
JVM 实战—Java 代码的运行原理
1.Java 代码到底是如何运行起来的
(1)首先假设写好了一个 Java 系统
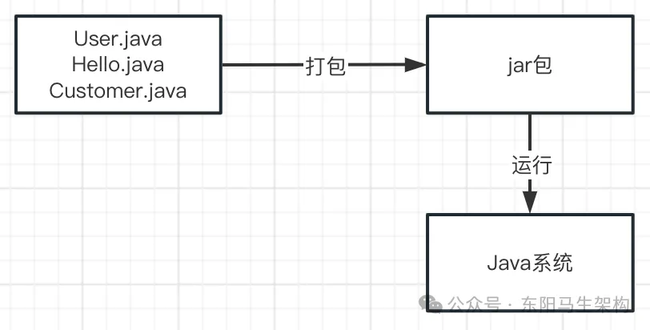
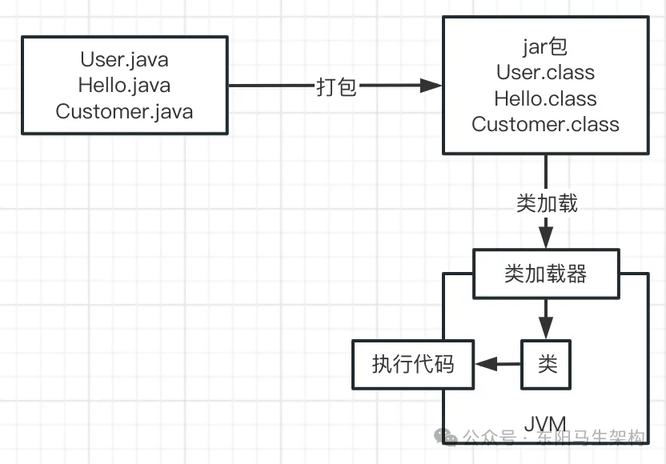
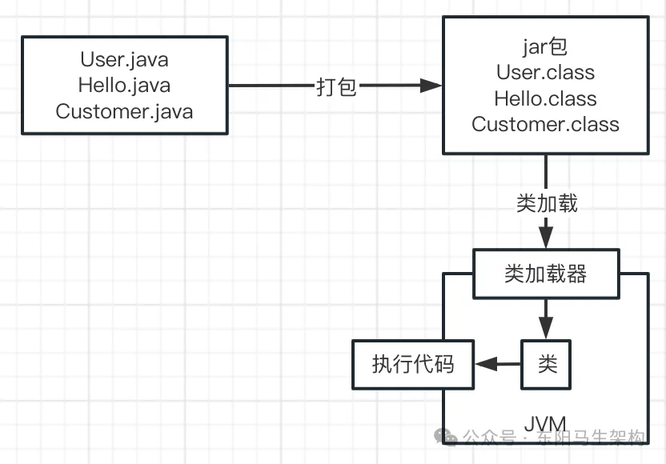
那这个 Java 系统中会包含很多以".java"为后缀的代码文件,比如 User.java。
当写好这个 Java 系统后,应如何部署到线上机器运行呢?一般会先将 Java 代码打包成以".jar"为后缀的 jar 包或者是以".war"为后缀的 war 包,然后把打包好的 jar 包或者 war 包放到线上机器进行部署。
部署的方式有多种,常见的一种方式就是通过 Tomcat 容器来进行部署,当然也可以通过"java"命令来运行一个 jar 包中的代码。如下图示:
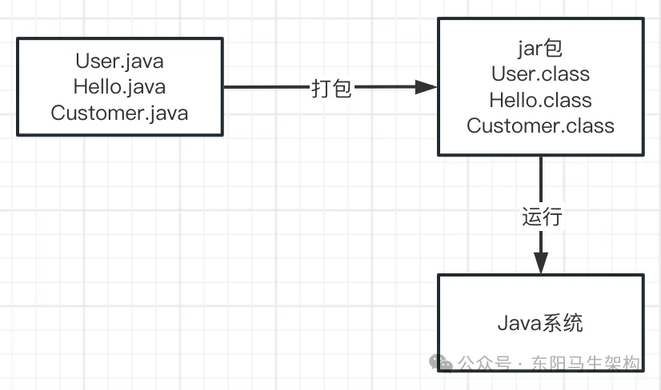
(2)把.java 代码文件编译成.class 字节码文件
对写好的".java"代码进行打包的过程中,会把代码编译成以".class"为后缀的字节码文件,比如 User.class。这些以".class"为后缀的字节码文件才是可以被 JVM 运行的。如下图示:
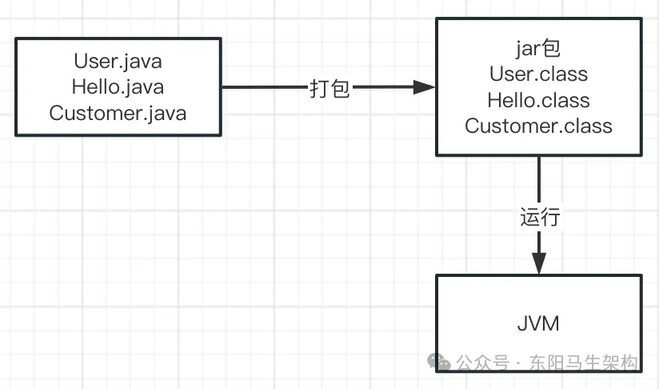
(3)启动 JVM 进程运行.class 字节码文件
这时就需要使用诸如"java -jar"之类的命令来运行打包好的 jar 包了。一旦执行"java"命令,就会启动一个 JVM 进程,这个 JVM 进程会负责运行这些".class"字节码文件。
所以在一台机器上部署一个写好的 Java 系统时,其实就是启动了一个 JVM 进程,由 JVM 来负责这个 Java 系统的运行。
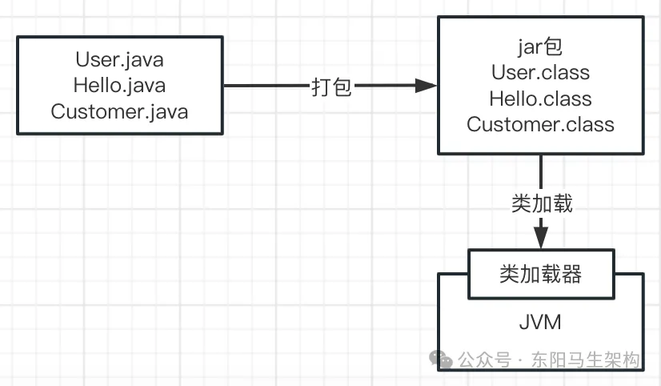
(4)类加载器加载字节码文件到 JVM
接着下一步,JVM 要运行这些".class"字节码文件中的代码。首先会把这些".class"文件中包含的各种类加载到 JVM 里。这些".class"文件就是写好的一个个类,此时就会涉及一个叫"类加载器"的概念。也就是采用类加载器把编译好的".class"字节码文件给加载到 JVM 中,然后供后续代码使用,如下图示:
(5)JVM 会基于字节码执行引擎来执行加载到内存里的那些类
比如代码中有个 main()方法,那么 JVM 就会从 main()方法开始执行代码。需要哪个类就会使用类加载器进行加载,对应的类就在".class"文件中,如下图示:
(6)问题
既然".java"文件可编译成".class"文件运行,那么".class"文件也可以反编译成".java"文件。但这样的话,由于公司的系统代码编译好之后,都是".class"的格式。如果被别人拿到,进行反编译就可以窃取公司的核心系统的源代码了。所以应该如何处理".class"文件,才能保证".class"文件可以不被反编译来获取公司源代码?
