
Groq:从头设计一个张量流式处理器架构

来源|Groq
翻译|贾川、程浩源、胡燕君
作为一家由多位前 Google TPU 开发者组建的芯片公司,Groq 一经成立便备受关注。2016 年底,曾领导研发 Google 张量处理单元(TPU,用于加速机器学习而定制的芯片)的 Jonathon Ross 离职创办了 Groq,他们希望能为 AI 和 HPC 工作负载提供毫不妥协的低延迟和高性能。
不同于传统的 CPU 和 GPU 架构,Groq 从头设计了一个张量流处理器 (TSP) 架构, 以加速人工智能、机器学习和高性能计算中的复杂工作负载。这个架构不是开发小型可编程内核并对其进行数百次复制,而是容纳一个具有数百个功能单元的单个处理器。

Groq 的软件将深度学习模型编译成指令流,所有这些都是预编排的。他们用“软件定义硬件”的思路,将芯片中的控制和调度操作都交给软件完成,从而减少相应的硬件开销,压榨更多的性能。
目前,Groq 主要面向云端推理领域。2021 年 4 月,Groq 宣布获得 3 亿美元新融资,用于开拓自动驾驶和数据中心行业市场。
近期,Groq 首席架构师 Dennis Abts 完整介绍了 Grop 公司研发的软件定义横向扩展的张量流式多处理器(Tensor Streaming Processor,简称 TSP)架构,主要包括搭建 TSP 架构的背景及构成,并说明了 TSP 的工作负载性能。
1、TSP 的设计理念
Groq 将软件定义(software-defined)的方法引入到多处理器中软硬件接口的设置问题。具体来说,静态和动态(static-dynamic)界面来区分什么应该在编译时做,什么应该在运行时执行;软硬件接口由通过指令集架构(ISA, instruction set architecture )来实现,仅仅向编译器暴露必要的体系结构内部状态。

我们将更多的控制权交给软件,并将那些应该硬件做的事交给芯片,而对于能在软件中完成的事情,则更多的放在软件堆栈中去做(在软件堆栈中这些任务也能完成得更好)。

面向确定性的设计(designing for determinism )要求我们在设计时作出选择,并对该设计理念一以贯之。我们必须确保硬件可以完全由编译器来控制,这不是要抽象掉硬件的细节,而是要显式地控制底层硬件。并且编译器能够清楚地了解硬件在任何给定周期内的工作情况。
传统的系统和 CPU 通常采用乱序执行(out-of-order execution)和推测执行(speculative execution)等技术在内存层次结构中暴露出附加的指令级并行(instruction level parallelism)和内存并发性(memory concurrency)。
而 Groq 则采取了不同方式,只在一个 220 兆字节的 scratchpad 内存中显式分配 tensor,以便编译器知道 tensor 的位置以及它们如何在芯片上移动。编译器还可以利用大量的内存并发性,我们通过分区的全局地址空间来对此进行描述,并使其可以在整个系统中访问。

由于系统中的处理单元会达到数以万计(这些元素通常由异构组件组成,例如 CPU、GPU、SmartNICs、FPGAs,所有这些组件都具有不同的故障特征和性能概况),系统层面的复杂性通常也会不断增加。
结果,系统的性能会发生变化,同时响应时间也会延长,这些变化也会相应地降低其他互联网应用程序的运行速度,所有需要机器各部分协作完成的事情最终都会受到这种延时的影响。
因此,我们尽量避免在系统层面出现这种资源浪费和滥用行为,同时引入新技术来帮助平衡系统负载,而无需在网络层面使用自适应路由和其他激进技术。
2、TSP 微架构:软件定义硬件意味着什么
接下来让我们介绍微架构。首先是从传统的同构众核开始,每个核心都包含计算单元、整数单元、浮点单元、加载存储单元和网络接口。我们将这些功能单元分解并重新组织成 SIMD 功能单元,并将它们彼此相邻放置,便于控制并利用其空间局部性。这看起来与传统 CPU 有点不同,但执行方式却与传统 CPU 一样将较大的指令分解为微指令。同样,我们将深度学习操作分解为更小的微操作,并将它们作为一个整体执行,共同实现更大的目标。

因此,如果我们只看芯片架构,会发现芯片是按照空间方向(spatial orientation)排列的,功能单元彼此相邻布置。它们通过在彼此之间传递操作数和结果来相互协作,这种有效运作方式称作“链条化(chaining)”,可以将一个功能单元的输出链接到相邻下游功能单元的输入。

