
分布式图计算如何实现?带你一窥图计算执行计划
GeaFlow(品牌名 TuGraph-Analytics) 已正式开源,欢迎大家关注!!! 欢迎给我们 Star 哦! GitHub👉https://github.com/TuGraph-family/tugraph-analytics更多精彩内容,关注我们的博客 https://geaflow.github.io/
图的遍历
我们一般说的的图算法是指在图结构上进行迭代计算的计算过程,例如有最短路径算法、最小生成树算法、PageRank 算法等。 这些算法往往用于解决图上的特定一类问题。例如最短路径算法主要用于寻找两个节点之间的最短路径,PageRank 算法则可以给节点重要性排序。
然而,还有一类被广泛使用的'图算法',它们也通过迭代计算处理,且在实际应用中有着广泛的应用,如金融风险管理、社交网络分析等。
它们就是图遍历,又被称之为 Traversal。图 Traversal 解决遍历图中节点的问题,通过可控的顺序访问图中节点和边,以便对图进行处理或收集信息。
一般的图遍历算法可以分为两种主要类型:深度优先搜索(DFS)和广度优先搜索(BFS)。手工实现算法只有既定的走图遍历模式,很难解决特定的图查询问题。
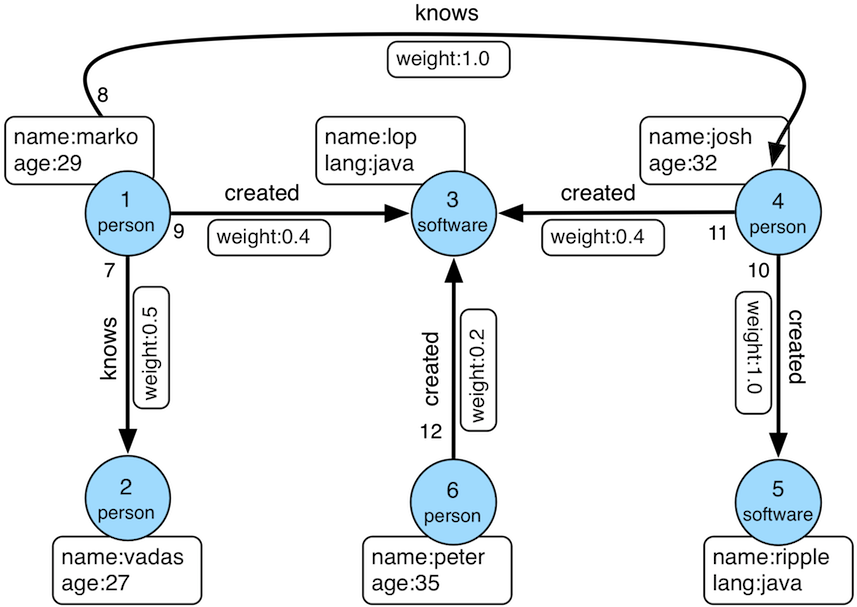
举例来说,在这个简单示例图中,如果要查找所有的'人创建软件'的模式,无论 DFS 还是 BFS 都需要实现复杂的计算逻辑,无法直观取得结果。
因此,基于图查询中的多元化走图需要,图查询语言自然产生。人们希望使用诸如 (:person)-[:created]->(:software) 的描述来达成需求。
图查询语言 GQL
主流的图查询语言有 Gremlin 和 GQL 等,其中 Gremlin 是直接命令式语言,每一个调用都明确地声明了下一步走图的方向。对于命令语言,查询本身就是执行计划,计算机容易理解,但人类学习成本较高,理解困难。
GQL 则是声明式语言,简单直观,例如'(:person)-[:created]->(:software)'就表示了我们要查找人创建软件的模式。'Return person.name, software.name;'就可以立即获得作者和软件的名称,大大降低了人理解语言的成本,学习成本接近于零。
然而声明式语言的缺点是描述不直接反应计算机执行的过程,因此需要执行平台将其'翻译'为计算机可以理解的执行计划来处理。
分布式图遍历执行计划
