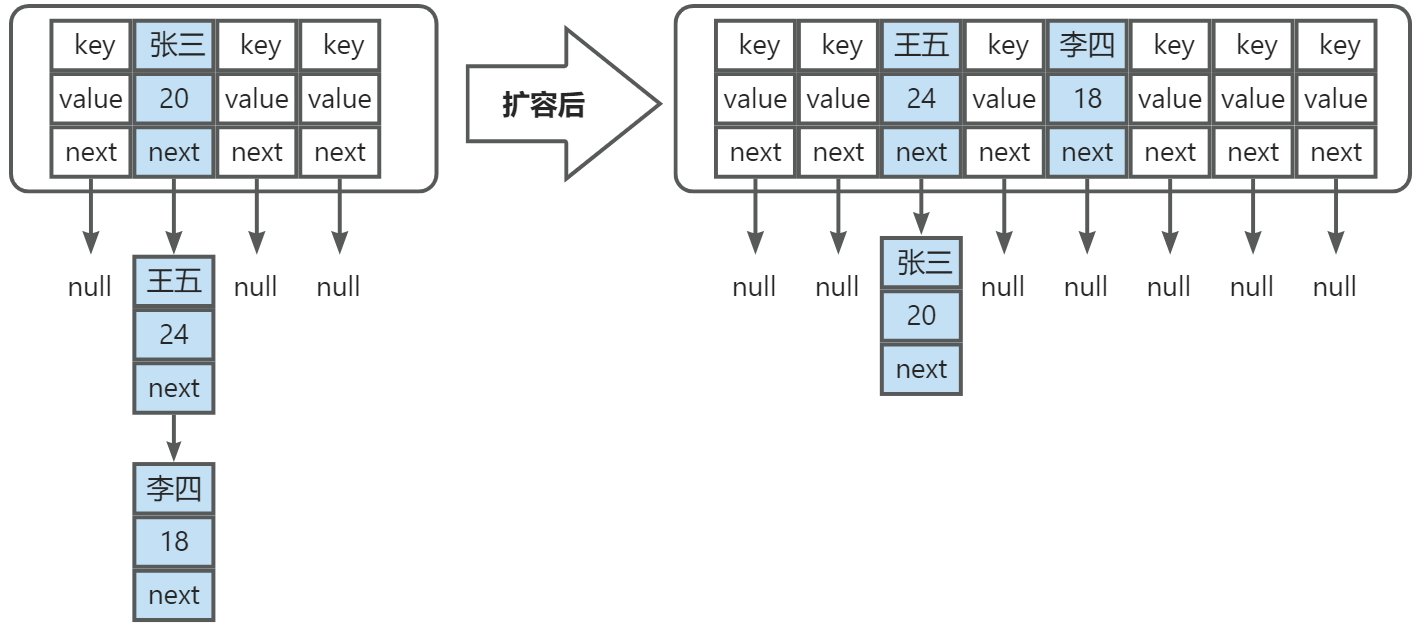
为什么要重新计算 index 值,直接把张三这条链表复制到新的数组中不行吗?
