
G1 原理—如何优化 G1 中的 MGC
1.大对象导致频繁 Mixed GC 的案例
(1)案例背景
电商平台一般都有几种模式:淘宝这种属于长距离电商,买的东西可能来自于全国各地。京东属于中距离电商,有京东物流,通过最近的仓库发货 ,速度会快点。在此基础上还有近距离电商,如天猫超市、京东到家、京东小时购等。在这种近距离电商上面购买商品后,马上会有物流系统去接单进行配送。
有一个小时购电商系统:这个小时购电商系统的特点就是,需要使用大量的缓存。包括接入到平台的店铺信息及其商品信息、平台自营商品、店铺信息等。在商品中心里,商品更新、新商品上架这些操作会发送 MQ。接着分批获取数据进行消费,更新 Redis 缓存,部分数据同步到本地缓存。
另外一个缓存更新的业务点是:有很多商品是批量上架的,尤其是自营商品,会直接批量上架一批商品。那么在商品更新后,会发送一条通知消息给这个缓存系统消费。缓存系统拿到通知消息后,去生成一个 Job 任务。然后执行这个 Job,读取商品系统里面的一些数据,缓存到系统中。
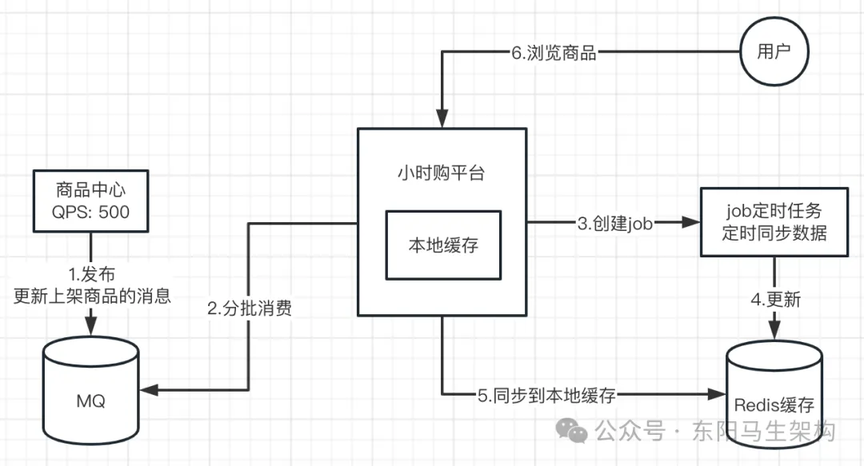
(2)问题现场
整个过程,在平常系统正常运行时,是没什么问题的。因为商品本身上架的频率就不高,商品的一些数据更新也并不是很频繁。因此在日常运行中这个系统运行起来没有任何问题。从业务逻辑上来说,只要没特殊情况,这个业务逻辑也是没任何问题,因为只是一个缓存更新的逻辑而已。
然而在双十一前夕商户运营反馈:有少量商品的缓存信息不显示,或者显示很慢,实时性比较差。虽然这个问题听起来不是很严重,但是毕竟在大促节点是个问题。
于是开始去排查这个问题,具体的表现是:商品中心的 QPS 并不大,单台机器在高峰期只有 500,总 QPS 不过 5 千。Redis 集群也在一个比较健康的范围内,带宽、CPU、内存都比较合理。
那为什么还是会出现商品系统查询商品信息时加载慢的情况呢?查看商品系统的日志发现:在出现加载慢时,日志中有一条"写入数据到缓存中"的 log 日志。在这个日志打印后大概四五秒才继续往后打印日志。
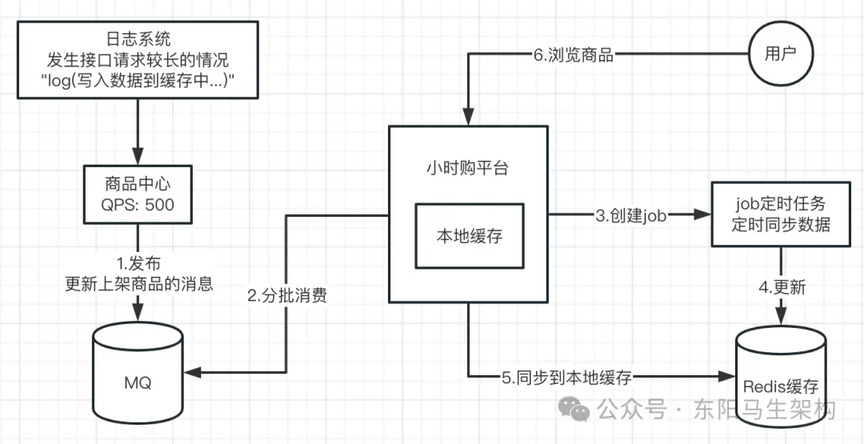