在芯片上的大型 MXM 模块是 TSP 架构的主力,该模块是矩阵单元,包含 409,600 个乘加器。换言之,我们可以通过芯片上的数据并行来利用大量权重参数,这使得我们能提供巨大的计算密度,每平方毫米硅面积超过 1 TeraOps。


现在往回看,来看看 GroqChip 的抽象构造。芯片上有多个不同的功能单元,这些单元组成了简单的构建块,长度为 320 个元素(本处所指的是 SIMD 单元),每个 SIMD 单元由指令调度单元(位于芯片底部)控制。

这些功能单元彼此相邻,正如软件的不同分类一样,这些不同的功能单元都有各自的用途,包括矩阵单元 MXM,用于逐点运算的 vector 单元,用于数据重塑的 SXM 单元(开关执行模块),以及一个用于处理片上存储的存储器单元。
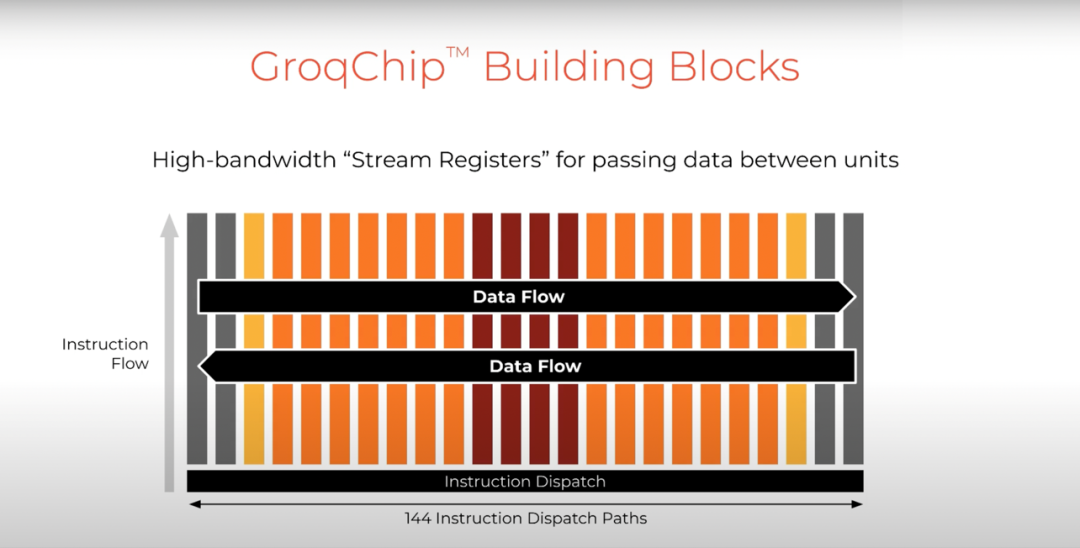
它们在布局上彼此相邻,以此来利用空间定向的优势。所以我们可以在芯片上采取东西向流式传输数据,充分利用其空间局部性。从某种意义上说,它正在捕获数据流的局部性,这在机器学习模型中很常见。
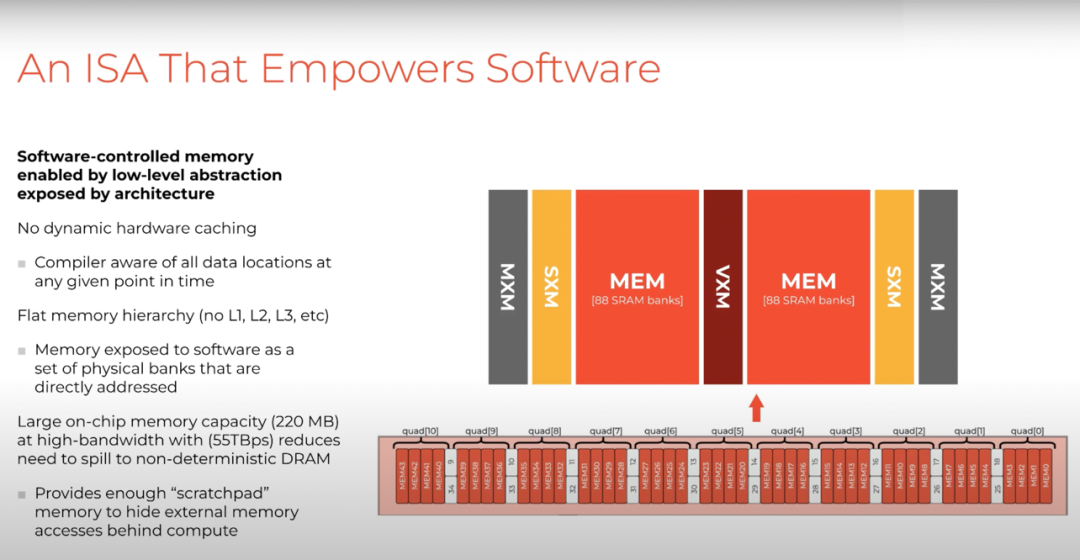
这种架构使得 ISA 能够赋能我们的软件堆栈。我们显式地将控制权移交给软件,特别是编译器,以便它可以从第一性原理的角度推断硬件上的正确性和调度指令。

