1.动手模拟出频繁 Young GC 的场景
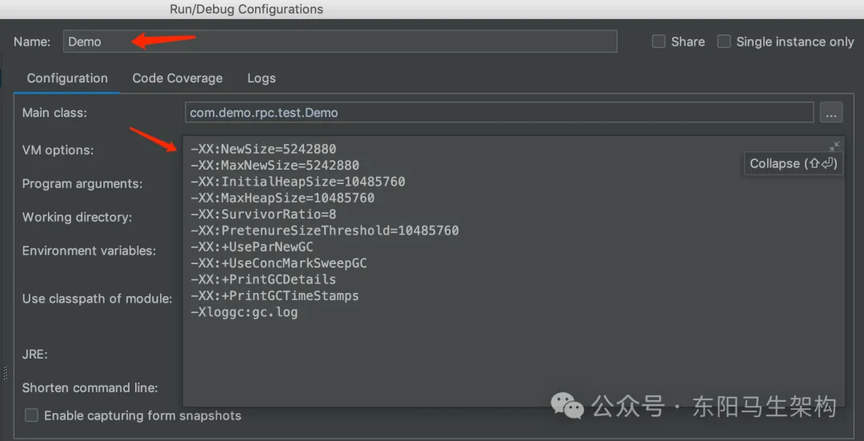
(1)程序的 JVM 参数示范
平时我们系统运行创建的对象,通常都优先分配在新生代中的 Eden 区。除非是大对象,大对象会直接进入老年代或者大对象专属 Region 区域。新生代有两块 S 区,默认 Eden 区占新生代 80%,每块 S 区占新生代 10%。比如用以下 JVM 参数来运行代码:
-XX:NewSize=5242880 -XX:MaxNewSize=5242880 -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10485760 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
复制代码
上述参数都是基于 JDK 1.8 来设置的,不同的 JDK 版本对应的参数名称不太一样,但基本意思类似。
-XX:InitialHeapSize和-XX:MaxHeapSize就是初始堆大小和最大堆大小; -XX:NewSize和-XX:MaxNewSize是初始新生代大小和最大新生代大小; -XX:PretenureSizeThreshold=10485760指定了大对象阈值是10M;
复制代码
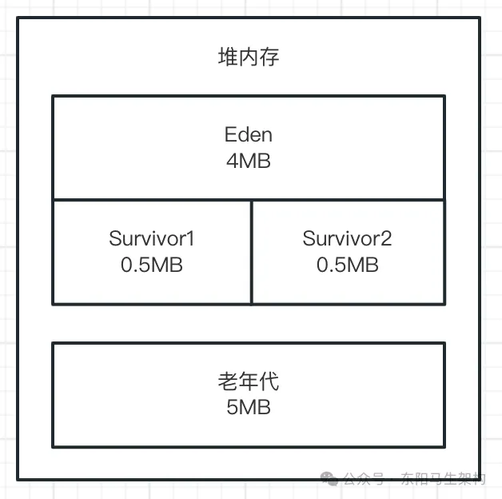
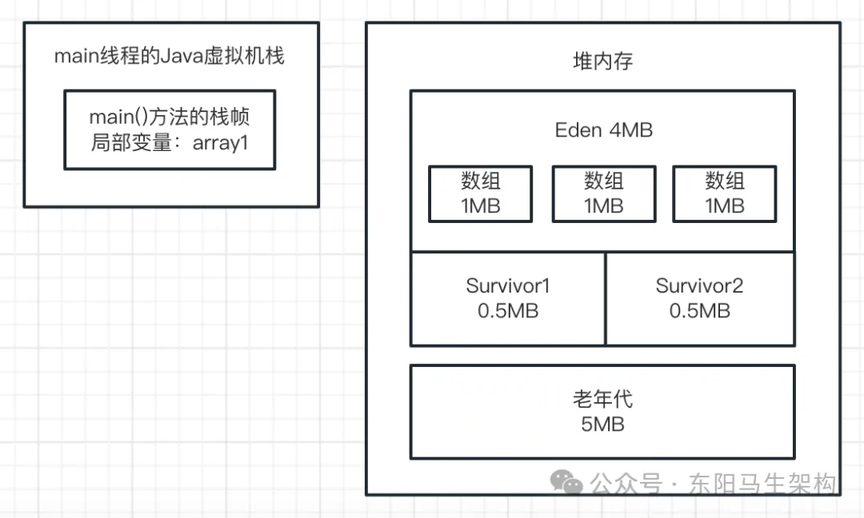
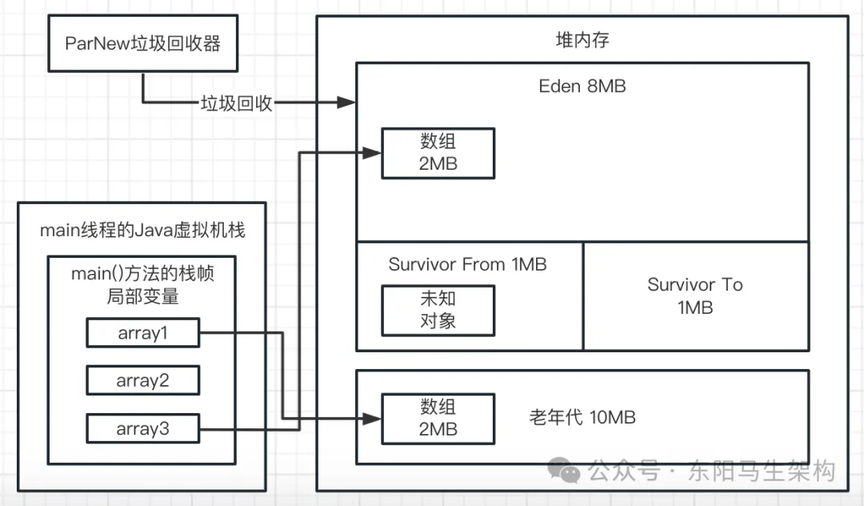
上面的 JVM 参数,相当于是给堆内存分配 10M 内存空间。其中新生代是 5M 内存空间,Eden 区占 4M,每个 Survivor 区占 0.5M。大对象必须超过 10M 才会直接进入老年代,年轻代使用 ParNew 垃圾回收器,老年代使用 CMS 垃圾回收器。如下图示:
(2)如何打印出 JVM GC 日志
接着需要在系统的 JVM 参数中加入 GC 日志的打印选型,如下所示:
-XX:+PrintGCDetils:打印详细的GC日志;-XX:+PrintGCTimeStamps:这个参数可以打印出每次GC发生的时间;-Xloggc:gc.log:这个参数可以设置将GC日志写入一个磁盘文件;
复制代码
加上打印 GC 日志参数后,JVM 参数如下所示:
-XX:NewSize=5242880 -XX:MaxNewSize=5242880 -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:SurvivorRatio=8 -XX:PretenureSizeThreshold=10485760 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
复制代码
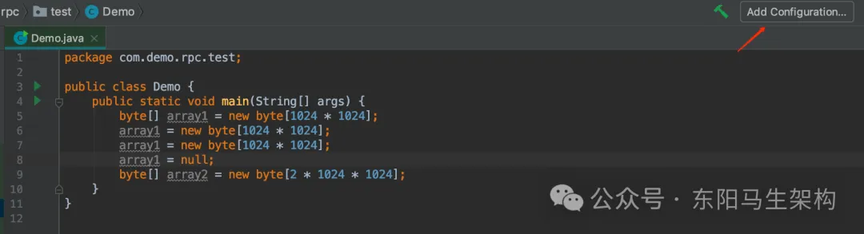
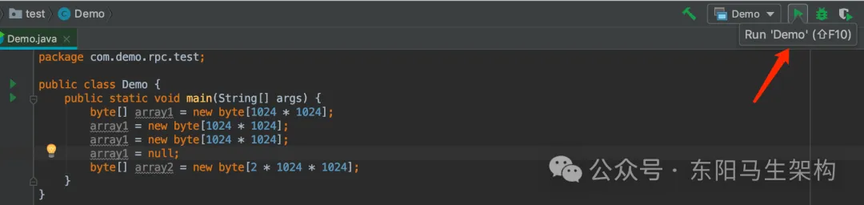
(3)示例程序代码
public class Demo1 { public static void main(String[] args) { byte[] array1 = new byte[1024 * 1024]; array1 = new byte[1024 * 1024]; array1 = new byte[1024 * 1024]; array1 = null; byte[] array2 = new byte[2 * 1024 * 1024]; }}
复制代码
(4)对象是如何分配在 Eden 区内的
上述代码先通过 new byte[1024 * 1024]连续分配 3 个数组,每个数组 1M;然后通过 array1 这个局部变量依次引用这三个对象;最后还把 array1 这个局部变量指向了 null。
那么在 JVM 中上述代码是如何运行的呢?
