
打造次世代分析型数据库(八):高效数据导入导出方案


作者介绍
ceciliasu(苏翠翠),腾讯云数据库工程师,加入腾讯以来持续从事分布式数据库内核研发工作,曾负责 TDSQL PG 版、CDW PG 快速扩容能力设计和研发。目前主要参与 CDW PG 数据库内核研发相关工作,负责外部数据快速导入工具的设计和研发。
原生数据导入导出方式以及存在的问题
使用原生 COPY 导入数据相当耗时,这是因为在 CN 上执行 COPY 导入数据是一个串行执行的过程,所有数据都需要经过 CN 处理分发给不同 DN 入库,所以 CN 是瓶颈,它只适合小数据量的导入。
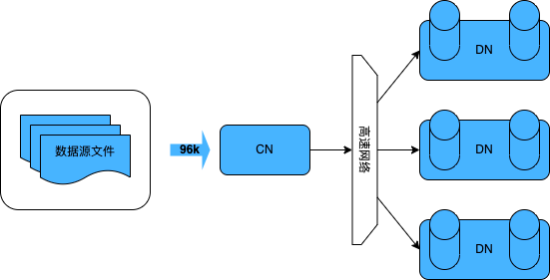
图表 1 COPY 数据流向示意图
TDX 提出了一种基于外表实现多 DN 并行导入数据的方式,将数据的处理和写入直接下推到 DN 执行,使 DN 直连数据源,充分利用分布式数据库的多节点优势,最大化数据库的计算能力。
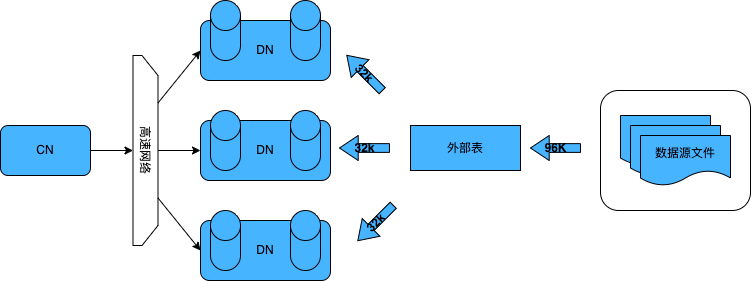
图表 2 TDX 数据流向示意图
从零开始 - TDX 使用实践
并行文件分发组件 TDX 服务部署
支持 CDW PG 并行导入导出的第一步便是在数据服务器上部署 CDW PG 并行文件分发组件-TDX 服务。数据服务器是指数据源文件所在的机器,数据服务器上是否分布有数据库结点无要求。
联系 CDW PG 团队人员获取 TDX 服务 rpm 包;
CDW PG_tdx-1.0-i.x86_64.rpm
基础依赖安装:
软件包安装:
配置并启动 TDX 服务
将 TDX 二进制目录添加到 $PATH:修改~/.bashrc,添加 PATH 路径:
并使其生效:
建立 TDX 数据目录并启动 TDX 服务
当启动 TDX 服务时,需要指定服务监听的端口和工作目录 $tdx_prefix(该目录内的数据都可以被访问)。
可以通过-l 参数来指定 TDX 服务的日志输出。
如果不需要 TDX 的输出,则可以这样启动 TDX 服务:
部署多个 TDX 服务
部署多个 TDX 服务可以提高数据导入效率,可以在不同机器上运行多个 TDX,也可以在一台机器上运行多个 TDX,充分利用机器 IO 和网络带宽。