图数据的规模往往十分庞大,例如 Github 交互的图规模可以到达数百 TB 规模,金融交易数据的规模可以达到万亿规模。如此复杂的图无法通过单机完成遍历计算。
因此分布式图计算引擎需要的是可以分布式执行的计划,这对执行计划的效率、可扩展性、负载均衡性提出了极高要求。
我们来看几个常见 GQL 语句的执行计划,一探究竟。这里以蚂蚁集团开源的图计算系统 GeaFlow(品牌名为 TuGraph-Analytics)为例,感兴趣的同学文末有开源地址。
走图
以示例图为例,我们要查看人与人之间的好友关系时,可以使用如下 GQL 描述。
该描述非常直观,表示了查询两个人 a, b 之间类型为 knows 的边,要求 b 的 id 不能为 1,返回三个结果字段作为结果表。
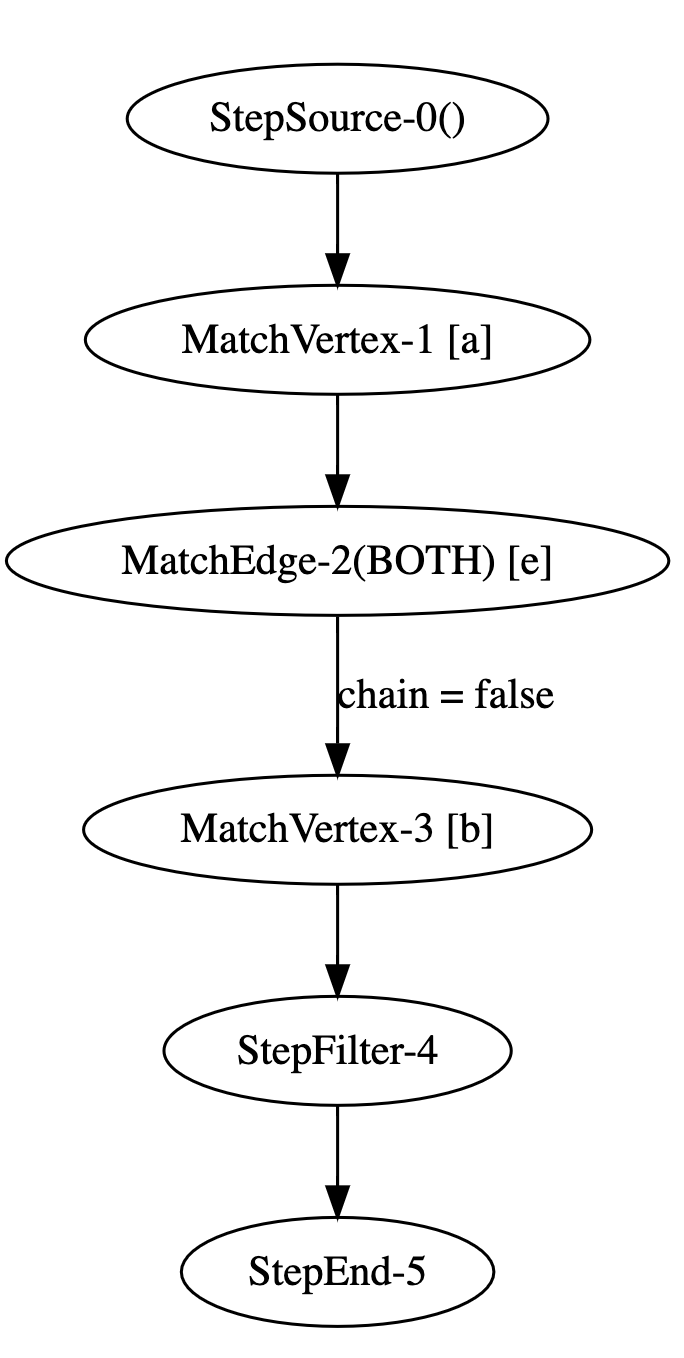
由于查询并不复杂,其产生的执行计划也不复杂,只有 6 个步骤。
StepSource 表示读取图,数字表示步骤的标识 ID。MatchVertex 步骤表示匹配对应类型的点,例如点 a 被声明为 person 类型,则必须把其他类型的点过滤掉。
MatchEdge 步骤表示匹配对应类型的边,BOTH 表示边的方向不限,因为好友关系是一种相互的关系。
