
PostgreSQL 技术内幕 (十一) 位图扫描
扫描算子在上层计算和底层存储之间,向下扫描底层存储的数据,向上作为计算的输入源,在 SQL 的执行层中,起着关键的作用。顺序、索引、位图等不同类型的扫描算子适配不同的数据分布场景。然而,扫描算子背后的实现原理是怎样的?如何评估不同扫描方法的代价和选择呢?
在往期的 PG 内幕直播讲解中,我们曾为大家介绍过 PostgreSQL 中的索引扫描。本次的直播,我们和大家分享了 PostgreSQL 中位图扫描的实现方式,讲解了位图扫描的源码实现,并从代价估算的角度对比了不同扫描方式。以下内容根据直播文字整理。
扫描方法分类及代价估算
在 PostgreSQL 的查询优化过程中,优化器会根据不同等价算子,构建许多符合条件的查询路径,并从中选择出代价最小的路径,转化为一个计划,传递给执行器执行。而评价路径优劣的依据是基于算子和系统统计信息估计出的不同路径的代价(Cost)。
常见的扫描方式有以下三种:
顺序扫描
当对无索引的字段进行查询,或者判断到查询将返回大量数据时,查询优化器将会使用顺序扫描方法,把表中所有数据块从前到后全部读一遍,然后找到符合条件的数据块。顺序扫描适合数据选择率高、命中大量数据的场景。
索引扫描
索引扫描先利用字段的索引数据,定位到数据的位置,然后再去数据表中读取数据。它适合选择率低、命中相对少数据的场景。
位图扫描
尽管索引数据一般比较少,但是它需要随机 IO 操作,相比顺序扫描所采用的顺序 IO 而言成本要更高,所以索引扫描的代价并不总是低。那如何在二者之间做平衡呢?对于选择率不高不低,命中率适中的场景,通常会使用到位图扫描。
位图扫描原理是将索引扫描中的随机 IO,尽量转换成顺序 IO,降低执行计划的代价。它首先访问索引数据,过滤出符合提交的数据的索引信息(CTID),然后根据 CTID 来进行聚合和排序,将要访问数据页面有序化,同时数据访问的随机 IO 也转换成顺序 IO。
接下来我们从代价估算的角度来看一下不同扫描方法的差异:
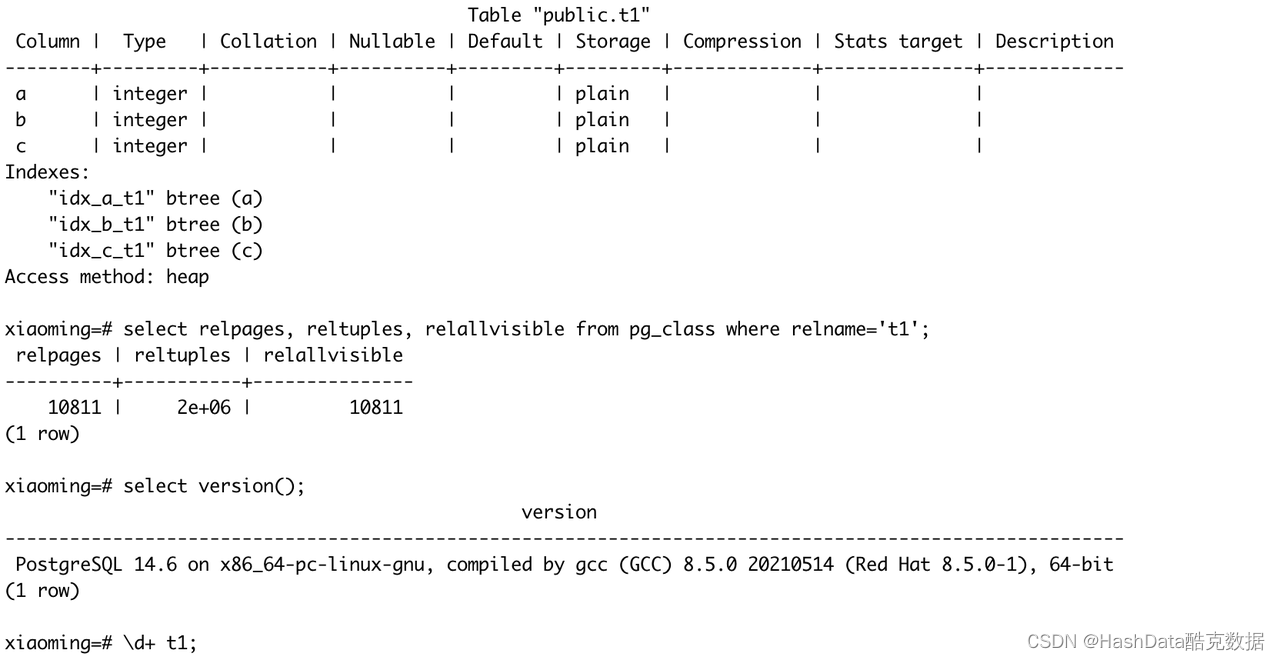
图 1:代价估算示例表
如图 1 所示,示例表中包含 a、 b 、c 三个字段;
索引信息:a、 b 、c 三个字段分别有一个 btree 索引;
统计信息:表内包含 200w 行数据,10811 个数据页,全部可见。
代价估算示例
最简单的扫描 (select * from t1;)
这是一个最简单的顺序扫描的示例,它的处理逻辑是:从表的 segment 文件中,按照顺序读取 page 页面到内存中,然后在内存中经过简单的 CPU 处理(MVCC 判断),返回适合的 heap tuple 数据。
从过程分析来看,执行代价可以归为两部分:IO_cost 和 CPU_cost。对于这个示例,它的 IO pattern 是顺序扫描,IO_cost = 顺序扫描一个页面的代价(seq_page_cost) * 顺序扫描多少页面(relpages);它对于 tuple 的处理,只是简单地判断 MVCC,所以它的 CPU_cost=处理一个 tuple 的代价(cpu_tuple_cost) * 多少个 tuple(reltuples)。
我们使用下列 SQL 来计算这个计划的 IO_cost 和 CPU_cost:
total_cost = io_cost + cpu_cost = 30811, 刚好等于 explain 语句输出的 cost(cost=0.00..30811.00 rows=2000000 width=12)。
不同扫描算子的代价对比
接下来我们通过同一个 SQL select * from t1 where a <= 10000; 的不同执行计划的代价,来理解扫描算子的过程。
顺序扫描
从 Plan 的输出可以看到,顺序扫描比我们代价估算示例中的 Plan,多了一个 Filter 的阶段,整个 Plan 的 cost 增加到了 35811。因为是顺序扫描,读取的数据是不变的,IO_cost 是固定等于 10811,所以增加的是 CPU_cost。
从计算顺序扫描代价的函数代码中看,每一个 tuple 的代价 cpu_per_tuple = cpu_tuple_cost + qpqual_cost.per_tuple, 其中 qpqual_cost.per_tuple 和表达式的复杂度有关。在之前的示例中,因为没有表达式,所以 qpqual_cost.per_tuple = 0。在当前这个代表式 where a <= 10000 下,我们可以反推出 qpqual_cost.per_tuple= 0.0025。
索引扫描
