
分布式系统学习:分布式锁
1. 为什么要用分布式锁?
分布式系统下,不同的服务/客户端通常运行在独立的 JVM 进程上。如果多个 JVM 进程共享同一份资源的话,使用本地锁就没办法实现资源的互斥访问了。于是,分布式锁 就诞生了
分布式锁的特点:
互斥:任意时刻,锁只能被一个线程持有
高可用:锁服务本身是高可用的,一个节点出问题,能自动切换到另一个节点
可重入:获取过锁的节点,可再次获取锁;
超时机制:为了防止锁无法被释放的异常情况,需要设置超时时间,过了超时时间,锁自动释放;
自动续期:如果任务处理时间超过超时时间,会出现任务未处理完成而锁释放的情况。因此可开启一个监听线程,监听任务还未完成就延长锁的超时时间;
2. 乐观锁和悲观锁
悲观锁:认为多线程环境下,每次访问共享资源一定会出现冲突,所以访问资源前就加锁;
乐观锁:认为冲突是偶然情况,没有竞争才是普遍情况。一开始就不加锁,在出现冲突时采取补救措施,简单概述:先修改共享资源,再验证有没有发生冲突,如没有,则操作完成。如果有其他线程已经修改过这个资源,就放弃本次操作。
使用场景:
乐观锁去除了加锁解锁的操作,但是一旦冲突后的重试成本非常高,只有再冲突概率非常低,且加锁成本比较高的场景,才考虑使用乐观锁
3.分布式锁的实现方式
常见分布式锁实现方案如下:
基于关系型数据库比如 MySQL 实现分布式锁。
基于分布式协调服务 ZooKeeper 实现分布式锁。
基于分布式键值存储系统比如 Redis 、Etcd 实现分布式锁。
3.1 基于 Redis 的实现
setnx + expire 组合命令
在 redis 中,SETNX命令可以实现互斥,即 Set if not exist 的意思,如果 key 不存在,才可设置 key 的值,如果 key 已存在,SETNX命令啥也做不了
setnx 命令不能设置 key 的超时时间,因此需要通过 expire 命令来设置 key 的超时时间
加锁
这里常见的问题就是加锁和设置过期时间是两个操作,不是原子操作,可能出现加锁成功,设置超时时间失败,出现锁永远不会释放的问题。为了解决这个问题,Redis 从2.6.12之后支持 set 命令增加过期时间参数:
关于 Redis SET命令的详细说明可以查看 Redis 官方文档:https://redis.io/docs/latest/commands/set/
参数说明:
EX 秒数:设置指定的过期时间,以秒为单位(正整数)。
PX 毫秒数:设置指定的过期时间,以毫秒为单位(正整数)。
EXAT 时间戳(秒):设置键将在指定的 Unix 时间戳(以秒为单位)过期(正整数)。
PXAT 时间戳(毫秒):设置键将在指定的 Unix 时间戳(以毫秒为单位)过期(正整数)。
NX:仅在键不存在时设置键。
XX:仅在键已存在时设置键。
KEEPTTL:保留键的生存时间。
GET:返回键存储的旧字符串,如果键不存在则返回 nil。如果键存储的值不是字符串,则返回错误并终止 SET 操作。
释放锁
释放锁时通过DEL命令删除 key 即可,但不能乱删,要保证执行操作的客户端就是加锁的客户端。为了防止误删了其他锁,这里建议使用 lua 脚本通过 key 对应的 value 来判断,使用 Lua 脚本保证解锁操作的原子性
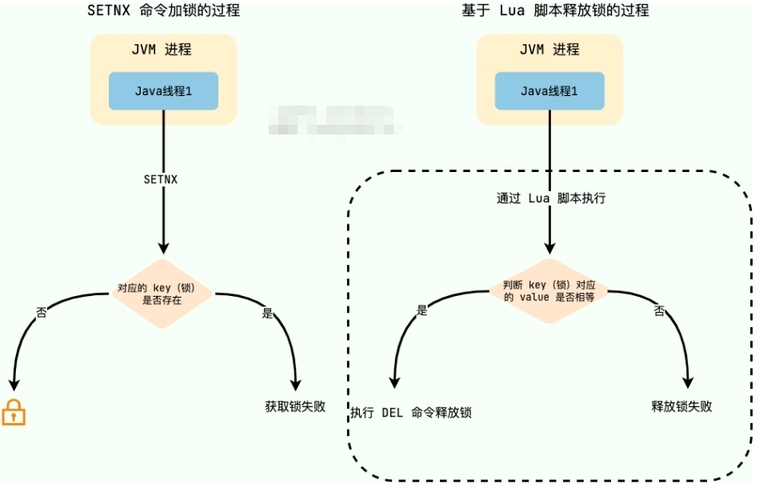
面试题:如何实现锁的优雅续期?