答案是不行的,因为 index 规则是根据数组长度来的,如图
所以 index 的计算公式是这样的:
index = HashCode(key) & (Length - 1)
4.循环链表问题
循环链表问题理解起来比较麻烦,如果理解不了就知道 JDK1.7HashMap 扩容的时候有这么回事就行。但是可能是我自己太笨了万一大家一看就懂了呢
我们来看一下 Java1.7 扩容的源码
重点在于 transfer 方法,作用是重新计算 index 值然后将旧数组中的数据迁移到新数组
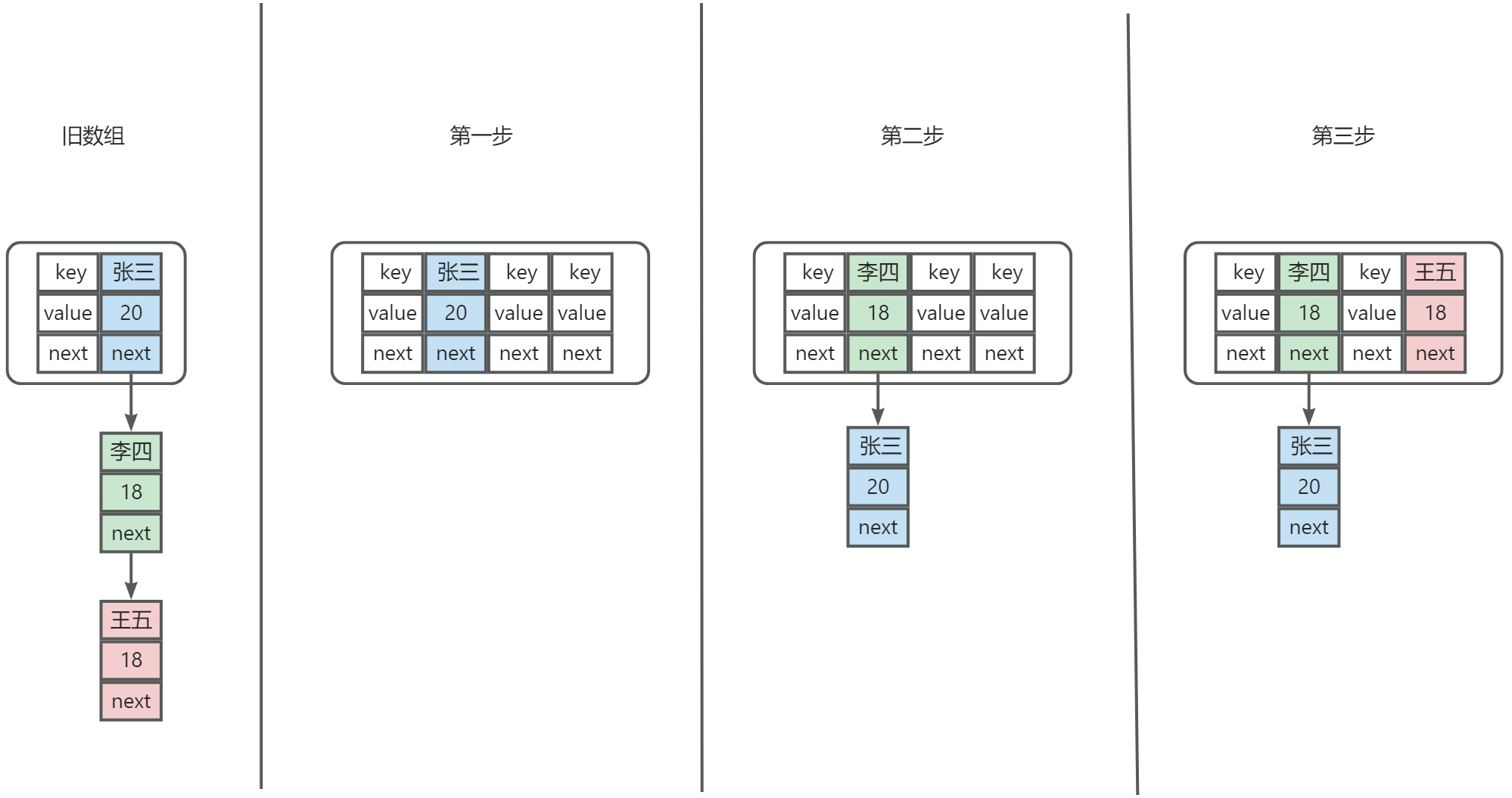
循环链表的产生:
原因:
假设我们有两个 Thread 都在执行 resize 方法,Thread1 第一步刚执行完第 23 行Entry<K,V> next = e.next;就卡住了,这时 Thread2 执行完了 resize 方法。
过程:
1、Thread1 第一次执行完 Entry<K,V> next = e.next 后,e=张三,next=李四,也就是说第二步执行李四的插入
2、Thread2 执行完 resize 后,李四的 next 变成了张三
3、此时又回到 Thread1,第二次执行 Entry<K,V> next = e.next 后,e=李四,next=张三,也就是说又要执行张三的插入,循环链表产生!
由此我们知道了循环链表产生的关键在于头部插入元素 A 时,元素 A 的 next 元素 B 的 next 是元素 A 本身,所以 Java8 采用了尾插法,避免了循环链表。
文章转载自:救苦救难韩天尊

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论