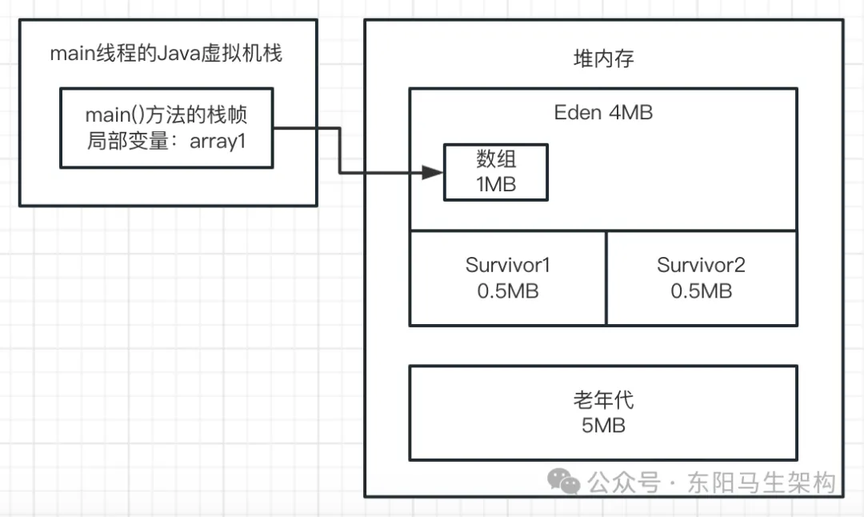
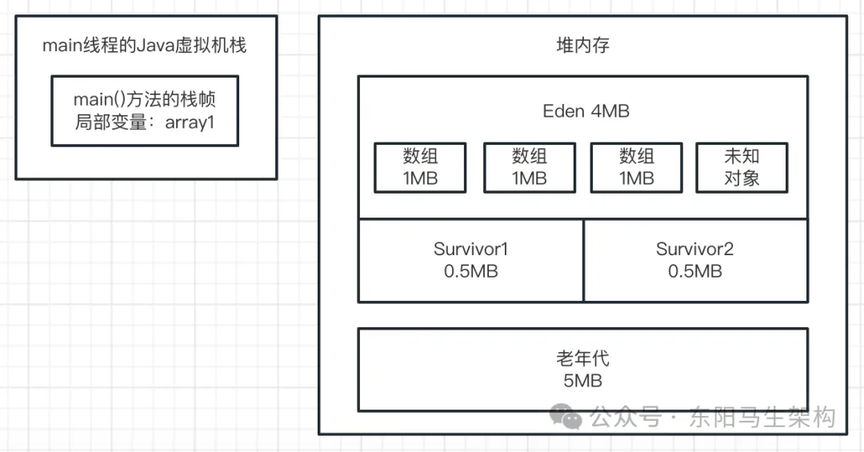
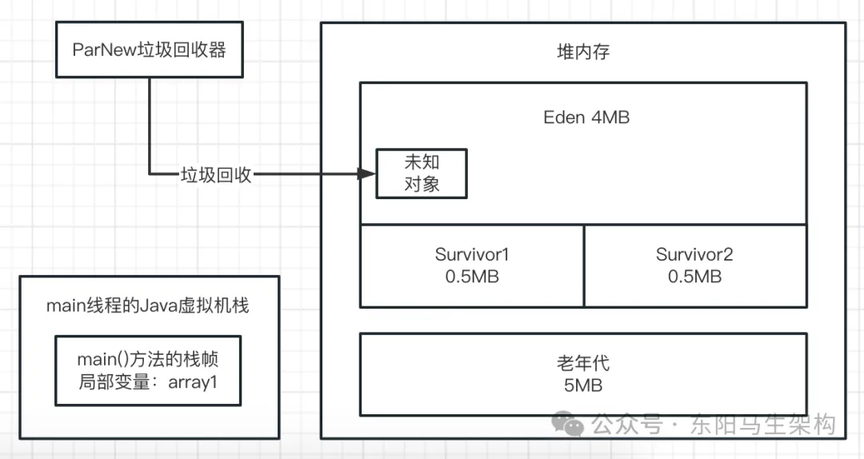
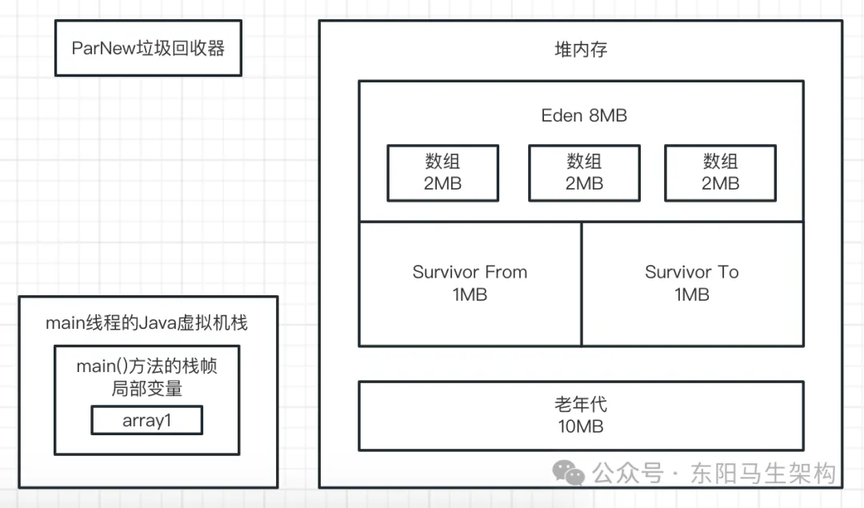
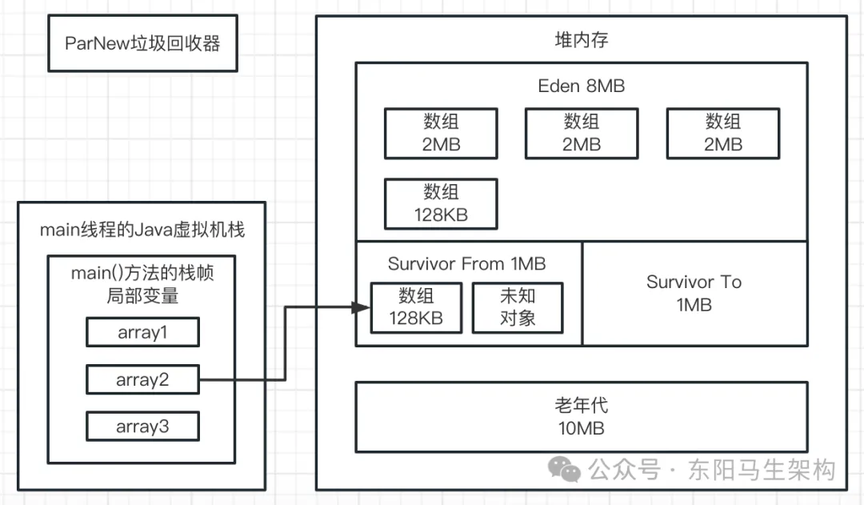
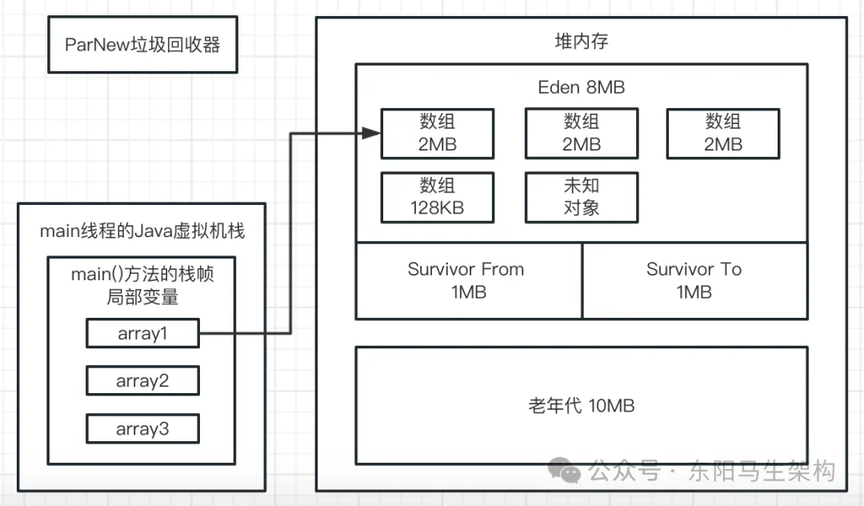
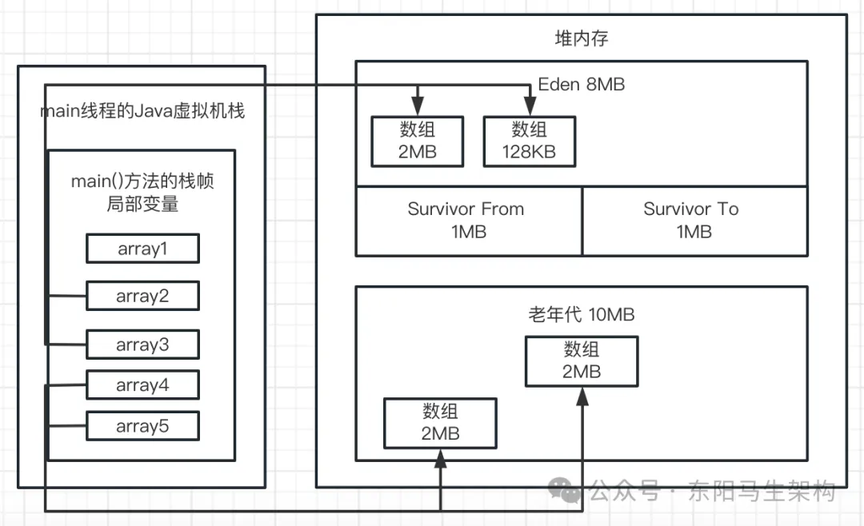
一.首先来看第一行代码:byte[] array1 = new byte[1024 * 1024];
这行代码一旦运行,就会在 JVM 的 Eden 区内放入一个 1M 的对象,同时在 main 线程的虚拟机栈中会压入一个 main()方法的栈帧。在 main()方法的栈帧内部,会有一个名为 array1 的局部变量。这个 array1 局部变量指向了堆内存 Eden 区的那个 1M 的数组,如下图示:
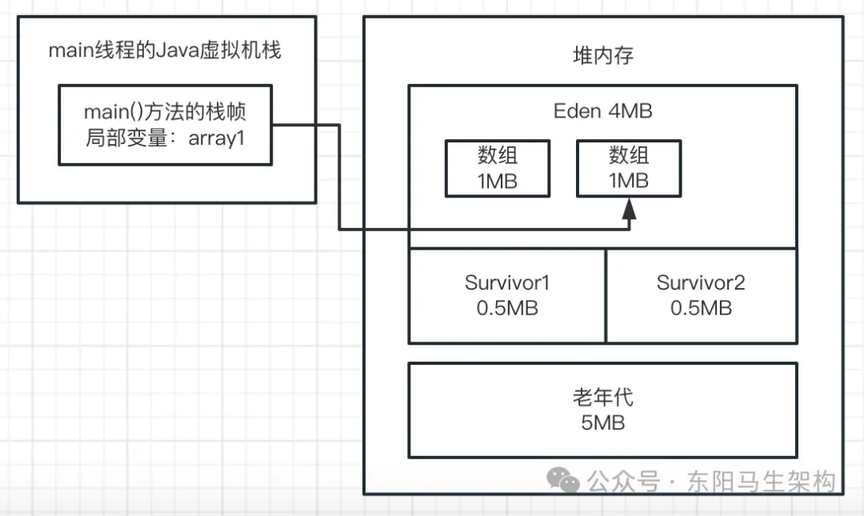
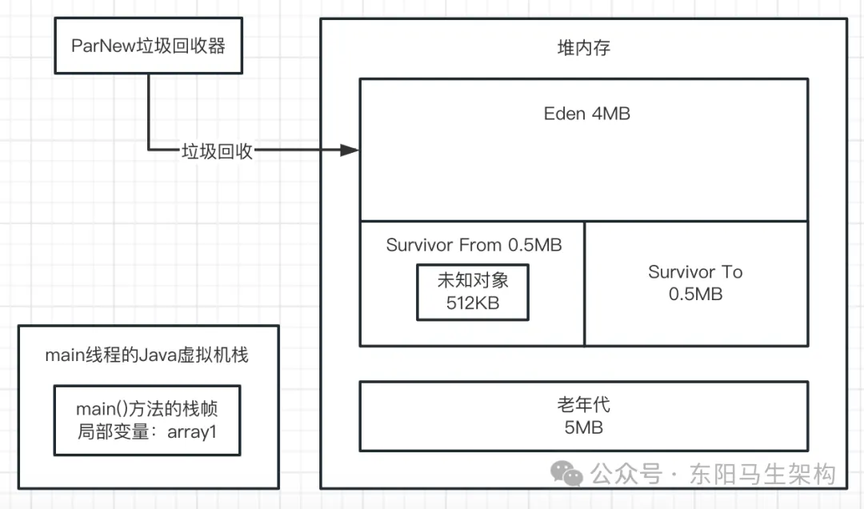
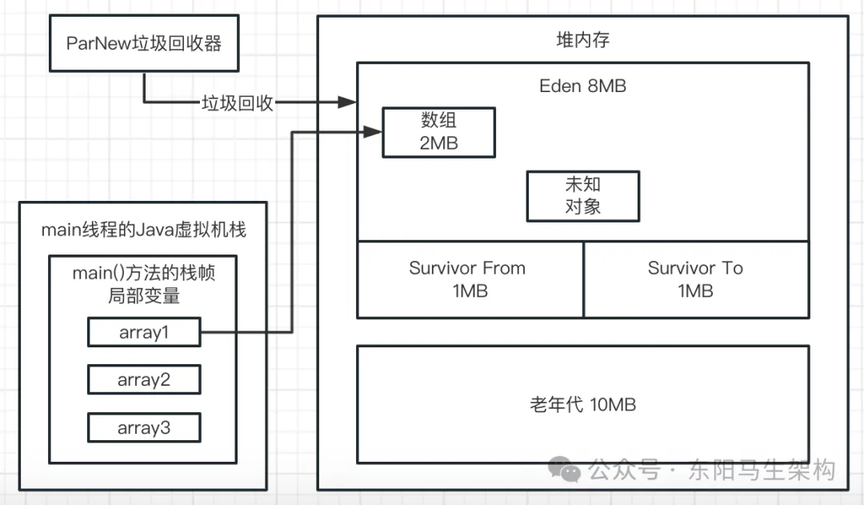
二.接着看第二行代码:array1 = new byte[1024 * 1024];
这行代码会在 Eden 区创建第二个数组,并让 array1 变量指向第二个数组。然后第一个数组就没被引用了,成了垃圾对象。如下图示:
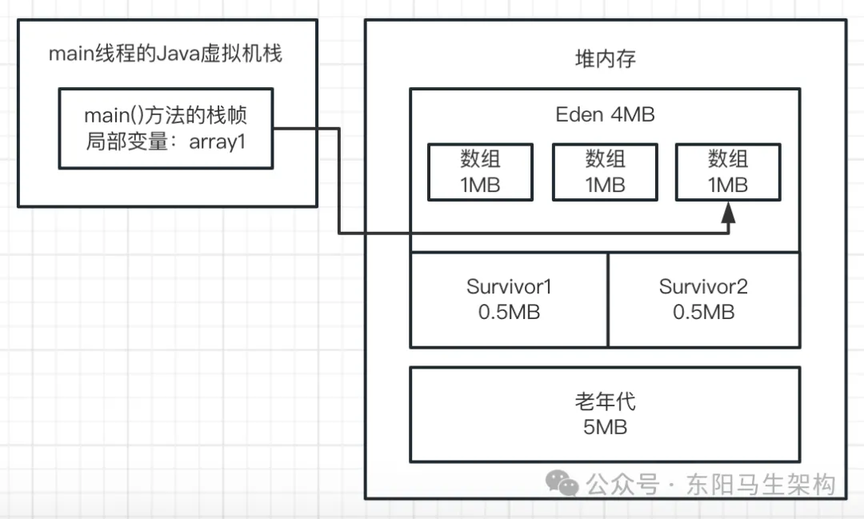
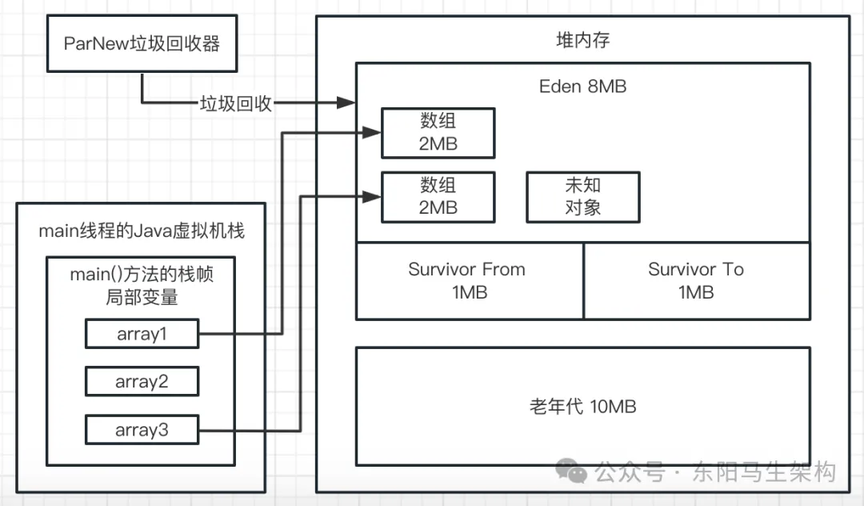
三.然后看第三行代码:array1 = new byte[1024 * 1024];
这行代码会在 Eden 区创建第三个数组,并让 array1 变量指向第三个数组。此时前面两个数组都没有被引用了,都成了垃圾对象,如下图示:
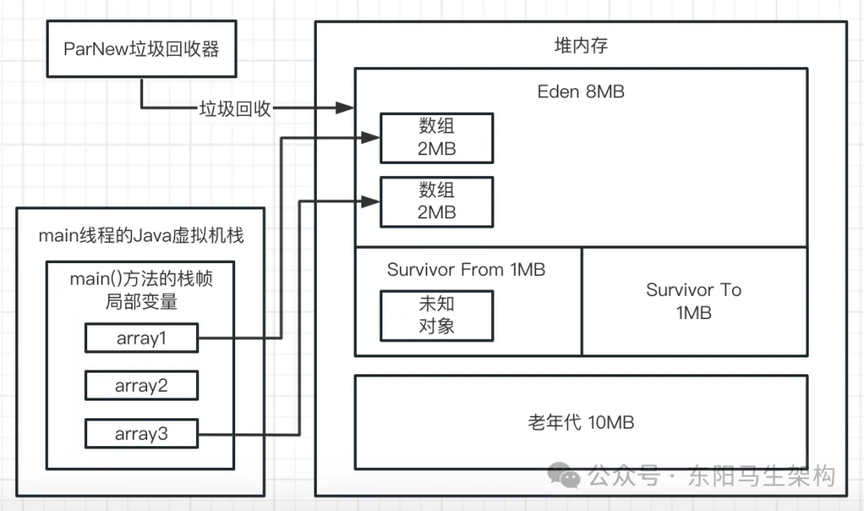
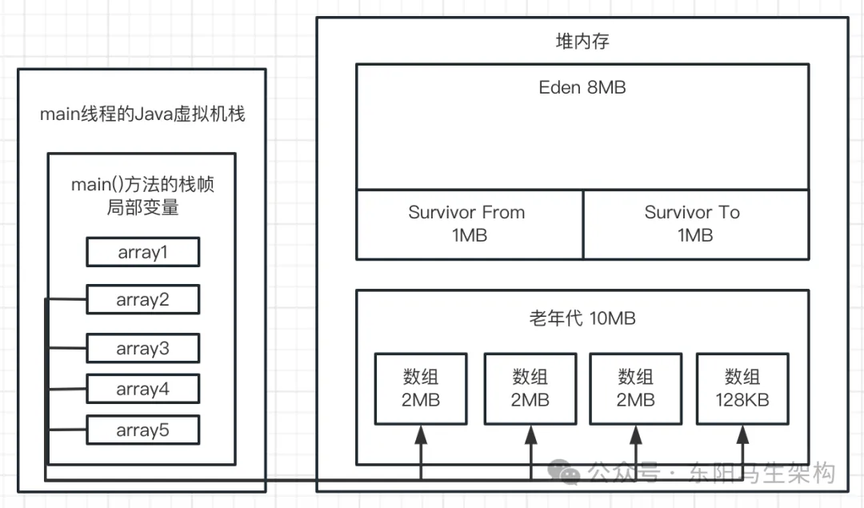
四.接着看第四行代码:array1 = null;
这行代码一执行,就会让 array1 局部变量什么都不指向了,此时会导致之前创建的 3 个数组全部变成垃圾对象。如下图示:
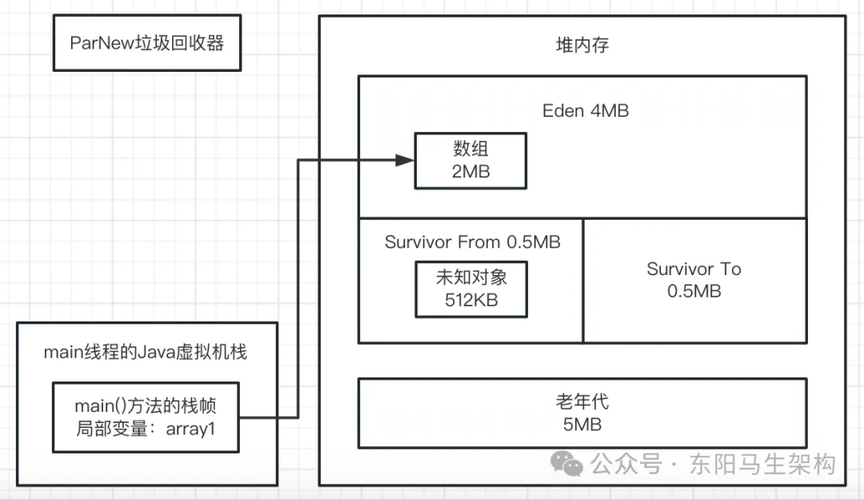
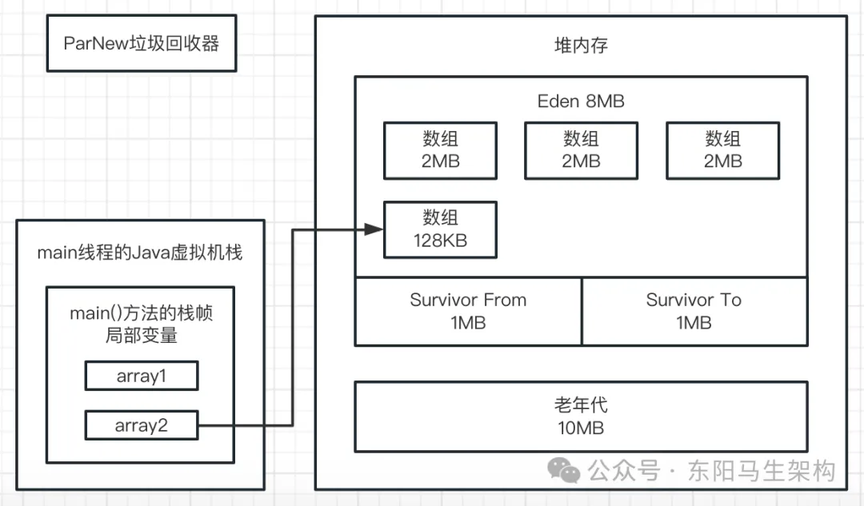
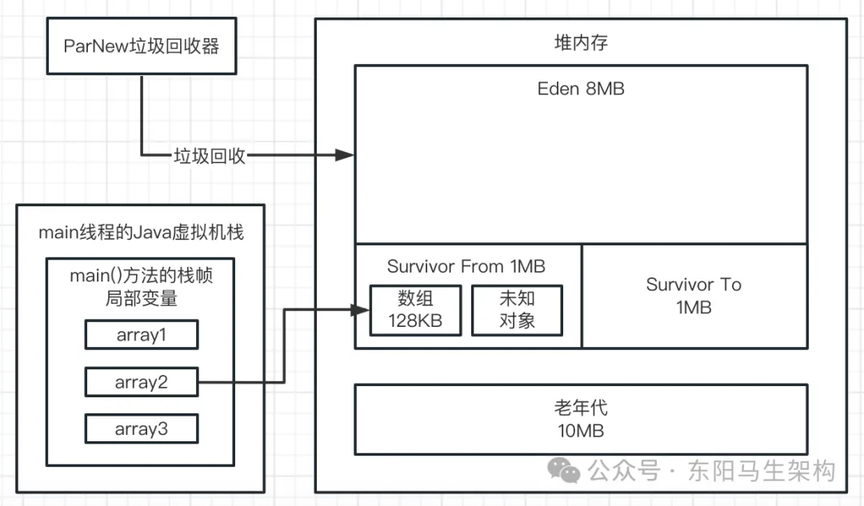
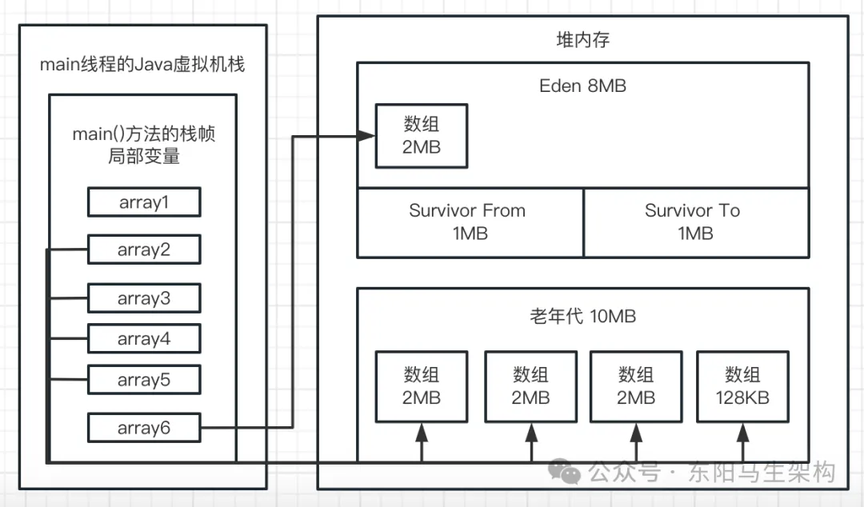
五.最后看第五行代码:byte[] array2 = new byte[2 * 1024 * 1024];
此时会分配一个 2M 大小的数组,尝试放入 Eden 区中。这时 Eden 区明显已经不能放下这个数组了,因为 Eden 区总共 4M,里面已经放入 3 个 1M 的数组,剩余空间只有 1M。此时再放一个 2M 的数组是放不下的,所以这个时候就会触发年轻代的 Young GC;