如果任务还没执行完成,锁就过期了,这样就出现锁提前过期的问题了。为了解决这个问题,Java 语言已经有了解决方案:Redisson
其他语言的解决方案,可以在 Redis 官方文档中找到:
https://redis.io/docs/latest/develop/use/patterns/distributed-locks/

官方提供了Redlock的算法,用于实现分布式锁管理器。
下面讲讲 Redisson 的自动续期机制,原理很简单:提供了一个专门用来监控和续期锁的 Watch Dog(看门狗)机制,如果操作共享资源的线程还未执行完成的话,Watch Dog 会不断延长锁的过期时间。
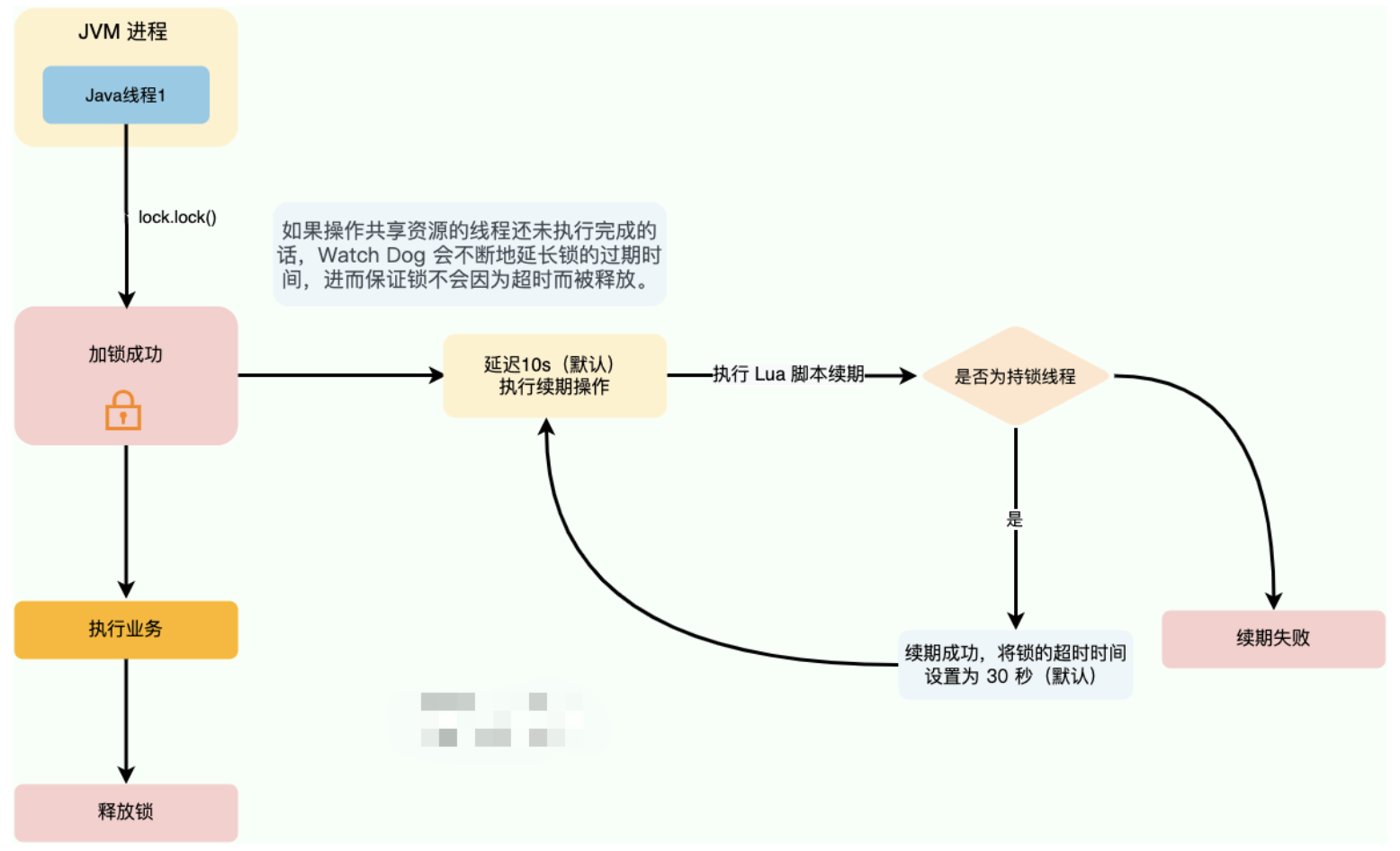
看门狗核心逻辑如下:
从
EXPIRATION_RENEWAL_MAP中获取锁的状态。如果锁已经被释放,则不再续期。如果锁仍然存在且当前线程持有锁,则异步调用
renewExpirationAsync方法来更新锁的过期时间。如果续期成功,会递归调用
renewExpiration方法,重新启动定时任务,继续进行下一次续期;
如何实现可重入锁?
