
架构设计|基于 raft-listener 实现实时同步的主备集群
背景以及需求
线上业务对数据库可用性可靠性要求较高,要求需要有双 AZ 的主备容灾机制。
主备集群要求数据和 schema 信息实时同步,数据同步平均时延要求在 1s 之内,p99 要求在 2s 之内。
主备集群数据要求一致
要求能够在主集群故障时高效自动主备倒换或者手动主备倒换,主备倒换期间丢失的数据可找回。
为什么使用 Listener
Listener:这是一种特殊的 Raft 角色,并不参与投票,也不能用于多副本的数据一致性。
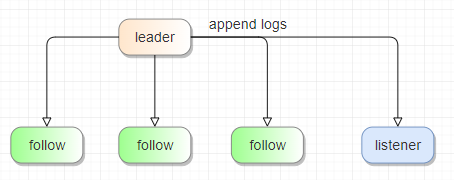
原本的 NebulaGraph 中的 Listener 是一个 Raft 监听器,它的作用是将数据异步写入外部的 Elasticsearch 集群,并在查询时去查找 ES 以实现全文索引的功能。
这里我们需要的是 Listener 的监听能力,用于快速同步数据到其他集群,并且是异步的执行,不影响主集群的正常读写。
这里我们需要定义两个新的 Listener 类型:
Meta Listener:用于同步表结构以及其他元数据信息
Storage Listener:用于同步 storaged 服务的数据
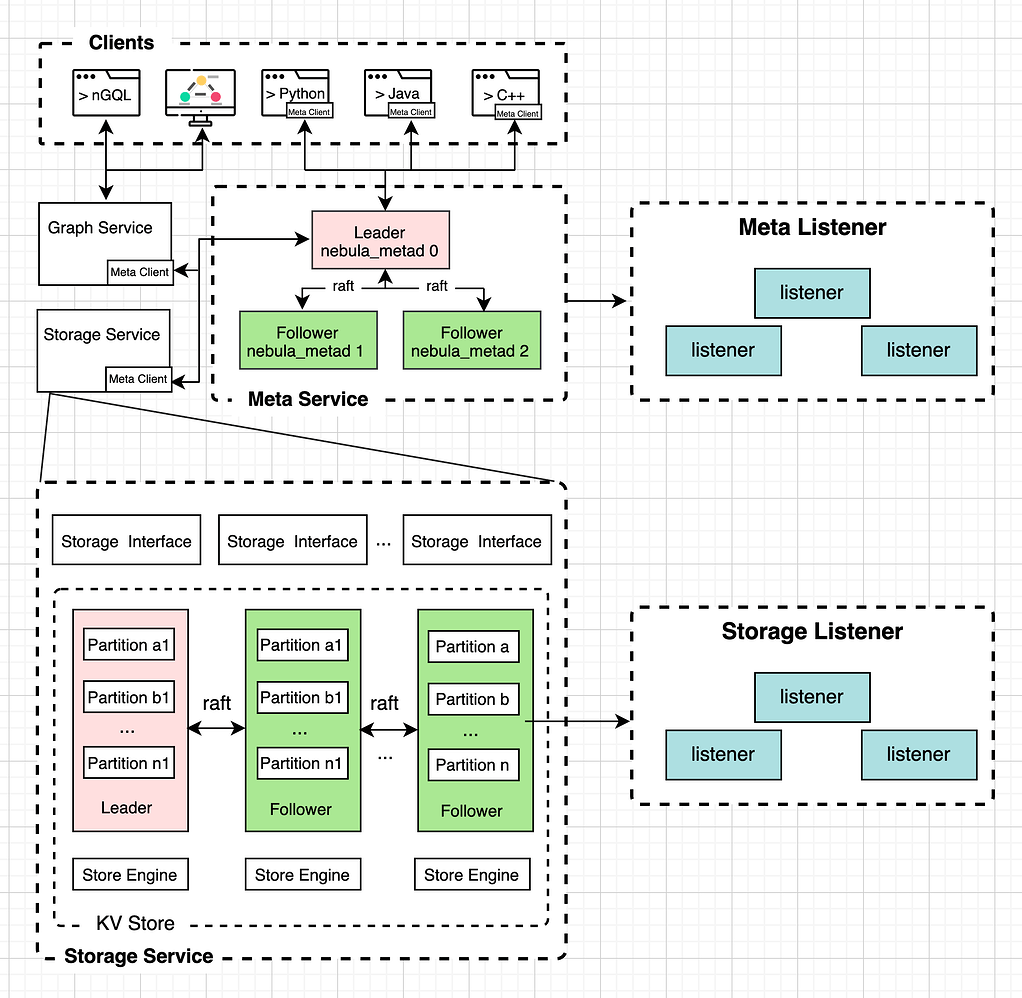
这样 storaged 服务和 metad 服务的 part leader 节点接受到写请求时,除了同步一份数据给 follower 节点,也会同步一份给各自的 listener 节点。
备集群如何接受数据?