首先在编译时,可以采用一些小工具对字节码加密,或者做混淆处理等。现在有很多公司专门做商业级的字节码文件加密,可付费购买其产品。然后在类加载时,对加密的类采用自定义的类加载器来解密文件即可,这样就可以保证源代码不被人窃取。
2.JVM 类加载机制的一系列概念
(1)JVM 的整体运行原理
首先把".java"代码文件编译成".class"字节码文件,然后类加载器把".class"字节码文件中的类加载到 JVM 中,接着 JVM 会从 main()方法开始执行类中的代码。
(2)JVM 在什么情况下会加载一个类
一个类从加载到使用,一般会经历如下过程:加载 -> 验证 -> 准备 -> 解析 -> 初始化 -> 使用 -> 卸载
问题:JVM 在执行写好的代码过程中,一般什么情况下会去加载一个类?也就是说,什么时候会从".class"字节码文件中加载这个类到 JVM 内存?答案非常简单,就是在代码中用到这个类的时候。
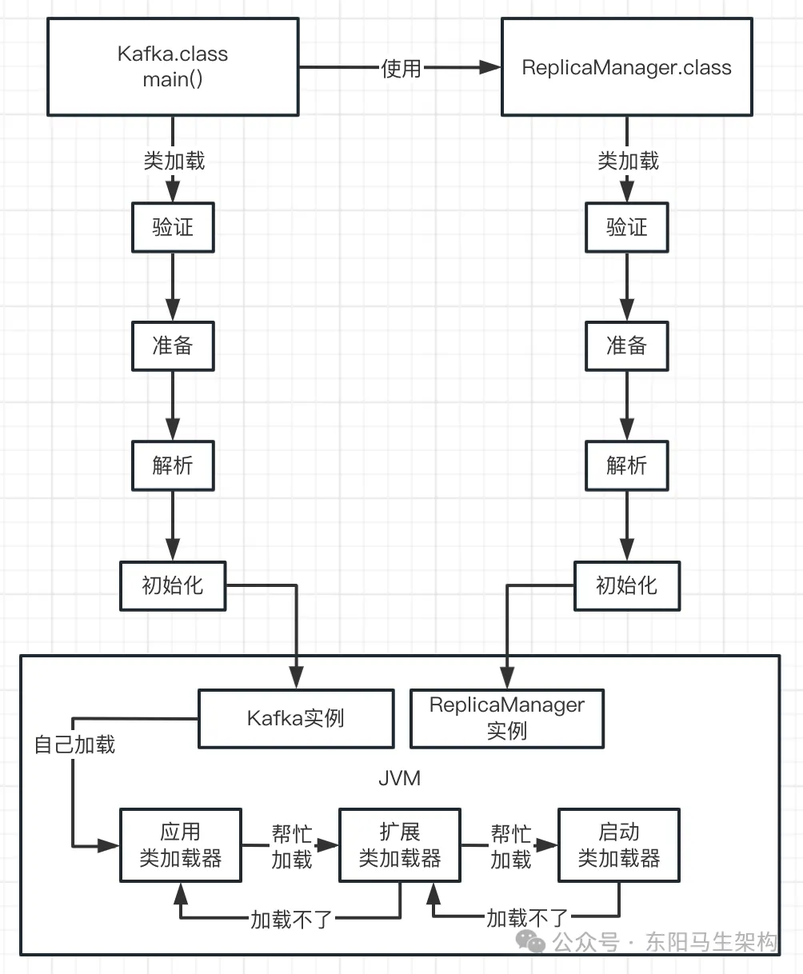
比如下面有一个类(Kafka.class),里面有一个 main()方法作为主入口。一旦 JVM 进程启动后,它一定会先把这个类(Kafka.cass)加载到内存里,然后从 main()方法的入口代码开始执行。
接着假设上面的代码中出现了如下一行代码:
新增的代码中明显需要使用 ReplicaManager 这个类去实例化一个对象,此时就要把 ReplicaManager.class 字节码文件中的这个类加载到内存中。
所以这时 JVM 就会通过类加载器从 ReplicaManager.class 字节码文件中,加载对应的 ReplicaManager 类到内存里使用,这样代码才能跑起来,如下图示:
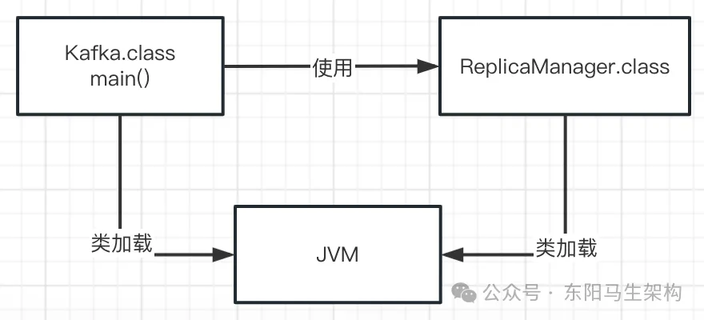
简单总结一下:首先代码中包含 main()方法的主类会在 JVM 进程启动后被加载到内存,然后 JVM 进程会开始执行 main()方法中的代码,接着遇到使用别的类就会从对应的".class"字节码文件加载该类到内存。
(3)验证、准备和初始化的过程
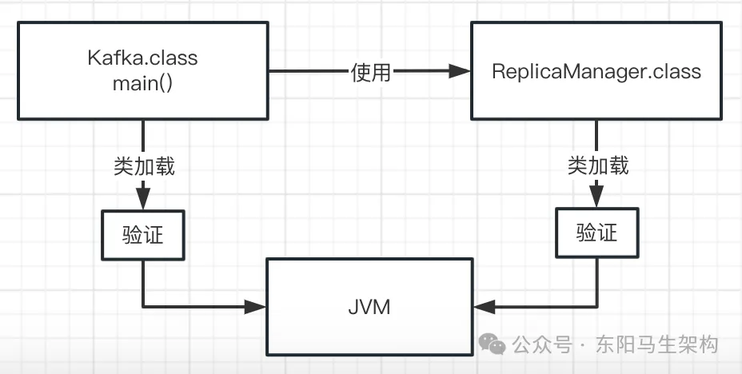
一.验证阶段
这一步会根据虚拟机规范,校验加载的".class"文件内容,是否符合规范。假如".class"文件被篡改,里面的字节码不符合规范,JVM 是没法执行的。
所以把".class"加载到内存里后,必须先验证一下。校验它必须完全符合 JVM 规范,后续才能把它交给 JVM 来运行。如下图示:
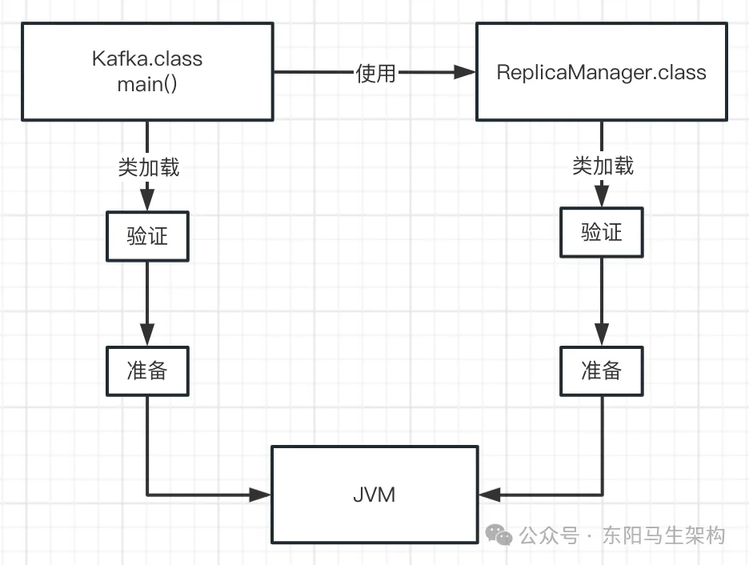
二.准备阶段
我们写好的那些类,其实都有一些类变量,比如这个 ReplicaManager 类:
当这个类的 ReplicaManager.class 文件内容被加载到内存后,就会进行验证,来确认这个字节码文件的内容是规范的。
接着就会进行准备工作,这个准备工作就是给这个 ReplicaManager 类分配一定的内存空间。然后给它的类变量(static 修饰的变量)分配内存空间,设置默认的初始值。比如给 flushInterval 这个类变量分配内存空间,并进行初始化 0 值。整个过程如下图示:
三.解析阶段
这个阶段就是把符号引用替换为直接引用的过程,如下图示:
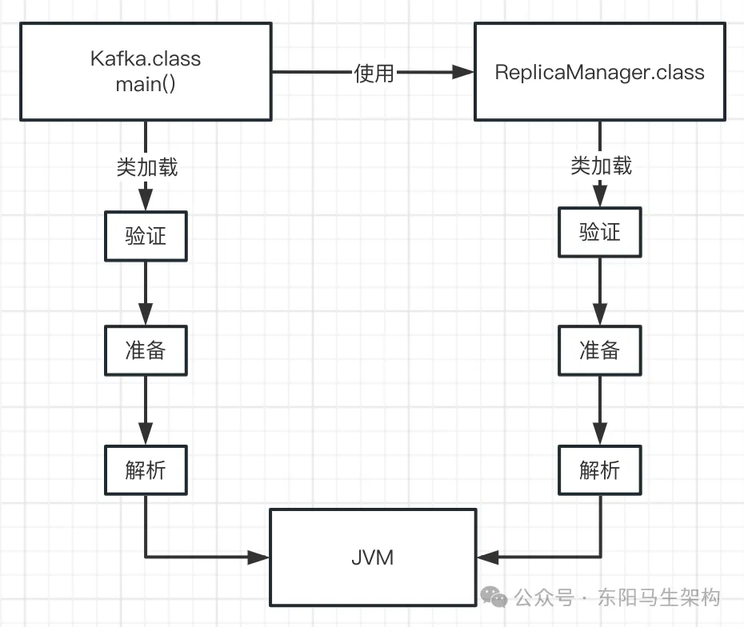
四.三个阶段的总结
这三个阶段里,最关键的其实就是准备阶段。准备阶段会给加载进来的类分配好内存空间,以及也会对类变量分配好内存空间,并设置默认初始值。
(4)核心阶段——初始化
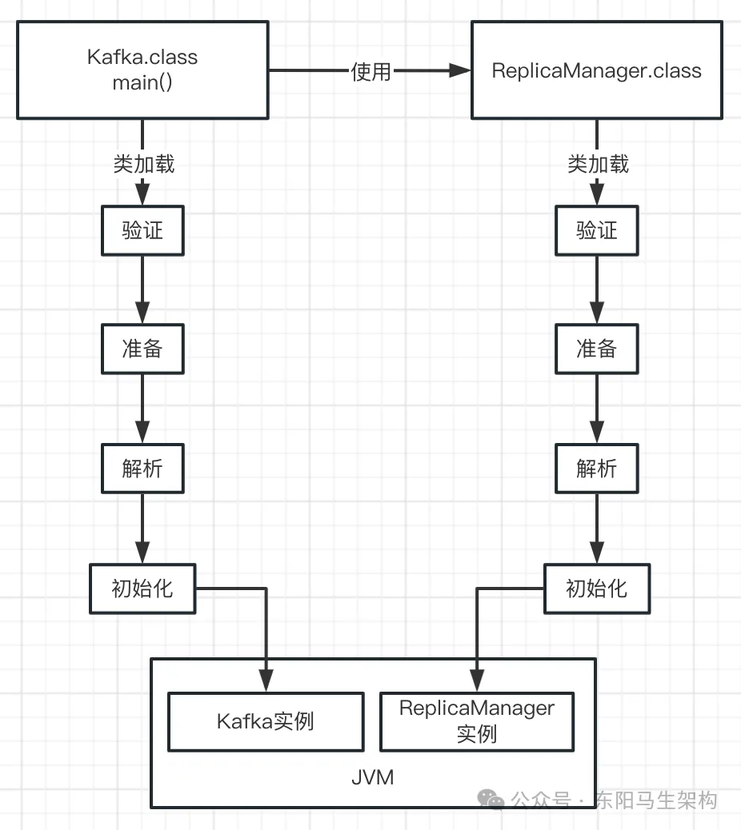
一.类的初始化示例
在准备阶段时,会对 ReplicaManager 类分配好内存空间,另外它的一个类变量 flushInterval 也会设置一个默认的初始值 0。所以接下来在初始化阶段就会正式执行类的初始化代码,类的初始化代码如下所示:
可以看到,flushInterval 这个类变量会通过 Configuration.getInt("flush.interval")获取一个值来进行赋值。但是在准备阶段是不会执行这个具体的赋值逻辑的。在准备阶段仅仅给 flushInterval 类变量开辟内存空间,然后设置初始值 0。在初始化阶段,才会执行类的初始化代码。比如执行 Configuration.getInt("flush.interval")代码,读取一个配置项,然后赋值给类变量 flushInterval。
