MyBatis 数据源 DataSource 分类
MyBatis 把数据源 DataSource 分为三种:
UNPOOLED 不使用连接池的数据源
POOLED 使用连接池的数据源
JNDI 使用 JNDI 实现的数据源
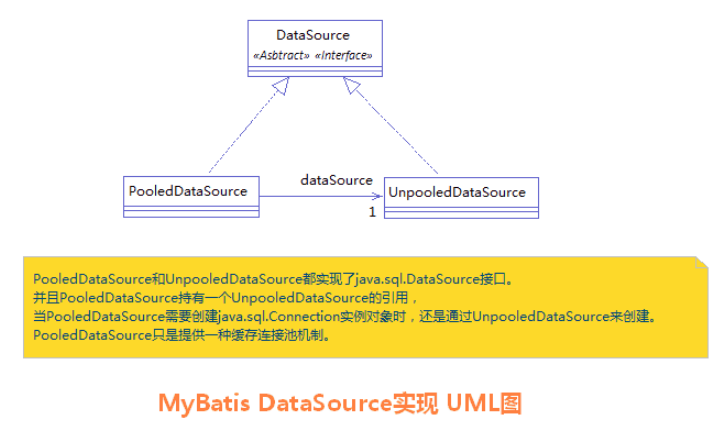
相应地,MyBatis 内部分别定义了实现了 java.sql.DataSource 接口的 UnpooledDataSource,PooledDataSource 类来表示 UNPOOLED、POOLED 类型的数据源。
对于 JNDI 类型的数据源 DataSource,则是通过 JNDI 上下文中取值。
官网 DataSource 配置内容清单
dataSource 元素使用标准的 JDBC 数据源接口来配置 JDBC 连接对象的资源。
大多数 MyBatis 应用程序会按示例中的例子来配置数据源。虽然数据源配置是可选的,但如果要启用延迟加载特性,就必须配置数据源。 有三种内建的数据源类型(也就是 type="[UNPOOLED|POOLED|JNDI]"):
UNPOOLED
这个数据源的实现会每次请求时打开和关闭连接。虽然有点慢,但对那些数据库连接可用性要求不高的简单应用程序来说,是一个很好的选择。 性能表现则依赖于使用的数据库,对某些数据库来说,使用连接池并不重要,这个配置就很适合这种情形。UNPOOLED 类型的数据源仅仅需要配置以下 5 种属性:
driver – 这是 JDBC 驱动的 Java 类全限定名(并不是 JDBC 驱动中可能包含的数据源类)。
url – 这是数据库的 JDBC URL 地址。
username – 登录数据库的用户名。
password – 登录数据库的密码。
defaultTransactionIsolationLevel – 默认的连接事务隔离级别。
defaultNetworkTimeout – 等待数据库操作完成的默认网络超时时间(单位:毫秒)。查看 java.sql.Connection#setNetworkTimeout() 的 API 文档以获取更多信息。
作为可选项,你也可以传递属性给数据库驱动。只需在属性名加上“driver.”前缀即可,例如:
这将通过 DriverManager.getConnection(url, driverProperties) 方法传递值为 UTF8 的 encoding 属性给数据库驱动。
POOLED
这种数据源的实现利用“池”的概念将 JDBC 连接对象组织起来,避免了创建新的连接实例时所必需的初始化和认证时间。 这种处理方式很流行,能使并发 Web 应用快速响应请求。
除了上述提到 UNPOOLED 下的属性外,还有更多属性用来配置 POOLED 的数据源:
poolMaximumActiveConnections – 在任意时间可存在的活动(正在使用)连接数量,默认值:10
poolMaximumIdleConnections – 任意时间可能存在的空闲连接数。
poolMaximumCheckoutTime – 在被强制返回之前,池中连接被检出(checked out)时间,默认值:20000 毫秒(即 20 秒)
poolTimeToWait – 这是一个底层设置,如果获取连接花费了相当长的时间,连接池会打印状态日志并重新尝试获取一个连接(避免在误配置的情况下一直失败且不打印日志),默认值:20000 毫秒(即 20 秒)。
poolMaximumLocalBadConnectionTolerance – 这是一个关于坏连接容忍度的底层设置, 作用于每一个尝试从缓存池获取连接的线程。 如果这个线程获取到的是一个坏的连接,那么这个数据源允许这个线程尝试重新获取一个新的连接,但是这个重新尝试的次数不应该超过 poolMaximumIdleConnections 与 poolMaximumLocalBadConnectionTolerance 之和。 默认值:3(新增于 3.4.5)
poolPingQuery – 发送到数据库的侦测查询,用来检验连接是否正常工作并准备接受请求。默认是“NO PING QUERY SET”,这会导致多数数据库驱动出错时返回恰当的错误消息。
poolPingEnabled – 是否启用侦测查询。若开启,需要设置 poolPingQuery 属性为一个可执行的 SQL 语句(最好是一个速度非常快的 SQL 语句),默认值:false。
poolPingConnectionsNotUsedFor – 配置 poolPingQuery 的频率。可以被设置为和数据库连接超时时间一样,来避免不必要的侦测,默认值:0(即所有连接每一时刻都被侦测 — 当然仅当 poolPingEnabled 为 true 时适用)。
JNDI
这个数据源实现是为了能在如 EJB 或应用服务器这类容器中使用,容器可以集中或在外部配置数据源,然后放置一个 JNDI 上下文的数据源引用。这种数据源配置只需要两个属性:
initial_context – 这个属性用来在 InitialContext 中寻找上下文(即,initialContext.lookup(initial_context))。这是个可选属性,如果忽略,那么将会直接从 InitialContext 中寻找 data_source 属性。
data_source – 这是引用数据源实例位置的上下文路径。提供了 initial_context 配置时会在其返回的上下文中进行查找,没有提供时则直接在 InitialContext 中查找。
和其他数据源配置类似,可以通过添加前缀“env.”直接把属性传递给 InitialContext。比如:
这就会在 InitialContext 实例化时往它的构造方法传递值为 UTF8 的 encoding 属性。
你可以通过实现接口 org.apache.ibatis.datasource.DataSourceFactory 来使用第三方数据源实现:
public interface DataSourceFactory { void setProperties(Properties props); DataSource getDataSource();}
复制代码
org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory 可被用作父类来构建新的数据源适配器,比如下面这段插入 C3P0 数据源所必需的代码:
import org.apache.ibatis.datasource.unpooled.UnpooledDataSourceFactory;import com.mchange.v2.c3p0.ComboPooledDataSource;
public class C3P0DataSourceFactory extends UnpooledDataSourceFactory {
public C3P0DataSourceFactory() { this.dataSource = new ComboPooledDataSource(); }}
复制代码
为了令其工作,记得在配置文件中为每个希望 MyBatis 调用的 setter 方法增加对应的属性。 下面是一个可以连接至 PostgreSQL 数据库的例子:
<dataSource type="org.myproject.C3P0DataSourceFactory"> <property name="driver" value="org.postgresql.Driver"/> <property name="url" value="jdbc:postgresql:mydb"/> <property name="username" value="postgres"/> <property name="password" value="root"/></dataSource>
复制代码
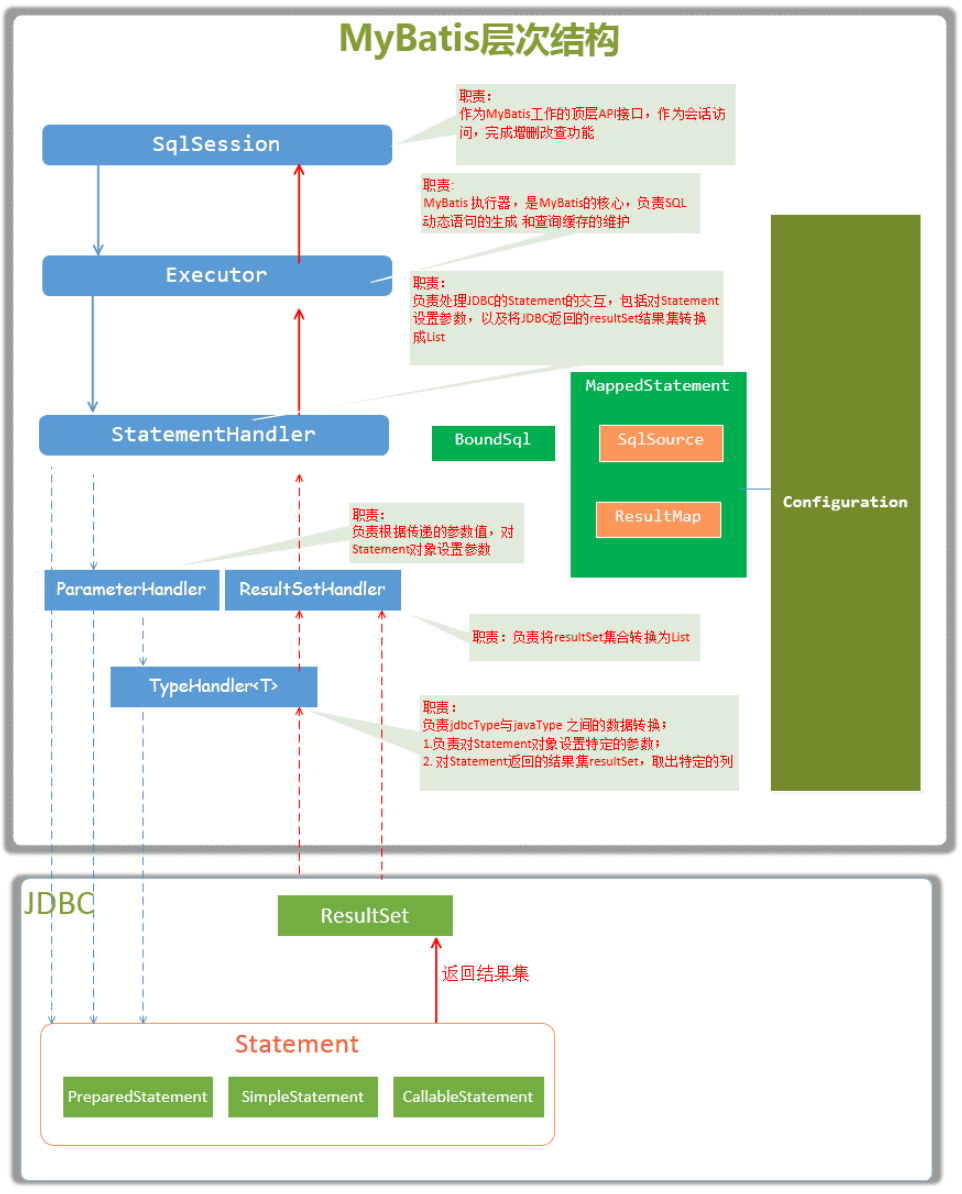
DataSource 的创建过程
MyBatis 数据源 DataSource 对象的创建发生在 MyBatis 初始化的过程中。下面让我们一步步地了解 MyBatis 是如何创建数据源 DataSource 的。
在 mybatis 的 XML 配置文件中,使用<dataSource>元素来配置数据源:
<dataSource type="org.myproject.C3P0DataSourceFactory"> <property name="driver" value="org.postgresql.Driver"/> <property name="url" value="jdbc:postgresql:mydb"/> <property name="username" value="postgres"/> <property name="password" value="root"/></dataSource>
复制代码
MyBatis 在初始化时,解析此文件,根据<dataSource>的 type 属性来创建相应类型的的数据源 DataSource,即:
type=”POOLED” :MyBatis 会创建 PooledDataSource 实例
type=”UNPOOLED” :MyBatis 会创建 UnpooledDataSource 实例
type=”JNDI” :MyBatis 会从 JNDI 服务上查找 DataSource 实例,然后返回使用
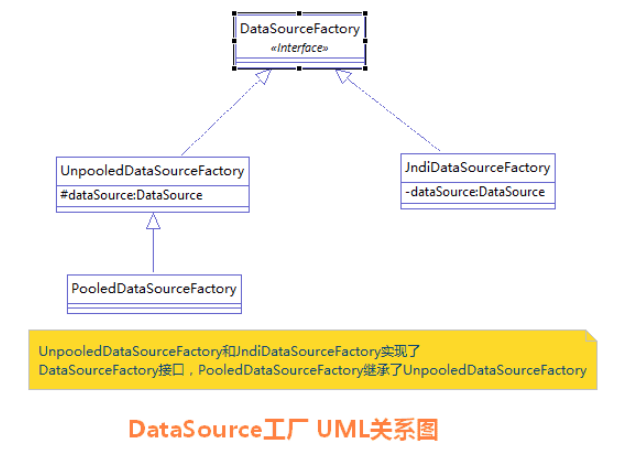
顺便说一下,MyBatis 是通过工厂模式来创建数据源 DataSource 对象的,MyBatis 定义了抽象的工厂接口:org.apache.ibatis.datasource.DataSourceFactory,通过其 getDataSource()方法返回数据源 DataSource:
public interface DataSourceFactory { void setProperties(Properties props); // 生产DataSource DataSource getDataSource(); }