现在我们面临几个问题:
两个新增 Listener 在接收到 leader 同步的日志后,应该如何再同步给备集群?
我们需要匹配和解析不同的数据操作,例如添加点、删除点、删除边、删除带索引的数据等等操作;
我们需要将解析到的不同操作的数据重新组装成一个请求发送给备集群的 storaged 服务和 metad 服务;
通过走读 nebula-storaged 的内核代码我们可以看到,无论是 metad 还是 storaged 的各种创建删除表结构以及各种类型数据的插入,最后都会序列化成一个 wal 的 log 发送给 follower 以及 listener 节点,最后存储在 RocksDB 中。
因此,我们的 listener 节点需要具备从 log 日志中解析并识别操作类型的能力,和封装成原请求的能力,因为我们需要将操作同步给备集群的 metad 以及 storaged 服务。
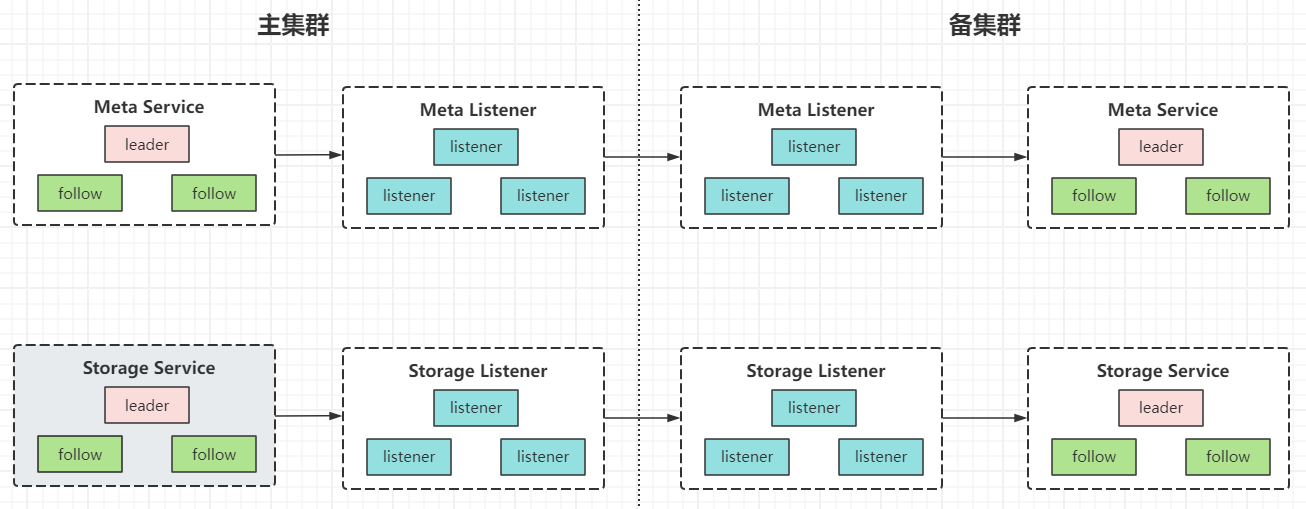
这里涉及到一个问题,主集群的 listener 需要如何感知备集群?备集群 metad 服务的信息以及 storaged 服务的信息?从架构设计上来看,两个集群之间应该有一个接口通道互相连接,但又不干涉,如果由 listener 节点直接发送请求给备集群的 nebula 进程,两个集群的边界就不是很明显了。所以这里我们再引入一个备集群的服务 listener 服务,它用于接收来自主集群的 listener 服务的请求,并将请求转发给自己集群的 metad 以及 storaged 服务。
这样做的好处。两边集群的服务模块是对称的,方便我们后面快速地做主备切换。
Listener 节点的管理和可靠性
为了保证双 AZ 环境的可靠性,很显然 Listener 节点也是需要多节点多活的,在 nebula 内核源码中是有对于 listener 的管理逻辑,但是比较简单,我们还需要设计一个 ListenerManager 实现以下几点能力:
listener 节点注册以及删除命令
listener 节点动态负载均衡(尽量每个 space 各个 part 分布的 listener 要均匀)
listener 故障切换
节点注册管理以及负载均衡都比较简单好设计,比较重要的一点是故障切换应该怎么做?