那么这个日志代表的意思是什么呢?因为在缓存没有命中时,是需要从数据库中查询数据加载到缓存中去的。然后加载完成后,会把查询到的数据返回给前端。如果缓存设置卡住的时间比较长,就会造成请求的整体响应时间比较长。
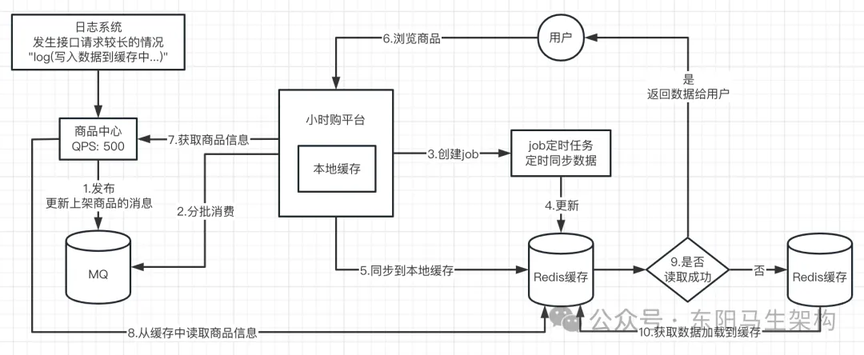
在 QPS 不高的情况下出现查询超时,并且是经过数据库查询后,设置数据到缓存导致超时。而 Redis 本身又没什么问题,于是只能继续针对 Redis 本身来查问题。
(3)Redis 缓存有什么问题
这里要补充一个细节:就是更新商品的缓存,是按照店铺来加锁的,因为这样做不至于在 Redis 中产生大量的分布式锁。其实按店铺的粒度已经够了,每个店铺更新商品的频率一般也不会很高。因为是小时购平台,所以更新商品要加锁,不能让用户购买更新前的商品。
在查 Redis 问题时,因为已经知道缓存更新时是按照店铺维度来加的锁,那么就直接查看一下这个锁相关的内容。结合 Redis 分布式锁的日志发现,获取锁失败进入等待的时间比较长。导致没有把缓存设置到 Redis 中,以至于这个请求的接口等待时间比较长。
知道这个问题后,开始尝试排查解决。首先要找到的就是为什么会超时?谁在持有这把锁,导致更新的时候出现的这么长时间的等待?要查这个问题,其实相对容易一点儿,直接通过 Redis 的客户端,来查看相关 Redis 分布式锁的 lock key 即可。Redis 分布式锁的加锁本质就是先去获取一个 key,然后在这个 key 对应的 value 里保存一些加锁的信息。
很快查到了匹配这个商铺相关的分布式锁,发现加锁的机器是小时购平台的缓存同步系统的其中一台机器。
到了这一步,很显然已经知道大概原因了。那就是因为这个缓存同步服务里的一些更新操作,获取到了锁,去更新这个商铺的商品缓存,然而更新的时间比较长,导致商品系统查询数据库 -> 更新缓存这个操作被阻塞了,最终导致接口请求时间非常长。
接下来就要找到这个原因,为什么同步缓存会这么久?
(4)缓存同步服务有什么问题
缓存同步服务持有锁这么长时间,导致其他的机器获取锁等待时间过久这个问题是什么原因?