复制代码
上述三种不同类型的 type,则有对应的以下 dataSource 工厂:
POOLED PooledDataSourceFactory
UNPOOLED UnpooledDataSourceFactory
JNDI JndiDataSourceFactory
其类图如下所示:
MyBatis 创建了 DataSource 实例后,会将其放到 Configuration 对象内的 Environment 对象中,供以后使用。
DataSource 什么时候创建 Connection 对象
当我们需要创建 SqlSession 对象并需要执行 SQL 语句时,这时候 MyBatis 才会去调用 dataSource 对象来创建 java.sql.Connection 对象。也就是说,java.sql.Connection 对象的创建一直延迟到执行 SQL 语句的时候。
比如,我们有如下方法执行一个简单的 SQL 语句:
String resource = "mybatis-config.xml"; InputStream inputStream = Resources.getResourceAsStream(resource); SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream); SqlSession sqlSession = sqlSessionFactory.openSession(); sqlSession.selectList("SELECT * FROM STUDENTS");
复制代码
前 4 句都不会导致 java.sql.Connection 对象的创建,只有当第 5 句 sqlSession.selectList("SELECT * FROM STUDENTS"),才会触发 MyBatis 在底层执行下面这个方法来创建 java.sql.Connection 对象:
java
protected void openConnection() throws SQLException { if (log.isDebugEnabled()) { log.debug("Opening JDBC Connection"); } connection = dataSource.getConnection(); if (level != null) { connection.setTransactionIsolation(level.getLevel()); } setDesiredAutoCommit(autoCommmit); }
复制代码
不使用连接池的 UnpooledDataSource
当 <dataSource>的 type 属性被配置成了”UNPOOLED”,MyBatis 首先会实例化一个 UnpooledDataSourceFactory 工厂实例,然后通过.getDataSource()方法返回一个 UnpooledDataSource 实例对象引用,我们假定为 dataSource。
使用 UnpooledDataSource 的 getConnection(),每调用一次就会产生一个新的 Connection 实例对象。
UnPooledDataSource 的 getConnection()方法实现如下:
/* * UnpooledDataSource的getConnection()实现 */ public Connection getConnection() throws SQLException { return doGetConnection(username, password); } private Connection doGetConnection(String username, String password) throws SQLException { //封装username和password成properties Properties props = new Properties(); if (driverProperties != null) { props.putAll(driverProperties); } if (username != null) { props.setProperty("user", username); } if (password != null) { props.setProperty("password", password); } return doGetConnection(props); } /* * 获取数据连接 */ private Connection doGetConnection(Properties properties) throws SQLException { //1.初始化驱动 initializeDriver(); //2.从DriverManager中获取连接,获取新的Connection对象 Connection connection = DriverManager.getConnection(url, properties); //3.配置connection属性 configureConnection(connection); return connection; }