(5)采用指定 JVM 参数运行程序
然后点击运行即可。运行完毕后,会在工程目录中出现一个 gc.log 文件,gc.log 文件里面就是本次程序运行的 gc 日志。如下图示:
打开 gc.log 文件,会看到如下所示的 gc 日志:
CommandLine flags: -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:MaxNewSize=5242880 -XX:NewSize=5242880 -XX:OldPLABSize=16 -XX:PretenureSizeThreshold=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC 0.268: [GC (Allocation Failure) 0.269: [ParNew: 4030K->512K(4608K), 0.0015734 secs] 4030K->574K(9728K), 0.0017518 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]Heap par new generation total 4608K, used 2601K [0x00000000ff600000, 0x00000000ffb00000, 0x00000000ffb00000) eden space 4096K, 51% used [0x00000000ff600000, 0x00000000ff80a558, 0x00000000ffa00000) from space 512K, 100% used [0x00000000ffa80000, 0x00000000ffb00000, 0x00000000ffb00000) to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000) concurrent mark-sweep generation total 5120K, used 62K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000) Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K class space used 300K, capacity 386K, committed 512K, reserved 1048576K
复制代码
2.JVM 的 Young GC 日志应该怎么看
(1)程序运行采用的默认 JVM 参数如何查看
在 GC 日志中,可以看到如下内容:
CommandLine flags: -XX:InitialHeapSize=10485760 -XX:MaxHeapSize=10485760 -XX:MaxNewSize=5242880 -XX:NewSize=5242880 -XX:OldPLABSize=16 -XX:PretenureSizeThreshold=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
复制代码
这展示了这次运行程序采取的 JVM 参数,包括设置的和默认的参数。
所以如果没有设置 JVM 参数,应该怎么看系统默认使用的 JVM 参数?