索引扫描分为两个阶段:扫描索引数据, 根据索引数据扫描 heap 表数据,所以它的 cost 也可以分为两个阶段计算:
扫描索引数据的 cost
对于 Btree 索引来说,cost 等于获取所需 btree page 的代价,btree pages 的数量估算=relpages * 选择率。并且这些页面在磁盘上并不是按顺序存储的,因此索引数据的扫描模式是随机的。成本估算还包括处理每个 index tuple 的成本 cpu_index_tuple_cost,以及每行的过滤成本 cpu_operator_cost。
所以扫描索引数据的 index_cost = relpages * selectivity rate * random_page_cost + reltuples * selectivity rate * (cpu_index_tuple_cost + cpu_operator_cost)。其中:
relpages 是索引表的页面数
reltuples 是索引表的 tuple 数
selectivity rate = 20557 / reltuples
下面的 SQL 是计算索引数据的 cost 逻辑:
扫描数据的 cost
对于 heap data 来说,我们能想到对于 heap data 的扫描,最坏的情况是每次 ctid 对应的 heap tuple 都是随机访问:io_cost_max = reltuples * selectivity rate * random_page_cost; 最好的情况 ctid 指向的 heap tuple 在磁盘上是有序的: io_cost_min = relpages * selectivity rate * seq_page_cost。
扫描 heap data 的 io cost 在[io_cost_min, io_cost_max]区间内,优化器是如何估算的呢?下面是 cost_index 函数里的代码:
其中核心是 indexCorrelation 这个字段,它的取值范围是 [-1,1]。当 indexCorrelation 的值接近 1 时,表示索引的顺序与表数据的顺序高度相关,即索引的排序与表数据的排序非常相似。当 indexCorrelation 的值接近 -1 时,表示索引的顺序与表数据的顺序高度负相关,即索引的排序与表数据的排序完全相反。当 indexCorrelation 的值接近 0 时,表示索引的顺序与表数据的顺序没有明显的相关性。
对于索引扫描,cache 也会影响索引代价估算。思考一种情况,如果 cache 足够大,所有的页面只需要访问一次,因为后续所有对于这个页面的访问,都是访问数据库缓存。
位图扫描
从 Plan 来看,Bitmap Scan 也分为两个阶段:Bitmap Index Scan 和 Bitmap Heap Scan。
通过对比三种扫描算子的 Plan 输出可以发现,当前 SQL,使用位图扫描的代价是最低的:
Bitmap scan cost(11559.98) < index scan cost(32243.95) < seq scan cost(35811)
位图扫描源码解析
位图扫描分为 Bitmap Index Scan 和 Bitmap Heap Scan 两个阶段。
Bitmap Index Scan:扫描 btree index 的数据,构建并返回 TID Bitmap;
Bitmap Heap Scan:依赖下层算子返回的 TID Bitmap,扫描 heap data,返回符合条件的 tuple 数据。
Bitmap Index Scan
Scan 算子都有相同的三个阶段 Init/Exec/End:
在 Init 阶段初始化扫描需要的数据结构,将查询条件转换成 ScanKey;
在 Exec 阶段执行真正的扫描动作;
在 End 阶段清理相关的资源。
Bitmap Index Scan 也不例外,ExecInitBitmapIndexScan 函数实现了 Bitmap Index Scan 的 Init 逻辑,特定于 Bitmap Index Scan 扫描的数据结构 struct BMScanOpaqueData,主要是记录扫描过程中 tid bitmap 访问位置信息。
MultiExecBitmapIndexScan 函数实现了 Exec 逻辑,主要通过调用 index_getbitmap(scandesc, &bitmap)函数,获取 bitmap,然后返回 bitmap 给上一级算子。因为示例表的索引都是 btree 索引,index_getbitmap 指向的是 btgetbitmap 索引扫描函数。