复制代码
如上代码所示,UnpooledDataSource 会做以下事情:
初始化驱动:判断 driver 驱动是否已经加载到内存中,如果还没有加载,则会动态地加载 driver 类,并实例化一个 Driver 对象,使用 DriverManager.registerDriver()方法将其注册到内存中,以供后续使用。
创建 Connection 对象:使用 DriverManager.getConnection()方法创建连接。
配置 Connection 对象:设置是否自动提交 autoCommit 和隔离级别 isolationLevel。
返回 Connection 对象。
上述的序列图如下所示:
总结:从上述的代码中可以看到,我们每调用一次 getConnection()方法,都会通过 DriverManager.getConnection()返回新的 java.sql.Connection 实例。
为什么要使用连接池
首先让我们来看一下创建一个 java.sql.Connection 对象的资源消耗。我们通过连接 Oracle 数据库,创建创建 Connection 对象,来看创建一个 Connection 对象、执行 SQL 语句各消耗多长时间。代码如下:
public static void main(String[] args) throws Exception { String sql = "select * from hr.employees where employee_id < ? and employee_id >= ?"; PreparedStatement st = null; ResultSet rs = null; long beforeTimeOffset = -1L; //创建Connection对象前时间 long afterTimeOffset = -1L; //创建Connection对象后时间 long executeTimeOffset = -1L; //创建Connection对象后时间 Connection con = null; Class.forName("oracle.jdbc.driver.OracleDriver"); beforeTimeOffset = new Date().getTime(); System.out.println("before:\t" + beforeTimeOffset); con = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:xe", "louluan", "123456"); afterTimeOffset = new Date().getTime(); System.out.println("after:\t\t" + afterTimeOffset); System.out.println("Create Costs:\t\t" + (afterTimeOffset - beforeTimeOffset) + " ms"); st = con.prepareStatement(sql); //设置参数 st.setInt(1, 101); st.setInt(2, 0); //查询,得出结果集 rs = st.executeQuery(); executeTimeOffset = new Date().getTime(); System.out.println("Exec Costs:\t\t" + (executeTimeOffset - afterTimeOffset) + " ms"); }
复制代码
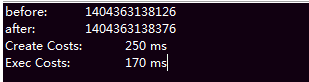
上述程序的执行结果为:
从此结果可以清楚地看出,创建一个 Connection 对象,用了 250 毫秒;而执行 SQL 的时间用了 170 毫秒。
创建一个 Connection 对象用了 250 毫秒!这个时间对计算机来说可以说是一个非常奢侈的!
这仅仅是一个 Connection 对象就有这么大的代价,设想一下另外一种情况:如果我们在 Web 应用程序中,为用户的每一个请求就操作一次数据库,当有 10000 个在线用户并发操作的话,对计算机而言,仅仅创建 Connection 对象不包括做业务的时间就要损耗 10000×250ms= 250 0000 ms = 2500 s = 41.6667 min,竟然要 41 分钟!!!如果对高用户群体使用这样的系统,简直就是开玩笑!
创建一个 java.sql.Connection 对象的代价是如此巨大,是因为创建一个 Connection 对象的过程,在底层就相当于和数据库建立的通信连接,在建立通信连接的过程,消耗了这么多的时间,而往往我们建立连接后(即创建 Connection 对象后),就执行一个简单的 SQL 语句,然后就要抛弃掉,这是一个非常大的资源浪费!