方法就是:给 JVM 加一段打印 GC 日志的参数,这样在 GC 日志里就可以看到默认给 JVM 进程分配多大的内存空间了。
(2)一次 GC 的概要说明
接着看 GC 日志中的如下一行:该行日志概要说明了本次 GC 的执行情况。
0.268: [GC (Allocation Failure) 0.269: [ParNew: 4030K->512K(4608K), 0.0015734 secs] 4030K->574K(9728K), 0.0017518 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
复制代码
一.为什么会发生一次 GC
从上图可知,因为最后要分配一个 2M 的数组,结果 Eden 区内存不够。所以就出现了 GC (Allocation Failure),也就是对象分配失败,所以此时就要触发一次 Young GC。
二.这次 GC 是什么时候发生的
很简单,看一个数字——0.268,这指的是系统运行后过了多少秒就发生本次 GC。比如这里的日志就是系统运行后过了 268 毫秒就发生了本次 GC。
三.新生代 GC 使用的是 ParNew
ParNew: 4030K->512K(4608K)。ParNew 的意思是:由于这次触发的是 Young GC,于是用指定的 ParNew 垃圾回收器执行。
四.GC 前新生代使用空间、GC 后存活对象、新生代可用空间
ParNew: 4030K->512K(4608K)。这个代表的意思是:新生代可用空间是 4608K,也就是 4.5M。为什么新生代可用空间是 4608K?因为 Eden 区是 4M,两个 S 区只有一个可放存活对象,另一个要保持空闲。所以新生代的可用空间就是 Eden 区 + 1 个 S 区的大小,即 4608K = 4.5M。
然后 4030K->512K,表示的是对新生代执行了一次 GC。GC 前已经使用了 4030K,但是 GC 后只有 512K 的对象存活下来。
五.本次新生代 GC 消耗时间,单位精确到微妙
0.0015734 secs。这个就是本次新生代 GC 耗费的时间,大概耗费 1.5ms,回收 3M 的对象。
六.GC 前和 GC 后的 Java 堆内存使用了多少
4030K->574K(9728K), 0.0017518 secs。这个代表的是整个 Java 堆内存的情况,整个 Java 堆内存的总可用空间是 9728K = 新生代 4.5M + 老年代 5M。GC 前整个 Java 堆内存使用了 4030K,GC 后 Java 堆内存使用了 574K。
七.本次 GC 消耗时间,单位到精确到 10 毫秒
[Times: user=0.00 sys=0.00, real=0.00 secs]。这个代表的是本次 GC 消耗的时间,这里最小单位是小数点之后两位。这里全部是 0.00 secs,也就是本次 GC 就耗费了几毫秒,所以是 0.00s。
(3)图解 GC 执行过程
第一:看这行日志
ParNew: 4030K->512K(4608K), 0.0015734 secs。在 GC 前,明明在 Eden 区只放了 3 个 1M 的数组,大小一共是 3M=3072K。那么 GC 前新生代应该是使用了 3072K,为什么显示使用了 4030K 内存?