可重入锁指的是一个线程可以多次获取同一把锁,如 Java 中的synchronized和ReentrantLock都是可重入锁
实现可重入锁的核心思路:线程在获取锁的时候判断是否为自己的锁,如果是的话,就不用再重新获取了。需要为每个锁关联一个可重入计数器和一个占有它的线程,计数器大于 0 时,锁被占用,需判断请求获取锁的线程和当前持有锁的线程是否为一个。
Redisson 本身已经支持了多种锁:可重入锁(Reentrant Lock)、自旋锁(Spin Lock)、公平锁(Fair Lock)、多重锁(MultiLock)、 红锁(RedLock)、 读写锁(ReadWriteLock)
3.2 基于 Zookeeper 的实现
当前面试比较卷啊,面试官可能会问除了用 Redis 做分布式锁外,还有没有其他方法,所以还是要多了解一种方法的
前面分布式理论基础时已经了解到 Zookeeper 是 CP 模式,提供数据一致性,因此适合作为分布式锁的选型。
ZooKeeper 分布式锁是基于 临时顺序节点 和 Watcher(事件监听器) 实现的。
分布式锁的实现步骤为:
(1)创建锁节点
在 Zookeeper 中创建一个父节点(如
/lock),作为锁的根节点每个客户端尝试获取锁时,会在
/lock下创建一个临时顺序节点(如/lock/lock-0000000001)
(2)获取锁
客户端创建完临时顺序节点后,会获取
/lock下所有子节点的列表。客户端检查自己创建的节点是否是当前所有子节点中序号最小的节点:如果是,则认为获取了锁。如果不是,客户端会监听比自己序号小的紧邻前一个节点的删除事件(即
/lock/lock-0000000001会监听/lock/lock-0000000000的删除事件)
(3)释放锁
当持有锁的客户端完成任务后,它会主动删除自己创建的临时顺序节点
由于 Zookeeper 的监听机制,下一个等待锁的客户端会收到通知,再次检查自己是否是当前序号最小的节点
如果是,则获取锁并继续执行

实际开发过程中,通常使用 Curator 来实现 Zookeeper 的分布式锁,该框架封装了各种 API 可直接使用,可实现:
InterProcessMutex:分布式可重入排它锁InterProcessSemaphoreMutex:分布式不可重入排它锁InterProcessReadWriteLock:分布式读写锁InterProcessMultiLock:将多个锁作为单个实体管理的容器,获取锁的时候获取所有锁,释放锁也会释放所有锁资源(忽略释放失败的锁)。
3.3 基于数据库的实现
这里只简单说下基于 MySQL 数据库实现的分布式锁,实际开发中应该没人用 MySQL 做分布式锁吧
基于悲观锁的方式
在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)
如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 具体响应方式由开发者根据实际需要决定。
如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。
示例:
我们使用了select…for update的方式,for update是一种行级锁,也叫排它锁。如果一条select语句后面加上for update,其他事务可以读取,但不能进进行更新操作。这样就通过开启排他锁的方式实现了悲观锁
基于乐观锁的方式
使用版本号,可以在数据初始化时指定一个版本号,每次对数据的更新操作都对版本号执行+1 操作。并判断当前版本号是不是该数据的最新的版本号
示例:
使用场景选择
这里还是使用 Redis 和 Zookeeper 的两种方式,MySQL 的方式性能较低
如果对性能要求比较高的话,建议使用 Redis 实现分布式锁。推荐优先选择 Redisson 提供的现成分布式锁,而不是自己实现。实际项目中不建议使用 Redlock 算法,成本和收益不成正比,可以考虑基于 Redis 主从复制+哨兵模式实现分布式锁。
如果对一致性要求比较高,建议使用 ZooKeeper 实现分布式锁,推荐基于 Curator 框架来实现。不过,现在很多项目都不会用到 ZooKeeper,如果单纯是因为分布式锁而引入 ZooKeeper 的话,那是不太可取的,不建议这样做,为了一个小小的功能增加了系统的复杂度。
文章转载自:卷福同学

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论