排查 GC 日志后,发现当请求时间非常长的情况时,存在大量 MGC,并且 MGC 持续时间长、频率非常高,基本上 10 分钟就要进行一轮 MGC。每一轮 MGC,基本上都要跑满 8 次,这就导致了超时的问题出现。
(5)线上环境的参数设置及调优
这就是当时线上环境的核心参数,目前已知因为 Mixed GC 过于频繁,导致了一些更新缓存的操作比较慢。
一.缓存系统定时对比补偿操作产生大量大对象
这里还有一个细节:就是 Job 任务不仅要批量更新缓存,还要进行缓存不一致的对比补偿操作。
在平常的系统运行,之所以没有出现问题。是因为 Job 定时更新缓存的频率不高,补偿 job 的频率和数据量也不高。总体没有造成影响。
而双十一期间,虽然看起来商品数据量没有变化太大。但是因为补偿任务和定时同步缓存的同时存在,导致有数倍于真实需要更新的商品数据的数据量(200w)要获取到系统中。并且补偿操作还是个定时执行的操作,把大量数据同步到缓存服务中。这就出现了大量的补偿操作带来大量的数据,导致内存资源被大量占用。
检查了 JVM 的 GC 日志,分析 dump 文件发现有大量的大对象,并且是缓存补偿操作下的 Job 持有的集合占用了大量的内存。继续观察 GC 日志发现,大对象分区占用的内存比例上升非常快。并且每次执行 MGC 时,都伴随着 humongous allocation failer 这种日志。
所以问题的原因就是产生了大量大对象,大量大对象进入了大对象分区。大对象分区占用的内存也会算在老年代占用里,从而导致频繁触发 MGC。
二.大对象产生的原因是 RegionSize 在优化时被调小
之前的工程师对这个缓存服务系统的性能进行过优化。他想的是如果能让 GC 的时间更快,就能提升整体的性能。所以他认为太大的 Region,可能会导致分析追踪对象时间过长。并且如果 Region 比较大,那么每个 Region 里存活对象的数量可能会太多,这就会导致选择性价比高的 Region 比较耗时。所以基于这些考虑,就把 RegionSize 由原来的 16M 调到了 4M。
但实际上,这些过程造成的性能问题基本上是可以忽略的。这种操作属于因小失大,改成 4M 在平常数据量小的时候没什么问题。但如果数据量大时,即使分批次对比补偿,也是按几百的数据量去获取。
一般系统都会限制每批次取最多 200 条数据。每一条商品的数据信息对象,大概能达到十多 K。十多 K 乘以 200,刚刚好差不多是达到 4M 的一半。这就成功让获取到的数据信息对象成为大对象,而大量对象会直接进入大对象分区。
因为补偿的操作,也需要花费一定的时间。数据量大的时候,源源不断的拉取数据。处理对比数据的速率却跟不上,导致大量对象存活在大对象分区。最终导致频繁发生 MGC,阻塞了正常的缓存同步操作,最终造成商品系统的缓存写入操作拿不到锁而阻塞。
三.如何解决缓存定时对比补偿操作中产生的大量大对象
第一步:就是把 Region 调大回 16M,因为这是经过大量的压测调试最终确定的。当然也有一个比较取巧的方法:参考优秀开源系统的一些参数设置。但要尽量匹配系统,比如 RocketMQ 的 Broker 参数设置 Region 是 16M。那么结合 RocketMQ 特点和系统是否匹配,考虑是否能借鉴其参数设置。
第二步:修改代码,调低 Job 补偿的频率,同时把 Job 每次处理的数据量调小一点,比如每次处理的数据量由 200 改为 100。
第三步:修改新生代初始比例,调整为 25,默认是 5,即初始占用 5%的堆内存。上述这个系统出问题时有大量数据要处理,处理不过来造成数据积压。如果不调整新生代大小,系统启动前期还是会出现频繁 MGC 的情况,因为会有大量存活对象经过 YGC 后进入到老年代区域。所以调大新生代的初始比例,可让系统在启动初期就能有比较高的吞吐。
2.Mixed GC 到底是在优化什么(从避免到提速)
(1)优化 Mixed GC 之避免策略
优化思路主要是避免过多发生 GC,通过修改代码、调整参数来实现间接调整 YGC 和 MGC 的持续时间、发生频率。
例如:通过调整 RegionSize + TLAB Size,避免大对象分配 + 堆分配。通过调整 RegionSize + 新生代大小 + 代码处理速度,减少 MGC 频率。这两个场景都是通过避免的思路来进行优化的。
关于避免思路的优化核心是:
避免什么 + 如何避免
第一:要避免慢速分配
在分配对象时要避免慢速分配,与慢速分配有关的因素。RegionSize 大小、TLAB 大小、refill_waste 大小、工作线程数量等。