StepFilter 步骤对应了 GQL 查询中的 b.id != 1 条件,类似 SQL 语言的 WHERE 语句,会被翻译成一个特定步骤。StepEnd 步骤表示执行计划结束。
关注细节的同学可能发现了,在 MatchEdge(e)和 MatchVertex(b)之间被标记为不能串联。
这实际对应了走图的 Shuffle 过程,匹配点和边都可以在一个点原地完成,这在物理上对应了一台机器。如果我们从出边走到其对端点,则对端点可能并不存储在这台机器上,因此会产生数据 Shuffle 过程,相当于 DFS/BFS 算法中的深度+1,在执行计划上反映为两个单步不可串联。
聚合
简单的走图过程几乎可以被 BFS/DFS 算法的实现所替代,例如上面走图的简单例子,可以转化为 2 轮迭代的遍历完成。
但实际上,随着图研发的深入,走图需求会越来越复杂,相应地 GQL 查询会越来越长,执行计划也会变得复杂。一旦执行计划复杂到一定程度,人工实现就变得不现实了。
来看这个点上聚合的例子,当我们从点 a 走到点 b 后,发起一个聚合子查询,该查询过滤了 b 点创建软件的数量,要求该数量为 0。待子查询返回后,根据其结果,我们可以按照条件过滤路径,然后输出结果所需的 a, b 对。
该查询产生的执行计划如图。这个执行计划包含了一个嵌套关系,在步骤 14 进入子查询 1。子查询 1 在步骤 13 返回,根据返回结果我们才能继续执行步骤 15。