listener 故障切换的设计
listener 节点故障切换的需求可以拆分为以下几个部分:
listener 同步 wal 日志数据时周期性记录同步的进度(commitId && appendLogId);
ListenerManager 感知到 listener 故障后,触发动态负载均衡机制,将故障 listener 的 part 分配给其他在运行的 listener;
分配到新 part 的 listener 们获取原先故障 listener 记录的同步进度,并以该进度为起始开始同步数据;
至于 listener 同步 wal 日志数据时周期性记录同步的进度应该记录到哪里?可以是存储到 metad 服务中,也可以存储到 storaged 服务对应的 part 中。
nebula 主备切换设计
在聊主备切换之前,我们还需要考虑一件事,那就是双 AZ 环境中,应该只能有主集群是可读可写的,而其他备集群应该是只读不能写。这样是为了保证两边数据的最终一致性,备集群的写入只能是由主集群的 listener 请求来写入的,而不能被 graphd 服务的请求写入。
所以我们需要对集群状态增加一种“只读模式”,在这种只读模式下,表明当前集群状态是处于备集群的状态,拒绝来自 graphd 服务的写操作。同样的,备集群的 listener 节点处在只读状态时,也只能接收来自主集群的请求并转发给备集群的进程,拒绝来自备集群的 wal 日志同步。
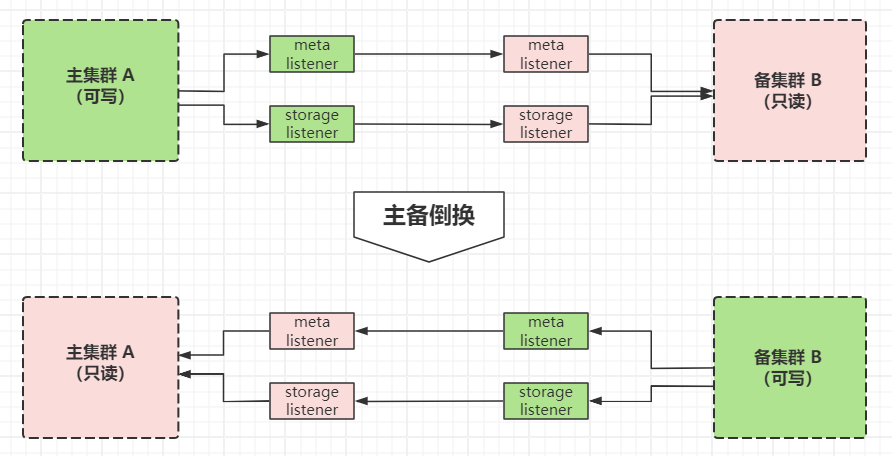
主备倒换发生时,需要有以下几个动作:
主集群的每个 listener 记录自己所负责的 part 的同步进度(commitId && appendLogId);
备集群的 nebula 服务转换为可写;
备集群的 listener 节点转换为可写,并且开始接收来自自己集群的 metad 和 storaged 进程的 wal 日志;
主集群的 listener 以及各个服务转换为只读状态,开始接收来自新的主集群的数据同步请求;
这几个动作细分下来,最主要的内容就是状态转换以及上下文信息保存和同步,原主集群需要保存自己主备切换前的上文信息(比如同步进度),新的主集群需要加载自己的数据同步起始进度(从当前最新的 commitLog 开始)
主备切换过程中的数据丢失问题
很明显,在上面的设计中,当主备切换发生时,会有一段时间的“双主”的阶段,在这个阶段内,原主集群的剩余日志已经不能再同步给备集群了,这就是会被丢失的数据。如何恢复这些被丢失的数据,可能的方案有很多,因为原主集群的同步进度是有记录的,有哪些数据还没同步完也是可以查询到的,所以可以手动或者自动去单独地同步那一段缺失数据。
当然这种方案也会引入新的问题,这段丢失地数据同步给主集群后,主集群会再次同步一遍回现在的备集群,一段 wal 数据的两次重复操作,不知道为引起什么其他的问题。
所以关于主备切换数据丢失的问题,我们还没有很好的处理方案,感兴趣的伙伴欢迎在评论区讨论。
感谢你的阅读 (///▽///)
对图数据库 NebulaGraph 感兴趣?欢迎前往 GitHub ✨ 查看源码:https://github.com/vesoft-inc/nebula
文章转载自:NebulaGraph

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论