另外,如下的 static 静态代码块,也会在这个初始化阶段执行。如下代码可理解为,在类初始化时调用 loadReplicaFromDisk()方法。然后从磁盘中加载数据副本,并且放在静态变量 replicas 中。
二.类的初始化时机
什么时候会初始化一个类,一般来说有以下时机:
一.使用 new 关键字实例化类的对象
此时会触发类的加载到初始化的全过程,把类准备好,然后实例化对象。
二.包含 main()方法的主类必须马上初始化
三.如果初始化一个类时发现父类还没初始化,则必须先初始化其父类
初始化父类是一个非常重要的规则,如下代码所示:
如果要初始化 ReplicaManager 类的实例,则会加载该类,然后初始化。但初始化该类之前,发现 AbstractDataManager 父类还没加载和初始化,那么就必须先加载这个 AbstractDataManager 父类,并初始化这个父类。如下图示:
(5)类加载器和双亲委派机制
介绍完类加载从触发时机到初始化的过程后,接下来介绍类加载器。因为实现上述过程,必须依靠类加载器来实现。
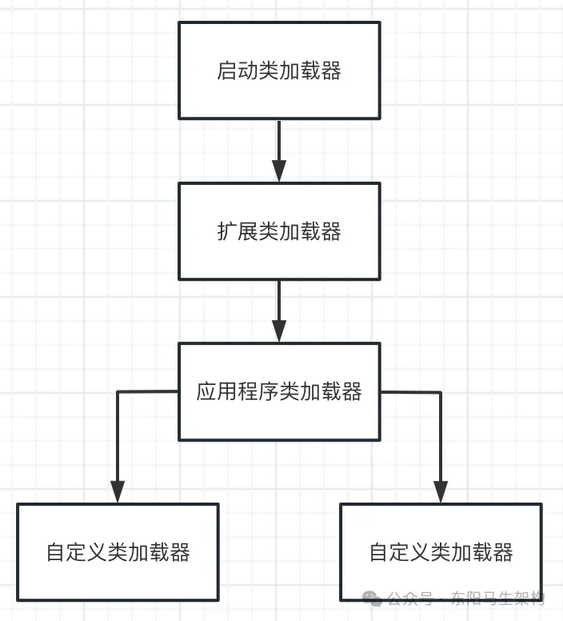
Java 里有如下这些几种类加载器:
一.启动类加载器
这个类加载器主要负责加载 Java 安装目录("lib"目录)下的类。如果要在一个机器上运行写好的 Java 系统,都得先装一下 JDK。那么在 Java 安装目录下,就有一个"lib"目录。"lib"目录里就有 Java 最核心的一些类库,支撑写好的 Java 系统的运行。JVM 一旦启动,就会使用启动类加载器去加载"lib"目录中的核心类库。
二.扩展类加载器
这个类加载器主要负责加载 Java 安装目录("lib\ext"目录)下的类。这个类加载器其实也是类似的,就是在 Java 安装目录下,有一个"lib\ext"目录。该目录有一些类需要使用这个类加载器来加载,以支撑 Java 系统的运行。那么 JVM 一旦启动,也得在 Java 安装目录下加载"lib\ext"目录中的类。
三.应用程序类加载器
这个类加载器就是负责加载"ClassPath"环境变量所指定的路径中的类。其实可以理解为去加载我们写好的 Java 代码,这个类加载器就负责加载我们写好的那些类到内存里。
四.自定义类加载器
除了上面几种外,还可以自定义类加载器,根据需求加载我们的类。
五.双亲委派机制
JVM 的类加载器是有亲子层级结构的:启动类加载器在最上层,扩展类加载器在第二层,第三层是应用程序类加载器,最后一层是自定义类加载器。
然后基于这个亲子层级结构,就有一个双亲委派的机制。当我们的应用程序类加载器需要加载一个类的时候,它会委派给自己的父类加载器去加载,最终传导到启动类加载器去加载。但是如果父类加载器在自己负责加载的范围内,没找到这个类,那么父类加载器就会下推加载权利给自己的子类加载器去进行加载。
比如 JVM 现在需要加载 ReplicaManager 类,此时应用程序类加载器会找其父类加载器(扩展类加载器)帮忙加载该类。然后扩展类加载器也会找其父类加载器(启动类加载器)帮忙加载该类。启动类加载器在"lib"下没找到该类,就会下推加载权利给扩展类加载器。扩展类加载器在"lib/ext"下也没找到该类,则让应用程序类加载器加载。然后应用程序类加载器在其负责范围内,比如由系统打包成的 jar 包中,发现了 ReplicaManager 类,于是它就会把这个类加载到内存里去。
这就是所谓的双亲委派模型:先找父亲去加载,加载不了再由儿子加载,这样就可以避免多层级的类加载器重复加载某些类。否则不同层级的类加载器加载高层级类加载器的类时就会出现重复加载。
(6)问题
当采用 Tomcat 之类的 Web 容器来部署 Java 开发的系统时:Tomcat 本身就是用 Java 写的,它自己就是一个 JVM。而开发好的程序就是一堆编译好的.class 文件,会打包成一个 war 包,然后这些 war 包就会被放入到 Tomcat 中运行。
Tomcat 的类加载机制应怎么设计才能把动态部署进去的 war 包中的类加载到 Tomcat 自身运行的 JVM 中,然后去执行那些开发好的代码?也就是对于 Tomcat 这种 Web 容器中的类加载器应该如何设计?