对于这个问题,需要明白两点:
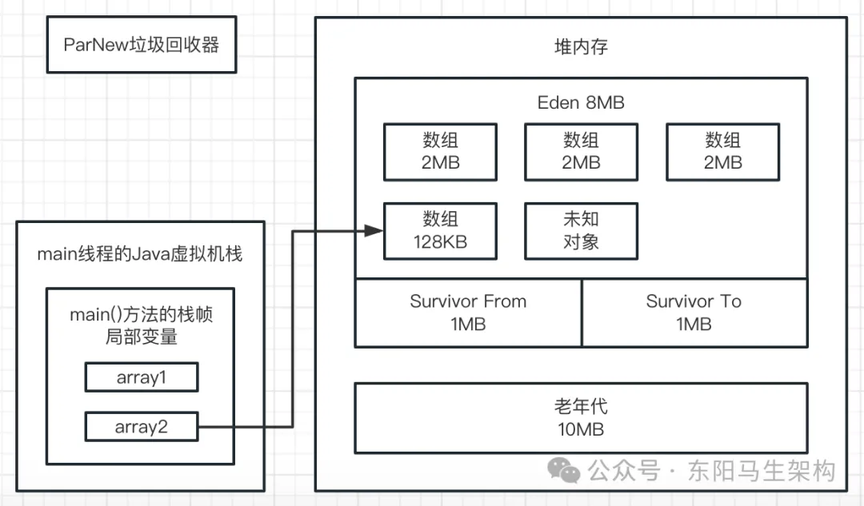
一.虽然创建的数组是 1M,但为了存储它,JVM 还会附带一些其他信息。所以每个数组实际占用的内存是大于 1M 的。
二.除了自己创建的对象以外,可能还有一些看不见的对象在 Eden 区。至于这些看不见的未知对象是什么,可通过专门的工具分析堆内存快照。
所以如下图示:GC 前三个数组和其他一些未知对象加起来,就是占据了 4030K 的内存。
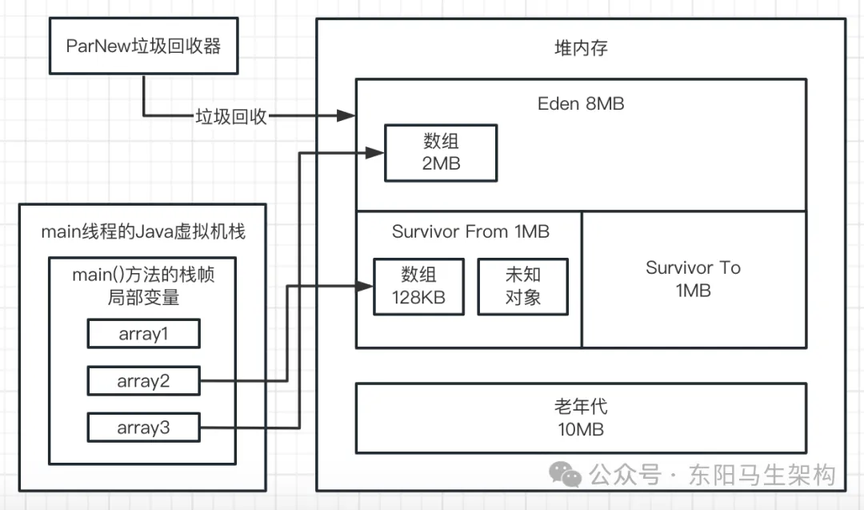
接着想要在 Eden 区分配一个 2M 的数组,此时就会触发 Allocation Failure。Allocation Failure 表示对象分配失败,于是触发 Young GC。然后使用 ParNew 垃圾回收器进行垃圾回收,回收掉之前创建的三个数组。因为此时这三个数组都没被引用,而成为垃圾对象了。如下图示:
第二:看这行日志
ParNew: 4030K->512K(4608K), 0.0015734 secs
复制代码
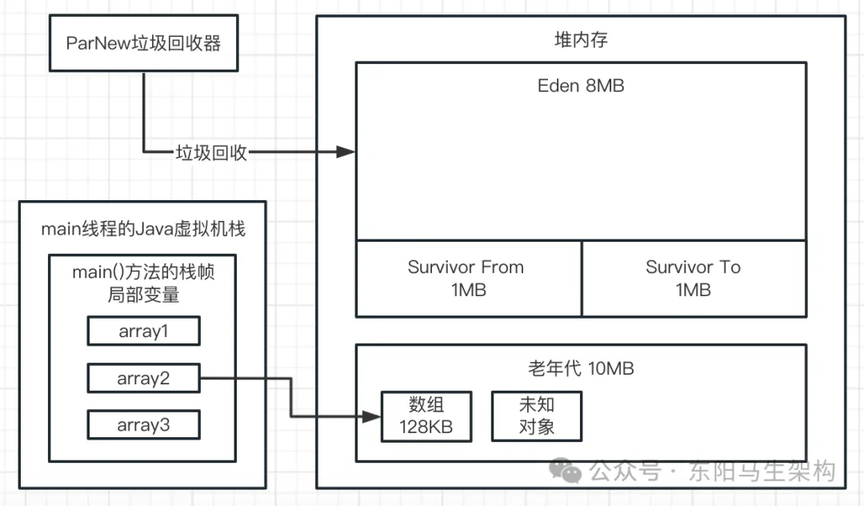
新生代 GC 回收后,新生代中已使用的内存从 4030K 降低到了 512K。也就是说这次 YGC 有 512K 的对象存活下来,从 Eden 区转移到了 S 区。如下图示:
以上就是本次 GC 的全过程。
(4)GC 过后的堆内存使用情况
接着看下面的 GC 日志,这段日志是在 JVM 退出时打印出来的当前堆内存的使用情况。
Heap par new generation total 4608K, used 2601K [0x00000000ff600000, 0x00000000ffb00000, 0x00000000ffb00000) eden space 4096K, 51% used [0x00000000ff600000, 0x00000000ff80a558, 0x00000000ffa00000) from space 512K, 100% used [0x00000000ffa80000, 0x00000000ffb00000, 0x00000000ffb00000) to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000) concurrent mark-sweep generation total 5120K, used 62K [0x00000000ffb00000, 0x0000000100000000, 0x0000000100000000) Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K class space used 300K, capacity 386K, committed 512K, reserved 1048576K
复制代码
一.当前新生代总共可用内存和已经使用内存
par new generation total 4608K, used 2601K
复制代码
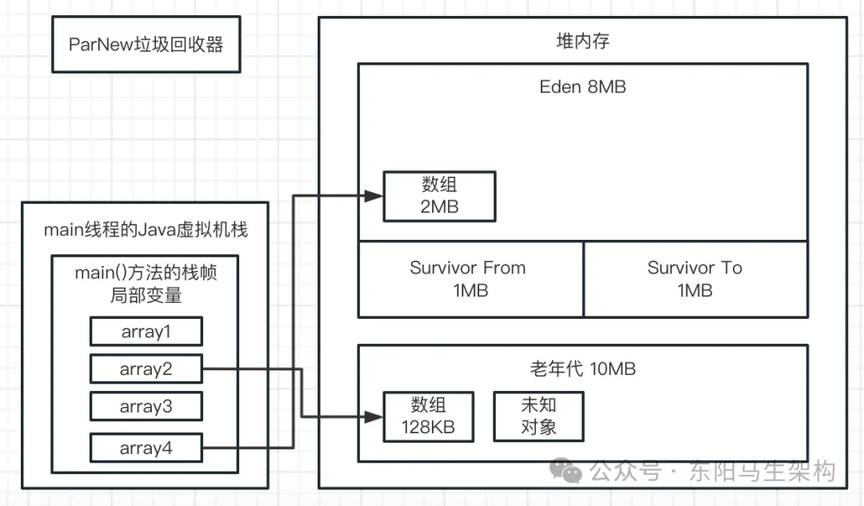
这代表 ParNew 垃圾回收器负责的新生代总共有 4608K(4.5M)可用内存,目前已经使用了的内存是 2601K(2.5M)。此时在 JVM 退出前,为什么新生代占用了 2.5M 的内存?