具体来说,我们有 144 个片上指令控制单元,每个指令控制单元控制着与其相关联的功能单元的调度。这使我们能够将调度的硬件开销保持在非常低的水平,仅仅不到 3%的区域用于指令解码和调度,同时将大部分芯片区域用于执行功能模型。
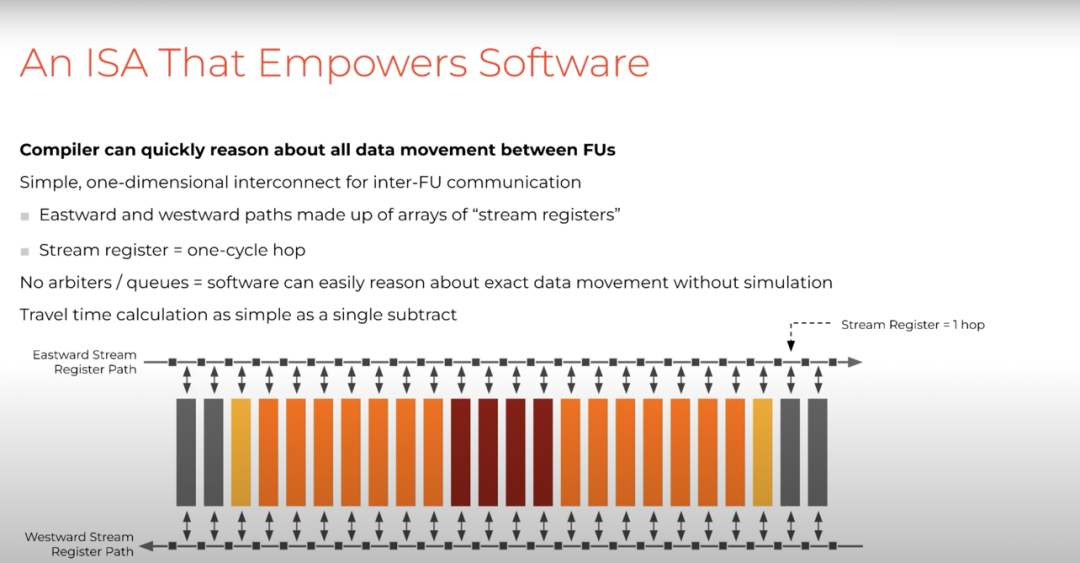
这使得编译器能非常简单地进行提取,即每个功能单元与一组流寄存器文件(SRF,stream register files)交互。通过 SRF 提供的管道(conduit),数据输入和数据结果被传送到其他功能单元。
可以把 SRF 看作是连接不同功能单元的 tensor 装配线,这些流寄存器是非常简单的模型,编译器可以推断每个流寄存器之间只有单周期跳(one-cycle hop)。在加载存储或网络引用中没有仲裁节点,没有提示,也没有重新排序。因此,编译器确实拥有预言性信息,以此推断其生成的每个程序的正确性。