首先 Tomcat 的类加载器体系如下图所示,它会自定义很多类加载器。
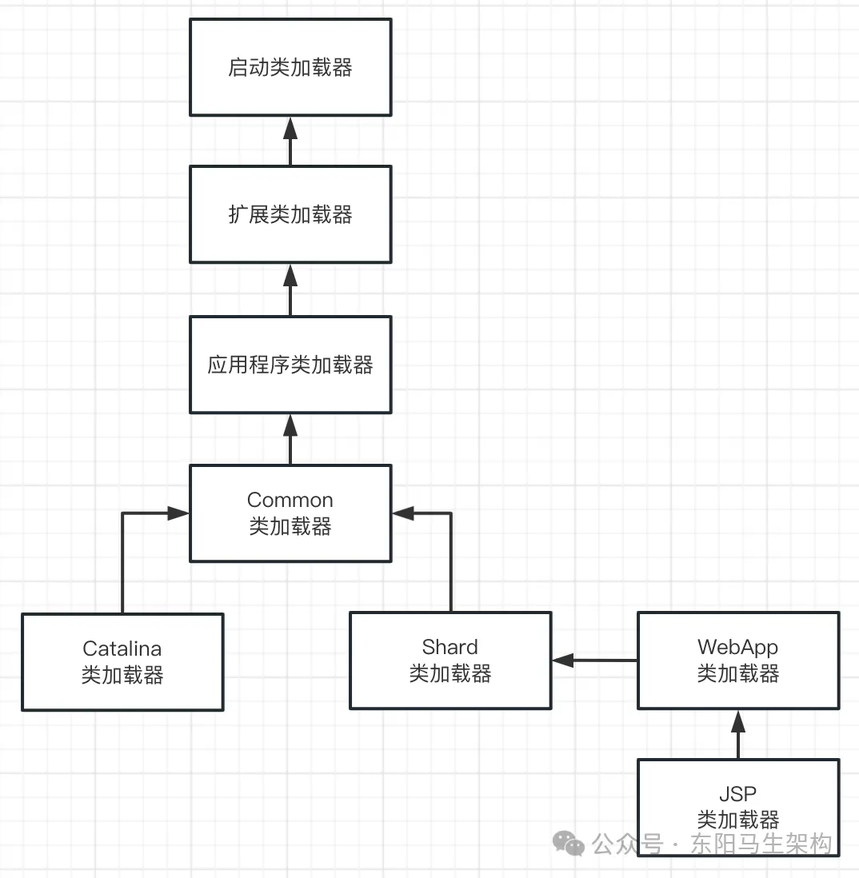
Tomcat 自定义了 Common、Catalina、Shared 等类加载器,其实这些类加载器就是用来加载 Tomcat 自己的一些核心基础类库的。
然后部署在 Tomcat 里的每个 Web 应用都有对应的 WebApp 类加载器,这些 WebApp 类加载器负责加载我们部署的这个 Web 应用的类。至于 JSP 类加载器,则是给每个 JSP 都准备了一个 JSP 类加载器。
而且需要注意的是:Tomcat 是打破了双亲委派机制的,每个 WebApp 负责加载自己对应的那个 Web 应用的 class 文件。即 war 包中的所有 class 文件,不会传导给上层类加载器去加载。
3.JVM 中有哪些内存区域及各自的作用
(1)JVM 类加载的机制问题总结
什么情况下会触发类的加载?
加载后的验证、准备和解析分别干什么?
准备和初始化阶段会如何为类分配内存空间?
然后类加载器的时机和规则是什么?
如下图示:
(2)什么是 JVM 的内存区域划分
其实这个问题非常简单。JVM 在运行我们写好的代码时,会使用多块内存空间,不同的内存空间用来放不同的数据。然后配合我们写的代码逻辑,才能让系统运行起来。
比如现已知 JVM 会加载类到内存来供后续运行,那么这些类加载到内存以后会放到哪里?所以 JVM 里必须有一块内存区域,用来存放我们写的那些类。如下图示:
我们的代码运行起来时,需要执行我们写的一个一个的方法。方法里会有很多变量,这些变量要放在某个内存区域里。类和方法里会创建一些对象,这些对象也需要放在某个内存空间里。如下图示:
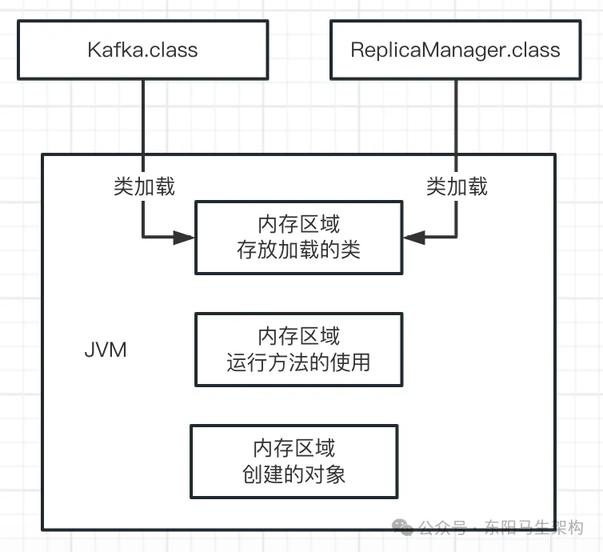
这就是为什么 JVM 中必须划分出来不同的内存区域,它是为了我们写好的代码在运行过程中不同的需要来使用的。接下来,依次看 JVM 中有哪些内存区域。
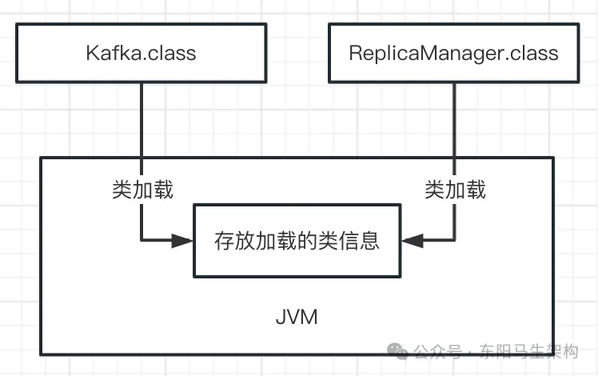
(3)存放类的方法区
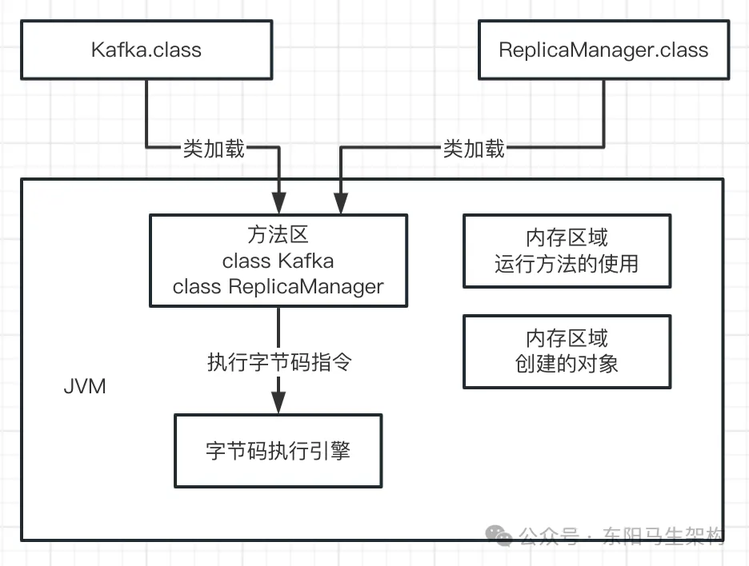
这个方法区是在 JDK 1.8 以前的版本里,代表 JVM 中的一块区域。主要存放从".class"文件加载进来的类,还会存放一些类似常量池的东西。但在 JDK 1.8 后,这块区域的名字改了,叫 Metaspace——元数据空间。当然这里主要还是存放我们自己写的各种类相关的信息。
假设有一个 Kafka.class 类和 ReplicaManager.class 类,如下所示:
这两个类加载到 JVM 后,就会放在这个方法区中,如下图示:

(4)执行代码指令用的程序计数器
如下代码所示:
上面这段代码首先会存在于".java"文件里,该文件就是 Java 源代码文件。但是这个文件是面向开发者的,计算机是看不懂开发者写的这段代码的。所以此时要通过编译器,把".java"源代码文件编译为".class"字节码文件。这个".class"字节码文件里存放的就是根据写出来的代码编译好的字节码。
字节码才是计算器可以理解的一种语言,而不是写出来的那一堆代码。字节码看起来大概如下,跟上面的代码无关,只是一个示例而已。
这段字节码可以大概看到".java"翻译成".class"后大概是什么样。比如"0: aload_0"就是"字节码指令",它会对应一条一条的机器指令。计算机只有读到这种机器码指令,才知道具体应该要干什么。比如字节码指令可从内存里读取某个数据,或者把某个数据写入到内存,各种各样的指令可以指示计算机去干各种各样的事情。
现在 Java 代码通过 JVM 跑起来的第一件事情就明确了。首先 Java 代码被编译成".class"文件中的字节码指令,然后字节码指令一定会被一条一条执行,这样才能实现代码的逻辑效果。当 JVM 加载类信息到内存后,就会使用自己的字节码执行引擎,去执行我们写的代码编译出来的代码指令,如下图示:
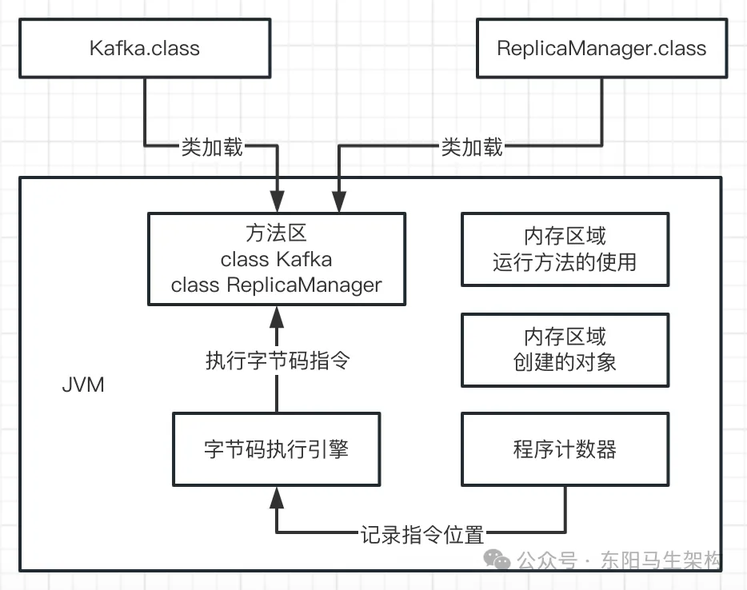
在执行字节码指令时,JVM 就需要一个特殊的内存区域——程序计数器。程序计数器就是用来记录当前执行的字节码指令位置的,也就是记录目前执行到了哪一条字节码指令。如下图示:
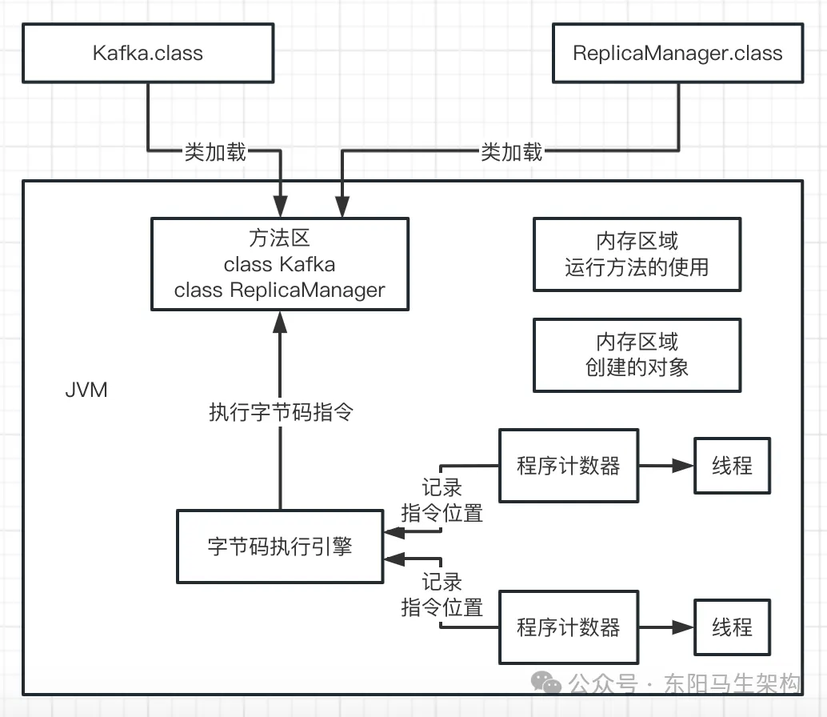
由于 JVM 是支持多个线程的,所以我们写好的代码可能会开启多个线程并发执行不同的代码,所以就会有多个线程来并发的执行不同的代码指令。因此每个线程都会有一个程序计数器,专门记录执行到哪条字节码指令。如下图示:
(5)Java 虚拟机栈
Java 代码在执行时,一定是通过线程来执行某个方法中的代码。即便是下面的代码,也会有一个 main 线程来执行 main()方法里的代码。在 main 线程执行 main()方法的代码指令时,就会通过 main 线程对应的程序计数器记录自己执行的指令位置。
但是在方法里,我们经常会定义一些方法内的局部变量。比如在上面的 main()方法里,就有一个 replicaManager 局部变量,这个局部变量引用了一个 ReplicaManager 实例对象。因此 JVM 必须有一块区域来保存每个方法内的局部变量等数据,这个区域就是 Java 虚拟机栈。
每个线程都有自己的 Java 虚拟机栈。比如 main 线程有一个 Java 虚拟机栈,用来存放执行的方法的局部变量。如果线程执行了一个方法,就会对这个方法调用创建对应的一个栈帧,栈帧里就有这个方法的局部变量表、操作数栈、动态链接、方法出口等。
一.比如 main 线程执行了 main()方法
那么就会为 main()方法创建一个栈帧然后压入 main 线程的 Java 虚拟机栈,同时在 main()方法的栈帧里会存放对应的"replicaManager"局部变量。这个 main 线程执行 main()方法过程,如下图示:

二.假设 main 线程继续执行其栈帧的局部变量里对象的方法
也就是执行 ReplicaManager 对象的方法,在 loadReplicasFromDisk()方法里定义一个局部变量 hasFinishedLoad。
那么 main 线程在执行上面的 loadReplicasFromDisk()方法时,就会为 loadReplicasFromDisk()方法创建一个栈帧压入 Java 虚拟机栈里,然后在栈帧的局部变量表里就会有 hasFinishedLoad 这个局部变量。如下图示:

三.接着 loadReplicasFromDisk()方法调用 isLocalDataCorrupt()方法
isLocalDataCorrupt()方法里也有自己的局部变量,代码如下:
此时会为 isLocalDataCorrupt()方法创建一个栈帧压入 Java 虚拟机栈,而且 isLocalDataCorrupt()方法栈帧的局部变量表有一个 isCorrupt 变量,isCorrupt 变量就是 isLocalDataCorrupt()方法的局部变量。整个过程如下图示:

四.接着 isLocalDataCorrupt()方法执行完毕
那么会把 isLocalDataCorrupt()方法对应的栈帧从 Java 虚拟机栈里出栈。如果 loadReplicasFromDisk()方法执行完毕,也会将对应的栈帧出栈。
上述就是 JVM 中的"Java 虚拟机栈"这个组件的作用:调用执行任何方法时,都会给方法创建栈帧然后入栈,在栈帧里存放这个方法对应的局部变量等数据。这些数据包括这个方法执行的相关信息,方法执行完毕后栈帧就出栈。
所以每个线程在执行代码时,除了程序计数器外,还搭配了一个 Java 虚拟机栈内存区域来存放每个方法中的局部变量表。
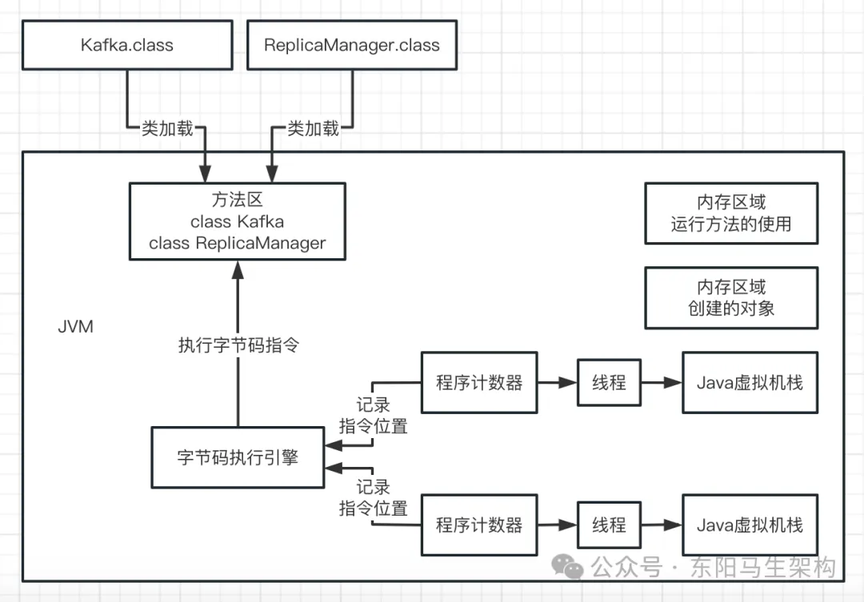
每个线程都会有一个程序计数器,专门记录目前执行到哪条字节码指令。
每个线程都有自己的 Java 虚拟机栈。