因为在 GC 后,会通过如下代码又分配一个 2M 的数组:byte[] array2 = new byte[2 * 1024 * 1024];
所以此时在 Eden 区中一定会有一个 2M 的数组,也就是 2048K。然后上次 GC 后在 Survivor From 区中存活了 512K 的对象。由于每个数组会额外占据一些内存来存放一些自己这个对象的元数据,所以可以认为多出来的 41K 是数组对象额外使用的内存空间。因此 GC 后新生代占用的大小是:2048K + 512K + 41K = 2601K。如下图示:
二.接着看以下 GC 日志
eden space 4096K, 51% used [0x00000000ff600000, 0x00000000ff80a558, 0x00000000ffa00000) from space 512K, 100% used [0x00000000ffa80000, 0x00000000ffb00000, 0x00000000ffb00000) to space 512K, 0% used [0x00000000ffa00000, 0x00000000ffa00000, 0x00000000ffa80000)
复制代码
其中清晰地表示,此时:Eden 区 4M 的内存被使用了 51%,因为有一个 2M 的数组在里面。然后 Survivor From 区,显示 512K,100%的使用率。也就是 Survivor From 区被这次 GC 后存活下来的 512K 对象全占据了。
三.接着看以下 GC 日志
如下日志指的是 CMS 管理的老年代内存空间一共 5M,此时已用 62K。
concurrent mark-sweep generation total 5120K, used 62K,
复制代码
而下面两段日志的意思是:Metaspace 元数据空间和 Class 空间的总容量、使用内存等,Metaspace 元数据空间会存放一些类的信息、常量池信息等。
Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K class space used 300K, capacity 386K, committed 512K, reserved 1048576K
复制代码
(5)Metaspace 中的 capacity、committed、reserved
Java8 取消了永久代 PermGen,取而代之的是元数据区 MetaSpace。方法区在 Java8 以后移至元数据区 MetaSpace,JDK8 开始把类的元数据放到本地内存(Native Heap),称为 MetaSpace。理论上本地内存剩余多少,MetaSpace 就可以有多大。
当然我们不可能无限制增大 MetaSpace,需要用-XX:MaxMetaSpaceSize 指定 MetaSpace 大小。
关于 used capacity commited 和 reserved:MetaSpace 由一个或多个 Virtual Space(虚拟空间)组成。虚拟空间是操作系统的连续存储空间,虚拟空间是按需分配的。分配时,虚拟空间会向 OS 预留(reserve)空间,但还没被提交(commit)。
一.MetaSpace 的预留空间(reserved)是全部虚拟空间的大小
虚拟空间的最小分配单元是 MetaChunk(也可以说是 Chunk),当新的 Chunk 被分配至虚拟空间时,与 Chunk 相关的内存空间会被提交。
二.MetaSpace 的 committed 指的是所有 Chunk 占有的空间
每个 Chunk 占据空间不同,当一个类加载器(Class Loader)被 GC 时:所有与之关联的 Chunk 被释放(freed),这些释放的 Chunk 会维护在一个全局的释放数组里。
三.MetaSpace 的 capacity 指的是所有未被释放的 Chunk 占据的空间
假如从 GC 日志发现 committed 是 4864K,capacity4486K。说明有一部分的 Chunk 已经被释放了,代表有类加载器被回收了。附上原文链接:
https://stackoverflow.com/questions/40891433/understanding-metaspace-line-in-jvm-heap-printout
复制代码
3.代码模拟动态年龄判定规则进入老年代
(1)动态年龄判定规则
对象进入老年代的四个常见时机如下:
一.躲过 15 次新生代 GC 后(年龄达到 15 岁)
二.动态年龄判定规则
如果在 S 区内,年龄 1+年龄 2+年龄 3+年龄 n 的对象总和大于 S 区的 50%。此时年龄 n 及以上的对象会进入老年代,不一定需要达到 15 岁。所以动态年龄判断规则有个推论:如果 S 区中的同龄对象大小超过 S 区内存的一半,就要直接升入老年代。
三.如果一次 YGC 后存活对象太多无法放入 S 区,就会直接放入老年代
四.大对象直接进入老年代
首先通过代码模拟出最常见的一种进入老年代的情况:如果 S 区内年龄 1 + 年龄 2 + 年龄 3 + 年龄 n 的对象总和大于 S 区的 50%,此时年龄 n 及以上的对象会进入老年代,也就是动态年龄判定规则。
示例程序的 JVM 参数如下:
-XX:NewSize=10485760 -XX:MaxNewSize=10485760 -XX:InitialHeapSize=20971520 -XX:MaxHeapSize=20971520 -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 -XX:PretenureSizeThreshold=10485760 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
复制代码
在这些参数里需要注意几点:
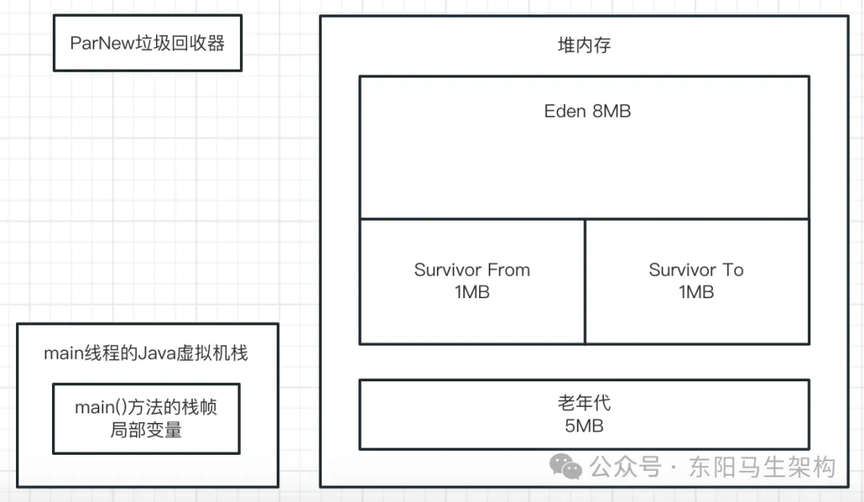
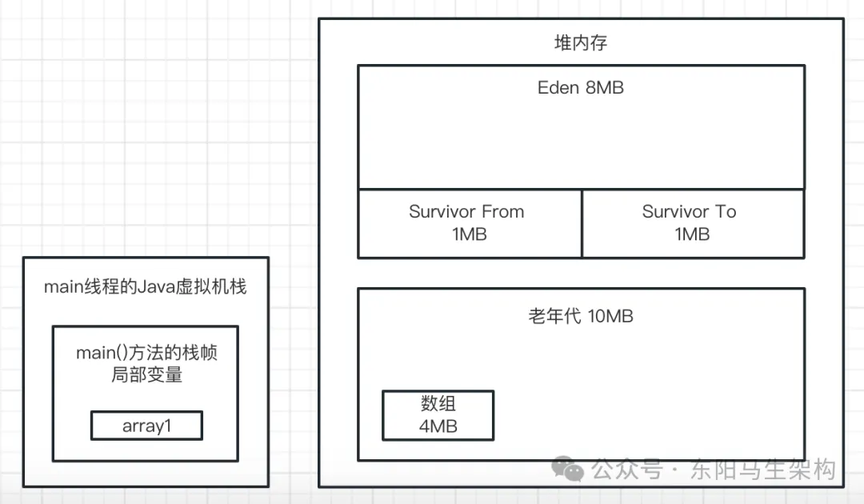
Java 堆的总大小通过-XX:InitialHeapSize 设置为 20M,新生代通过-XX:NewSize 设置为 10M,所以老年代是 10M。然后通过-XX:SurvivorRatio 参数可知,Eden 区是 8M,每个 S 区是 1M。接着大对象必须超过 10M 才会直接进入老年代,-XX:MaxTenuringThreshold=15 设置对象年龄达到 15 岁会进入老年代。
一切准备就绪,先看当前的内存分配情况:
(2)动态年龄判定规则的示例代码
public class Demo { public static void main(String[] args) { byte[] array1 = new byte[2 * 1024 * 1024]; array1 = new byte[2 * 1024 * 1024]; array1 = new byte[2 * 1024 * 1024]; array1 = null; byte[] array2 = new byte[128 * 1024]; byte[] array3 = new byte[2 * 1024 * 1024]; }}
复制代码
接下来运行示例代码,然后通过打印出的 GC 日志分析上述代码执行后 JVM 中的对象分配情况。
(3)示例代码运行后产生的 GC 日志
把上述示例代码以及给出的 JVM 参数配合起来运行,此时会看到如下的 GC 日志。
CommandLine flags: -XX:InitialHeapSize=20971520 -XX:MaxHeapSize=20971520 -XX:MaxNewSize=10485760 -XX:MaxTenuringThreshold=15 -XX:NewSize=10485760 -XX:OldPLABSize=16 -XX:PretenureSizeThreshold=10485760 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:SurvivorRatio=8 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC 0.297: [GC (Allocation Failure) 0.297: [ParNew: 7260K->715K(9216K), 0.0012641 secs] 7260K->715K(19456K), 0.0015046 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]Heap par new generation total 9216K, used 2845K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000) eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000) from space 1024K, 69% used [0x00000000ff500000, 0x00000000ff5b2e10, 0x00000000ff600000) to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000) concurrent mark-sweep generation total 10240K, used 0K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K class space used 300K, capacity 386K, committed 512K, reserved 1048576K