该功能的核心是指令集,它是用于在机器学习模型上运行的特定领域指令集。具体来说,我们采用 conv.2d 之类的机器学习操作,并将它们分解为一组微指令,这些指令在每个不同功能单元的芯片上执行。它们协作产生更高级别的指令,如 conv.2d 或 max pooling 操作,并且根据每个功能单元将指令分解为不同的指令集。
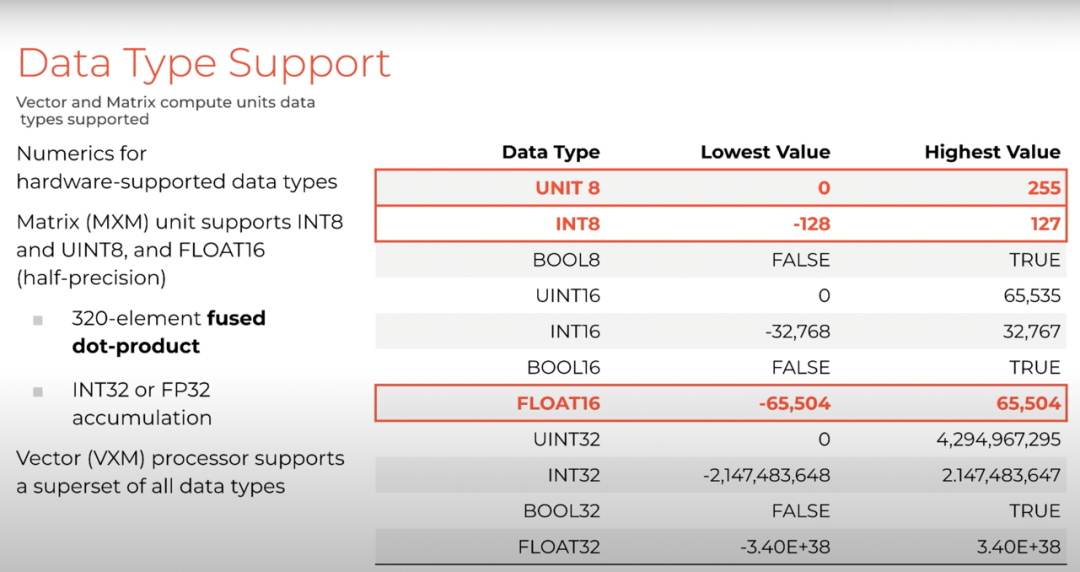
硬件本身支持的数据类型是 INT8、UINT8 以及 FLOAT16,处理逐点元素的向量处理器支持包括 FP32 在内的超集。

所以如果只看 TSP 的功能单元,每个功能单元都有一定数量必备指令,即取指、无操作(No-Op)和同步。这些是协调执行所必需的基本指令。

芯片的核心是矩阵乘法单元。矩阵引擎通过具有 320 个元素的向量进行操作,每个矩阵中有 320 个特征,提供 320x320 整数运算。对于浮点运算,我们可以做 320x160,可以同时处理整数和浮点数。浮点有点独特,因为一对字节平面(byte planes)协作产生一个 FP16 的输出。

芯片的中间是矢量执行模块(VXM,vector execution module),它是机器学习模型中常见的向量逐点运算,例如 GELU 或 ReLU,并且向量单元中存在其他超越函数(transcendental functions)以利用逐点操作。

每个矢量通道支持 16 个 ALU(网络算术逻辑单元,Arithmetic Logic Unit),并且通过内存功能单元(memory functional unit)连接到在 SRAM(静态随机存取存储器,Static Random-Access Memory)中的片上内存。内存功能单元在芯片上有 88 个切片,每个切片每次可读取一次。所以原则上内存系统最多支持 176 路并发执行,这是大量可利用的内存并发。

最后,SXM(switch execution module)是一个开关执行模块。SXM 就像是一把瑞士军刀,来处理数据操作、数据重塑、片上数据搬运和片外数据搬运。如上图所示,C2C IO、PCIE 也由这个 SXM 单元处理。
3、系统概览:封装、拓扑、路由和流控