每个虚拟机栈都会存放线程执行方法的栈帧。
每个方法的栈帧都会存放该方法的局部变量。
开始执行方法,方法的栈帧入线程虚拟机栈。
执行完方法,方法的栈帧出线程的虚拟机栈。
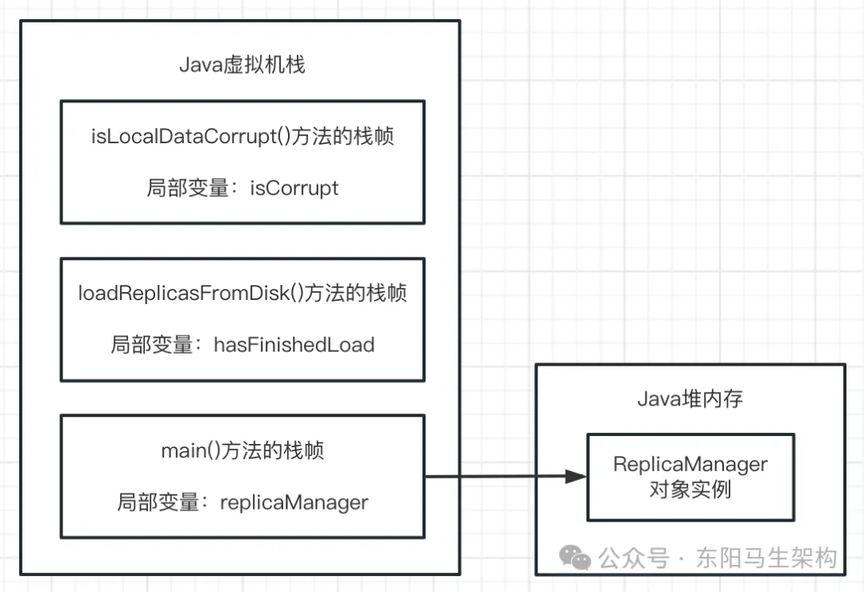
(6)Java 堆内存
现在已知,main 线程执行 main()方法时,会有自己的程序计数器。此外,还会依次把 main()方法、loadReplicasFromDisk()方法、isLocalDataCorrupt()方法的栈帧压入 Java 虚拟机栈,存放其局部变量。
那么接着就得来看 JVM 中的另外一个非常关键的区域,就是 Java 堆内存。Java 堆内存就是用来存放我们在代码中创建的各种对象的,比如下面的代码:
上面 new ReplicaManager()创建了一个 ReplicaManager 类的对象实例。这个 ReplicaManager 对象实例里面会包含一些数据,如下代码所示。这个 ReplicaManager 类的 replicaCount 属于这个对象实例的一个数据,类似 ReplicaManager 这样的对象实例,就会存放在 Java 堆内存里。
Java 堆内存区域里会放入类似 ReplicaManager 的对象,由于在 main 方法里创建了 ReplicaManager 对象,所以会在 main 方法对应的栈帧的局部变量表里,让引用类型的 replicaManager 局部变量存放 ReplicaManager 对象的地址。可认为局部变量表里的 replicaManager 指向了堆的 ReplicaManager 对象。如下图示:
(7)核心内存区域的全流程总结
整体流程图如下:
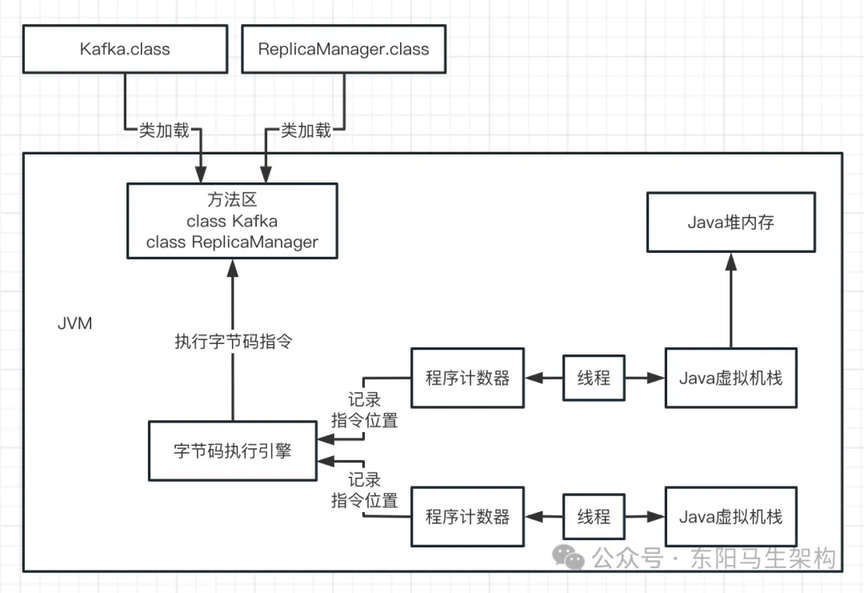
整体代码如下:
首先,JVM 进程启动时就会先加载 Kafka 类到内存里。然后有一个 main 线程,开始执行 Kafka 中的 main()方法。main 线程有一个程序计数器,执行到哪行指令,程序计算器就会记录。
其次,main 线程在执行 main()方法时,会在 main 线程关联的 Java 虚拟机栈里,压入一个 main()方法的栈帧。接着发现要创建一个 ReplicaManager 类的实例对象,此时会首先加载 ReplicaManager 类到内存,然后会创建一个 ReplicaManager 的对象实例分配在 Java 堆内存里,并且在 main()方法的栈帧里的局部变量表引入一个 replicaManager 变量,让 replicaManager 变量引用 ReplicaManager 对象在 Java 堆内存中的地址。
接着,main 线程开始执行 ReplicaManager 对象中的方法,于是会依次把自己执行到的方法的栈帧压入自己的 Java 虚拟机栈,各个方法执行完之后再把方法对应的栈帧从 Java 虚拟机栈里出栈。
以上就是 JVM 各个核心内存区域的功能和对应 Java 代码之间的关系总结。
(8)其他内存区域
其实在 JDK 很多底层 API 里,其内部的源码很多都不是 Java 代码,比如 IO、NIO、Socket 等是通过 native 方法来调用操作系统里的方法。这些方法可能是 C 语言写的方法,或者一些底层类库的方法,比如下面这样的:
在调用这种 native 方法时,就会有线程对应的本地方法栈。本地方法栈类似 Java 虚拟机栈,存放 native 方法的局部变量表等信息。
还有一个区域,是不属于 JVM 的。通过 NIO 中的 allocateDirect 这种 API,可以在 Java 堆外分配内存空间,然后通过 Java 虚拟机里的 DirectByteBuffer 来引用和操作堆外内存空间。很多技术都会用这种方式,因为某些场景下堆外内存分配可提升性能。
(9)问题
在 Java 堆内存中分配的那些对象,到底会占用多少内存?一般怎么来计算和估算系统创建的对象会占用多少内存?