复制代码
(4)GC 日志分析
一.首先看如下几行代码
byte[] array1 = new byte[2 * 1024 * 1024];array1 = new byte[2 * 1024 * 1024];array1 = new byte[2 * 1024 * 1024];array1 = null;
复制代码
这里连续创建了 3 个 2M 的数组,最后还把局部变量 array1 设置为 null,所以此时的内存如下图示:
二.接着执行下面这行代码:
byte[] array2 = new byte[128 * 1024];
复制代码
此时会在 Eden 区创建一个 128K 的数组同时由 array2 局部变量来引用,如下图示:
三.然后会执行下面的代码:
byte[] array3 = new byte[2 * 1024 * 1024];
复制代码
此时希望在 Eden 区再次分配一个 2M 的数组,由于此时 Eden 区里已有 3 个 2M 数组和 1 个 128K 数组,大小都超过 6M 了。Eden 区总共才 8M,此时是不可能在 Eden 区再次分配一个 2M 的数组的,因此一定会触发一次 Young GC。
四.接着开始看 GC 日志:
ParNew: 7260K->715K(9216K), 0.0012641 secs
复制代码
这行日志清晰表明,在 GC 前新生代占用了 7260K 的内存。大概就是 6M 的 3 个数组 + 128K 的 1 个数组 + 几百 K 的未知对象 = 7260K,如下图示:
五.接着看回上述 GC 日志:
这表明,一次 Young GC 过后,剩余的存活对象是 715K。由于新生代刚开始会有 512K 左右的未知对象,此时再加上 128K 的数组,差不多就是 715K。
六.接着看如下 GC 日志:
par new generation total 9216K, used 2845K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000) eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000) from space 1024K, 69% used [0x00000000ff500000, 0x00000000ff5b2e10, 0x00000000ff600000) to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)concurrent mark-sweep generation total 10240K, used 0K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
复制代码
从上面的日志可以清晰看出:此时 From Survivor 区域被占据了 69%的内存,大概就是 700K 左右。这就是一次 Young GC 后存活下来的对象,它们都进入 From Survivor 区。
同时 Eden 区域内被占据了 26%的空间,大概就是 2M 左右。这就是执行代码"byte[] array3 = new byte[2 * 1024 * 1024]"时,在 Young GC 后分配在 Eden 区内的数组。如下图示:
现在 Survivor From 区里的那 700K 对象,是 1 岁。它们熬过一次 GC,年龄就会增长 1 岁。此时 S 区总大小是 1M,存活对象已经有 700K 了,已经超过了 50%。
(5)完善示例代码
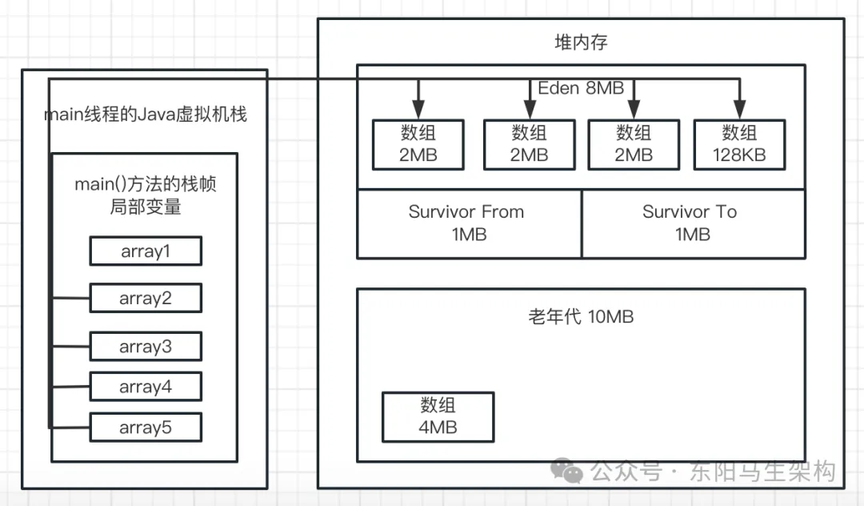
public class Demo { public static void main(String[] args) { byte[] array1 = new byte[2 * 1024 * 1024]; array1 = new byte[2 * 1024 * 1024]; array1 = new byte[2 * 1024 * 1024]; array1 = null; byte[] array2 = new byte[128 * 1024]; byte[] array3 = new byte[2 * 1024 * 1024]; array3 = new byte[2 * 1024 * 1024]; array3 = new byte[2 * 1024 * 1024]; array3 = new byte[128 * 1024]; array3 = null; byte[] array4 = new byte[2 * 1024 * 1024]; }}
复制代码
把示例代码给完善一下变成上述的样子,接下来要触发第二次 YGC,然后看 S 区内的动态年龄判定规则能否生效。
一.接着前面代码执行的分析,继续看如下代码:
array3 = new byte[2 * 1024 * 1024];array3 = new byte[2 * 1024 * 1024];array3 = new byte[128 * 1024];array3 = null;
复制代码
这几行代码运行后,会接着分配 2 个 2M 的数组。然后再分配一个 128K 的数组,最后让 array3 变量指向 null。如下图示:
二.此时接着会运行下面的代码:
byte[] array4 = new byte[2 * 1024 * 1024];
复制代码
这时会发现,Eden 区如果要再放一个 2M 数组进去,是放不下的,所以此时会触发一次 YGC。使用上述 JVM 参数运行这段程序会看到如下 GC 日志:
0.269: [GC (Allocation Failure) 0.269: [ParNew: 7260K->713K(9216K), 0.0013103 secs] 7260K->713K(19456K), 0.0015501 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]0.271: [GC (Allocation Failure) 0.271: [ParNew: 7017K->0K(9216K), 0.0036521 secs] 7017K->700K(19456K), 0.0037342 secs] [Times: user=0.06 sys=0.00, real=0.00 secs]Heappar new generation total 9216K, used 2212K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000) eden space 8192K, 27% used [0x00000000fec00000, 0x00000000fee290e0, 0x00000000ff400000) from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000) to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)concurrent mark-sweep generation total 10240K, used 700K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K class space used 300K, capacity 386K, committed 512K, reserved 1048576K
复制代码
(6)分析最终版的 GC 日志
一.首先第一次 GC 的日志如下:
0.269: [GC (Allocation Failure) 0.269: [ParNew: 7260K->713K(9216K), 0.0013103 secs] 7260K->713K(19456K), 0.0015501 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
复制代码
这个过程前面已经分析过了。
二.接着第二次 GC 的日志如下:
0.271: [GC (Allocation Failure) 0.271: [ParNew: 7017K->0K(9216K), 0.0036521 secs] 7017K->700K(19456K), 0.0037342 secs] [Times: user=0.06 sys=0.00, real=0.00 secs]
复制代码
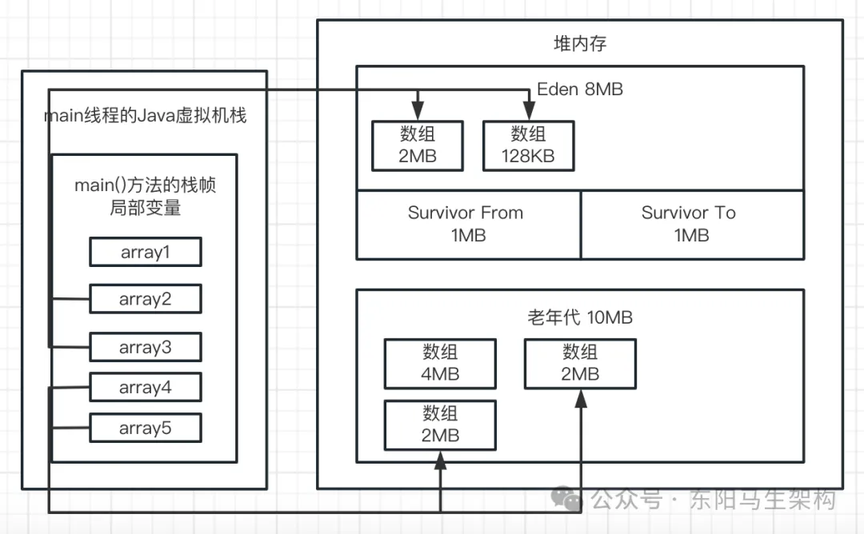
第二次触发 Yuong GC,就是第一次赋值给局部变量 array4 的时候。此时的日志"ParNew: 7017K->0K(9216K)"表明:这次 GC 过后,新生代直接就没有对象了。但 array2 这个局部变量还一直引用一个 128K 的数组,它是存活对象。那么这 128K 的数组以及还有那 500 多 K 的未知对象,此时都去哪里了?