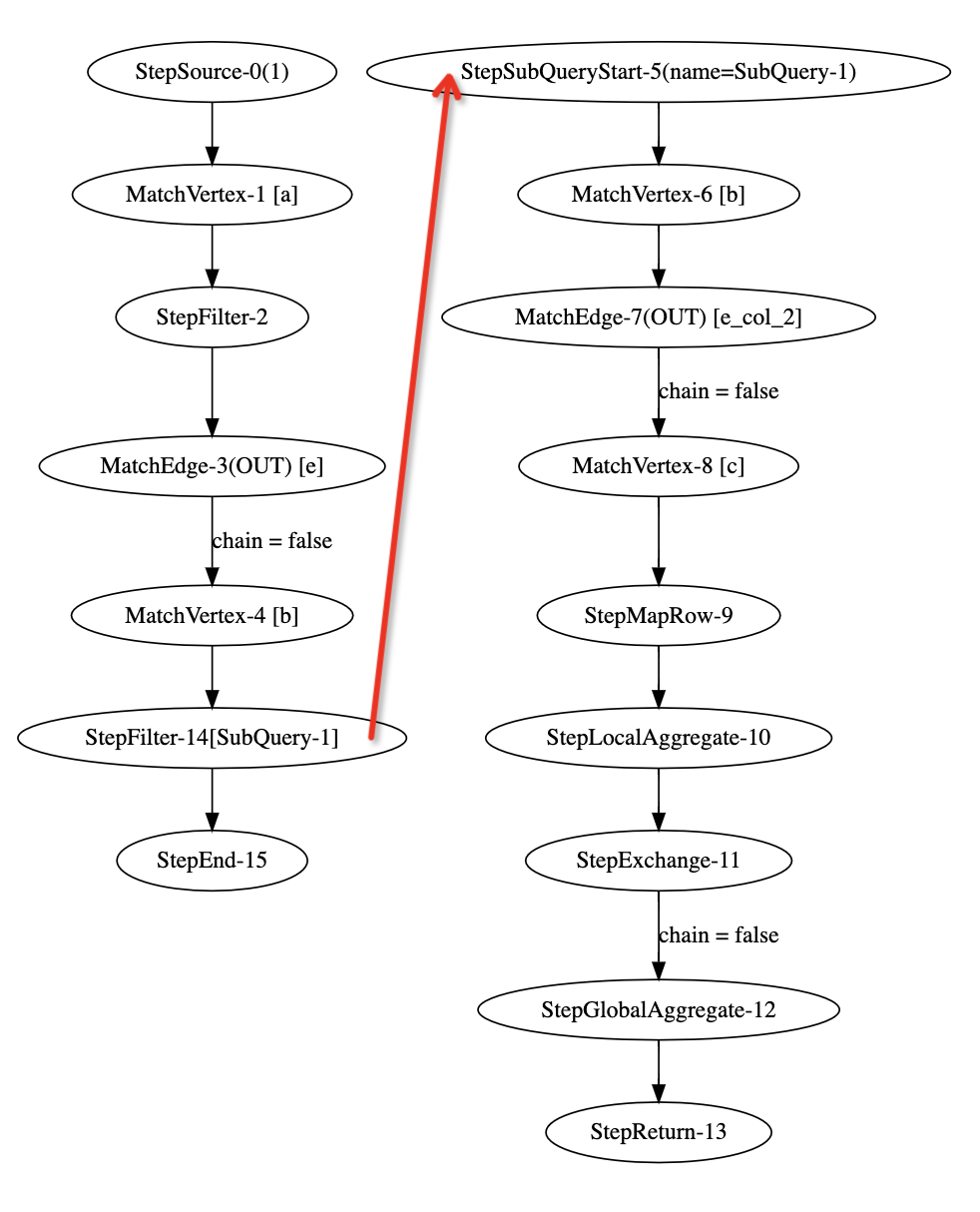
多么的复杂!我相信没有人愿意手工实现这个图算法的。
细心的同学不难发现,COUNT()算子被翻译为点上聚合步骤,且分为了局部聚合(步骤 10)和全局聚合(步骤 12)。这是分布式计算的考虑,如果在每个点上,把本地的结果计数,提前产生 COUNT 值的中间结果,再发送到全局加和,就能够降低通信和计算的开销。
循环
好了!我们已经学会了图计算执行计划的思路,让我们实现更多的查询吧。
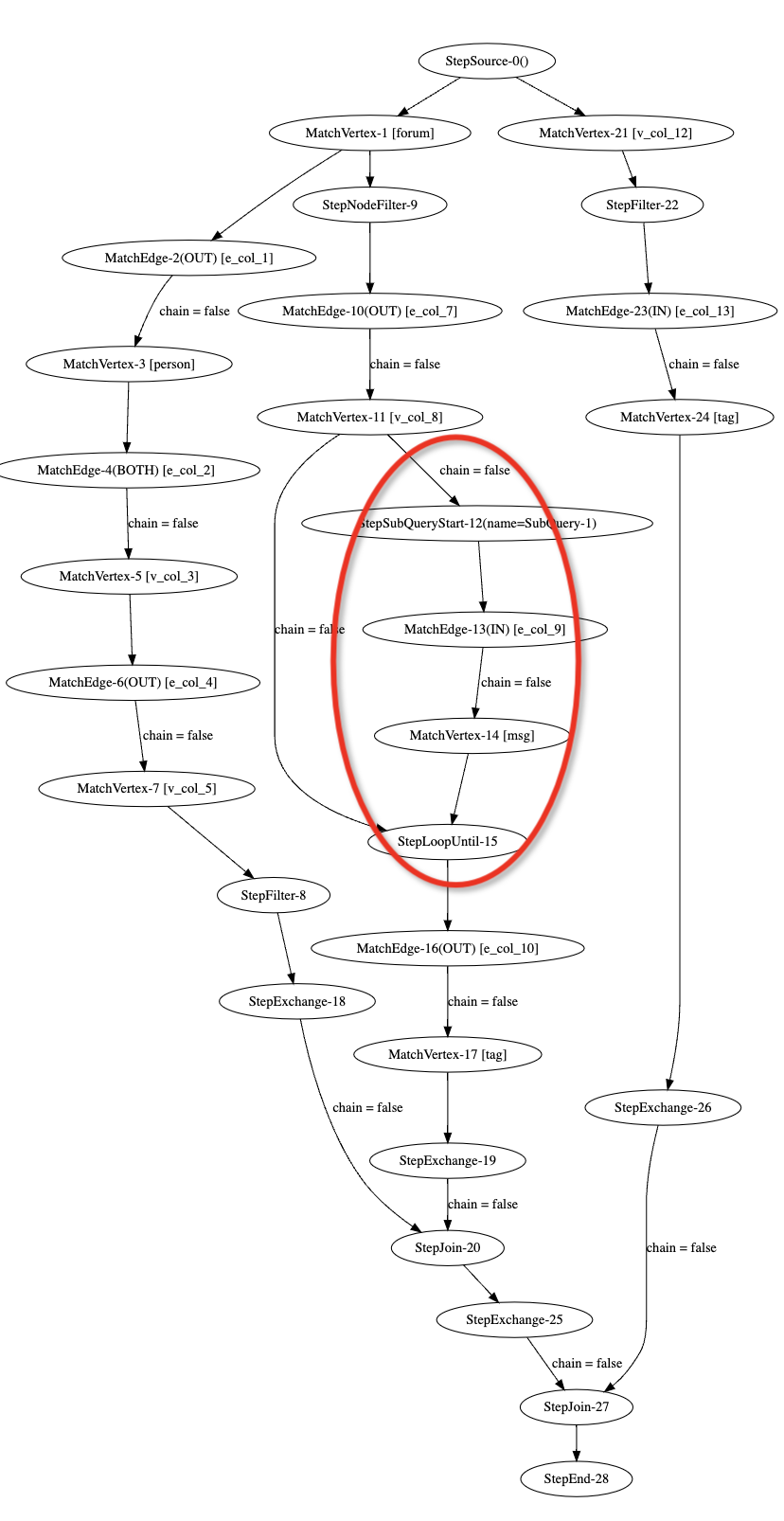
这个是社交分析的一个例子,来自 LDBC 测试集的 BI03 测试。
在该查询中我们处理了一个循环'<-[:replyOf]-{0,}',从而递归地获取博文 post 的所有回复。这对应着执行计划中的步骤 15 的 LoopUtil 算子。
全局标记
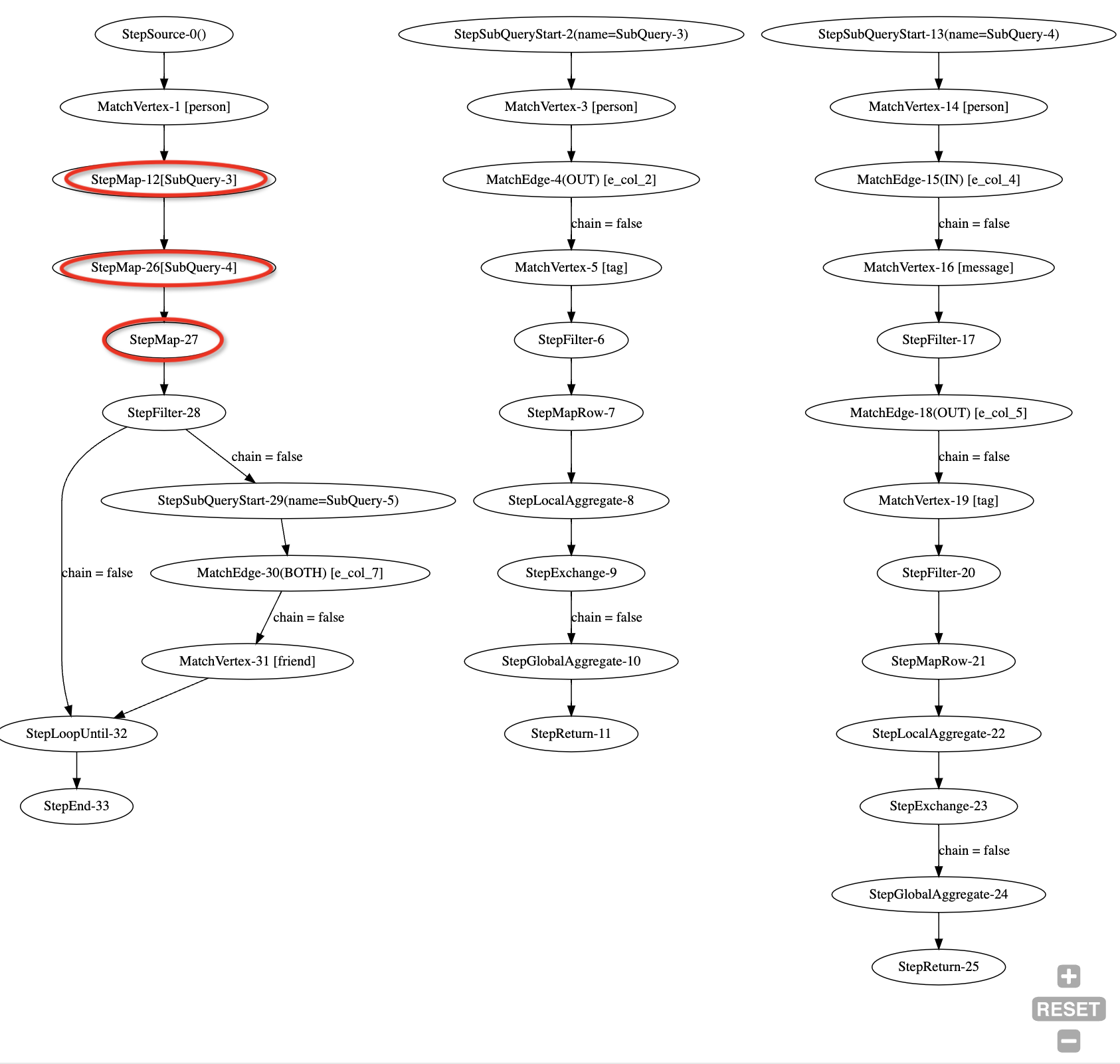
走图过程中,通过 LET 语句,可以将状态暂存在点上,以便在后续使用。例如以下查询,来自 LDBC BI08 测试,该测试中我们先计算每个人的分数,在 Person 类型点上进行标记,以便在走图到 firend 时取值使用。
这在执行计划中体现为 StepMap 步骤,三个 StepMap 步骤分别完成三个 LET 语句的功能。可以数一数,这个执行计划总共需要多少轮迭代呢?
总结
本文介绍了 GeaFlow 图计算引擎如何使用 GQL 图查询语言进行走图查询,并介绍了几类查询语句对应生成的图计算执行计划。
GeaFlow(品牌名 TuGraph-Analytics) 已正式开源,欢迎大家关注!!!
欢迎给我们 Star 哦!
Welcome to give us a Star!
GitHub👉https://github.com/TuGraph-family/tugraph-analytics
更多精彩内容,关注我们的博客 https://geaflow.github.io/

欢迎访问:geaflow.github.io 2023-07-05 加入
GeaFlow(品牌名TuGraph-Analytics) 是一个分布式流图计算引擎 欢迎给我们 Star 哦! GitHub👉github.com/TuGraph-family/tugraph-analytics 更多精彩内容,关注我们的博客geaflow.github.io









评论