第二:要避免慢回收
就是要尽可能避免 Miexd GC,因为速度比较慢,与慢回收有关的因素。RegionSize 大小、新生代比例、老年代占比阈值、停顿时间。
这两个避免,也是我们日常工作中需要关注的重点调优点,大多数的调优思路其实都是来源于此。
(2)优化 Mixed GC 之提速策略
除了避免策略,还可以对 Mixed GC 的过程进行提速,来达到优化效果。也就是从分配、标记、回收、回收过程中的各种操作来提升处理速度。
关于提速思路的优化核心是:
提什么速 + 怎么提速
第一:提升分配速度
这个和避免慢速分配有异曲同工之妙,主要就是和 TLAB 相关的参数。在调大 TLAB、调整 refill_waste 后,基本可以避免对象分配进入慢速分配。但是在此基础上,还要关注 JVM 之外的一些重要内容,比如工作线程的数量。
如果服务器是 16 核这种高性能机器,可以开几百个线程其实问题不大。如果服务器是 4 核这种普通服务器,就不能开几百个线程处理请求了。这样即使 TLAB 相关的参数调整得再好,分配的效率也还是会很低。所以提速主要就是根据服务器来确定工作线程的数量。
第二:提升回收的速度
比如在 YGC 阶段:参与回收的线程数量、DCQ 相关白绿黄红四个区域设定、DCQ 的长度设置、PLAB 的大小设置都是一些提升回收速度的手段。
在服务器可承受的情况下,提升参与的线程数,肯定能提升回收效率。白绿黄红区域的阈值设置合理也能在一定的程度上减少 GC 过程中的处理压力,从而减少 GC 总时间。
PLAB 缓冲区(对象复制时的缓存)如果足够充裕,也能够保证更快的回收。当然也可能会造成比较多的内存碎片,这个点依然是需要做很多权衡。
在 Mixed GC 阶段:SATB 队列的长度 GCDrainStackTargetSize、并发标记阶段处理时一次标记的最多对象个数、GC 一次最多选择多少个分区进行回收、剩余多少垃圾时停止 MixedGC 回收等参数都可提速。
3.Mixed GC 相关参数详解之堆内存分配参数
Mixed GC 参数介绍——堆内存分配相关内容:
(1)-XX:InitiatingHeapOccupancyPercent 的默认值为 45
当老年代内存占用总空间达到 45%后,才会启动并发标记的任务。大对象分区也认为是属于老年代。这个值的大小调整需要经过反复的测试观察,才能调整到最优的比例。
一.如果这个值过小可能会频繁 MGC,比如 30%
那么在一次 MGC 后,老年代的占比可能又快速达到 30%,从而频繁 MGC。
二.如果这个值过大可能会频繁 YGC,比如 70%
虽然能避免频繁发生 MGC,但又导致年轻代(如只占 30%)又会频繁 YGC。频繁 YGC 可能又会导致新生代的对象频繁触发晋升,从而进入老年代。大量的垃圾对象可能会占满老年代,如果发生晋升失败就会导致 FGC。注:在出现晋升失败时也会导致 FGC。
三.如果这个值设置得比较小,怎么保证尽量少发生 FGC
假如这个值设置得比较小 20%,那么老年代使用比例很快就会到达这个值,MGC 触发的频率就会相对高很多。
只要系统是正常的,没有大量存活对象在老年代、造成空间不够用的问题,那么垃圾对象在晋升失败造成的 FGC 就基本可以避免了。
20%意味着新生代的比例会比较高,晋升到老年代的对象可能就不会太多。因为新生代内存足够,大多数请求都能在正常处理完时避免碰上 YGC。
这个参数不太好设置,所以如果要去调节这个参数,可以综合来考虑。目的就是保证 YGC、混合 GC 都比较快,同时 Full GC 比较少。
这里可以分享一个经验:如果要设置这个值,可以根据系统运行过程中的"平均使用内存"来设置。把这个值设置的和"平均使用内存"保持一致,这样整体的效率会高一些。
想要观察内存使用情况的话,可以打开打印 Region 详情的实验参数。
参数一:G1PrintHeapRegions
参数二:G1PrintRegionLivenessInfo
-XX:InitiatingHeapOccupancyPercent 这个值设置好能极大提升性能,但如果想要设置得合理,就需要不断地尝试。
(2)-XX:G1ReservePercent 默认为 10
这个参数的含义是:在 JVM 初始化时,保留一部分分区不使用。这保留的部分分区,在新生代晋升老年代时,给晋升的对象来使用。
默认是将 10%的空间留给新生代对象来处理晋升,如果因为新生代对象晋升失败导致的 FGC 比较多,那么可以适当调大这个值。
这个值的大小,也是和 YGC、MGC 息息相关的。如果这个值过大,则程序正常运行过程中实际可使用的空间就比较少,那么新生代、老年代可以用的空间就会比较少。如果这个值过大,还可能会在晋升过程中,造成晋升失败。
