
谈谈 JVM 垃圾回收机制
前言
垃圾回收需要思考三件事情,哪些内存需要回收?什么时候回收?如何回收?
一、哪些内存需要回收
JVM 的内存区域中,程序计数器、虚拟机栈和本地方法栈的生命周期是随线程而生,随线程而灭的。这几个区域的内存分配和回收都具有确定性,不需要过多考虑回收问题,当方法或线程结束时,内存自然就跟着回收了。
Java 堆和方法区是具有不确定性的,比如一个方法根据不同的条件执行可能需要的内存是不同的。只有处于运行期才能知道需要创建哪些对象,创建多少对象,这部分的内存分配和回收是动态的,垃圾回收所关注的就是这部分内存。
二、对象何时会“死亡”
Java 堆中存放了几乎所有的对象实例,垃圾回收器在进行回收前,需要判断哪些对象“存活”,哪些对象“死亡”,“死亡”的对象才会被回收。
1. 引用计数法
给对象中添加一个引用计数器:
每当有一个地方引用它,计数器就加 1;
当引用失效,计数器就减 1;
任何时候计数器为 0 的对象就是不可能再被使用的。
这个方法实现简单,效率高,但是目前主流的虚拟机中并没有选择这个算法来管理内存,其最主要的原因是它很难解决对象之间相互循环引用的问题。
2. 可达性分析算法
通过一系列被称为GC Roots的根对象作为起始节点集,从这些节点开始,通过引用关系向下搜寻,搜寻走过的路径称为“引用链”,如果某个对象到GC Roots没有任何“引用链”相连,就说明该对象不可达,即可以被回收。
如下图,Object 5、Object 6、Object 7 虽有关联,但是到GC Roots是不可达的,因此会被判定“死亡”。

Java 中固定可作为GC Root对象的有:
虚拟机栈的栈帧中的本地变量表中引用的对象,如,参数、局部变量、临时变量等。
方法区中类静态属性引用的对象,如,类中的静态变量。
方法区中常量引用的对象。
本地方法栈中 JNI(也就是native方法)引用的对象。
Java 虚拟机内部的引用,如基本数据类型对应的 Class 对象、常驻异常、系统类加载器等。
被同步锁持有的对象。
除了这些固定的还有一些临时性加入的,有兴趣的可以看下《深入理解 Java 虚拟机》。
上述两种方法都需要了解引用,详细介绍见Java引用。
3. 方法区的回收
不要求虚拟机在方法区进行垃圾回收,在 Java 堆中,尤其是在新生代中,常规进行一次垃圾收集通常可以回收 70%至 99%的内存空间,相比之下,在方法区进行回收的“性价比”较低。该区域的垃圾回收主要是两个部分,废弃的常量和不再使用的类。
3.1 废弃常量
假如在字符串常量池中曾存在字符串 "java",如果当前没有任何字符串对象引用该字符串常量的话,就说明常量 "java" 就是废弃常量,如果这时发生内存回收的话而且有必要的话,"java" 就会被系统清理出常量池了。
3.2 不再被使用的类
类需要同时满足下面 3 个条件才能算是 “不在被使用的类” :
该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
加载该类的 ClassLoader 已经被回收。
该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
三、垃圾回收算法
这里整理的均为“追踪式垃圾回收“,也成为”间接垃圾回收“。
1. 分代回收
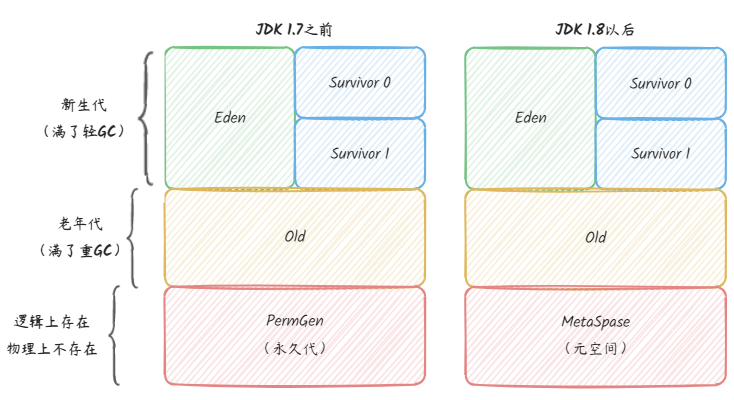
Java 堆的区域划分如下图,被分为新生代、老年代、永久代或元空间,具体划分为五大块区域,不同的 GC 会针对不同的区域进行垃圾回收。
GC 类型一般有以下几大类:

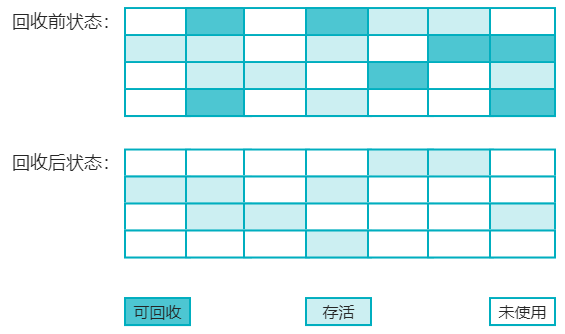
2. 标记-清除算法
最早出现的垃圾回收算法,分为“标记”、“清除”两个阶段。可以标记存活的对象,也可以标记要回收的对象。该算法有两个缺点:
是执行效率不稳定,随着对象的增多,标记效率会越来越低;
内存空间产生很多碎拼,浪费空间,分配大对象时可能需要重新触发垃圾回收。
标记-清除算法执行过程如下图:
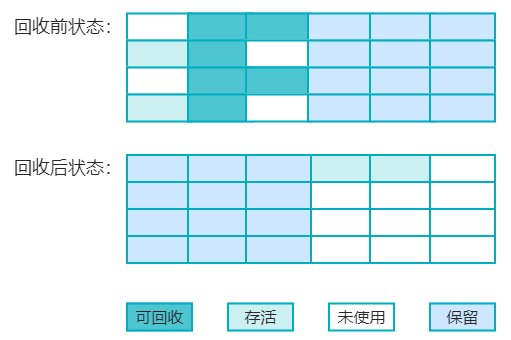
3. 标记-复制算法
简称复制算法,为了解决标记-清除算法面对大量可回收对象执行效率低的问题,就是将内存分成两个区域,每次只使用其中一个区域,当该区域内存满了之后,会将还存活的对象复制到另一个区域,然后将原区域直接清理掉。该算法有两个缺点:
对象存活率过多时,会影响复制的效率;
一半内存不使用,浪费了大量空间。
标记-复制算法执行过程如下图:
由于 Java 的新生代对象存活率不高,所以一般针对新生代的垃圾回收使用标记-复制算法。
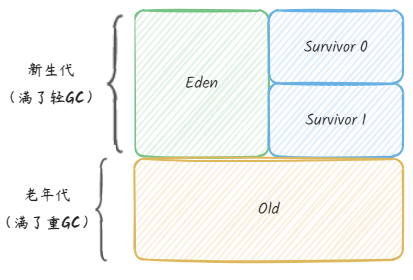
如下图,将新生代分为内存较大的Eden,和两块内存较小的Survivor。每次分配内存只使用Eden和其中一个Survivor,我们假设第一次分配内存是Eden、Survivor 0。
发生 GC 时,将使用的
Eden、Survivor 0中存活的对象一次性复制到Survivor 1中,然后清理掉Eden、Survivor 0内存。这时分配的内存就变成了
Eden、Survivor 1,周而复始。
注意:当Survivor不足以容纳轻 GC 之后的对象时,就需要依赖老年代来进行内存分配了。
4. 标记-整理算法
标记完存活对象以后,让所有存活对象都向内存空间的一端移动,然后在清理掉边界以外的内存。
标记-整理算法执行过程如下图:
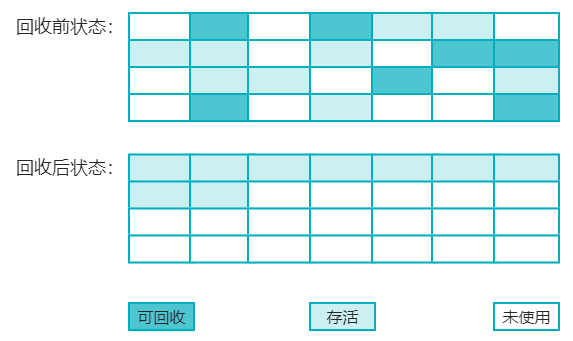
这种涉及到了对象的移动,如果移动存活对象,尤其是老年代这种每次回收都有大量对象存活的区域,会耗时很多,并且对象移动操作会全部暂停用户应用程序才能进行,这样会产生停顿时间。
这种停顿被称为
Stop The World。
5. 标记-清除-整理算法
先使用标记-清除算法进行垃圾回收,暂时容忍内存碎片的存在,直到碎片过多影响对象分配时,在进行标记-整理算法进行回收,获得规整空间。
四、经典垃圾收集器
下图展示了 7 种经典垃圾收集器,若两两出现互连情况,则表明两者它们可以搭配使用。
单线程收集器 Serial、Serial old
并行收集器 Par New、Parallel Scavenge、Parallel old
并发收集器 CMS、G1

1. Serial 收集器
最基本、历史最早的垃圾收集器了。单线程的收集器,收集垃圾时,必须暂停其他所有工作线程,也就是必有停顿,使用复制算法。
2. Par New 收集器
多线程并行版本的 Serial 收集器,收集垃圾时,必须暂停其他所有工作线程,也就是必有停顿,使用复制算法。
3. Parallel Scavenge 收集器
类似 Par New 收集器,但关注点是达到一个可控的吞叶量,使用复制算法。
吞吐量公式:

吞吐量示例:
代码运行 95 秒 , 垃圾收集器运行 5 秒 , 那么吞吐量就是 $\frac{95}{95 + 5} = 0.95$
4. Serial old 收集器
Serial 收集器的老年代版本,单线程收集器,使用标记-整理算法。它主要有两大用途:
在 JDK1.5 及以前的版本中与 Parallel Scavenge 收集器搭配使用;
作为 CMS 收集器的后备方案。
5. Parallel old 收集器
Parallel Scavenge 收集器的老年代版本。使用多线程和标记-整理算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器(JDK8 默认的新生代和老年代收集器)。
6. CMS 收集器
是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用,它是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
整个过程分为 5 个步骤:初始标记→并发标记→重新标记→并发清理→并发重置。
7. G1 收集器
基于标记整理算法实现,运作流程主要包括以下:初始标→并发标记→最终标记→筛选回收,不会产生空间碎片,可以精确地控制停顿,可以支持用户设置期望停顿时间。
不追求一次性将 Java 堆清理干净,只要垃圾收集的速度赶得上对象分配的速度即可。
文章转载自:fuxing.

还未添加个人签名 2023-06-19 加入
还未添加个人简介






评论