对于需要频繁地跟数据库交互的应用程序,可以在创建了 Connection 对象,并操作完数据库后,可以不释放掉资源,而是将它放到内存中,当下次需要操作数据库时,可以直接从内存中取出 Connection 对象,不需要再创建了,这样就极大地节省了创建 Connection 对象的资源消耗。由于内存也是有限和宝贵的,这又对我们对内存中的 Connection 对象怎么有效地维护提出了很高的要求。我们将在内存中存放 Connection 对象的容器称之为连接池(Connection Pool)。下面让我们来看一下 MyBatis 的线程池是怎样实现的。
使用了连接池的 PooledDataSource
同样地,我们也是使用 PooledDataSource 的 getConnection()方法来返回 Connection 对象。现在让我们看一下它的基本原理:
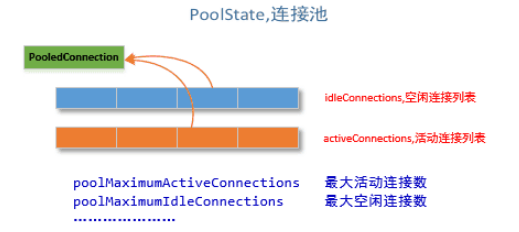
PooledDataSource 将 java.sql.Connection 对象包裹成 PooledConnection 对象放到了 PoolState 类型的容器中维护。 MyBatis 将连接池中的 PooledConnection 分为两种状态:空闲状态(idle)和活动状态(active),这两种状态的 PooledConnection 对象分别被存储到 PoolState 容器内的 idleConnections 和 activeConnections 两个 List 集合中:
idleConnections: 空闲(idle)状态 PooledConnection 对象被放置到此集合中,表示当前闲置的没有被使用的 PooledConnection 集合,调用 PooledDataSource 的 getConnection()方法时,会优先从此集合中取 PooledConnection 对象。当用完一个 java.sql.Connection 对象时,MyBatis 会将其包裹成 PooledConnection 对象放到此集合中。
activeConnections: 活动(active)状态的 PooledConnection 对象被放置到名为 activeConnections 的 ArrayList 中,表示当前正在被使用的 PooledConnection 集合,调用 PooledDataSource 的 getConnection()方法时,会优先从 idleConnections 集合中取 PooledConnection 对象,如果没有,则看此集合是否已满,如果未满,PooledDataSource 会创建出一个 PooledConnection,添加到此集合中,并返回。
PoolState 连接池的大致结构如下所示:
下面让我们看一下 PooledDataSource 的 getConnection()方法获取 Connection 对象的实现:
public Connection getConnection() throws SQLException { return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection(); } public Connection getConnection(String username, String password) throws SQLException { return popConnection(username, password).getProxyConnection(); }
复制代码
上述的 popConnection()方法,会从连接池中返回一个可用的 PooledConnection 对象,然后再调用 getProxyConnection()方法最终返回 Conection 对象。(至于为什么会有 getProxyConnection(),请关注下一节)。
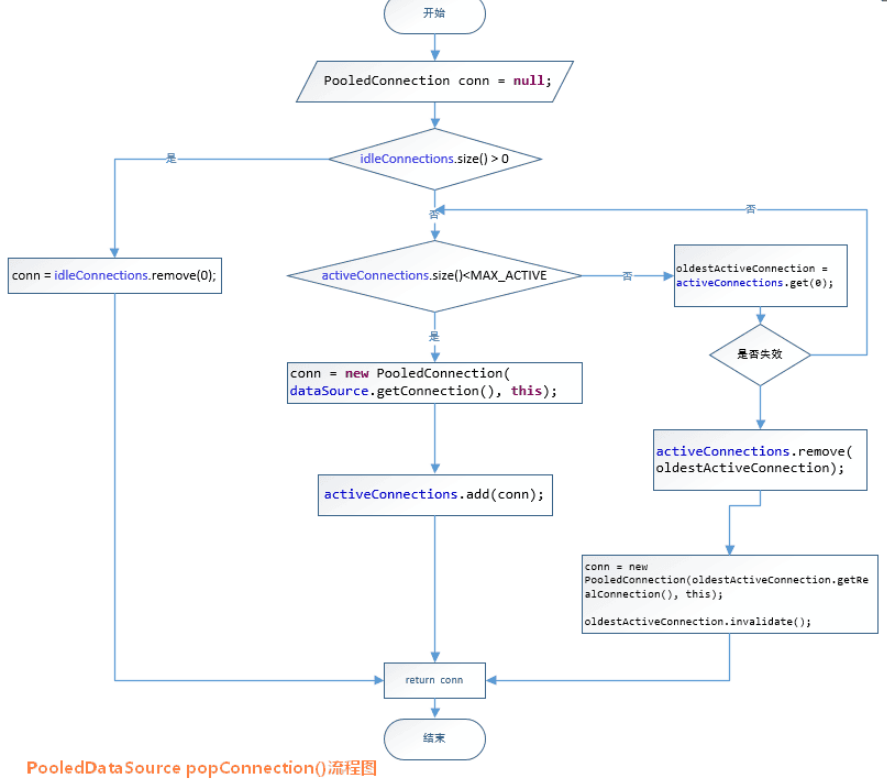
现在让我们看一下 popConnection()方法到底做了什么:
先看是否有空闲(idle)状态下的 PooledConnection 对象,如果有,就直接返回一个可用的 PooledConnection 对象;否则进行第 2 步。
查看活动状态的 PooledConnection 池 activeConnections 是否已满;如果没有满,则创建一个新的 PooledConnection 对象,然后放到 activeConnections 池中,然后返回此 PooledConnection 对象;否则进行第三步;
看最先进入 activeConnections 池中的 PooledConnection 对象是否已经过期:如果已经过期,从 activeConnections 池中移除此对象,然后创建一个新的 PooledConnection 对象,添加到 activeConnections 中,然后将此对象返回;否则进行第 4 步。
线程等待,循环 2 步