btgetbitmap 函数逻辑很简单:首先调用_bt_first/_bt_next 逐条获取 item;接着通过 tbm_add_tuples 添加到 TIDBitmap 里;最终构建一个完整的 bitmap,核心就三个函_bt_first/_bt_next/tbm_add_tuples。
_bt_first 函数是索引扫描的起始,首先会调用_bt_preprocess_keys 预处理扫描键,若扫描键条件无法满足,则设置 BTScanOpaque->qual_ok 为 false 并提前结束扫描。若没找到有用的边界 keys,则需要调用_bt_endpoint 从第一页开始,否则调用_bt_search 从 BTree 的 root 节点_bt_getroot 开始扫描,直至找到符合扫描键和快照的第一个叶子节点,之后调用二分查找_bt_binsrch 找到符合扫描键的页内 item 偏移,最后将找到的页面载入到 buffer 中并返回 tuple。
_bt_next 函数会从当前页中尝试获取下一条 tuple,若当前页已没有 tuple,则调用_bt_steppage,_bt_steppage 会拿到下一页块号,之后调用_bt_readnextpage 读取该文件块中的内容,之后_bt_next 尝试从中获取下一条 tuple。重复上述过程,直至扫描结束。
tbm_add_tuples 函数添加 CTID,构建 TIDBitmap 数据结构,细节稍后讲解。
ExecEndBitmapIndexScan 函数则用来清理相应的资源。
数据结构 TIDBitmap
从上面的代码我们可以看到,btgetbitmap 会一次返回符合条件的所有 tid 组成的 TIDBitmap,而且 TIDBitmap 指向的内存区域大小是有限制的,等于 work_mem * 1024 Byte. work_mem,默认值等于 Heap Page Size。这些限制的存在使得 TIDBitmap 在设计上也有一些 trade off。
在这个数据结构中,有几个重点需要关注的字段:
TBMStatus status 字段
TBM_EMPTY 代表当前 TIDBitmap 是空
TBM_ONE_PAGE 代表 TIDBitmap 中只有一个 page 的 bitmap 信息
TBM_HASH 代表 TIDBitmap 中,bitmap 信息是存储在 hash table 里
为什么会有 TBM_ONE_PAGE 和 TBM_HASH 的区别?因为如果 TIDBitmap 只存储一个 PageTableEntry 时,不需要花费时间构建动态 hash 表,查找时也不需要通过 hash 查找,只需要返回 entry1 即可。
struct pagetable_hash pagetable
page table 是一个 hash table,按照 page 维度存储 bitmap,hash table 的 key 是 BlockNumber 类型。value 是一个 PagetableEntry 结构。一般来说可以使用 hash table 中的一个 PagetableEntry 用来存储一个 page 中哪些 tid 是符合查询需求的,block no 对应 page number, PagetableEntry 中 bitmap words 的第 n bit 代表 page 中第 n+1 个 tuple。这样当我们构建 bitmap 时,相同 block no 的 tid 会被聚合到同一个 key 对应 PagetableEntry 中,btgetbitmap 扫描完成所有存在的 TID,都按照 page 聚合,类似图 1 的做法。
我们在前面看到,TIDBitmap 的容量使用是有限制的(tbm_create 调用指定),如果一个 page 对应一个 PageTableEntry,在有大量 page 需要构建 bitmap 的时候,内存使用肯定会超出。所以 TIDBitmap 里有一个 maxentries 字段,代表 TIDBitmap 最多可以有多少个 PageTableEntry 结构来存储 bitmap。
为了满足超出 maxentries 个 page 的 bitmap 标记需求,当 tbm_add_tuples 添加 tuple id 时,page 数量超出 maxentries, bitmap 就会进入调用 tbm_lossify 函数来使部分 PageTableEntry 从 exact page 变成 lossy page 状态。即这些 PageTableEntry 不再代表某个 page 的 bitmap,而是代表一组 page 的状态。