接下来如何将这些组件封装,进而组建成一个系统?首先是将 GroqChip 与散热器封装在一张卡上,然后将八张这种卡集合成一个 GroqNode,最后再将八个 GroqNode 加一个备用包打包到一个 GroqRack 中,并使其在云端也可访问。
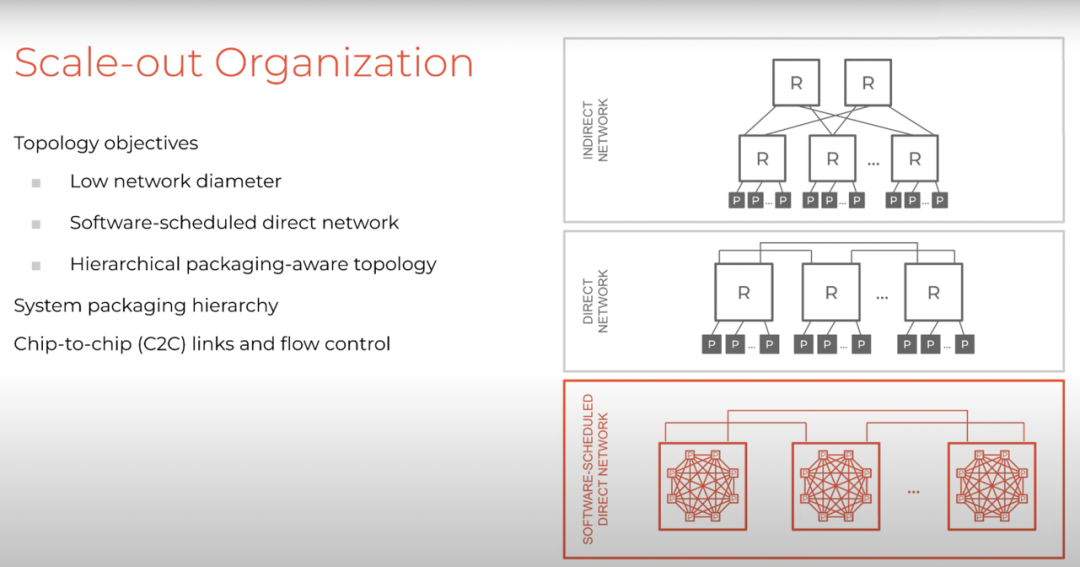
这种横向扩展排列方式非常独特。第一,它利用封装层次来制作低直径网络,这利用了蜻蜓拓扑(dragonfly topology),而蜻蜓拓扑又利用了封装局部性(packaging locality)。它创建了所谓的软件调度的直连网络(software-scheduled direct network),支持每个 TSP 上的 16 个直接相连的芯片到芯片链路进行通信。

横向扩展组织利用较小的网络直径将多达 8 个芯片打包到一个节点中,这 8 个芯片使用 28 根电线连接到它们的 7 个中转点,这些电线被放置在每个节点底层,使我们能够丰富地连接单个节点内的 8 个 TSP,以再次利用封装的局部性。这些节点使用电线连接,较长的电线将在机架到机架网络(rack-to-rack network)之间使用光缆。

蜻蜓拓扑是分层拓扑。它首先通过识别这 8 个 TSP 构建成一个组,每个 TSP 都公开四个全局端口,所以 8×4 是 32 个端口。这 32 个虚拟端口用于连接全局系统,使能够连接多达 30 到 32 个单个系统中共计 264 个 TSP 的对等节点。
我们可以实现这个想法,并将这个机架作为本地组,如此一来,我们将能够在系统中连接多达 145 个机架,从而实现超过 10000 TSP 的总可扩展性。
Groq 的横向扩展拓扑使用蜻蜓拓扑来完全连接机架内的八个全局节点集,如下图所示。
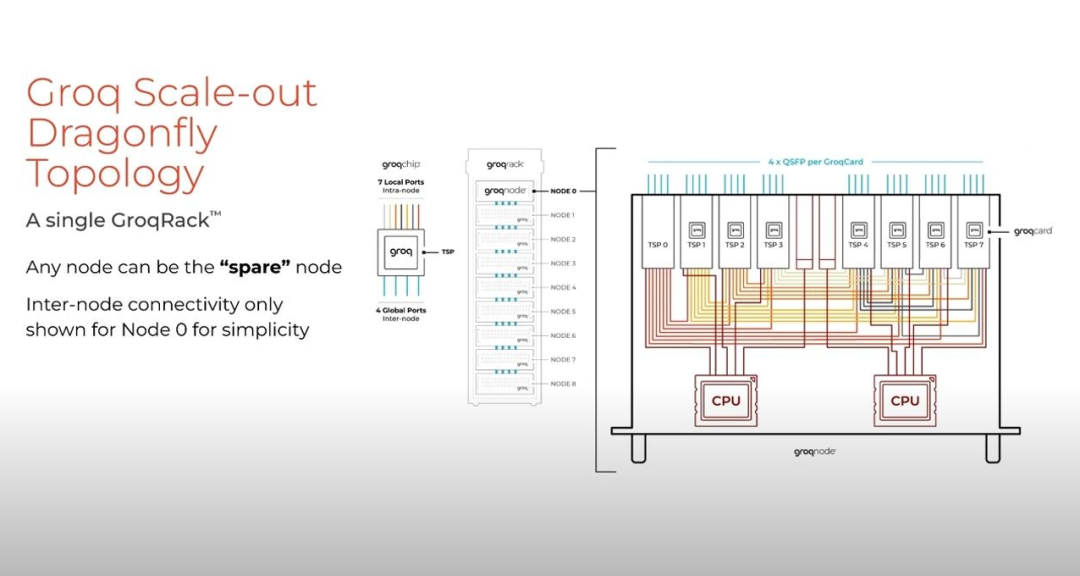
该结构提供了一个备用节点作为热备用(hot spare),并利用网络的边缘和节点对称性来提供 n+1 冗余,由此提高系统弹性。
4、全局同步网络
这个系统组织的核心是全局同步网络。当然,目前这个网络并不是真正同步的,因为系统中的每个节点都还没有统一的全局时钟。我们提供了同步行为的假象,还特别使用了一系列硬件和软件技术、硬件对齐计数器和软件对齐计数器,帮助检测何时发生漂移并补偿漂移。
全局同步网络由多同步链路组成,这意味着它们大部分是同步的,在驱动每个链接的时钟晶体的容差范围内是同步的。正是对于这一点的利用,使得我们能够检测到漂移何时发生,并通过硬件和软件技术对其进行补偿。