/* * 传递一个用户名和密码,从连接池中返回可用的PooledConnection */ private PooledConnection popConnection(String username, String password) throws SQLException { boolean countedWait = false; PooledConnection conn = null; long t = System.currentTimeMillis(); int localBadConnectionCount = 0; while (conn == null) { synchronized (state) { if (state.idleConnections.size() > 0) { // 连接池中有空闲连接,取出第一个 conn = state.idleConnections.remove(0); if (log.isDebugEnabled()) { log.debug("Checked out connection " + conn.getRealHashCode() + " from pool."); } } else { // 连接池中没有空闲连接,则取当前正在使用的连接数小于最大限定值, if (state.activeConnections.size() < poolMaximumActiveConnections) { // 创建一个新的connection对象 conn = new PooledConnection(dataSource.getConnection(), this); @SuppressWarnings("unused") //used in logging, if enabled Connection realConn = conn.getRealConnection(); if (log.isDebugEnabled()) { log.debug("Created connection " + conn.getRealHashCode() + "."); } } else { // Cannot create new connection 当活动连接池已满,不能创建时,取出活动连接池的第一个,即最先进入连接池的PooledConnection对象 // 计算它的校验时间,如果校验时间大于连接池规定的最大校验时间,则认为它已经过期了,利用这个PoolConnection内部的realConnection重新生成一个PooledConnection // PooledConnection oldestActiveConnection = state.activeConnections.get(0); long longestCheckoutTime = oldestActiveConnection.getCheckoutTime(); if (longestCheckoutTime > poolMaximumCheckoutTime) { // Can claim overdue connection state.claimedOverdueConnectionCount++; state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime; state.accumulatedCheckoutTime += longestCheckoutTime; state.activeConnections.remove(oldestActiveConnection); if (!oldestActiveConnection.getRealConnection().getAutoCommit()) { oldestActiveConnection.getRealConnection().rollback(); } conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this); oldestActiveConnection.invalidate(); if (log.isDebugEnabled()) { log.debug("Claimed overdue connection " + conn.getRealHashCode() + "."); } } else { //如果不能释放,则必须等待有 // Must wait try { if (!countedWait) { state.hadToWaitCount++; countedWait = true; } if (log.isDebugEnabled()) { log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection."); } long wt = System.currentTimeMillis(); state.wait(poolTimeToWait); state.accumulatedWaitTime += System.currentTimeMillis() - wt; } catch (InterruptedException e) { break; } } } } //如果获取PooledConnection成功,则更新其信息 if (conn != null) { if (conn.isValid()) { if (!conn.getRealConnection().getAutoCommit()) { conn.getRealConnection().rollback(); } conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password)); conn.setCheckoutTimestamp(System.currentTimeMillis()); conn.setLastUsedTimestamp(System.currentTimeMillis()); state.activeConnections.add(conn); state.requestCount++; state.accumulatedRequestTime += System.currentTimeMillis() - t; } else { if (log.isDebugEnabled()) { log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection."); } state.badConnectionCount++; localBadConnectionCount++; conn = null; if (localBadConnectionCount > (poolMaximumIdleConnections + 3)) { if (log.isDebugEnabled()) { log.debug("PooledDataSource: Could not get a good connection to the database."); } throw new SQLException("PooledDataSource: Could not get a good connection to the database."); } } } } } if (conn == null) { if (log.isDebugEnabled()) { log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection."); } throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection."); } return conn; }
复制代码
对应的处理流程图如下所示:
如上所示,对于 PooledDataSource 的 getConnection()方法内,先是调用类 PooledDataSource 的 popConnection()方法返回了一个 PooledConnection 对象,然后调用了 PooledConnection 的 getProxyConnection()来返回 Connection 对象。
当我们的程序中使用完 Connection 对象时,如果不使用数据库连接池,我们一般会调用 connection.close()方法,关闭 connection 连接,释放资源。如下所示:
private void test() throws ClassNotFoundException, SQLException { String sql = "select * from hr.employees where employee_id < ? and employee_id >= ?"; PreparedStatement st = null; ResultSet rs = null; Connection con = null; Class.forName("oracle.jdbc.driver.OracleDriver"); try { con = DriverManager.getConnection("jdbc:oracle:thin:@127.0.0.1:1521:xe", "louluan", "123456"); st = con.prepareStatement(sql); //设置参数 st.setInt(1, 101); st.setInt(2, 0); //查询,得出结果集 rs = st.executeQuery(); //取数据,省略 //关闭,释放资源 con.close(); } catch (SQLException e) { con.close(); e.printStackTrace(); } }
复制代码
调用过 close()方法的 Connection 对象所持有的资源会被全部释放掉,Connection 对象也就不能再使用。
那么,如果我们使用了连接池,我们在用完了 Connection 对象时,需要将它放在连接池中,该怎样做呢?