PagetableEntry 的数据结构,在 exact page 和 lossy page 状态下具有不同的含义:
Exact page 状态:PageTableEntry 对应一个 page 的 bitmap
blockno 就是 page number
ischunk 等于 false,代表是 exact
words 的第 n bit 代表 page 的 offset = n+1 的 tuple
Lossy page 状态:PageTableEntry 等于一组 page 的状态
blockno 是一个 chunk_pageno, 对应一组 page。这一组 page 的 page no 范围就是<chunk_page_no,chunk_page_no + PAGES_PER_CHUNK>
tbm_mark_page_lossy 函数实现了 PageTableEntry 从 exact page 向 lossy page 的转换
ischunk 等于 true,代表是 lossy
words 的第 n bit 代表 page no = chunk_page_no + n 的这个 page,是有符合查询条件的 tuple 的
npages 和 nchunks 字段分别代表,hash table 里有多少 exact page 和 lossy page。
3.PagetableEntry **spages 和 PagetableEntry **schunks
这两个字段主要是在 BitmapHeapScan 阶段使用的,spages 和 schunks 在初始化 bitamp iterator 时构建,主要过程就是遍历 hash table,根据 exact page 和 lossy page 的状态,分别添加到 spages 和 schunks 里,然后按照 block no 对 spages 和 schunks 进行排序。后续在 Bitmap Heap Scan 阶段,就可以顺序访问了。
4.dsa_*相关变量,都是和并行化扫描有关的。
了解数据结构后,tbm_add_tuples 要做的事情就很清晰了:
根据 page no 在 hash table 里找到相应的 bucket,然后找到对应的 PageTableEntry(不存在则会创建)。但是如果此时只有一个 PageTableEntry(即 TBM_ONE_PAGE 状态),则直接返回 entry1 变量,不需要通过 hash 查找。
拿到 entry 后,根据 tid,解析出 offset,然后按照 offset -1 去设置 bitmap words 的比特位即可。
如果在步骤 1 中,创建一个新的 PageTableEntry,发现 npages 的数量超出了 tbm->maxentries 的值,则会调用 tbm_lossify()函数,将 TIDBITMap 中的部分 PageTableEntry 转换成 lossy page,同时按照 exact page 的减少和 lossy page 的增加,相应的修改 npages 和 nchunks 的值。
如果在步骤 2 中,因为 tbm_lossy 后,部分 PageTableEntry 是 lossy 状态的,如果此时步骤 2 拿到的是一个 lossy page,则按照 page no = chunk_page_no + n 的转换规则,设置对应的 n 个比特位。
如果最后 tbm 的全部 entry 都变成 lossy 状态了,则会触发 tbm 的扩容操作。maxentries = nentries * 2。
Bitmap Add
BitmapAnd 节点获取从 BitmapIndexScan 节点生成的位图,并输出一个对所有输入位图进行 AND 操作的位图。
Bitmap Or
同样的,BitmapOr 节点获取从 BitmapIndexScan 节点生成的位图,并输出一个对所有输入位图进行 OR 操作的位图。其中,第一个输入位图用于存储 OR 操作的结果,并返回给调用者。
Bitmap Heap Scan
Bitmap Heap Scan 采用 Bitmap Index Scan 生成的 bitmap(或者经过 BitmapAnd 和 BitmapOr 节点通过一系列位图集操作后,生成的 bitmap)来查找相关数据。位图的每个 page 可以是精确的(直接指向 tuple 的)或有损的(指向包含至少一行与查询匹配的 page)。
Bitmap Heap Scan 阶段的实现函数 BitmapHeapNext:
代码核心逻辑如下:
下层算子的执行函数 MultiExecProcNode()返回了一个 TIDBitmap;
调用 tbm_generic_begin_iterate()基于 tbm 构建了一个 iterator;
每次循环获取一个指向具体页面的 TBMIterateResult 结构,通过 table_scan_bitmap_next_block 一次读取一个 page 到 ScanDesc 的 rs_buffer 里;然后调用 table_scan_bitmap_next_tuple,根据 TBMIterateResult 里的偏移,在内存 buffer 里获取相应的 tuple;
根据 bitmap 中 PageTableEntry 的状态(即 exact 还是 lossy), 读取指定的 page;如果是 exact page,则直接读取指定 offset 的 tuple;如果是 lossy 的,则根据 filter 过滤掉不必要的 tuple,然后调用 recheck 检查其他查询条件;
调用 recheck 函数,判断 tuple 是否满足查询条件,不满足则继续 next;满足则返回 tuple 给上层节点。
代价分析
Bitmap Index Scan 的代价估算就是 Index Scan 的访问索引数据的代价,即如下计算公式:
Bitmap Heap Scan 的 cost 计算比较复杂,逻辑在 cost_bitmap_heap_scan 这个函数。首先是 Bitmap Heap Scan 读取 page 的数量的估算计算公式:

图 2:page 数量的估算公式
公式中的 sel 是选择率, 在我们这个例子里 sel=0.01027850。其次单个页面的获取成本估计在 seq_page_cost 和 random_page_cost 之间,如果 tid 分布很松散,则趋近于 random_page_cost; 如果 tid 分布聚集性好,则趋近于 seq_page_cost。在同时存在 exact 和 lossy bitmap 时,对于 exact bitmap, 处理 tuple 的数量等于 sel * reltuples。对于 lossy bitmap,则需要对 lossy page 上的每一个 tuple 进行 recheck 操作。在我们的例子中,不会超出 TID Bitmap 的 max_entries 数量,所以我们所有的 bitmap 都是精确的。
下面这个 SQL 就是模拟 Bitmap Scan 的 cost 计算逻辑(entry 全是 exact page 的情况)。计算的 total_cost 值 11560,刚好和我们前面 Plan 给出来的值 11559.98 相近。
位图扫描限制
目前大多数的分析场景,都是基于一个前提,存储的随机 IO cost 远远大于顺序 IO cost 的基础上(在 pg 中是 4 倍的差距,默认 random_page_cost=4, seq_page_cost=1)。但是今天大量新的存储硬件或者云原生存储的使用场景下,随机 IO 和顺序 IO 的差距已经不再是这种关系。当我们在启用 bitmap scan 的时候,一定要仔细考虑这其中的问题。例如下面的场景:
新型 Nvme SSD 的随机 IO 能力已经非常强,顺序 IO 和随机 IO 的性能差异已经显著缩小,io 的延迟也很低。
在存算分离架构中,访问云存储的网络延迟、IO 延迟比较大,优化器要考虑 IO 合并和 prefetching 对 cost 的影响。云存储的 IO Pattern 也很并发的从不同节点读写具备更高的性能。单次 IO 请求的延迟比较高。
总结
正常情况下,PostgreSQL 优化器可以选择出来一种最优的方式来执行,但不保证总是可以生成最优化的执行计划。
任何优化都是一个系统工程,而不是一个单点工程,通过不同资源的消耗比例来提升整体性能,Bitmap Scan 也并非完美无瑕,其优化理念是通过 Bitmap 的生成过程中增加内存和 CPU 成本来降低 IO 成本。
对于高性能存储或者内存资源充足的情况而言,并不一定总是发生物理 IO,那么 IO 就不会成为瓶颈,如果去做 Bitmap 的生成,反倒是一种浪费。此时可以根据具体的 IO 能力,考虑禁用 Bitmap scan 等方案,从而实现整体计划的最优化。
版权声明: 本文为 InfoQ 作者【HashData】的原创文章。
原文链接:【http://xie.infoq.cn/article/1f85e72943f5738214cc5ae86】。文章转载请联系作者。

还未添加个人签名 2021-03-10 加入
云原生企业级数据仓库









评论