再次强调,在这个部分必须启用 ISA 支持,以便能够对这些芯片间的链接进行纠偏(我们有特定的指令支持纠偏)。
此外,这些链接不是硬件流控制,而是软件流控制。软件控制链接的运行节奏,以确保它们永远不会溢出或下溢。该链接的核心是前向纠错,这样就可以在每个网络链路上都有一个固定的延迟,让编译器能够推断出需要消息传递的时间。

从概念上讲,这些计数器在机器刚复位时相互独立,然后将它们放入锁步(lock step),可能会随着时间的推移略有漂移,但我们会消除偏移并将它们重新放入锁步。这就是我们如何在分布式系统中保持同步行为的方法。

不同于传统网络依赖硬件判优机制来动态竞争一组输出端口,我们让编译器可以调度所有物理网络端口,使它可以像调度 ALU 或矩阵一样调度网络链接。传统方法只会对网络中的拥塞做出反应,而不是对拥塞做出反应后进行自适应路由,以试图改善因竞争而导致的热点(hot spots)问题。
相反,我们的首要原则是完全避免竞争,并将流量模式分散到网络上的可用路径多样性中,以显现和利用额外的对分带宽。

我们将 tensor 视为消息,换句话说,我们将 tensor 作为数据包进行路由,这些连续的向量流在时间上背对背出现,形成一个 tensor。这使我们能将消息构建为向量序列,能够非常有效地在网络上对消息进行编码,而编码开销仅为 2.5%。
5、确定性的负载平衡
同时,利用最小和非最小路由是我们这个想法的核心。系统中的每个 TSP 在每个源目标对之间都有一个最小路径,但是也有很多非最小路径。在这种情况下,编译器可以查看张量的大小,并决定在其上传播多少条路径,以最大限度地减少在网络传输时的序列化延迟。
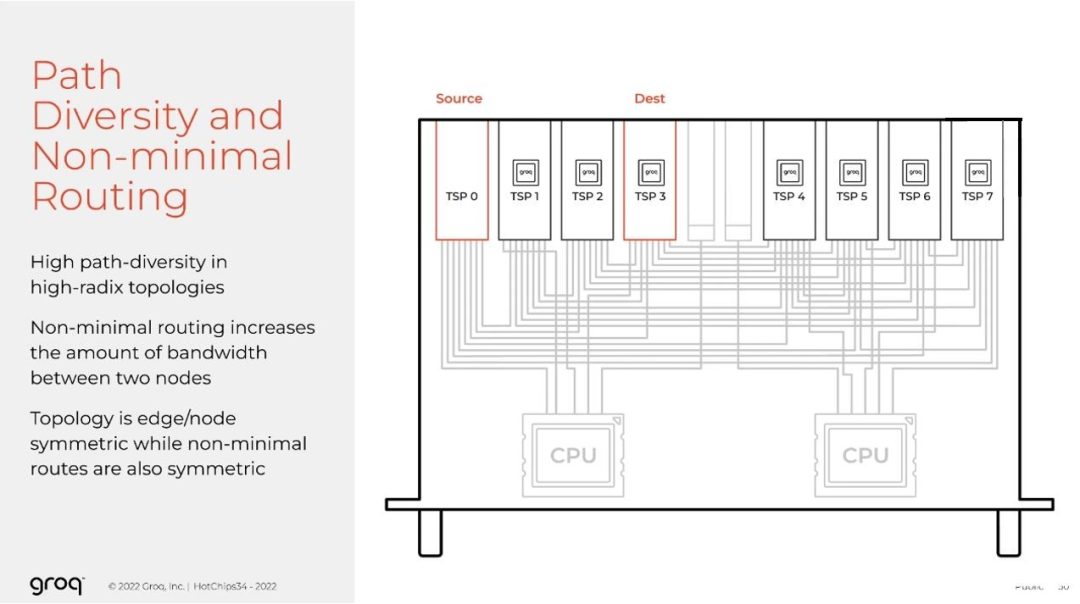
这使我们能够进行所谓的确定性负载平衡,而不必使用更传统的自适应路由方法去适应或响应网络中的拥塞。传统的方法有其自身的问题,因为只能看到一小部分网络,只能查看输出端口的拥塞状态,这可能导致做出错误的决定,选择一条可能比目前路径更拥挤的糟糕路径。
我们的方法做出了更好的权衡,它允许编译器对所有物理链路进行负载平衡,就像我们对芯片上的任何其他功能单元进行负载平衡一样。

Groq 芯片间链路的核心是简化的通信协议和流量控制。流量控制是由软件明确驱动的,没有硬件流量控制,所以软件必须确保它们不会溢出或下溢,我们设计的就是保证确定性成为首要原则,这也是设计的基石。