为了和一般的使用 Conneciton 对象的方式保持一致,我们希望当 Connection 使用完后,调用.close()方法,而实际上 Connection 资源并没有被释放,而实际上被添加到了连接池中。这样可以做到吗?答案是可以。上述的要求从另外一个角度来描述就是:能否提供一种机制,让我们知道 Connection 对象调用了什么方法,从而根据不同的方法自定义相应的处理机制。恰好代理机制就可以完成上述要求.
怎样实现 Connection 对象调用了 close()方法,而实际是将其添加到连接池中:
这是要使用代理模式,为真正的 Connection 对象创建一个代理对象,代理对象所有的方法都是调用相应的真正 Connection 对象的方法实现。当代理对象执行 close()方法时,要特殊处理,不调用真正 Connection 对象的 close()方法,而是将 Connection 对象添加到连接池中。
MyBatis 的 PooledDataSource 的 PoolState 内部维护的对象是 PooledConnection 类型的对象,而 PooledConnection 则是对真正的数据库连接 java.sql.Connection 实例对象的包裹器。
PooledConnection 对象内持有一个真正的数据库连接 java.sql.Connection 实例对象和一个 java.sql.Connection 的代理,其部分定义如下:
class PooledConnection implements InvocationHandler { //...... //所创建它的datasource引用 private PooledDataSource dataSource; //真正的Connection对象 private Connection realConnection; //代理自己的代理Connection private Connection proxyConnection; //...... }
复制代码
PooledConenction 实现了 InvocationHandler 接口,并且,proxyConnection 对象也是根据这个它来生成的代理对象:
public PooledConnection(Connection connection, PooledDataSource dataSource) { this.hashCode = connection.hashCode(); this.realConnection = connection; this.dataSource = dataSource; this.createdTimestamp = System.currentTimeMillis(); this.lastUsedTimestamp = System.currentTimeMillis(); this.valid = true; this.proxyConnection = (Connection) Proxy.newProxyInstance(Connection.class.getClassLoader(), IFACES, this); }
复制代码
实际上,我们调用 PooledDataSource 的 getConnection()方法返回的就是这个 proxyConnection 对象。当我们调用此 proxyConnection 对象上的任何方法时,都会调用 PooledConnection 对象内 invoke()方法。
让我们看一下 PooledConnection 类中的 invoke()方法定义:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { String methodName = method.getName(); //当调用关闭的时候,回收此Connection到PooledDataSource中 if (CLOSE.hashCode() == methodName.hashCode() && CLOSE.equals(methodName)) { dataSource.pushConnection(this); return null; } else { try { if (!Object.class.equals(method.getDeclaringClass())) { checkConnection(); } return method.invoke(realConnection, args); } catch (Throwable t) { throw ExceptionUtil.unwrapThrowable(t); } } }
复制代码
从上述代码可以看到,当我们使用了 pooledDataSource.getConnection()返回的 Connection 对象的 close()方法时,不会调用真正 Connection 的 close()方法,而是将此 Connection 对象放到连接池中。
JNDI 类型的数据源 DataSource
对于 JNDI 类型的数据源 DataSource 的获取就比较简单,MyBatis 定义了一个 JndiDataSourceFactory 工厂来创建通过 JNDI 形式生成的 DataSource。下面让我们看一下 JndiDataSourceFactory 的关键代码:
if (properties.containsKey(INITIAL_CONTEXT) && properties.containsKey(DATA_SOURCE)) { //从JNDI上下文中找到DataSource并返回 Context ctx = (Context) initCtx.lookup(properties.getProperty(INITIAL_CONTEXT)); dataSource = (DataSource) ctx.lookup(properties.getProperty(DATA_SOURCE)); } else if (properties.containsKey(DATA_SOURCE)) { //从JNDI上下文中找到DataSource并返回 dataSource = (DataSource) initCtx.lookup(properties.getProperty(DATA_SOURCE)); }
复制代码
文章转载自:Seven
原文链接:https://www.cnblogs.com/seven97-top/p/18660719
体验地址:http://www.jnpfsoft.com/?from=001YH














评论