因为这个值过大,那么 YGC 就会比较少,从而导致晋升就会比较频繁。晋升频繁就可能导致预留空间快速填满,当预留区域不够就会导致 FGC。
因此这个值一般不做改动,除非发现因为晋升失败导致的 FGC 比较频繁。比如系统一共发生了 4 次 FGC,其中三次产生的原因是发生了晋升失败,那么此时就可以调大到 15%。
(3)-XX:G1HeapWastePercent 默认为 5%
这个参数的含义是:如果开启了并发标记,标记结束后,根据 CSet 统计出垃圾对象的占比。如果垃圾对象占用整个堆内存的比例达到 5%,就会开启多批次的 MGC。如果比例达不到 5%就不再进行 MGC,等下一次 YGC 再次进行并发标记。
这个值可以决定 MGC 是否需要执行,也就是可以控制 MGC 的频率。如果 MGC 频率较高,同时每次回收的垃圾数量不多,就可以提高该值。
4.Mixed GC 其他相关的参数详解及优化
(1)ParallelGCThreads
这个参数是指定并行 GC 线程的数量,一般最好和 CPU 核心数量相当。如果不设置的话,会自动推断,计算公式是:
注意:这个值的意思是,并行执行 GC 操作时会有多少个线程参与。这个并行执行阶段,可以理解为处于 STW 过程中的阶段。这个阶段系统程序会完全停止,多个线程会并行处理标记、清理等任务。
(2)ConcGCThreads 默认值为 0
这个参数的含义是 GC 并发过程中的线程数量。如果没有设置的话,这个值会自动调整。调整的依据是:(ParallelGCThreads + 2) / 4。最小值为 1,也就是至少为 1 个 GC 线程。
假如服务器是 4 核的,那计算出来得到的值就是:(4 + 2) / 4 = 1,也就是一个线程在工作,那么就是只有一个线程在并发过程中起作用。
如果发现并发过程速度比较慢,可以考虑增大该值。对于这个值,也要慎重调节。因为这个值如果调的过大,会导致系统程序的吞吐量下降。
并发线程数是指:这个并发执行阶段,系统是可以执行的,也就是 GC 过程中的非 STW 阶段。如果这个线程的数量过多,在程序和并发线程共同工作时:系统可以使用的 CPU 资源或者线程资源就越少,就会导致系统吞吐量下降。
(3)HeapSizePerGCThread 默认值为 64
这个参数的含义是,在 GC 过程中,每个线程处理的空间大小。可以简单的理解为:每 64M 的空间就分配一个线程去处理。
关于这个参数主要是要看服务器的计算能力,这个计算能力就不单单要考虑多少核了,而是处理器本身的能力是否强大。I3、I5、I7 处理器假如都是 4 核,那肯定是 I7 处理器的计算性能更好。
不过因为使用的服务器多数是不需要考虑核心的计算性能的,所以一般这个参数的值就保持默认值即可,不需要做特别的调整。
(4)UseDynamicNumberOfGCThreads
这个参数的含义是,默认不能动态调整线程数量,默认为 false。如果开启,则会按照最大线程数、HeapSizePerGCThread 来动态调整。正常来说关闭即可,因为开启这个参数带来的收益非常有限。
普通的 4 核、16 核机器还是目前服务器的主流,即使开启了这个参数其实也没有多大意义。反而有可能因为动态调整的判定逻辑,导致 JVM 需要额外消耗一部分性能去动态调整这个值。
(5)G1SATBBufferSize
表示每个 SATB 队列最多存放 1000 个灰色对象,这个参数正常来说也不需要修改,因为对整体性能没什么影响,默认值为 1K。
(6)G1OldCSetRegionThresholdPercent
这个参数表示,每轮 MGC 回收的 Region 最大比例,默认值是 Java 堆的 10%。如果执行了 MGC 回收,总共 8 轮,那么每轮不能回收超过堆内存 10%的 Region 数量。假如停顿时间设置得比较短,每次的值可能会远远低于这个 10%。这个参数一般也不需要做调整,保持默认即可。
(7)GCDrainStackTargetSize
这个参数表示并发标记阶段,一次最多能标记多少个对象,默认值为 64。出于性能考虑,这个值不宜过大,也不宜过小。和 HeapSizePerGCThread 参数类似,也要基于处理器的运算能力。运算能力强可以适当提高这个参数的值,从而在一定程度提升并发标记的效率。
(8)ForceDynamicNumberOfGCThreads
这个参数是强制开启动态调整线程数,默认值为 false。