如果看一下传统的 RDMA 类型的请求,我们向目标发出读取请求,并且该读取将造成内存事务(memory transaction),然后将这个回复回流到网络,以便以后使用。
更简单的方法是让编译器知道正在读取的地址,并且数据只在需要时通过网络推送,以便在源头使用。这使得我们能够以更少的网络消息和更少的开销来实现更高效的网络传输。
6、可靠性
我们在整个系统中利用了 TSP 和网络内的冗余。例如制造良率的问题,芯片实际上是由 21 条超级通道构成的,而我们只使用了 20 条,因此可以允许出现一条无效的超级通道。这意味着我们可以在编译器中隐藏备用的超级链接,实际上也确实将硬件细节隐藏在其中。
这使我们能够使用一个全优的芯片,其能够包容目前领域可能存在的一些缺陷。
此外,每个架构内的冗余电源和冗余节点提供了额外的冗余。不仅如此,确定性还简化和改进了 ASIC 的设计过程,设计和验证可以通过硬件和软件需要确保的一些假设来表达,并保证硬件和软件需要确保彼此进行验证。例如,硬件制造的任何保证需要作为软件假设进行验证。

软件堆栈对可靠性和冗余性起着重要作用,特别是在运行时层面处理异常处理时。这就是为什么所有链路都需要前向纠错,如果遇到错误,则需要软件重演(software replay),并且通过运行时处理。
为了保护所有片上数据结构,我们使用单纠错和双检测(SECDED)来保护所有数据路径、所有流寄存器、所有指令缓冲区和芯片上的指令提示。我们称这种方法为无处不在的 ECC。

既然开销很容易计算,那么我们可以利用这一点。在这个问题上偏执一点是值得的,因为确实有过无记载数据损坏,我的谷歌前同事在他们的论文《cores that don't count(不算数的内核)》中声明了这一点。重要的是,我们要成为客户数据的好管家。
因此,我们需要保护所有关键的硬件结构,在这个图中,每一个被编号的灰色框都是流寄存器,SECDED 保护着它们的安全,当张量在芯片流动时,我们可以对它再次保护。
此外,我们希望提供异常处理来避免常见问题,例如算术异常,算术溢出或下溢,可以通过提前决定异常语义来处理先验,例如编译器可以通过使用饱和指令来避免任何算术溢出,比如加减饱和或乘以饱和。这让我们可以避免值溢出,并将溢出位精度精确到一个很小的值。