首先在 Eden 区里的 3 个 2M 的数组和 1 个 128K 的数组,肯定会被回收掉的。如下图示:
然后发现 S 区中的对象都是存活的,且总大小超过 50%以及年龄都是 1 岁。于是根据动态年龄判定规则:年龄 1+...年龄 n 的对象总大小超 S 区 50%,年龄 n 及以上的对象进老年代。由于此时 S 区里的对象的年龄都是 1,所以会全部直接进入老年代了。
S 区的对象第一次 YGC 进来时已超 50%,但在第二次 YGC 还存活才升代。所以不是进入 S 区的时候使用动态年龄去判断,而是扫描 S 区时才去判断。
如下图示:
这个可以从下面的日志进行确认:
concurrent mark-sweep generation total 10240K, used 700K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
复制代码
CMS 管理的老年代,此时使用空间刚好是 700K。由此证明此时 Survivor 的对象触发了动态年龄判定规则,虽然没达到 15 岁,但全部进入老年代了。
三.然后 array4 变量引用的 2M 的数组,此时就会分配到 Eden 区中,如下图示:
看如下日志:
eden space 8192K, 27% used [0x00000000fec00000, 0x00000000fee290e0, 0x00000000ff400000)
复制代码
这就说明 Eden 区当前就是有一个 2M 的数组,然后再看下面的日志:
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
复制代码
表示两个 Survivor 区域都是空的,因为之前存活的 700K 对象都进入老年代了,所以现在 Survivor 区都空了。
(7)总结
这里分析了对象是如何通过动态年龄判定规则进入老年代的。如果每次 YGC 过后存活的对象太多,特别是超过了 S 区 50%的空间。那么下次 YGC 时就会触发动态年龄判定规则让一些对象进入老年代中。
注意:不是进入 S 区的时候就用动态年龄去判断,而是扫描 S 区时才判断。
4.代码模拟 S 区放不下部分进入老年代
(1)示例代码
public class Demo { public static void main(String[] args) { byte[] array1 = new byte[2 * 1024 * 1024]; array1 = new byte[2 * 1024 * 1024]; array1 = new byte[2 * 1024 * 1024]; byte[] array2 = new byte[128 * 1024]; array2 = null; byte[] array3 = new byte[2 * 1024 * 1024]; }}
复制代码
(2)GC 日志
使用之前的 JVM 参数来跑一下上面的程序,可以看到下面的 GC 日志:
0.421: [GC (Allocation Failure) 0.421: [ParNew: 7260K->573K(9216K), 0.0024098 secs] 7260K->2623K(19456K), 0.0026802 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]Heap par new generation total 9216K, used 2703K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000) eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000) from space 1024K, 55% used [0x00000000ff500000, 0x00000000ff58f570, 0x00000000ff600000) to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000) concurrent mark-sweep generation total 10240K, used 2050K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K class space used 300K, capacity 386K, committed 512K, reserved 1048576K
复制代码
(3)分析 GC 日志
一.首先看如下几行代码:
byte[] array1 = new byte[2 * 1024 * 1024];array1 = new byte[2 * 1024 * 1024];array1 = new byte[2 * 1024 * 1024];
byte[] array2 = new byte[128 * 1024];array2 = null;
复制代码
上面的代码中:首先分配了 3 个 2M 的数组,然后让 array1 变量指向第三个 2M 数组。接着创建了一个 128K 的数组,并让 array2 指向了 null。同时我们一直都知道,Eden 区里会有 500K 左右的未知对象,如下图示:
二.接着会执行如下代码:
byte[] array3 = new byte[2 * 1024 * 1024];
复制代码
此时想要在 Eden 区里再创建一个 2M 的数组,肯定是不行的,所以此时必然会触发一次 Young GC。
先看如下日志:
ParNew: 7260K->573K(9216K), 0.0024098 secs
复制代码
这里清晰说明了,本次 GC 过后,新生代里就剩下了 500 多 K 的对象了。这是为什么呢,此时明明 array1 变量是引用了一个 2M 的数组的。
因为这次 GC 时,会回收掉上图中的 2 个 2M 的数组和 1 个 128K 的数组,然后留下一个 2M 的数组和 1 个未知的 500K 的对象作为存活对象。这时存活下来的 2M 数组和 500K 未知对象是不能放入 Survivor 区的,因为 Survivor 区只有 1M。如下图示:
三.根据对象进入老年代规则,此时是否要把全部存活对象都放入老年代
也不是,因为首先根据如下日志:
eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000)
复制代码
可知,Eden 区内一定放入了一个新的 2M 的数组,而且这个数组就是刚才最后想要分配的那个数组,由 array3 变量引用。此时会如下图示:
然后再根据如下的日志:
from space 1024K, 55% used [0x00000000ff500000, 0x00000000ff58f570, 0x00000000ff600000)
复制代码
可知,此时 Survivor From 区中有 500K 对象,即那 500K 未知对象。所以新生代 GC 后会存活 2M 数组和 500K 未知对象,放不进 Survivor 区。但也不会让这 2M 数组和 500K 未知对象全部都进入老年代,而是会把 500K 的未知对象先放入 Survivor From 区中。
所以结合 GC 日志,可以清晰的看到:在这种情况下,是会把部分对象放入 Survivor 区的,如下图示:
接着再根据如下日志:
concurrent mark-sweep generation total 10240K, used 2050K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
复制代码
可以发现此时老年代里会有 2M 的数组,因此可以认为:YGC 过后,发现存活下来的对象有 2M 的数组和 500K 的未知对象。此时会把 500K 的未知对象放入 Survivor 区,把 2M 的数组放入老年代。如下图示:
(4)总结
这里展示了 YGC 后存活对象放不下 S 区,部分对象会进入老年代的例子。这种场景下,会有部分对象留在 Survivor 中,有部分对象进入老年代中。
5.JVM 的 Full GC 日志应该怎么看
(1)示例代码
public class Demo { public static void main(String[] args) { byte[] array1 = new byte[4 * 1024 * 1024]; array1 = null; byte[] array2 = new byte[2 * 1024 * 1024]; byte[] array3 = new byte[2 * 1024 * 1024]; byte[] array4 = new byte[2 * 1024 * 1024]; byte[] array5 = new byte[128 * 1024]; byte[] array6 = new byte[2 * 1024 * 1024]; }}
复制代码
(2)GC 日志
接下来需要采用如下参数来运行上述程序:
-XX:NewSize=10485760 -XX:MaxNewSize=10485760 -XX:InitialHeapSize=20971520 -XX:MaxHeapSize=20971520 -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 -XX:PretenureSizeThreshold=3145728 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log
复制代码
这里最关键一个参数,就是-XX:PretenureSizeThreshold=3145728。该参数设置大对象阈值为 3M,即对象大小超过 3M 就直接进入老年代。
运行之后会得到如下 GC 日志:
0.308: [GC (Allocation Failure) 0.308: [ParNew (promotion failed): 7260K->7970K(9216K), 0.0048975 secs]0.314: [CMS: 8194K->6836K(10240K), 0.0049920 secs] 11356K->6836K(19456K), [Metaspace: 2776K->2776K(1056768K)], 0.0106074 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]Heap par new generation total 9216K, used 2130K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000) eden space 8192K, 26% used [0x00000000fec00000, 0x00000000fee14930, 0x00000000ff400000) from space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000) to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000) concurrent mark-sweep generation total 10240K, used 6836K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)Metaspace used 2782K, capacity 4486K, committed 4864K, reserved 1056768K class space used 300K, capacity 386K, committed 512K, reserved 1048576K
复制代码
(3)分析日志
一.首先看如下代码:
byte[] array1 = new byte[4 * 1024 * 1024];array1 = null;
复制代码
这行代码直接分配了一个 4M 的大对象,此时这个对象会直接进入老年代,接着 array1 不再引用这个对象。如下图示:
二.接着看下面的代码:
byte[] array2 = new byte[2 * 1024 * 1024];byte[] array3 = new byte[2 * 1024 * 1024];byte[] array4 = new byte[2 * 1024 * 1024];byte[] array5 = new byte[128 * 1024];
复制代码
连续分配了 4 个数组,其中 3 个是 2M 的数组,1 个是 128K 的数组。如下图示,全部都会进入 Eden 区。
三.接着会执行如下代码:
byte[] array6 = new byte[2 * 1024 * 1024];
复制代码
此时新生代就放不下 2M 的对象了,因为 Eden 区已经不够空间了,所以会触发一次 Young GC。可以参考下面的 GC 日志:
ParNew (promotion failed): 7260K->7970K(9216K), 0.0048975 secs
复制代码
这行日志就显示了:Eden 区原来是有 7260K 对象,但是回收后发现一个都回收不掉,因为上述几个数组都还被 main()方法栈的局部变量引用。
所以此时就会直接把这些对象都放入到老年代里,但是现在老年代里已经有一个 4M 的数组了,此时老年代已经放不下 3 个 2M 的数组和 1 个 128K 的数组了。参考如下 GC 日志:
[CMS: 8194K->6836K(10240K), 0.0049920 secs] 11356K->6836K(19456K), [Metaspace: 2776K->2776K(1056768K)], 0.0106074 secs]
复制代码
可以清晰看到,此时执行了 CMS 垃圾回收器的 Full GC。Full GC 会对老年代进行 GC,同时一般会跟一次新生代 GC 关联,以及触发一次元数据区(永久代)的 GC。
由于在 CMS 的 Full GC 之前,就已经触发过 Young GC 了。所以 Young GC 已经有了,接着就是执行针对老年代的 Old GC。也就是如下日志:
CMS: 8194K->6836K(10240K), 0.0049920 secs
复制代码
这里可以看到老年代从 8M 左右的对象占用,变成了 6M 左右的对象占用。这个过程具体如下:
第一:在完成 Young GC 之后,先把 2 个 2M 的数组放入到老年代。如下图示:
第二:如果继续往老年代放入 1 个 2M 数组和 1 个 128K 数组,则一定放不下。因此这时就会触发 CMS 的 Full GC,然后就会回收掉老年代中的一个 4M 的数组,因为它已经没被引用了。如下图示:
第三:接着往老年代放入 1 个 2M 的数组和 1 个 128K 的数组。如下图示:
所以可以看到如下的 CMS 垃圾回收日志:
CMS: 8194K->6836K(10240K), 0.0049920 secs
复制代码
老年代从 Full GC 回收前的 8M 变成了 6M,就是上图所示。
第四:最后当 CMS 执行 Full GC 完毕后,新生代的对象都进入了老年代。此时最后一行代码要在新生代分配 2M 的数组就可以成功了。如下图示:
(4)总结
这里介绍了一个触发老年代 GC 的案例:就是新生代存活对象太多,老年代都放不下了,就会触发 CMS 的 FGC。
(5)触发老年代 GC 的其他场景
一.执行 YGC 后存活对象太多,老年代逐个放不下后会触发老年代 GC
二.执行 YGC 前老年代可用空间小于历次 YGC 升入老年代对象平均大小,于是就会在执行 YGC 前,提前触发老年代 GC
三.老年代使用率已经达到了 92%的阈值,也会触发老年代 GC
6.问题汇总
问题一:
JVM 优化思路总结
阶段一:项目上线初期
一.上线前,根据预期的 QPS、平均每个请求或者任务的内存需求大小等。评估出需要使用几台机器来承载,每台机器需要什么样的配置。
二.根据系统的请求或者任务处理速度,评估内存使用情况。然后合理分配 Eden 区、Survivor 区、老年代的内存大小。
JVM 调优的总体原则就是:
让短命对象在 YGC 就被回收,不要进入老年代。让长期存活的对象尽早进入老年代,不要在新生代复制来复制去。对系统响应时间敏感且内存需求大的,建议采用 G1 回收器。
如何合理分配各个区域:
一.根据内存增速来评估多久进行 YGC
二.根据每次 YGC 会有多少存活对象来评估 S 区的大小设置是否合理
三.评估多久会进行一次 FGC+产生的 STW 是否可接受
阶段二:项目运营出色,系统负载增加了 100 倍
方案 1:增加服务器数量
根据系统负载的增比,同比增加机器数量,机器配置和 JVM 的配置可以保持不变。
方案 2:使用更高配置的机器
更高的配置,意味着更快速的处理速度和更大的内存。响应时间敏感且内存需求大的使用 G1 回收器,这时候需要和项目上线初期一样,合理地使用配置和分配内存。
问题二:
G1 存不存在类似 ParNew + CMS 频繁回收导致的系统变慢问题?
答:G1 可能会频繁回收,但它每次回收时间可控,所以不会对系统造成太大影响。
文章转载自:东阳马生架构
原文链接:http://www.jnpfsoft.com/?from=infoqyh
体验地址:http://www.jnpfsoft.com/?from=infoq














评论