TDX 数量不能超过 DN 数量,一个 DN 只连接一个 TDX 服务。
外部表创建
在数据库正常启动并创建 exttable_fdw 插件之后,我们便可以创建外部表(External Table)了。
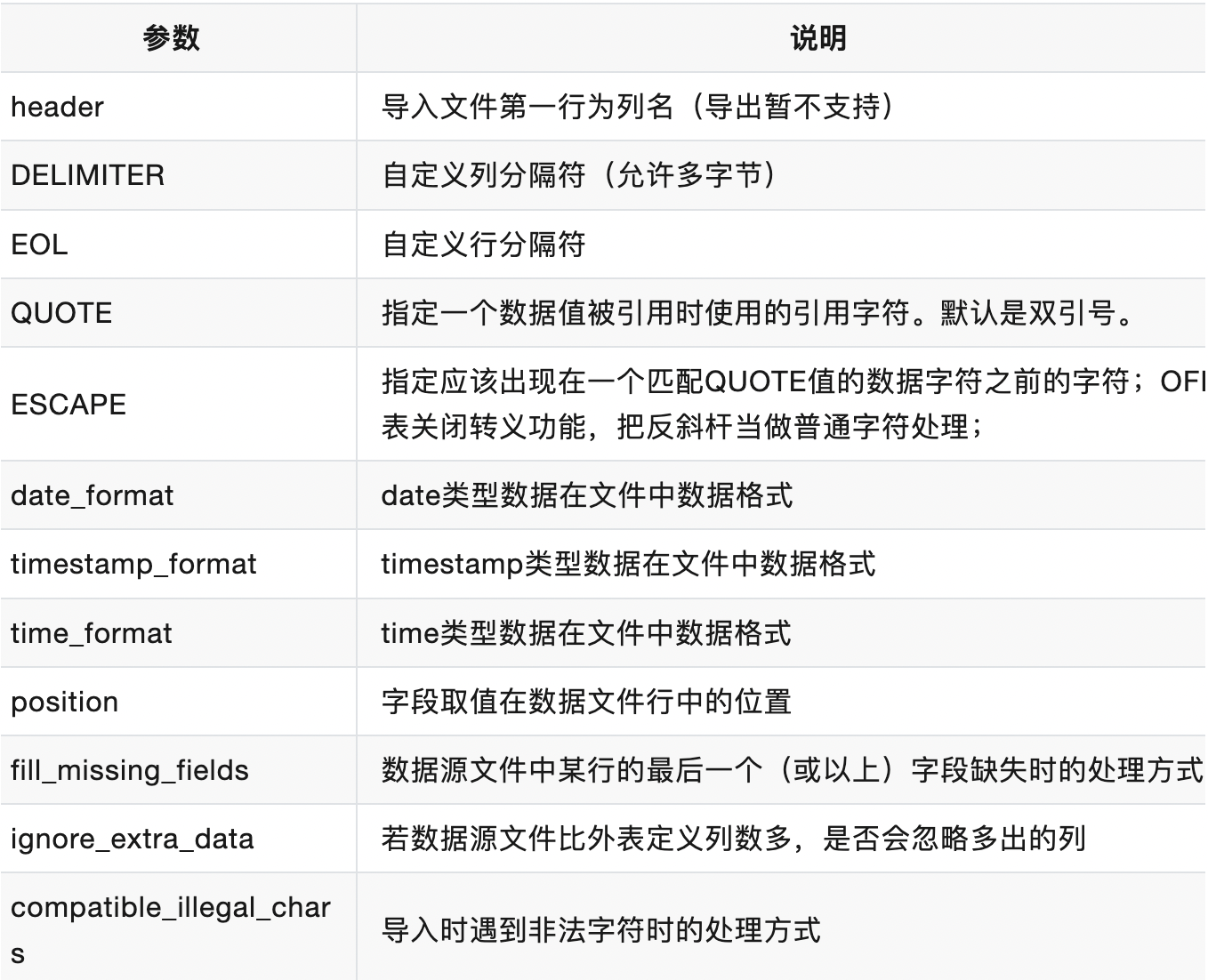
参数说明
WRITABLE/READABLE(缺省) -
外表分为可读外表和可写外表;创建外表时指定 WRITABLE,则外表为可写外表;未指定时默认为可读外表。可读外表支持数据并行导入,可写外表支持数据并行导出。
LOCATION -
指定外部数据的 URL,包括外部数据读写协议(tdx/tdxs)。
FORMAT -
指定外部数据格式(csv 或 text),CDW PG 会根据这些指定的格式,实现外部数据和数据库内部元组的转换。
[ [LOG ERRORS] SEGMENT REJECT LIMIT count [ROWS | PERCENT] ] -
LOG ERRORS 是否记录有关具有格式错误的信息;
SEGMENT REJECT LIMIT count [ROWS | PERCENT] 拒绝限制计数可以指定为行数(默认值)或总行数百分比(1-100),如果错误行的数量达到 limit,整个外部表操作会被中止并且不会有行被处理。
其他参数说明如下
外表的创建示例如下:
数据的导入导出
数据的导入导出通过类似的句式来实现。
数据导入
数据导入 SQL 的执行计划如上所示。
从查询计划可以看出 DN 的工作包括:
扫描可读外表,从 TDX 获取部分数据块,将它转化为元组;
根据需要导入的本地表的分布键,对元组进行重分布,发往对应 DN;
对应 DN 将元组插入到本地表中。
数据导出
数据导出需要创建可写(writable)外部表:
数据导出需要执行如下 SQL:
从执行计划可以看出对本地表的扫描与外部表的写入(将数据发送给 TDX 执行写入文件操作)都被下推到了 DN 执行。
收尾工作
外部表的删除
TDX 的停止
在文件服务器找到 TDX 进程直接 kill 即可。

还未添加个人签名 2020-06-19 加入
欢迎关注,邀您一起探索数据的无限潜能!









评论