我们创建的那些对象,到底在 Java 堆内存里会占用多少内存空间?这个其实很简单,一个对象对内存空间的占用,大致分为两块:
一.对象自己本身的一些信息
二.对象的实例变量作为数据占用的空间
比如对象头,如果在 64 位的 Linux 操作系统上,会占用 16 字节。然后如果我们的实例对象内部有个 int 类型的实例变量,会占用 4 个字节。如果是 long 类型的实例变量,会占用 8 个字节。如果是数组、Map 之类的,那么就会占用更多的内存。
对象占用的内存:Object Header(16 字节) + Class Pointer(4 字节) + Fields(对象存放类型)。但 JVM 对象的内存占用大小是 8 的倍数,所以结果要向上取整到 8 的倍数。另外 JVM 对这块有很多优化的地方,比如补齐机制、指针压缩机制。
4.JVM 的垃圾回收机制的作用
(1)JVM 中几块内存区域的作用总结
代码在运行时,有一个 main 线程会去执行所有代码。然后线程执行时会通过自己的程序计数器记录执行到哪一个代码指令。另外线程在执行方法时会为每个方法创建一个栈帧放入自己的虚拟机栈,每个方法的栈帧里都有该方法的局部变量。最后就是代码运行过程中创建的各种对象,都会放在 Java 堆内存里。
JVM 中的内存区域:元数据区 + 程序计数器+ 虚拟机栈+ 本地方法栈 + Java 堆 + 堆外内存。
(2)对象的分配与引用
假设有下面一段代码,该代码会通过 loadReplicasFromDisk()方法去磁盘加载需要的副本数据,然后通过 ReplicaManager 对象实例完成这个加载操作。
结合 JVM 运行原理,下面分析上述代码的运行流程。
一.首先一个 main 线程会执行 main()方法里的代码
main 线程自己是有一个 Java 虚拟机栈的,JVM 它会把 main()方法的栈帧压入 main 线程的 Java 虚拟机栈里,如下图示:

二.然后 main()方法里由于调用了 loadReplicasFromDisk()方法
此时会创建 loadReplicasFromDisk()方法的栈帧,然后压入 main 线程的虚拟机栈里,如下图示:

三.接着在 loadReplicasFromDisk()方法里发现一个 repliaManager 变量
于是往 loadReplicasFromDisk()方法的栈帧放入一个 repliaManager 变量,如下图示:

四.然后发现在代码里创建了一个 ReplicaManager 类的实例对象
此时就会在 Java 堆内存中分配这个实例对象的内存空间,同时让 loadReplicasFromDisk()方法的栈帧内的 replicaManager 局部变量,去指向那个 Java 堆内存里的 ReplicaManager 实例对象。如下图示:
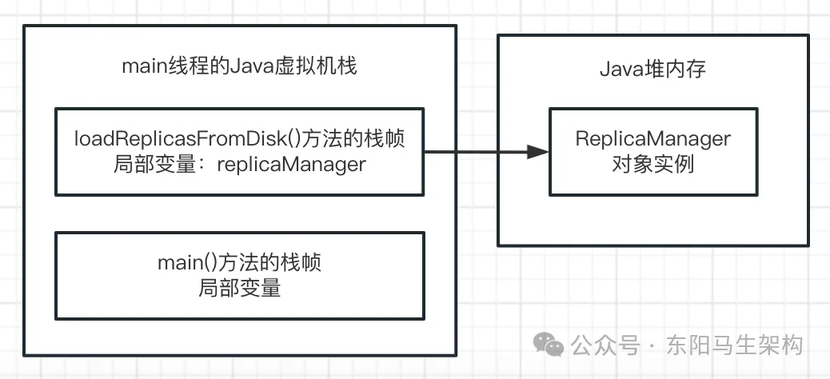
接着就通过 replicaManager 局部变量引用到 ReplicaManager 实例对象,执行 ReplicaManager 实例对象的 load()方法,去完成业务逻辑。
(3)一个方法执行完毕之后会怎样
接着上述代码:
一旦方法里的代码执行完毕,那么这个方法就执行完毕了。也就是说此时 loadReplicasFromDisk()方法就执行完毕了。而一旦 loadReplicasFromDisk()方法执行完毕,就会把 loadReplicasFromDisk()方法的栈帧从 main 线程的虚拟机栈里出栈。如下图示:
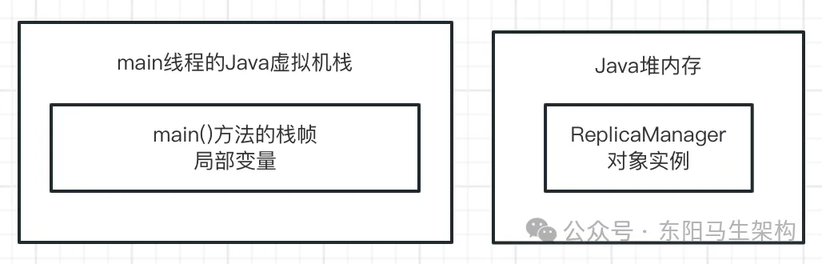
此时一旦 loadReplicasFromDisk()方法的栈帧出栈,那么那个栈帧里的局部变量 replicaManager 也就没有了,即没有任何一个变量指向 Java 堆内存里的 ReplicaManager 实例对象了。
(4)创建的 Java 对象都是要占用内存资源的
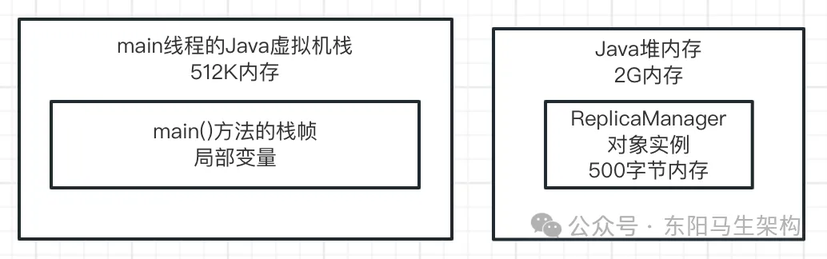
此时 Java 堆内存里的那个 ReplicaManager 实例对象已经没有被引用了,这个对象实际上已经没用了,现在还留在内存里,但内存资源是有限的。
一般会在一台机器上启动一个 Java 系统,机器的内存资源是 4G。然后启动的 Java 系统本质是一个 JVM 进程,它负责运行 Java 系统代码。那么这个 JVM 进程也会占用机器的部分内存资源,如占用 2G 内存资源。当 Java 系统在 JVM 的堆内存中创建对象时,就会占用 JVM 的内存资源,比如 ReplicaManager 实例对象占用 500 字节的内存。
所以在 Java 堆里创建的对象都是会占用内存资源的,而且内存资源有限,如下图示:
(5)不再需要的那些对象应该怎么处理
既然 ReplicaManager 对象实例不需要使用了,已经没有任何方法的局部变量在引用该实例对象了,而它还占着内存资源,那么就可以使用 JVM 的垃圾回收机制来进行处理。
JVM 会有垃圾回收机制,它是一个后台自动运行的线程。我们只要启动一个 JVM 进程,就会自带一个垃圾回收的后台线程。这个线程会在后台不断检查 JVM 堆内存中的各个实例对象,如下图示:
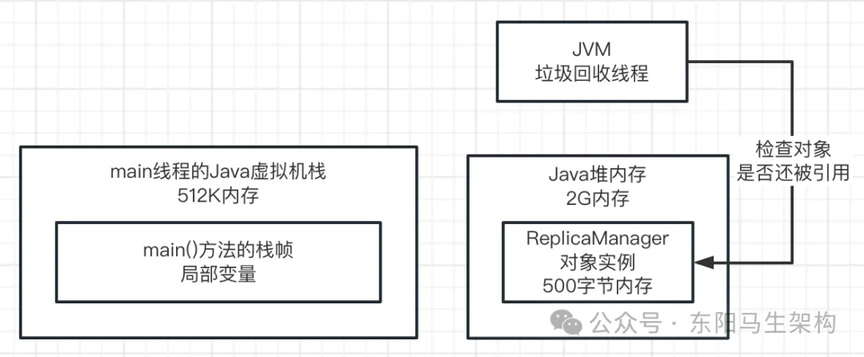