(9)MarkStackSize 和 MarkStackSizeMax
这个参数表示:在并发标记阶段中用到的标记栈的大小。默认情况下,在 32 位 JVM 中为 32K 和 4M,64 位 JVM 中为 4M 和 512M。
当然,如果没有设置,G1 是会按照自动推断的方式计算设置这些参数,这个参数的调优结果在测试中没有显示出很好的效果。前后同样的环境,对系统影响不大。
在某种特殊场景下,可以调整此参数来尝试提升效率:当发现并发标记时间久,且并发标记的根对象数量和对象字段数量很大,此时就可以尝试调整此参数去提高并发标记的速度,避免标记栈过小。
注意:标记栈是有可能会溢出的。在溢出时,JVM 会尝试停止标记操作。然后尝试扩展这个标记栈,这个过程是会降低标记效率的。
如果使用的是 CMS 垃圾回收器,也会有类似的参数:-XX:CMSMarkStackSize=8M,-XX:CMSMarkStackSizeMax=32M。这两个参数主要的意义就是,并发标记阶段,标记栈到达给多大。
对于 G1 来说:可认为在标记存活对象过程中,会把对象的一个个字段加入到一个栈中。这个栈就是由 MarkStackSize 这个参数所设置的,一般情况也不需要去设置,保持默认值即可。
这些冷门参数,一般情况下是不调整的。大多数情况下,只需要调整那些主流的参数其实满足大多数系统需求了。
(10)G1MixedGCLiveThreshoudPercent
这个参数是用于判断回收时选择 Region 加入 CSet 的阈值,默认值是 85。如果符合条件的 Region 中的存活对象的比例小于 85%,那么就可以加入 CSet。其实就是判定 Region 是否有比较高的回收价值。
这个参数其实一般情况下也不需要调整,即使要去调整,也要有大量的测试数据来支撑。
如果这个参数调整得太大,比如 95。那么只要存活对象比例小于 95%的 Region 都会加入到 CSet 中去。可能会出现本来 MGC 进行 3 批次就可以完成回收,现在要 8 次才完成回收。带来的收益是:在回收时可能会有更多的对象被回收掉。带来的负面是:严重降低回收效率,因为 95%的存活比例是非常高的。回收一个 Region 的时间 / 回收垃圾数量的比例会降低,整体效率比较低。
如果这个参数调整得太小,如小于 50%的 Region 才会进入到 CSet 中回收,那么可能会导致一次 MGC 可以回收的垃圾对象数量就比较少。同时因大量 50%以上使用率的 Region 并没有被回收,导致很多内存碎片。比较多内存碎片,导致内存利用效率比较低,可能会导致比较频繁的 GC。
因此对于这个参数的调整还是需要综合考虑具体情况来具体分析,一般情况下,保持默认值不变即可。
(11)G1ConcMarkStepDurationMillis
这个参数的默认值为 10,表示每次并发标记阶段执行的时间要在 10ms 内完成,并发标记其实是一个限时操作。所以 MGC 时,有可能会出现再次重新标记,有可能会出现多次并发标记。
这个值的大小可以影响到并发标记的频率。对于 G1 的混合回收,并发标记并不属于一次完整的混合回收。有可能出现多次并发标记才能完成所有的标记任务的。
那么这个参数的大小其实就可以决定并发标记的频率。如果时间调整的比较小,那么就意味着并发标记的频率会高一些。如果时间调整的比较大,那么并发标记的频率就会低一些。
如何调优?什么时候调整这个参数?如果要调优这个参数,需要知道并发标记的频率会带来什么影响。如果并发标记频率比较低,并发标记单次的时间比较长,会造成什么影响?系统是会不断运行的,新对象会不断产生,重新标记的时间也会比较长。
假如把并发标记的时间设为 10s,那么是不是 10s 内就有可能触发 FGC?因为垃圾对象太多,而 MGC 又卡在这个并发标记、重新标记这两步里。
所以默认值 10ms 一般是足够用了。如果 FGC 比较频繁时,除了空间分配合理,还有一个可能就是:并发标记不够及时,MGC 不够及时,并发标记占用过多时间,回收不及时。
所以如果发现了频繁的 FGC,通过各种比例的调整效果不好时:可以尝试减小这个并发标记时间,提高并发标记频率。从而减少重新标记时间,尽早完成混合回收。
(12)G1UseConcMarkReferenceProcessing
这个参数的意思是可以在并发标记时处理软引用相关的对象,默认值为 true,这个参数一般也是不需要动的。如果系统使用的软引用比较多,如反射用的非常多,可考虑关闭该参数。
文章转载自:东阳马生架构

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论