7、负载评估
因此,如果查看我们独特的工作负载,会发现它们往往都与线性代数有关,因为这是机器学习以及许多 HPC 代码的主力。举个例子,看一下乔里斯基分解(Cholesky Factorization),它使用块循环将这个三角形元素扩展到多个芯片。
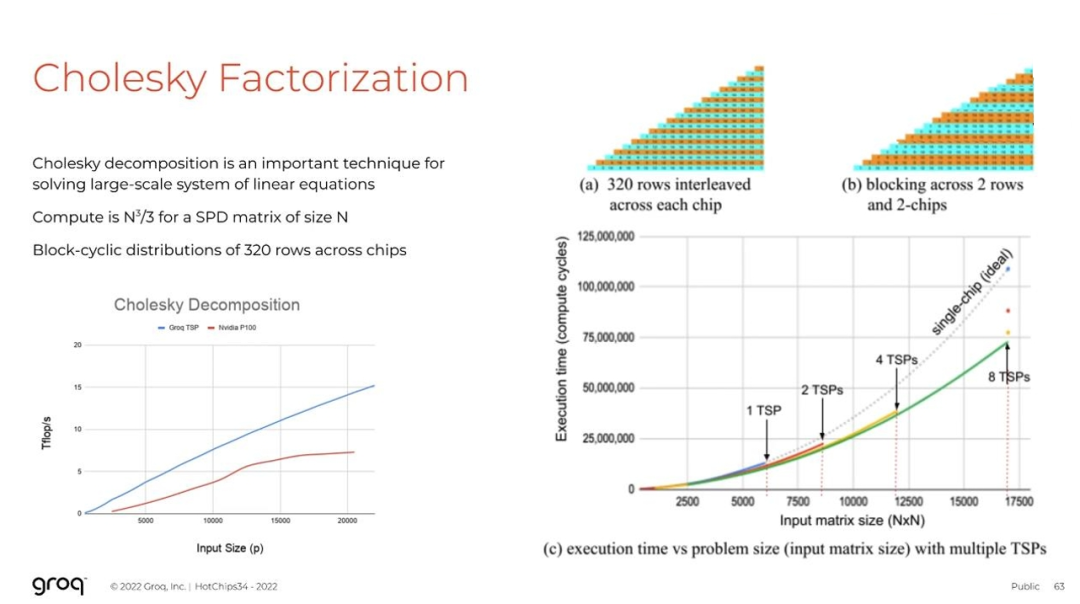
我们在 TSP 上实现了 BERT 和 BERT Large 的最先进的结果,并展示了如何真正有效地完成一般矩阵乘法。最后,当我们准备进行通信时,就能体会到所有上述优点,即使我们的引脚带宽比竞品芯片少,也能够更好地利用该引脚带宽,并采取细粒度通信的优势,换句话说,小张量在这个网络上可以非常有效。
8、总结
简单总结一下。首先,所有这些内容都是为了使编译器更高效且更轻量级,从编译器取得的快速进展就可以看出,我们已经能够更广泛地编译各种不同类型操作的模型。因此,从更广泛的角度来看,我们试图实现的是可预测和可重复性的性能,以在整个系统中提供低延迟和高吞吐量,以及支持软件定义的硬件方法。

我们不是要通过抽象去掉细节,而是要控制底层的硬件。我们希望公开一组正确的架构可见状态,将其交给编译器,它可以从第一性原理推断正确性,使软件和异常处理分别在编译时和运行时处理。
最后,我们启用了同步通信模型,该模型使得在非常大的系统中进行无锁通信,这是我们希望能够帮助到你的超级力量。
(原视频:https://www.youtube.com/watch?v=xTT2GpdSRKs)
其他人都在看
欢迎下载体验 OneFlow v0.8.0 最新版本:https://github.com/Oneflow-Inc/oneflow/
版权声明: 本文为 InfoQ 作者【OneFlow】的原创文章。
原文链接:【http://xie.infoq.cn/article/1bf3fe3631f5c39c786f7cd7c】。文章转载请联系作者。

不至于成为世界上最快的深度学习框架。 2022.03.23 加入
★ OneFlow深度学习框架:github.com/Oneflow-Inc/oneflow ★ OF云平台:oneflow.cloud









评论