如果某个实例对象没有任何一个方法的局部变量指向它,也没有任何一个类的静态变量包括常量等指向它,那么这个垃圾回收线程就会把这个没人指向的实例对象给回收掉,也就是从内存里清除掉,让它不再占用任何内存资源。
这样这些不再被指向的对象实例,即 JVM 中的垃圾,就会定期被后台垃圾回收线程清理掉,不断释放内存资源。如下图示:
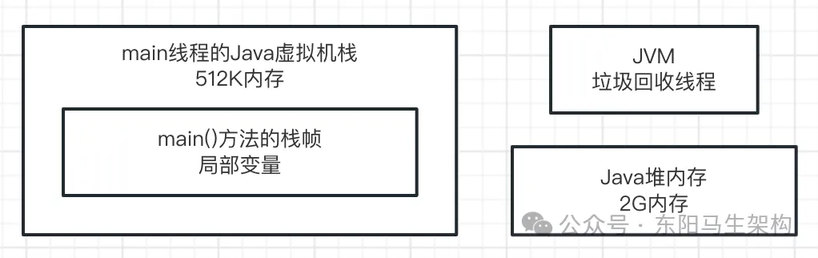
至此,便介绍完了什么是 JVM 中的垃圾,以及什么是 JVM 的垃圾回收。
(6)问题
既然 Java 堆内存里的对象会被回收,那加载到方法区的类会被回收吗?方法区的类什么时候会被回收?
在以下几种情况下,方法区里的类会被回收:
一.该类的所有实例对象都已从堆内存里回收
二.加载这个类的类加载器 ClassLoader 已被回收
三.对该类的 Class 对象没有任何引用
满足上面三个条件就可以回收该类了。
5.问题汇总
问题一:
方法执行完,引用消失,堆内存还未必消失。好多人在做报表导出的时候,就会在 for 循环里不断的创建对象。这样很容易造成堆溢出,像这种大文件导出怎么处理?
答:不要在 for 里创建对象,可以在外面创建一个对象,for 循环里对一个对象修改数据即可。
问题二:
(1)Java 支持多线程,每个线程有自己的 Java 虚拟机栈和本地方法栈?
(2)新建的实例在堆内存,实例变量也是在堆内存?是这样吗?
答:每个线程有自己的 Java 虚拟机栈和本地方法栈。对象实例存放在 Java 堆内存中,实例变量存放在 Java 虚拟机栈中。
问题三:
如果有一个静态的成员变量 int,那么多线程更改是否有线程安全问题?
答:静态成员变量,在内存里只有一份,属于类的,不属于线程私有。多个线程并发修改,一定会有并发问题,可能导致数据出错。
问题四:
类加载是按需加载,可以一次性加载全部的类吗?
答:如果是默认的类加载机制,就是运行过程中遇到什么类加载什么类。如果你要自己加载类,就需要写自己的类加载器;
问题五:
为什么要一级一级的往上找,能否直接从顶层类加载器开始往下找?
答:双亲委派模型的工作过程是:
如果一个类加载器收到了类加载请求,它首先不会自己尝试加载这个类。而是把该请求委派给父类加载器去完成,每一个层次的类加载器都如此。因此所有的加载请求最终都应该传送到最顶层的启动类加载器中。只有当父加载器己无法完成加载请求时,子加载器才会尝试去完成加载。
这样做的一个显而易见的好处就是:Java 中的类随着它的类加载器一起具备了一种带有优先级的层次关系,可保证例如 Object 类在程序的各种类加载器环境中都是同一个类。否则用户编写一个名为 java.lang.Object 类,并放在程序的 ClassPath 中,那么系统就会出现多个不同的 Object 类,当然还双亲委派机制可以避免重复加载同一个类。
从 java.lang.ClassLoader 的 loadClass()方法就可以知道:如果从顶层开始找,就要将 parent 换成 child + 对 child 硬编码,才能找到。也就是说需要改动 loadClass()方法,需要把 parent 换成 child + 硬编码,硬编码也要先从下往上逐层获得整个父子路径才能直接从顶层往下找到。
loadClass()方法的逻辑如下:
先检查请求加载的类是否已被加载过。若没有则调用父加载器的 loadClass(),若父加载器为空则默认使用启动类加载器作为父加载器。如果父类加载器加载失败则抛异常,才调用自己的 findClass()尝试进行加载。
问题六:
包含 main 方法的类优先加载,一个项目中多个类都有 main 方法都加载么?
答:不会的,因为启动一个 jar 包需要指定某个 main 主类,优先会加载它。
问题七:
类加载双亲委派机制中,为什么要先找父加载而不是自己找?
答:每个层级的类加载器各司其职,而且不会重复加载一个类。比如代码用两个不同层级的类加载器,尝试加载父类加载器的某个类。如果有双亲委派机制,那么都会先找父类加载器去加载。父类加载器加载到了之后,以后都会由父类加载器去加载这个类。否则如果没有双亲委派机制,则会出现如下情况:两个不同层级的类加载器就要各自加载,从而出现重复加载同一个类。比如要加载一个"lib"目录下的类,根据双亲委派机制 loadClass()代码:应用程序类加载器初次加载后,它的父类加载器也完成对该类的加载,以后其他应用程序类加载器再次加载该类,就可通过父类加载器加载。
问题八:
自定义类加载器如何实现?
答:自定义一个类继承 ClassLoader 类,重写类加载的 findClass()方法,然后在代码里可用自定义类加载器去针对某个路径下的类加载到内存里。
问题九:
动态部署和静态部署的区别是什么?
答:假设在 Tomcat 部署系统。那么动态部署(热部署),就是直接把系统放入 Tomcat 对应目录,Tomcat 会自动重新加载最新的代码(热部署),无需对 Tomcat 停机再重启。静态部署就是先停止 Tomcat,然后把最新代码放到目录,再重启 Tomcat。
问题十:
类加载器是否会把 jar 包里的所有类一次性加载进去?
答:不会。首先会加载 main 方法的主类,然后在运行时遇到什么类再加载什么类。
文章转载自:东阳马生架构

还未添加个人签名 2023-06-19 加入
还未添加个人简介












评论